- The paper introduces a cosine-normalized attention mechanism that realigns traditional dot-product attention to focus on angular similarities in hyperspectral data.
- The proposed spatial–spectral transformer, using L2 normalization and squared cosine similarity, achieves up to 99.23% Overall Accuracy on standard datasets.
- The approach enhances robustness to illumination and sensor variations while effectively operating under limited labeled data conditions.
Cosine-Normalized Attention for Hyperspectral Image Classification
Introduction
Hyperspectral image classification (HSIC) requires nuanced exploitation of highly redundant, high-dimensional data where angular relationships between spectral signatures are pivotal for discriminative feature learning. While transformer-based methods have set the state-of-the-art in modeling long-range spatial-spectral dependencies, their conventional dot-product attention mechanisms are fundamentally misaligned with hyperspectral data geometry due to their sensitivity to feature magnitude. The paper "Cosine-Normalized Attention for Hyperspectral Image Classification" (2604.01763) addresses this representational mismatch by introducing a cosine-normalized attention mechanism that emphasizes angular similarity, an inductive bias known to confer robustness to illumination and sensor intensity variations.
Methodology
The proposed framework integrates cosine-normalized attention into a spatial–spectral transformer backbone. Unlike standard inner-product attention, the methodology normalizes query and key embeddings onto the unit hypersphere before computing their interaction, so attention weights are derived from squared cosine similarity. This operation makes the scoring function sensitive only to the angular orientation between vectors, effectively filtering out magnitude-induced bias and aligning model inductive priors with the spectral angle mapper (SAM) metric widely employed in remote sensing.
The proposed pipeline begins with patch-tokenization of hyperspectral image cubes. Each spatial-spectral patch undergoes linear spectral embedding and spatial positional encoding, which are then fed to a stacked transformer with multi-head cosine-normalized attention modules. Specifically, for each token, attentive interactions between queries and keys are obtained via
q~=∥q∥2q,k~=∥k∥2k
The attention score is computed as the square of their dot product, i.e., (q~⊤k~)2. This process is illustrated geometrically and operationally.
(Figure 1)
Figure 1: Standard dot-product attention (left) vs. cosine-normalized attention (right)—the latter ensures similarity depends only on the angle between query and key embedddings.
The mechanism is further extended to multiple attention variants (cosine/cosine2, dot-product, additive, etc.) and cross-attention formulations. Value aggregation, layer normalization, and regularization are implemented in line with transformer conventions, followed by global average pooling and a linear classifier yielding semantic pixel labels.
(Figure 2)
Figure 2: Overview of the spatial–spectral transformer pipeline with integrated cosine-normalized multi-head attention.
Experimental Results
Quantitative Comparison
Experiments are performed on three widely used hyperspectral datasets (Salinas—SA, WHU_Hi_HongHu—HH, and QUH-Tangdaowan—TD), with a severely limited supervision regime (1% labeled training pixels). The proposed cosine-normalized transformer is benchmarked against state-of-the-art CNNs, transformers, and recent Mamba/state-space models, including MSST, S2CIFT, S2CAT, WaveFormer, Differential Transformer, SSAM, DBMLLA, GraphMamba, and PolicyMamba.
Cosine-based attention achieves consistently superior numerical performance:
- On SA, cross scaled dot-product (C-SDP) and cosine2 (CS2) variants reach up to 99.15% Kappa and 99.23% Overall Accuracy (OA)
- On HH, cosine-based attention tops the Kappa/OA charts (up to 97.64%/98.32%)
- On TD, cosine2 and learnable encoding yield the best results (up to 98.84% OA)
Critically, the classification accuracy of lightweight cosine-normalized models matches or outperforms models of significantly higher architectural complexity.
Qualitative Analysis
Classification maps demonstrate that cosine-normalized attention produces more homogeneous, less noisy semantic segmentations with sharper class boundaries, particularly in spectrally ambiguous regions. This homogeneity and edge preservation are especially apparent when visually compared to baselines on real HSI scenes.
(Figure 3)
Figure 3: Classification maps for Salinas (SA), depicting ground truth and model outputs for transformer, Mamba-style, and proposed cosine-normalized attention.
(Figure 4)
Figure 4: Classification maps for QUH-Tangdaowan (TD) following the same protocol.
(Figure 5)
Figure 5: Classification maps for WHU_Hi_HongHu (HH) showing the efficacy of geometric normalization under limited labels.
Feature Space Structure
t-SNE visualization of latent representations further confirms that cosine-normalized attention induces well-separated, compact class clusters, which is indicative of robust, discriminative hyperspectral representations.

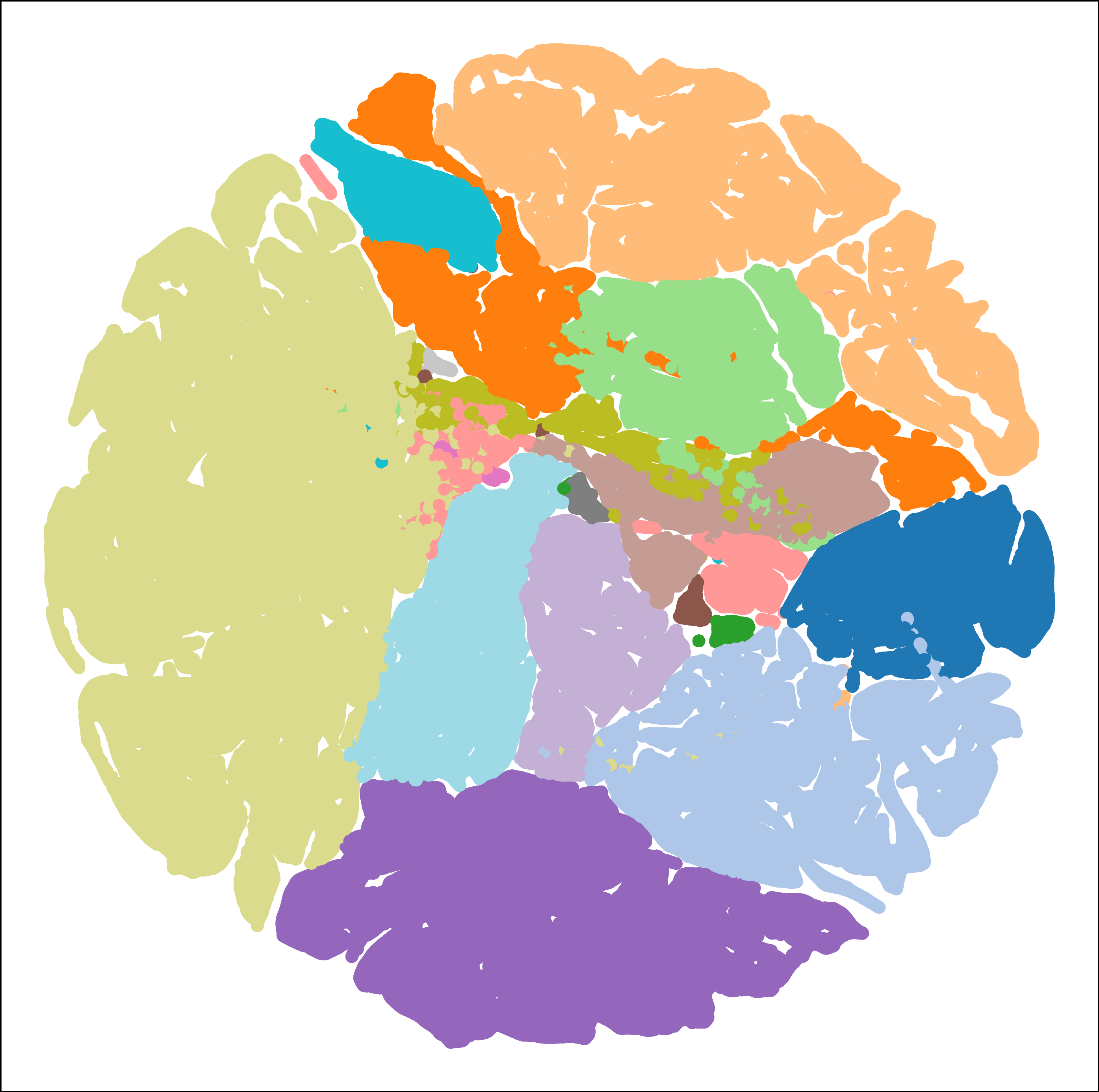
Figure 6: t-SNE visualization reveals compact and separable class clusters in the feature space induced by cosine-normalized attention.
Ablation and Robustness
Ablation studies disentangle the performance contributions of normalization, squaring strategies, positional embeddings, head number, encoder depth, and embedding dimension. The following is observed:
- ℓ2-normalizing both queries and keys is most effective, supporting the geometric hypothesis.
- Squared cosine similarity offers a softer, yet more discriminative, sharpening of attentional focus relative to linear cosine similarity or absolute value.
- Although architecture hyperparameters tune performance, attention scoring function overwhelmingly determines classification success.
- Cosine-normalized attention exhibits gradual, not catastrophic, degradation when subjected to synthetic spectral noise, demonstrating superior robustness.
Implications and Future Directions
The results substantiate that attention's similarity scoring function is an underappreciated yet dominant inductive bias for HSIC, arguably surpassing network width, depth, or expressivity in importance. Cosine-normalized attention, by privileging angular relationships, is naturally compatible with common hyperspectral analysis practices and is better suited to the vagaries of real-world remote sensing where illumination and sensor noise yield variable vector magnitudes.
Given its lightweight design, this approach is particularly viable for scenarios with limited labeled data and restricted compute budgets. Theoretically, aligning model priors with the geometry of hyperspectral data could improve generalization in even more weakly supervised or self-supervised contexts.
The paper anticipates extensions to:
- Self-supervised and semi-supervised learning regimes
- Scaling to giga-pixel hyperspectral scenes
- Multimodal fusion (e.g., HSI + LiDAR) using geometric attention scores
Conclusion
This work delivers a concrete advance in HSIC by showing that cosine-normalized, angle-centric attention outperforms conventional similarity measures and complex architectural alternatives. Its success points to the necessity of reconsidering attention score design as a central axis of model innovation for remote sensing tasks, rather than a minor implementation detail. This perspective shift opens avenues for geometric deep learning extensions and broader adoption of angularly aligned attention in settings where directionality encodes core semantic information.

