- The paper demonstrates that claim verification datasets mainly test direct evidence extraction, masking deficiencies in multi-step and compositional reasoning.
- It employs a large-scale reasoning trace generation and a six-category taxonomy to analyze performance variations across different datasets.
- The error analysis uncovers domain-specific weaknesses, urging improved benchmarks with adversarial examples and numerical synthesis challenges.
Systematic Reasoning Analysis of Claim Verification Benchmarks
Introduction and Motivation
The proliferation of claim verification datasets, such as LLMAggreFact, SciFact, and FEVER, has been instrumental in measuring progress for fact-checking systems and trustworthy LLMs. However, while models have achieved high performance on these benchmarks, persistent failures are observed in real-world scenarios, particularly for claims that necessitate multi-step reasoning, compositional logic, or numerical computation. This paper provides a comprehensive empirical study of the kinds of reasoning that current claim verification datasets actually exercise, leveraging large-scale trace generation, a detailed taxonomy of reasoning patterns, and a multi-domain error analysis.
Reasoning Trace Generation and Taxonomy
The authors generate structured reasoning traces for 30.4K claim-verification pairs across nine datasets, filtering to 24.1K examples after consistency checks. Manual annotation over a 1,000-sample stratified subset yields a six-category taxonomy:
- Direct evidence extraction: identifying explicit support/contradiction via string or paraphrase matches.
- Handling nuance/implication: inferring support from contextual or partial evidence.
- Absence of evidence identification: asserting that the document does not provide the required information.
- Synthesis of multiple information points: integrating evidence from disparate sentences or sections.
- Scope/specificity mismatches: claims that go beyond or add specificity not present in the source.
- Step-by-step verification: procedural or sequential checks.
A quantitative breakdown shows a heavy dominance of direct extraction, consistent across the combined datasets (Figure 1), with other categories underrepresented.
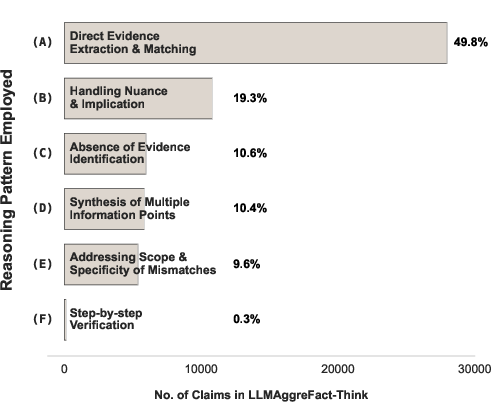
Figure 1: Distribution of reasoning patterns across 24.1K claim verification traces, with direct evidence extraction accounting for the majority.
Dataset-Level Variation in Reasoning Demands
The analysis reveals that the dominance of direct surface matching is not uniform; reasoning pattern prevalence varies significantly by dataset. For example, AggreFact-CNN requires information synthesis for roughly half the examples, whereas datasets like FactCheck-GPT and Wice exhibit more nuanced patterns such as scope and specificity mismatches, or higher rates of evidence absence identification. Multi-step and compositional reasoning remains exceedingly rare across all datasets, even in those designed for scientific or mathematical claims.
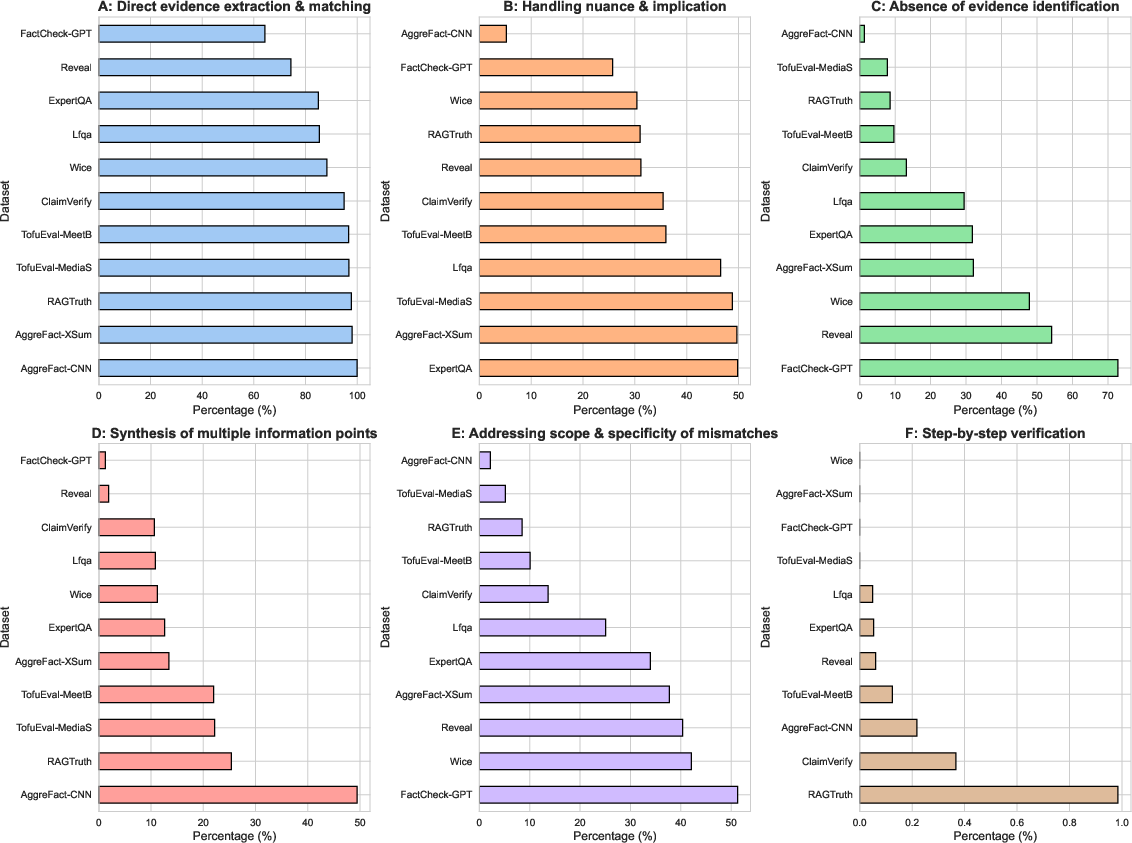
Figure 2: Heterogeneous distribution of reasoning strategies across constituent datasets in LLMAggreFact; different sources elicit different types and prevalence of reasoning.
Error Analysis with a Compact Reasoning Verifier
To probe model weaknesses, the authors introduce ClaimTrace, a 1B-parameter fine-tuned reasoning verifier, and systematically profile its error types across general, scientific, and mathematical domains. Five principal error categories are identified:
- Lexical overlap bias: superficial textual similarity leads to false positives.
- Insufficient aggregation: inability to synthesize across multiple evidence points.
- Negation/temporal confusion: mishandling of negations and temporal reasoning.
- Overcautiousness: under-prediction due to over-reliance on explicit evidence.
- Hallucinated justification: unsupported or confidently incorrect explanations.
- Arithmetic reasoning failure: (math domain only) inability to execute correct computations.
The prevalence of error types is strongly domain-dependent; for example, lexical overlap dominates general benchmarks, overcautiousness is predominant in scientific data, and arithmetic errors are primary for mathematical tasks. Importantly, the paper demonstrates that standard claim verification datasets under-test precisely those reasoning skills where models are weakest.
Implications for Benchmark Design and Evaluation
The findings drive several critical conclusions:
- Current benchmarks primarily test retrieval-plus-entailment: Models excel if they can adequately match spans in the evidence document, but this does not necessarily translate to robust claim verification in real-world settings.
- Complex reasoning and numerical synthesis are underrepresented: Multi-sentence synthesis and step-wise or numerical reasoning are exceedingly rare, allowing models to perform well without such competencies.
- Error distributions are domain- and dataset-specific: No single error mitigation improves generalization across all claims due to underlying structural biases in dataset construction.
Consequently, the authors urge the community to pursue adversarial dataset construction to target lexical overlap, include multi-hop and numerical reasoning challenges, and adopt domain- and reasoning-stratified reporting.
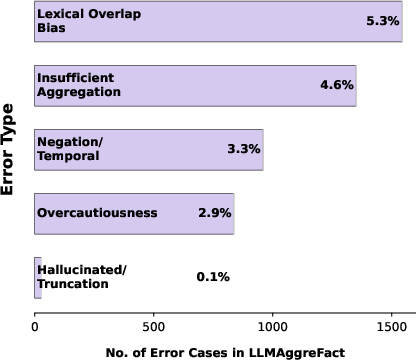

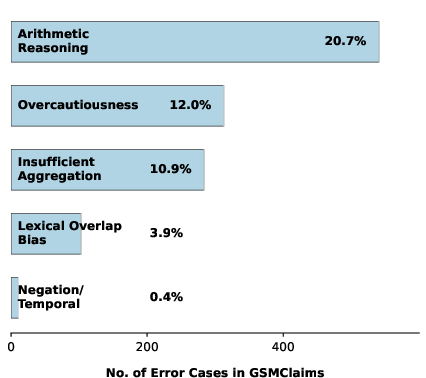
Figure 3: LLMAggreFact dataset composition and flow, reflecting diversity but with dominant simplification biases in reasoning demands.
Future Directions
The results suggest crucial changes for future benchmark and model design, including:
- Adversarial and adversarially mined datasets to prevent surface cue exploitation.
- Increased representation of deeply compositional, multi-step, and numerical claims.
- Per-domain evaluation metrics to expose hidden weaknesses.
- Finer-grained evaluation labels beyond binary support/refute, enabling richer model assessment.
Conclusion
This large-scale, systematic analysis reveals that benchmark performance in claim verification tasks is most reflective of retrieval and text matching rather than genuine reasoning or verification capacity. As such, progress reported on current benchmarks risks overestimating the robustness and generality of deployed systems. Improved datasets and evaluation methodologies—emphasizing multi-step, compositional, and numerical reasoning—are essential to drive development of models that are more reliable in real-world factuality assessment.