- The paper proposes an agentic framework that dynamically selects between 2D and 3D evidence operators to resolve ambiguities in affordance reasoning within 3D Gaussian scenes.
- It models the task as a Partially Observable Markov Decision Process, using a MLLM-driven policy optimized via GRPO to achieve up to 16.55 mIoU gain on unseen affordances.
- Experimental results demonstrate that adaptive evidence acquisition leads to spatially precise predictions, significantly outperforming static one-shot inference methods in complex, cluttered environments.
Agentic Cross-Dimensional Evidence Acquisition for Fine-Grained Affordance Reasoning in 3D Gaussian Scenes
Problem Setting and Motivation
Affordance reasoning aims to determine the scene regions functionally supporting a specified interaction described in natural language, serving as a core connection between perception and action for embodied agents. Recent 3D Gaussian Splatting (3DGS) representations enable efficient and geometry-aware scene rendering, supporting fine-grained affordance analysis in complex scenes. However, prior approaches predominantly adopt passive one-shot inference from fixed observations, which is fundamentally limited in ambiguous or cluttered environments where task-relevant evidence may be occluded, distributed, or not available in a single view. This evidence-limited setting highlights that the deficit is often not in detection capacity or network expressivity, but rather in the capacity to acquire missing, task-relevant cues.
To address these limitations, "A3R: Agentic Affordance Reasoning via Cross-Dimensional Evidence in 3D Gaussian Scenes" (2604.01882) proposes an agentic framework for affordance reasoning, where evidence is actively and sequentially acquired via 2D and 3D operators, leveraging policy-driven cross-dimensional querying under partial observability.
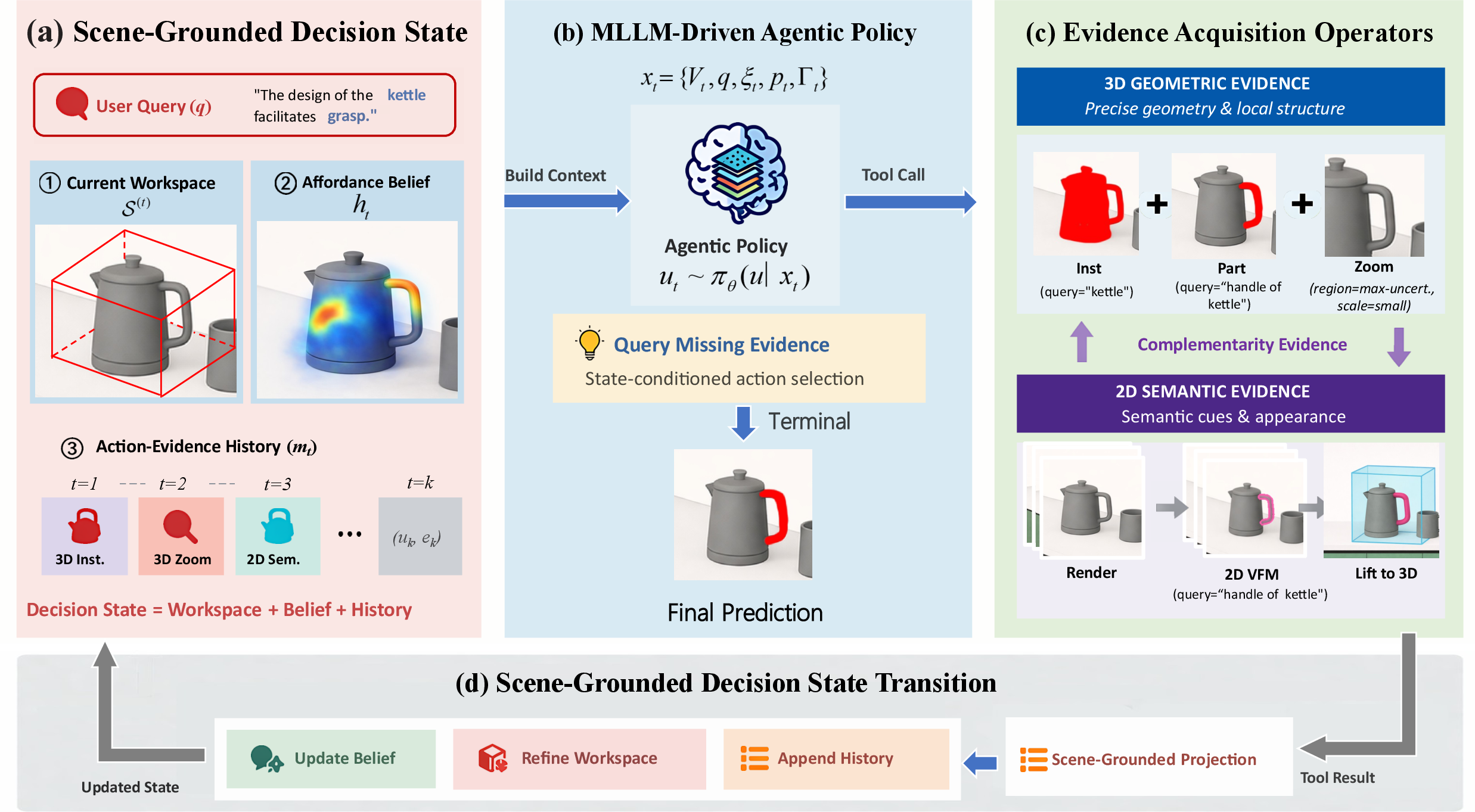
Figure 1: The A3R agent maintains a scene-grounded decision state and dynamically selects 2D or 3D evidence operators, progressively updating its affordance belief to resolve ambiguity.
Technical Approach
A3R models affordance reasoning as a Partially Observable Markov Decision Process (POMDP) over a 3DGS scene S and query q. The agent's internal state embeds:
- the workspace S(t) (a region of the 3DGS-mapped environment),
- a soft belief map ht over the S Gaussians,
- an action-evidence history mt.
At each step, the agent observes context rendered from its current state, and generates evidence-acquisition actions ut—including 3D part/instance segmentation, 2D semantic mask lifting, zoom, or termination—via an MLLM-based (Multimodal LLM) policy. The acquired evidence is projected onto the Gaussian support and updates ht, allowing dynamic refinement of the spatial belief in response to ambiguity.
Cross-Dimensional Evidence Operators
A3R interleaves five evidence-acquisition actions:
- Inst: 3D instance segmentation for initial distractor suppression,
- Part: 3D part segmentation for precise local affordance refinement,
- SAM2D: 2D segmentation (via Segment Anything Model) with 3D lifting for semantic disambiguation,
- Zoom: recursively focusing the workspace for graduated resolution,
- Term: ending evidence acquisition and outputting binary predictions by thresholding ht.
This design supports coarse-to-fine, cross-modal, and context-dependent evidence gathering, crucial for handling previously unseen affordances or ambiguous scenes.
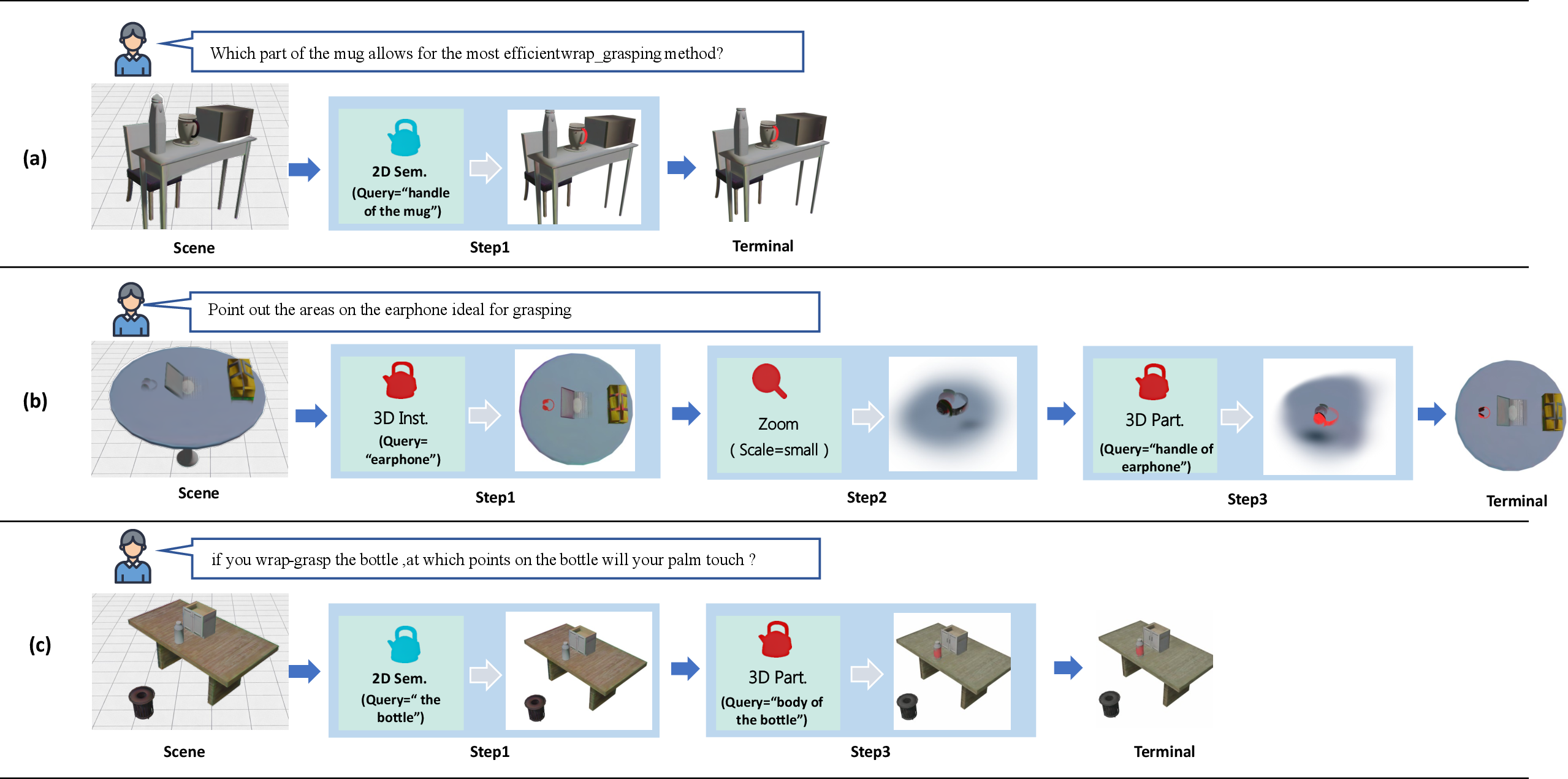
Figure 2: Sample evidence-acquisition trajectories: the agent adaptively transitions between semantic and geometric operators, iteratively refining affordance localization.
MLLM-Driven Policy Optimization
A3R utilizes a Qwen3-VL architecture for the control policy, with decision-making conditioned on:
- multi-view rendered visual context,
- the textual affordance query,
- structured prompts,
- the current decision state and operator schema.
Policy training uses Group Relative Policy Optimization (GRPO), which operates over complete trajectories and updates the MLLM via LoRA, aligning the action generation with task-level reward (spatial mIoU, action efficiency), without requiring dense step-wise supervision.
Experimental Analysis
A3R is evaluated on SeqAffordSplat and 3DAffordSplat, two representative 3DGS-based affordance benchmarks, across Seen and Unseen split protocols. Main results demonstrate:
- A3R achieves up to 16.55 mIoU gain over strong one-shot baselines in generalization to unseen affordance types.
- The training-free policy already outperforms all static fusion and single-modal variants.
- The RL-optimized policy further improves accuracy and step-efficiency.
Qualitative results underline significant differences: static methods yield diffuse or cluttered support in ambiguous cases, while A3R consistently generates spatially precise predictions tightly localized to functional regions, especially for challenging cases with many distractors or subtle part-level distinctions.
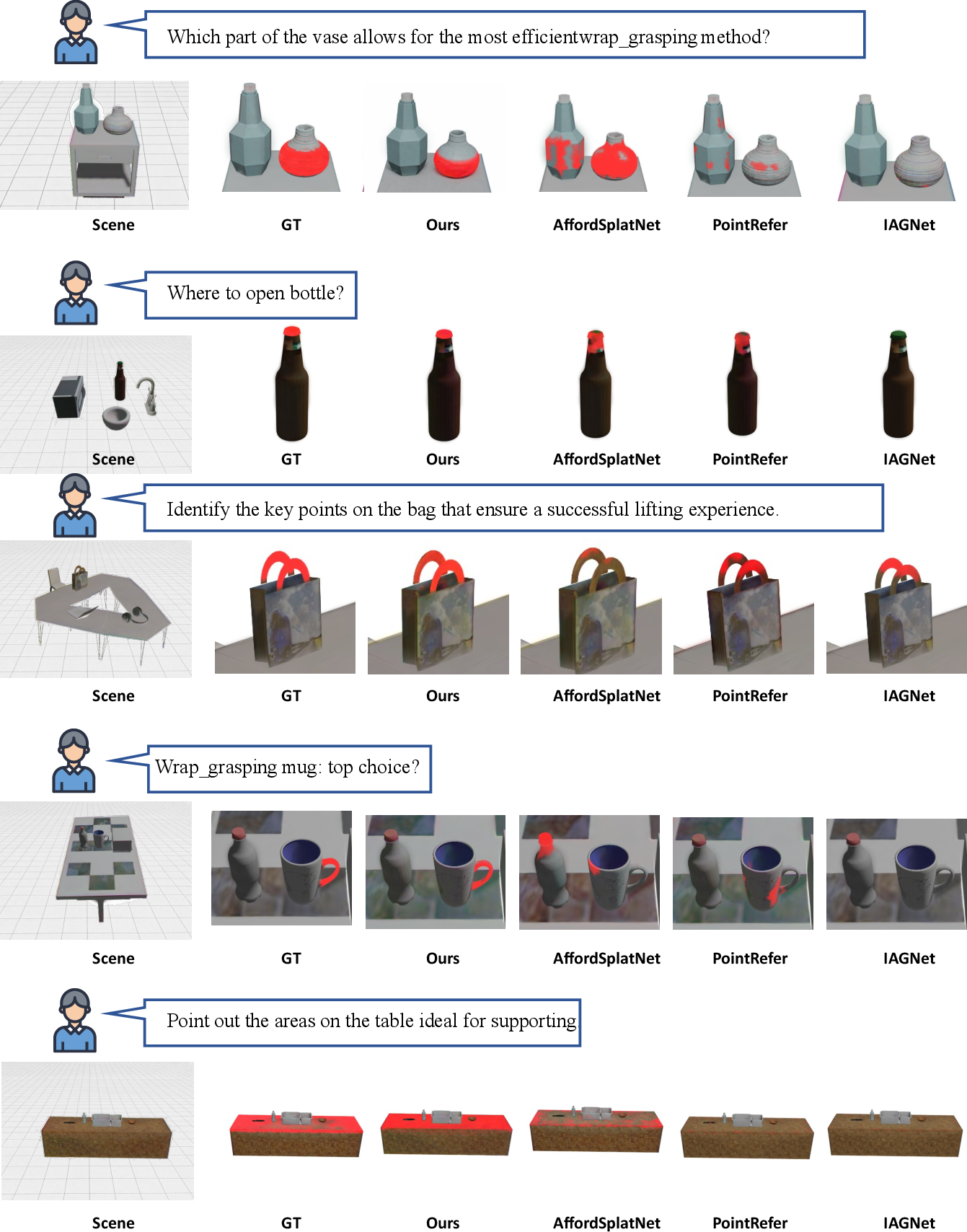
Figure 3: A3R yields spatially precise affordance predictions in ambiguous scenes where static methods mislocalize or over-activate regions.
Ablation reveals that geometric operators (especially part segmentation) are critical for localization in 3DGS, semantic operators (SAM2D) boost disambiguation, and workspace refinement (Zoom) further enhances localization sharpness. Adaptive sequencing via the policy backbone outperforms hand-designed or greedy operator chains, particularly on ambiguous and unseen cases.
Theoretical and Practical Implications
A3R challenges the paradigm of passive, one-shot inference for fine-grained affordance grounding in complex 3D environments. By formalizing the problem as evidence-limited and partially observable, it motivates integrating active perception and agentic decision-making with large pretrained models. The demonstrated efficacy of cross-dimensional evidence acquisition establishes that geometry and semantics must be invoked adaptively, not statically fused.
Practically, these agentic affordance models are well-aligned with the requirements of robotic manipulation, human-robot interaction, and AR/VR, where reasoning under uncertainty, dynamic viewpoint or level-of-detail switching, and robust function localization are essential.
On the theoretical side, A3R links perceptual evidence accumulation models to RL+MLLM-driven scene reasoning, with policy learning mechanisms that leverage end-to-end reward without manual trajectory supervision.
Future Directions
The work suggests several further lines:
- Extension to open-vocabulary or compositional affordance queries,
- More general policies operating over additional evidence operators (e.g., tactile cues, multispectral imagery),
- End-to-end fine-tuning where segmentation operators are also updated,
- Multi-agent or collaborative perception settings,
- Integration into closed-loop action pipelines for robot learning.
Conclusion
A3R constitutes a substantial advance in scene-level affordance reasoning, demonstrating that sequential, agentic cross-dimensional evidence acquisition dramatically improves generalization and localization in 3DGS environments over static or single-modal approaches. The framework establishes a foundation for more general, robust, and interactive reasoning agents—moving affordance grounding methodology towards active, open-world perception and action.