- The paper introduces RAAP, which decouples static (contact points) and dynamic (action directions) affordance prediction using retrieval-augmented features.
- It employs cross-image alignment with a dual-weighted attention mechanism, reducing angular errors to 32.55° on DROID tasks compared to baseline methods.
- Empirical results demonstrate robust zero-shot and low-shot generalization, achieving up to 85% manipulation success in challenging cross-category tasks.
Retrieval-Augmented Affordance Prediction with Cross-Image Action Alignment: A Technical Analysis
Introduction
The paper "RAAP: Retrieval-Augmented Affordance Prediction with Cross-Image Action Alignment" (2603.29419) introduces a novel framework, RAAP, designed to improve generalization in visual affordance prediction for robotic manipulation, particularly under data-scarce regimes and in scenarios involving unseen object categories and tasks. The method strategically combines the strengths of retrieval-based and training-based paradigms, introducing a decoupled architecture wherein static and dynamic affordance components are addressed through distinct but complementary mechanisms. This essay provides a detailed technical discussion of the methodology, experimental findings, and broader implications of RAAP.
Methodological Contributions
RAAP is architected around the explicit decomposition of affordances into static (contact point) and dynamic (action direction) elements. The static component is handled via dense correspondence using feature backbones from state-of-the-art vision models, while the dynamic component is predicted through a cross-image alignment model that aggregates information from multiple retrieved references. Unlike previous works that either transfer full affordance tuples from a single memory sample or apply a monolithic large-scale model, RAAP decouples transfer modalities and leverages cross-reference contextualization for ambiguity resolution in dynamic prediction.
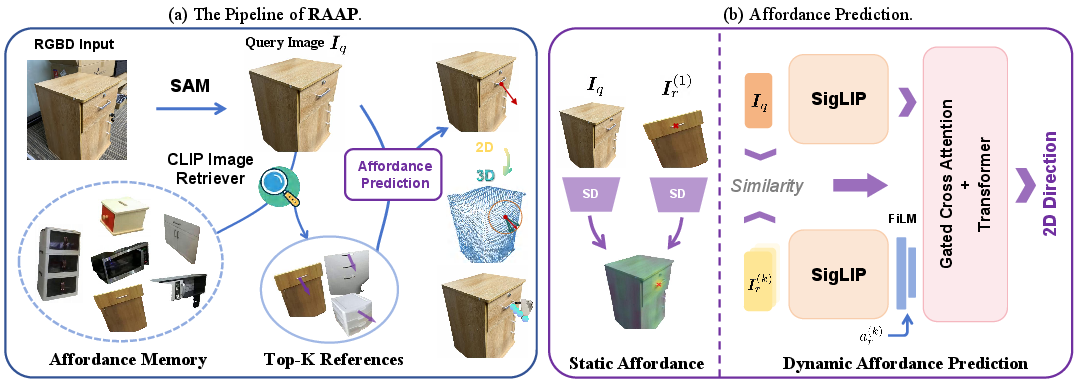
Figure 1: Schematic of the RAAP pipeline, illustrating memory retrieval, dense static affordance transfer, reference aggregation, and alignment-based dynamic direction prediction.
The affordance memory at the core of RAAP stores segmented object interaction episodes, making use of CLIP embeddings for efficient and semantically-aware reference retrieval. Static contact prediction is executed by matching local features from a top-1 reference (using Stable Diffusion–extracted representation), prioritizing geometrically precise transfer. In parallel, dynamic action vectors are regressed by fusing multiple (top-K) memory references via a SigLIP-2 backbone, FiLM modulation, and a dual-weighted attention mechanism that incorporates both pre-computed visual similarity and learned gating to select and weigh relevant exemplars.
Empirical Results and Quantitative Analysis
Comprehensive experiments on the DROID and HOI4D datasets, alongside extensive real-world and simulated robotic trials, establish the strong generalization capabilities of RAAP, especially under low-shot and zero-shot settings.
Ablation studies confirm that the dual-weighted attention, which fuses both pretrained and learned relevance signals during multi-reference alignment, yields the lowest angular errors in post-contact dynamic prediction. For instance, with K=3 retrieved references, the model's mean angular error (MAE) on DROID tasks is 32.55∘, a clear improvement over RAM (62.84∘) and A0 (74.81∘) baselines. Notably, retrieval aggregation reduces failure modes due to misalignment or memory sparsity afflicting previous approaches.

Figure 2: Qualitative comparison of 2D affordance predictions, visualizing superior accuracy (contact and action) for RAAP relative to RAM and A0 baselines.
Model performance scales favorably with increases in the number of retrieved references up to K=3, after which noise and diminishing returns are observed. This validates the empirical choice of moderate reference aggregation.
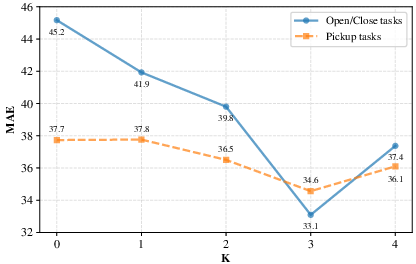
Figure 3: Sensitivity analysis of MAE as a function of the number of retrieved references K, demonstrating optimal error reduction at K=3.
Real-world experiments on a Franka Emika robotic platform (with random object placements) demonstrate systematic improvements in manipulation success rates for both unseen-object and cross-category scenarios. For challenging cross-category manipulations—such as transferring "pickup mug" knowledge to "pickup kettle"—RAAP achieves success rates as high as 85% in simulation, outperforming RAM and A0 by wide margins. These results are attributed to the model's ability to localize contact points robustly and disambiguate dynamic action directions through cross-scene contextualization.
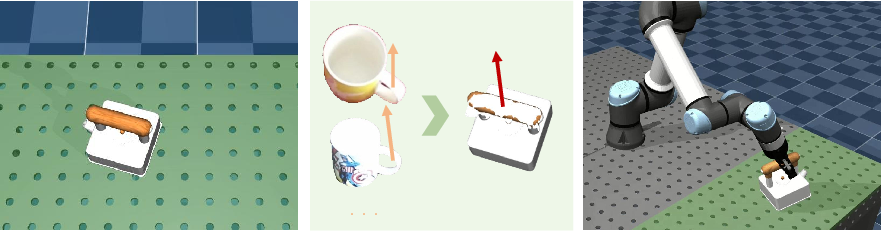
Figure 4: Demonstration of cross-category transfer, with handle-oriented pickup affordances successfully applied from mugs to kettles in MuJoCo simulation.
Implications for Affordance Generalization and Robotic Manipulation
The dual-branch decoupling in RAAP directly addresses the geometric versus semantic nature of affordance uncertainty. By leveraging feature correspondence in static transfer and selective evidence aggregation for dynamic prediction, the framework achieves robust zero-shot generalization without requiring large-scale task-specific datasets. This approach challenges the prevailing dependence on either curated demonstration libraries or overparameterized neural policies, indicating that careful architecture and retrieval-augmented cross-scene alignment can close generalization gaps often observed in high-level robot affordance reasoning.
Practically, RAAP's architecture supports plug-and-play transfer for novel object categories and manipulation tasks, provided semantically relevant references exist within the memory. The framework's efficacy in low-shot and zero-shot settings makes it appropriate for embodied agents intended to operate in open-world, long-tail environments where exhaustive annotation and data collection are infeasible.
Future Directions
While RAAP attains reduced inference error and increased execution reliability in the evaluated tasks, the current framework operates predominantly for short-horizon, single-object interactions. Extension to multi-object scenes and long-horizon sequential affordance reasoning (where temporal and spatial dependencies compound affordance ambiguity) remains open. Moreover, the integration of closed-loop feedback or active perception modules could further enhance robustness in non-stationary and unpredictable environments. Scalable affordance memories with efficient retrieval over very large collections also merit further architectural investigation.
Conclusion
RAAP sets a new technical standard for data-efficient, generalizable affordance prediction in robotics by merging dense static transfer and retrieval-augmented dynamic action alignment. The explicit decomposition of affordance representation, supported by semantically-aware reference selection and attention-weighted multi-exemplar aggregation, yields consistent improvements in both simulation and physical robotic execution. The framework provides a credible pathway toward truly adaptive robotic systems that can perform fine-grained manipulation in the open world with minimal supervision and annotation, paving the way for further developments in scalable, retrieval-augmented embodied AI.
References
- "RAAP: Retrieval-Augmented Affordance Prediction with Cross-Image Action Alignment" (2603.29419)