- The paper demonstrates that integrating multi-view priors, hierarchical layout grounding, and iterative rectification significantly improves physical plausibility in short-text based indoor scene generation.
- It introduces a novel modular framework that leverages external scene datasets and semantic similarity measures to enhance spatial reasoning in 3D scene synthesis.
- Empirical results show reduced collision and OOB rates along with superior functional metrics, establishing a new state-of-the-art in text-to-3D scene generation.
SDesc3D: Layout-Aware 3D Indoor Scene Generation from Short Descriptions
Text-to-3D indoor scene generation has recently evolved due to advancements in LLMs and VLMs, enabling the synthesis of spatially-coherent, semantically-aligned 3D environments from linguistic input. However, when conditioning on short, semantically condensed descriptions (e.g., "a cozy bedroom"), current systems exhibit limitations: they frequently generate implausible layouts with insufficient detail and a lack of physical plausibility, primarily due to reliance on explicit, fine-grained textual cues. This paper, "SDesc3D: Towards Layout-Aware 3D Indoor Scene Generation from Short Descriptions" (2604.01972), addresses the semantic-to-layout information gap by introducing a modular framework that leverages multi-view knowledge, hierarchical spatial reasoning, and iterative geometric refinement.
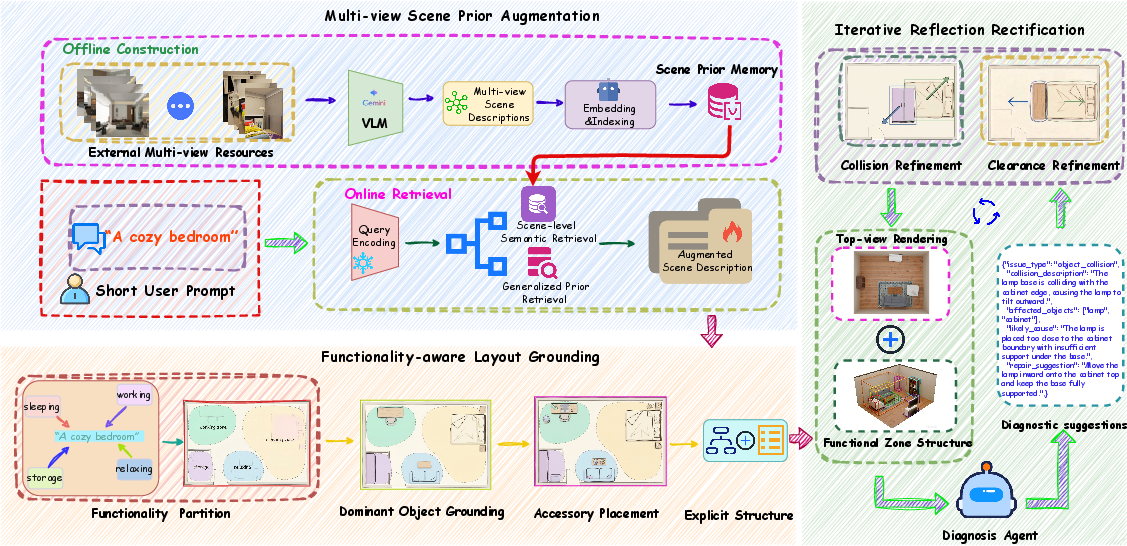
Figure 1: Overview of the SDesc3D framework; its pipeline includes multi-view structural prior injection, regional functionality-based grounding, and feedback-based rectification for physically plausible, detailed scene generation.
Methodological Advancements
Multi-view Scene Prior Augmentation (MSPA)
To address the semantic underspecification inherent in short descriptions, SDesc3D develops a retrieval-based augmentation mechanism that injects external multi-view relational priors into the generation process. Specifically, the system constructs a memory bank from external scene datasets (ScanNet, SpatialGen), encoding each scene as multi-view, VLM-parsed summaries capturing object types, spatial relations, and scale. Given a new description, the framework computes semantic similarity and retrieves the top-K relevant priors (using embedding-based similarity; BM25 ranking as a fallback) to augment the original input, thus providing the missing compositional and spatial context necessary for downstream reasoning.
Functionality-aware Layout Grounding (FLG)
FLG implements a hierarchical reasoning mechanism: it infers region-level functional partitions from the aggregated prior-enhanced description, treating these "zones" as implicit spatial anchors. Each zone is assigned dominant objects and accessories, with relaxed boundary constraints to reflect functional adjacency. The layout is first constructed at a coarse (zone) level, and then recursively refined within each region, with dominant objects positioned according to both functional semantics and geometric feasibility. This results in a graph-structured, hierarchical scene layout capturing both high-level functional structure and fine-scale object arrangements.
Iterative Reflection-Rectification (IRR)
Rather than relying on one-shot post-processing, SDesc3D adopts a multi-stage, feedback-driven refinement process. Each intermediate layout is rendered into a top-down image, then jointly analyzed (along with the programmatic scene graph and historical trace) by an LLM-based agent that diagnoses geometric and physical violations (e.g., collisions, insufficient clearance, OOB errors). Violation types are weighted and aggregated into a penalty score. When the score exceeds a threshold, targeted rectification tools (handling collisions and clearances) are applied, with iteration until satisfactory plausibility is achieved or the maximum step budget is reached.
Empirical Analysis
Quantitative and Qualitative Results
SDesc3D consistently outperforms recent SOTA (HSM, Reason3D) on all core metrics in the short-text setting. Numerically, its collision rate (5.36%) and OOB rate (7.70%) are lowest reported, and it ranks highest in physical plausibility (OP, AO), functional metrics (ZO, CR, FC), and detail richness (DR) under both AI and human evaluation protocols. Notably, improvements in ZO and CR reflect superior zone-based organization and cross-region reasoning, directly attributable to the FLG module. User studies show strong correlation with automatic metrics (r=0.81, ρ=0.73).

Figure 2: Qualitative comparison of SDesc3D against baselines—SDesc3D exhibits more coherent, detailed, and physically plausible scene structures on short-text prompts.
Ablation confirms that MSPA, FLG, and IRR each provide distinct, complementary contributions—MSPA recovers missing structural knowledge, FLG enhances regional structure and composition, and IRR strengthens physical plausibility, with the full model setting the new upper bound on all semantic and physical evaluation metrics.
Robustness and Generalization
SDesc3D exhibits consistent performance across various LLM backends (Gemini 3 Flash, GPT-5.4, Qwen3, Claude-sonnet-4-6), demonstrating that its architectural inductive biases, not a specific foundation model, underpin its capabilities. In contrast to previous pipelines that deteriorate when deprived of fine-grained input, SDesc3D retains competitive or superior performance even in the long-text regime.

Figure 3: Under long-text queries, SDesc3D matches or exceeds competing hierarchical reasoning frameworks, showing generalizability beyond the short-text focus.
Scene Editing and Extendibility
Unlike previous systems, which generate static, hard-to-edit outputs, SDesc3D’s programmatic, functionally annotated representations support interactive editing operations (object addition, deletion, relocation) without loss of global consistency or plausibility.
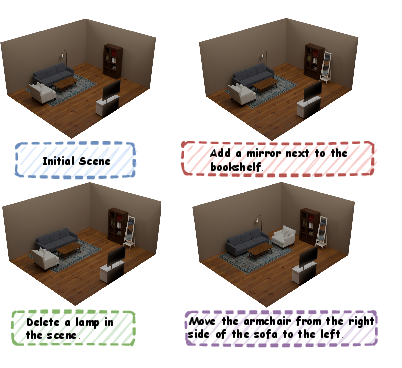
Figure 4: Scene editing results—SDesc3D robustly supports localized, text-driven scene edits via operations on its functionally-structured representation.
Implications and Future Directions
SDesc3D demonstrates that multi-view knowledge injection, hierarchical functional parsing, and agentic, iterative correction are collectively necessary to solve the semantic gap in text-conditioned 3D scene synthesis, particularly under semantic condensation. The modularity and LLM-agnosticism of SDesc3D position it as a candidate backbone for future research into open-ended, interactive embodied environments and for extension into robotics, AR/VR content pipelines, and generative design. Perspectively, richer scene prior curation, further incorporation of commonsense physical rules, and tighter integration of visual input across modalities (e.g., joint text-image reasoning at all stages) offer promising directions for continual improvement.
Conclusion
SDesc3D achieves state-of-the-art functional and physical realism in short-text-conditioned 3D scene generation by integrating multi-view prior augmentation, functionally aware hierarchical reasoning, and iterative, LLM-guided rectification. Its architectural contributions are validated across multiple evaluation axes and LLMs, and it establishes new standards for interactive, editable, and semantically aligned 3D indoor scene generation (2604.01972).