- The paper presents a high-fidelity framework that integrates a 3D dynamic viseme library with a physiologically informed coarticulation model.
- It introduces a sparse linear mapping technique to convert ARKit blendshape digital commands to robot actuation signals for smooth lip motion.
- Experimental validation shows reduced mean absolute jerk and improved Pearson correlation compared to baselines, ensuring natural motion.
Realistic Lip Motion Generation for Human-Robot Interaction: 3D Dynamic Viseme and Coarticulation Modeling
Overview
The paper "Realistic Lip Motion Generation Based on 3D Dynamic Viseme and Coarticulation Modeling for Human-Robot Interaction" (2604.01756) introduces a high-fidelity, computationally efficient framework for speech-driven lip motion in Mandarin-speaking humanoid robots. It leverages a 3D dynamic viseme library coupled with a physiologically informed coarticulation model to overcome limitations present in both classic static viseme approaches and recent end-to-end deep generative models. The framework targets robust deployment on hardware-limited robot platforms, focusing on achieving anthropomorphic motion naturalness, synchronization, and kinematic smoothness with direct mapping to a multi-DoF robotic head.
Lip synchronization is critical for naturalistic HRI; mismatches disrupt multimodal integration and exacerbate the uncanny valley effect. Conventional rule-based phoneme-to-viseme mappings, often built for English, are ill-suited for Mandarin due to its extensive coarticulatory behaviors and syllable complexity. These static approaches lose vital spatiotemporal cues, causing motion discontinuity on physical robots. Data-driven deep models, while powerful, produce 2D outputs mismatched with robotic multi-DoF requirements, lack kinematic interpretability, and are restricted by on-device compute. The authors address these gaps by proposing a structurally-constrained, dynamic, and modular pipeline explicitly modeling Chinese phonology and the nonlinearities of mechanical actuation.
Dynamic 3D Viseme Library Construction
A central innovation is a 3D viseme library adhering to the ARKit blendshape standard, encapsulating temporally-dense motion trajectories (rather than static positions) for 14 core categories aligned with Mandarin phonological structure—derived by many-to-one clustering across 60+ pinyin combinations.
Articulatory dynamics are captured using high-resolution facial motion tracking (TrueDepth IR sensors, ARKit blendshapes). For each viseme, feature trajectories are normalized, denoised, and temporally aligned, then mean-fused to provide canonical cycles preserving both local muscular detail and holistic jaw-lip couplings.
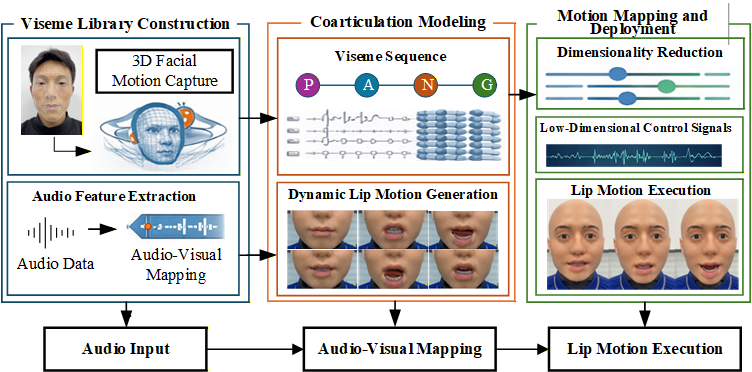
Figure 1: Framework of the lip motion generation system, highlighting pipeline stages from speech input to robot actuation.
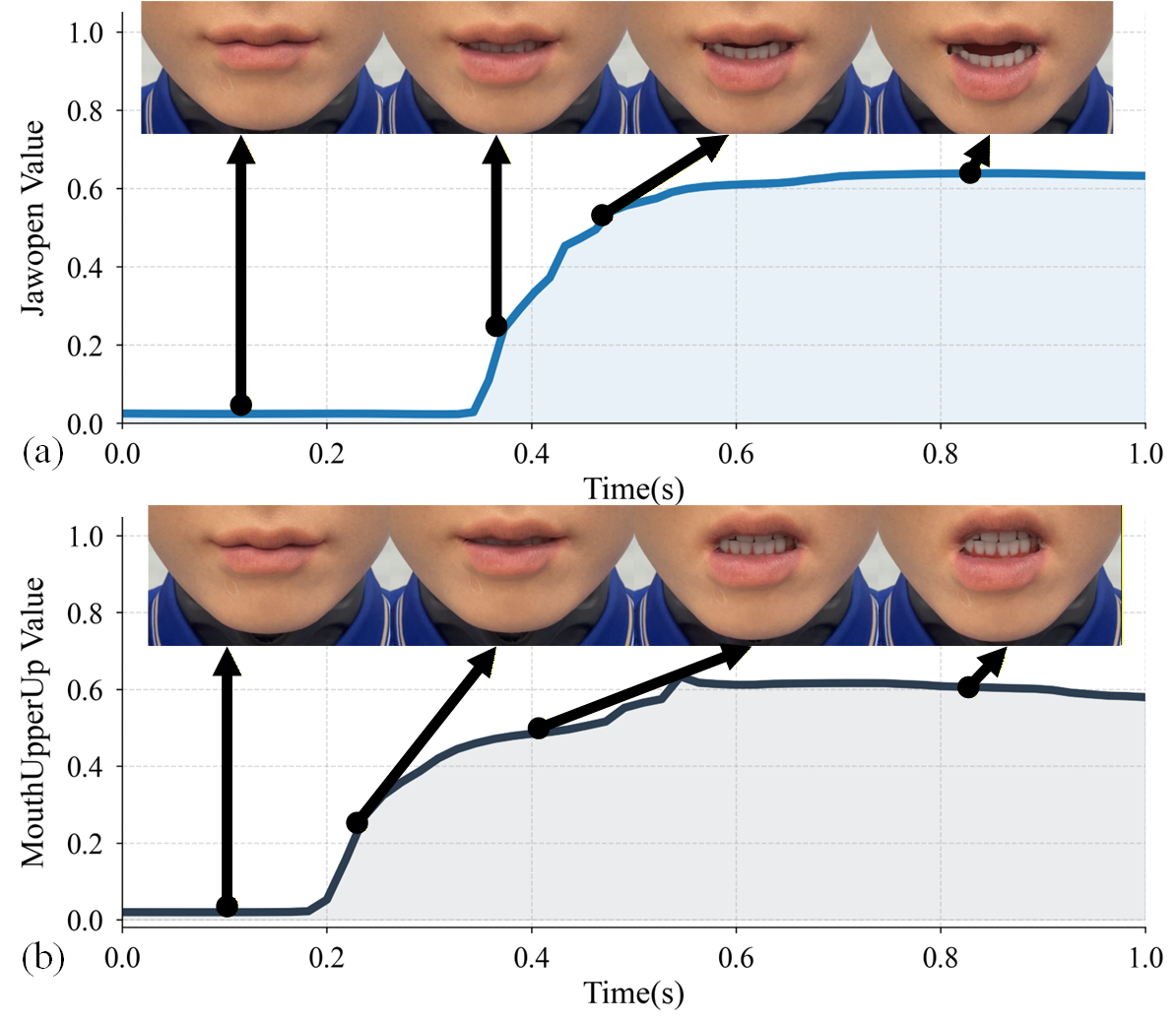
Figure 2: Viseme morphology and parameter dynamics, illustrating differential activation of JawOpen and MouthUpperUp for two representative visemes (bilabial and labiodental).
The resulting library forms the core prior for runtime speech-driven mapping, elevating spatiotemporal continuity and articulation realism over prior discrete-target or linear-interpolated methods.
Coarticulation Modeling
Coarticulation—where pronunciation of an articulatory gesture is conditioned by its phonological context—poses unique challenges, especially in Chinese. The proposed model recognizes Mandarin’s initial-final syllabic decomposition, integrating:
- Initial-final decoupling: For dual-viseme syllables, viseme blending is nonlinear, governed by a temporally modulated weight function w(τ,a) anchored in acoustic observations (e.g., initials typically <20% of duration). An exponential-biased cosine function shapes the transition, physically accommodating actuator latency and preventing visual phoneme omission.
- Compound final handling: For triple-viseme syllables (e.g., initial + compound final), the motion trajectory is explicitly piecewise, maintaining intermediate viseme support and minimizing coarticulatory loss.
These methods operate directly in the high-dimensional blendshape space, ensuring muscularly plausible, rhythmically synchronized transitions.
Digital-to-Mechanical Motion Mapping
The ARKit-based digital command vectors (27D) must be mapped onto the robot’s available DoFs (14). The authors introduce a sparse, linear combination mapping layer, with calibration completed via a hybrid process:
- Vision-based facial motion capture supplies initial blendshape-DoF correspondences.
- Manual heuristic tuning compensates for actuator nonlinearity, skin deformation, and linkage slack, maximizing anthropomorphic fidelity and cross-modal alignment.
This strategy resolves critical DOF-mismatch and physical error compensation challenges that plague other digital-to-actuator retargeting schemes.
Experimental Validation
The framework is implemented and evaluated on a humanoid robot platform (14 DoF lips/jaw, 29 DoF total head). The viseme library is constructed via high-frequency ARKit blendshape data acquisition, and comprehensive Mandarin test sentences are selected to maximize phonetic and kinematic variability.
Quantitative evaluation includes ablation (static baseline, dynamic only, coarticulation, with/without amplitude modulation/filtering) using key metrics:
- Mean Absolute Jerk (MAJ): For smoothness; excessive jerk implies visual jitter and potential hardware stress.
- Pearson Correlation Coefficient (PCC): For temporal similarity to ground-truth human articulation.
- Root Mean Square Error (RMSE): For spatial accuracy in jaw-lip trajectories.
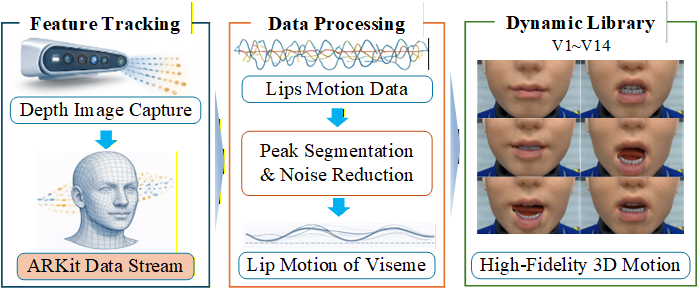
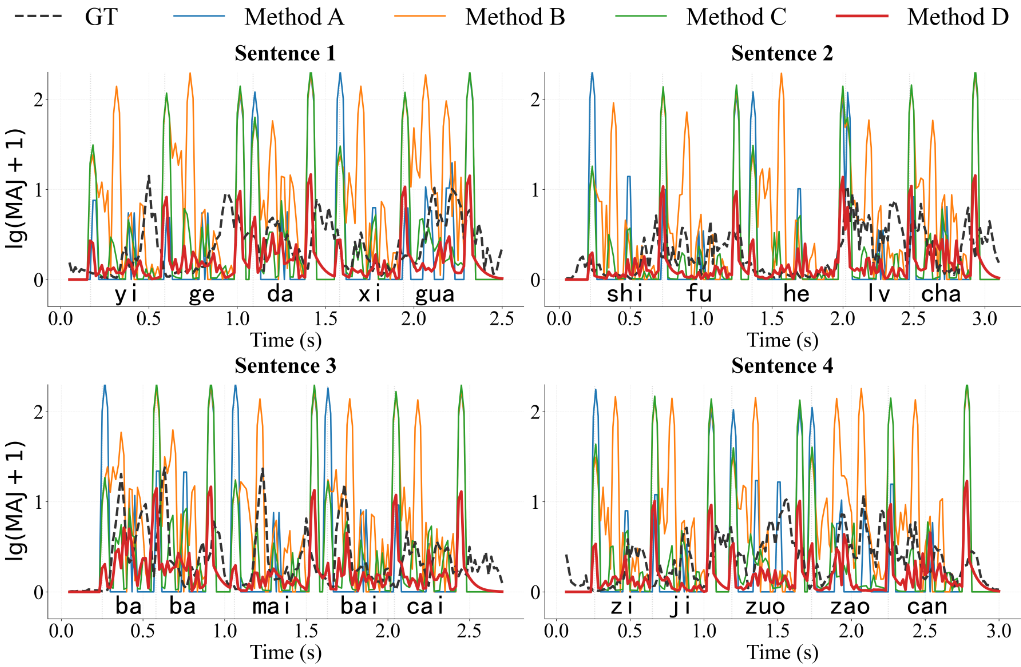
Figure 3: MAJ plots demonstrating the superior motion smoothness of the proposed method, closely tracking human reference, and outperforming all ablations.
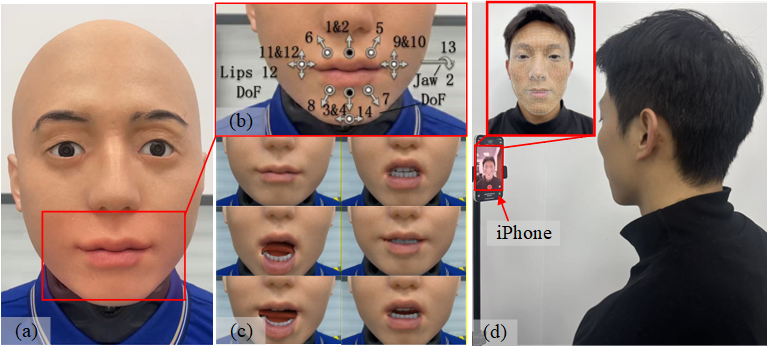
Figure 4: JawOpen parameter trajectories, evidencing both macro-rhythmic fidelity (PCC) and amplitude accuracy (RMSE) against ground-truth.
Notable findings include:
Theoretical and Practical Implications
The study systematically demonstrates that physically informed, modular frameworks combining 3D dynamic viseme execution with task-specific coarticulation modeling are crucial for robust, natural HRI lip synchronization—far outpacing both static mapping and uninterpretable end-to-end models for real-world robotics.
The fully transparent pipeline enables expert tuning at the algorithm→mechanism boundary, facilitating direct transfer and cross-lingual/emotional upgrades. Computational efficiency is maintained throughout, obviating the need for GPU-based inference, which is instrumental for embedded/edge deployment.
Beyond lip motion, the approach provides a foundation for full-face anthropomorphic synthesis. Integrating LLM-driven audio-semantic conditioning and employing reinforcement learning for adaptive calibration point to plausible future extensions, paving the way for scalable HRI interfaces in multi-lingual, multi-expressive robotic systems.
Conclusion
The proposed framework establishes a practical standard for deployable, high-fidelity, and kinematically-sound lip motion generation on humanoid robots interacting in Mandarin. Through physiologically-aligned 3D dynamic visemes, explicit coarticulation modeling, and hybrid digital-mechanical mapping, it achieves unprecedented smoothness, temporal synchrony, and anthropomorphic plausibility under hardware constraints. The paradigm and open-source asset contributions (library, videos) are expected to catalyze further development in HRI, full-face animation, and cross-lingual robotic expression domains.