- The paper introduces an influence-guided PPO framework that uses data attribution to filter out harmful rollouts, enhancing model alignment and sample efficiency.
- It employs a gradient dot product between episode gradients and a reference validation gradient to dynamically weight and remove anti-aligned trajectories.
- Empirical results across various LLM scales demonstrate reduced training cost and improved confidence calibration in challenging reasoning benchmarks.
Influence-Guided PPO: Data Attribution for Efficient and Faithful LLM Post-Training
Motivation and Background
Recent advances in LLM optimization reveal the limitations of naively applying RL algorithms, in particular standard Proximal Policy Optimization (PPO), during post-training. Traditional PPO assumes all self-generated episode trajectories within the rollout buffer are equally suited for updating the policy, a supposition that is invalidated by the high prevalence of noisy or unfaithful reasoning in LLM generations. This noise not only hinders alignment with intended reasoning targets but also introduces sample inefficiency, redundant gradient noise, and computational overhead. The paper "Learning from the Right Rollouts: Data Attribution for PPO-based LLM Post-Training" (2604.01597) addresses these issues by integrating per-trajectory data attribution into PPO, actively filtering harmful or redundant episodes from the optimization pipeline.
Influence-Guided PPO Framework
The central idea is to decouple episode generation from its influence on the downstream update, leveraging data attribution to calculate an influence score for each episode. The architecture contrasts directly with conventional PPO (Figure 1): whereas PPO uses the entire rollout buffer, the proposed Influence-Guided PPO (I-PPO) applies a scoring filter, excising episodes anti-aligned with validation gradients.
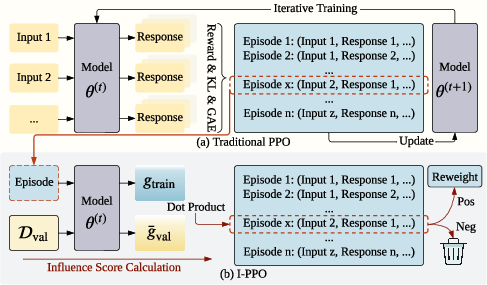
Figure 1: Overview of I-PPO—policy rollouts are refined via influence attribution, negative-influence episodes are eliminated, and only positive-contributing data influence the policy update.
Concretely, the method computes, for each episode zi, the directional dot product of the actor PPO gradient ∇θLPPO(zi) and a reference validation gradient derived from SFT-like supervised loss on a human-preferred validation set. Episodes with negative dot product—i.e., those that would move the policy further from alignment with the ground truth—are omitted from PPO updates. Beyond binary filtering, influence scores are normalized and used as scalar weights for the surrogate loss, ensuring more informative samples directly drive optimization dynamics.
Theoretical Foundations and Implementation
The design leverages a gradient-attribution paradigm in the RL context, inspired by TracIn and scalable attribution approximations. The pipeline proceeds as follows:
- Rollout Collection: For each prompt, multiple diverse CoT responses are generated. Each episode records the prompt, response, reward, and the set of policy and value network related statistics.
- Reference Direction: The validation gradient is computed using average SFT loss on a held-out set of high-quality examples.
- Influence Score Calculation: Each candidate episode’s influence score is the dot product of its PPO gradient and the reference gradient.
- Dynamic Filtering and Reweighting: Negative influence episodes are dropped; the remaining are weighted by normalized influence before backpropagation within PPO.
This method departs fundamentally from recent RLHF or outcome-based reward methods by using a training-free, process-level reward signal that is agnostic to the episode’s final outcome, directly targeting the gradient-level effect on model generalization.
Empirical Results and Analysis
Data Efficiency and Convergence
Experiments were conducted across substantial reasoning domains (mathematical, science, commonsense) using a diverse portfolio of SFT LLMs (Rho-1B, Gemma-2-2B, Qwen2.5-3B, Phi-3-4B, LLaMA-3-8B). Performance is consistently superior to SFT and vanilla PPO across Majority Vote, Exact Match, and Pass@K, with improvements most notable in sample efficiency and confidence calibration, as opposed to raw upper-bound accuracy (Pass@K). The dynamic buffer pruning property of I-PPO manifests in reduced wall-clock training times, as evidenced by the per-step cost decreasing throughout optimization (Figure 2).
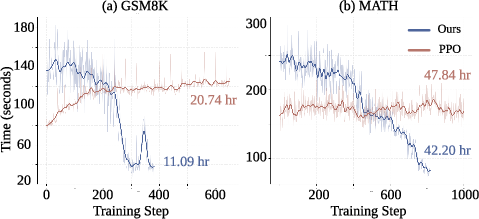
Figure 2: Per-step training cost for I-PPO decreases as filtering intensifies, leading to significant total training time reduction.
Histograms of influence scores (Figures 4, 5) show that as optimization progresses, the distribution shifts from positive and wide to sharply peaked at zero or negative values. This reflects the model’s convergence, at which point the majority of additional rollouts offer minimal or negative alignment value and are pruned.
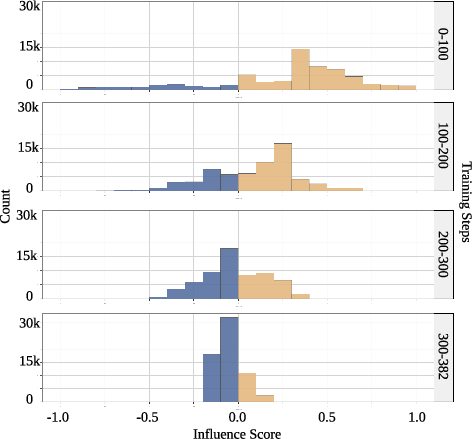
Figure 3: Influence score distributions on GSM8K reveal the transition from positive to mostly negative scores as learning saturates.
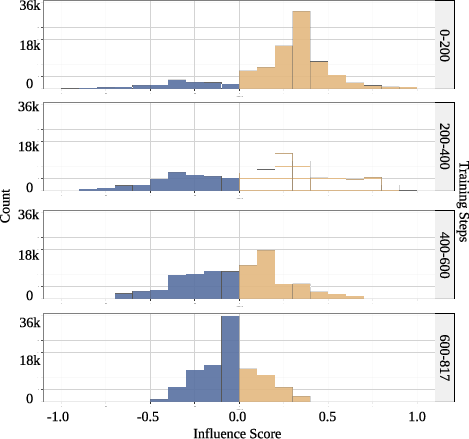
Figure 4: On the MATH dataset, a similar shift in influence scores is observed, indicating efficient rollout pruning upon convergence.
Reasoning Analysis and Faithfulness
A qualitative and mechanistic evaluation demonstrates that I-PPO’s attribution system preferentially filters episodes with unfaithful or post-hoc reasoning, even when the final answer is correct. Three major undesirable patterns—false positives (logical errors by coincidence), nonsensical reasoning, and reasoning shortcuts—appear at higher rates in filtered-out trajectories (negative influence episodes), as verified by LLM-based and human rater analysis.
A sparse autoencoder analysis reveals that positive-influence episodes are tightly associated with explicit, step-by-step, procedural arithmetic, while negative-influence episodes correspond to shortcuts, inconsistent logic, or systematic errors.
Reweighting Ablation
The reweighting mechanism (using scalar influence as sample weight rather than only performing binary filtering) yields further nontrivial improvements across datasets and scale regimes, as summarized in ablation studies (Figure 5, Figure 6).
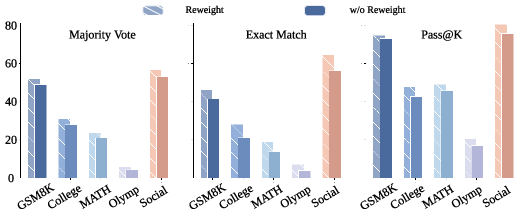
Figure 5: Reweighting with influence scores, compared to binary filtering, yields consistent gains across all reasoning benchmarks using Rho-1B.
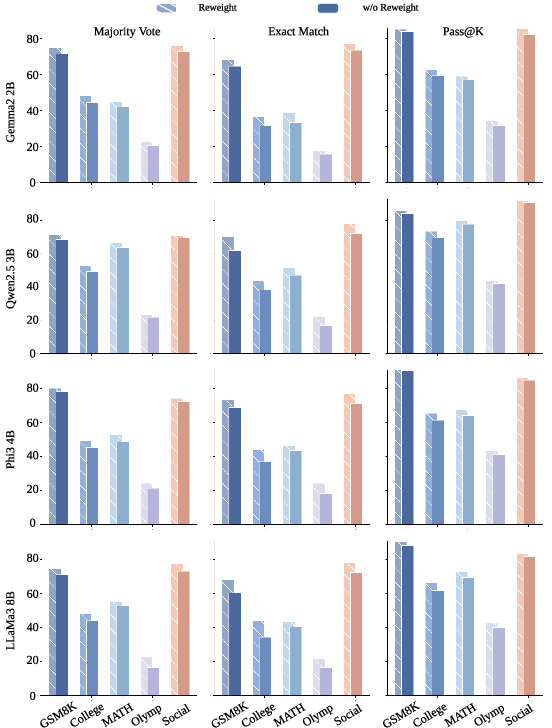
Figure 6: Ablation results on larger models confirm the necessity of reweighting—across metrics, not reweighting degrades alignment and reliability.
Implications and Future Directions
This work represents a transition from indistinguishable, reward-centric RL fine-tuning to trajectory-level intervention, wherein only those rollouts empirically shown (on the model’s updates) to facilitate alignment with preferred validation logic are utilized. The approach introduces an intrinsic, adaptive early stopping effect and significantly reduces computational cost via aggressive pruning of low-value optimization data.
Practical ramifications include sample-efficient RL alignment for LLMs, robust suppression of “spurious reasoning” exploitation, and readiness for deployment in time/compute-sensitive RLHF pipelines. From a theoretical perspective, the framework champions the use of local attribution signals as process-based reward functions, opening new research in attribution-driven RL, gradient-level distillation, and introspective filtering policies.
Open problems include developing validation-set construction strategies robust to noise (since data attribution is only as effective as the alignment signal from the reference set), extending the method to multi-agent or open-ended environments, and integrating data attribution with token-level interventions or explainability diagnostics. Further, there is natural synergy between influence-guided rollouts and curriculum learning schemes, potentially enabling adaptive reasoning curricula in unsupervised RL settings.
Conclusion
I-PPO demonstrates that integrating scalable data attribution with PPO yields consistent improvements in performance, sample efficiency, and output faithfulness for LLM post-training. By eliminating harmful and non-aligned episodes upfront via influence scoring, the framework steers policy optimization towards faithful reasoning, reduces computational cost, and serves as a blueprint for future LLM RL research predicated on explicit, informative trajectory attribution.