- The paper establishes that synchronous update policies with time-multiplexed p-bit reuse reduce hardware cost while maintaining or improving solution quality.
- It demonstrates that asynchronous updates suffer performance degradation as hardware delay nears the update interval, especially under low DAC precision.
- The study provides a unified framework linking architectural parameters, enabling scalable design for combinatorial optimization in p-bit Ising machines.
Architectural Principles and Motivation
The paper "A Unified Performance-Cost Landscape of Parallel p-bit Ising Machines Based on Update Dynamics" (2604.01564) presents a comprehensive architectural study on parallel p-bit networks for combinatorial optimization, focusing on Ising machine implementations. The authors systematically dissect synchronous and asynchronous update policies within resource-constrained hardware, explicitly modeling practical constraints: finite hardware delay, time-multiplexed p-bit reuse, and limited input DAC precision. By defining and analyzing a unified landscape that links solution quality and normalized hardware cost, the study provides an actionable framework for designing large-scale probabilistic hardware systems.
Probabilistic spin logic using p-bits enables Boltzmann sampling and optimization with highly parallel operations, leveraging intrinsic device stochasticity, especially in nanosecond-range MTJ-based p-bits. Scalability, however, hinges on update mechanisms and the physical mapping between logical units and hardware resources. The trade-offs between update synchronization, hardware timing, and cost have not been exhaustively characterized prior to this work.
The core contribution is the explicit construction of a global performance–cost landscape. This is achieved by sweeping four key architectural parameters: update policy (synchronous vs. asynchronous), per-spin update interval (τ), time-multiplexing reuse factor (c), and DAC precision (b). Each point in the landscape corresponds to an operating regime, evaluated under standardized simulation schedules on G-set MaxCut benchmarks.
Synchronous architectures with structured control and time-multiplexed reuse (c>1) are shown to access low-cost operating regimes, achieving solution quality comparable to or superior to asynchronous updates while using less than half the normalized hardware cost. This is evident in the global landscape, where the vertical axis quantifies mean normalized cut, and the horizontal axis depicts normalized hardware cost.
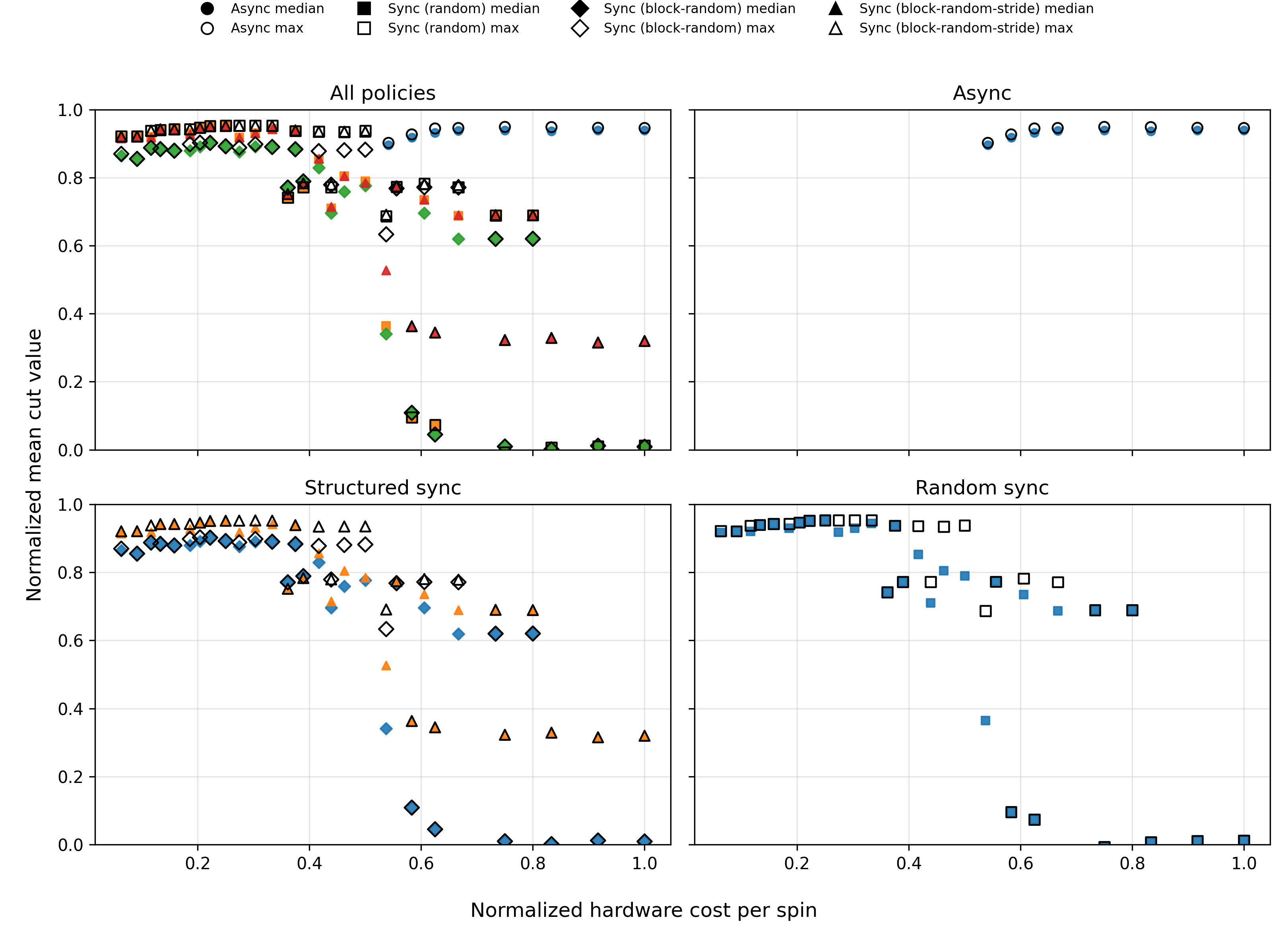
Figure 1: Unified performance–cost landscape for representative operating regimes in parallel p-bit Ising machines across G-set MaxCut benchmarks.
Dynamic Stability and Update Policies
Synchronous Updates: Oscillation and Stabilization
The study reveals that synchronous updates are not inherently unstable, contrary to common assumptions. Rather, instability and coherent energy oscillations arise only when many logical p-bits are updated simultaneously, particularly in strongly coupled graphs. Oscillatory behavior is progressively suppressed as the time-multiplexing reuse factor c increases, reducing per-spin update rate and breaking phase alignment.
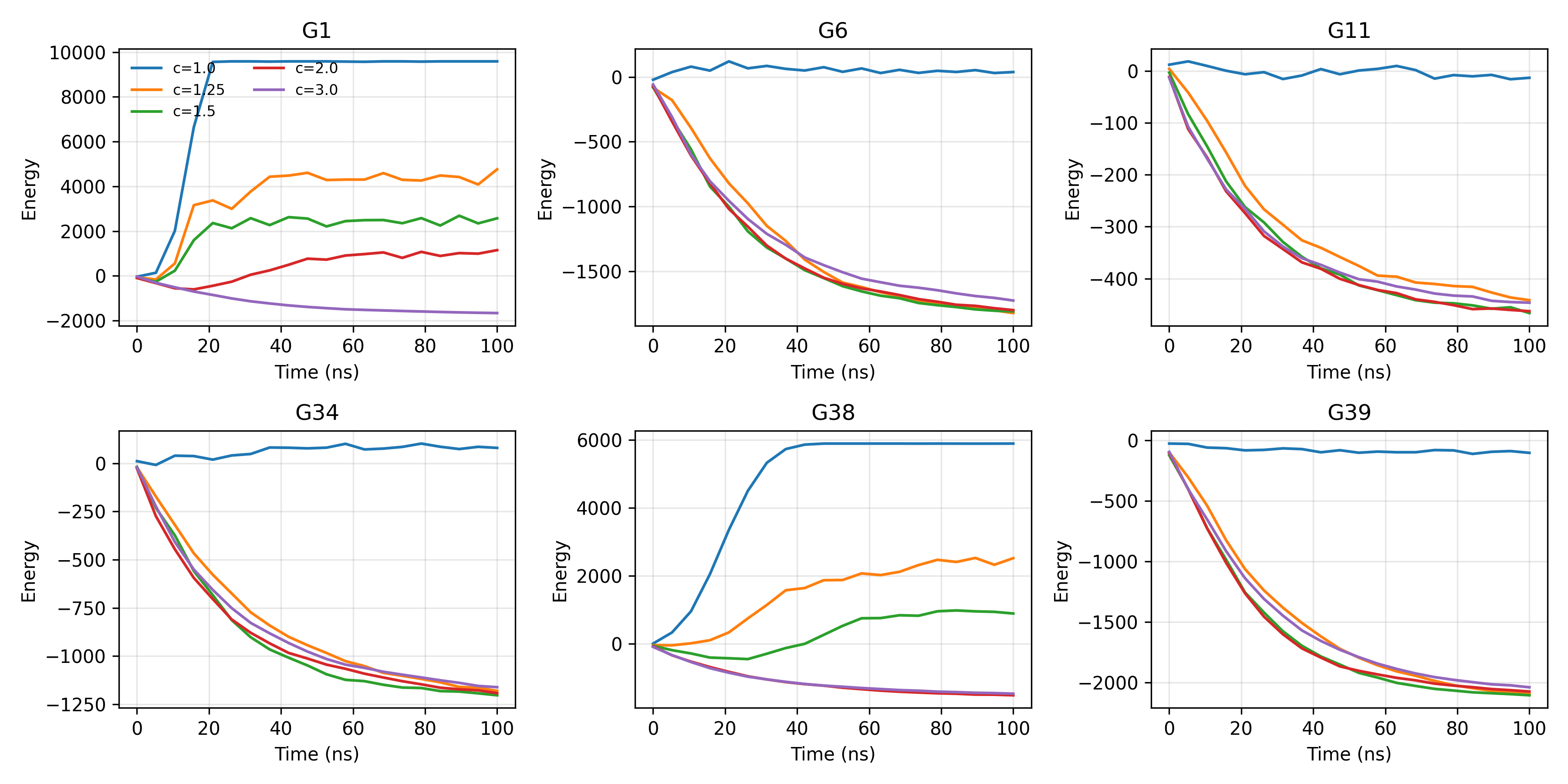
Figure 2: Energy trajectories for synchronous random updates as c increases, highlighting suppression of oscillations.
Asynchronous Updates: Sensitivity to Hardware Delay
Asynchronous (Gillespie-type) updates offer natural desynchronization but are sensitive to the ratio of hardware delay (d) to update interval (τ). As this ratio approaches unity, significant performance degradation is observed, due to spins acting on stale local fields—an effect exacerbated under low DAC resolution. This structurally constrains asynchronous architectures, forcing lower update rates to maintain stability.
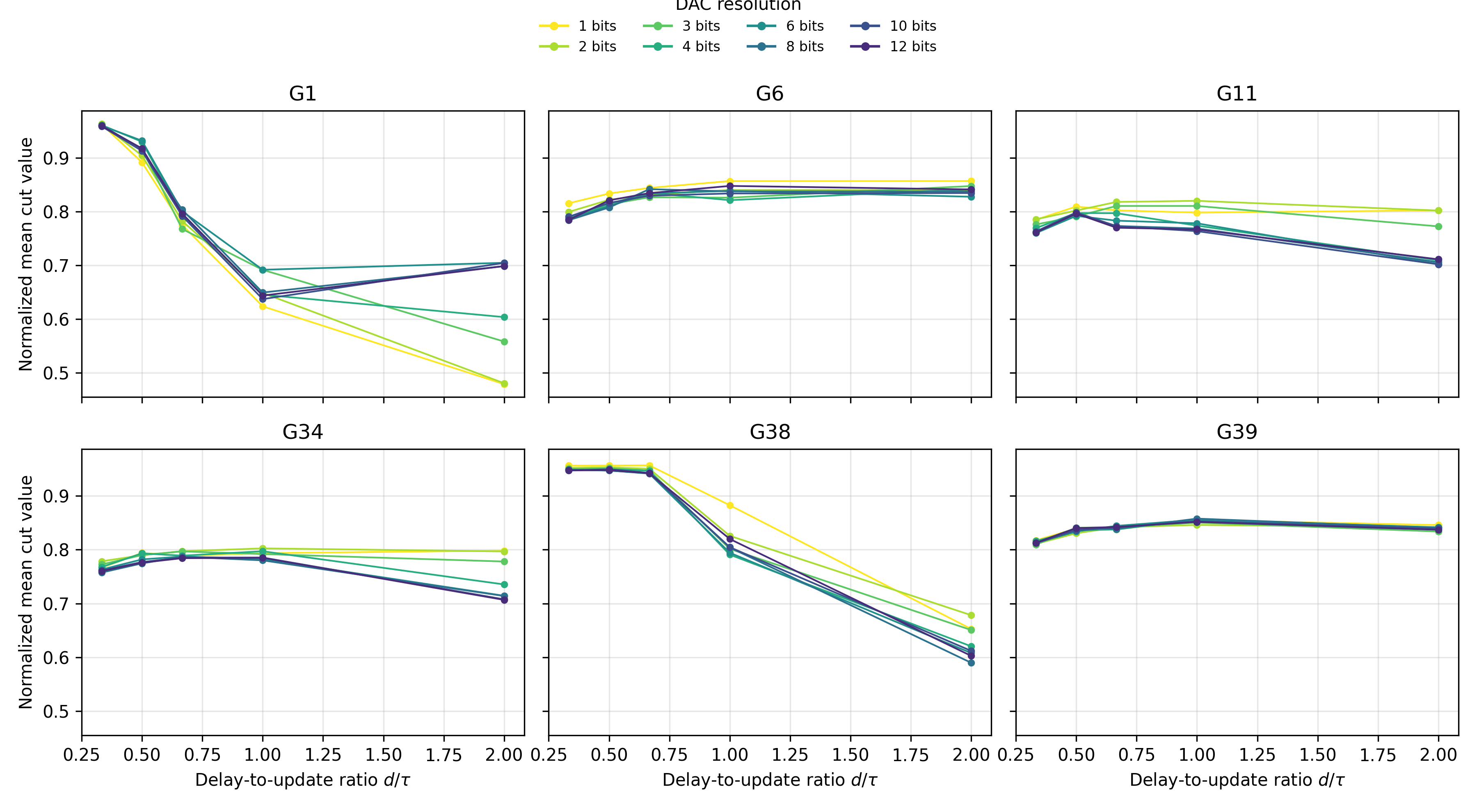
Figure 3: Degradation in normalized cut for asynchronous updates as delay-to-update ratio increases, with heightened sensitivity at low DAC precision.
Structured Synchronous Control Policies
Structured synchronous control (block-random, block-random-stride) mitigates harmful correlations with minimal randomization, preserving memory access locality and hardware efficiency. These policies attain similar or higher performance compared to fully random masking, while tolerating lower DAC bit widths.
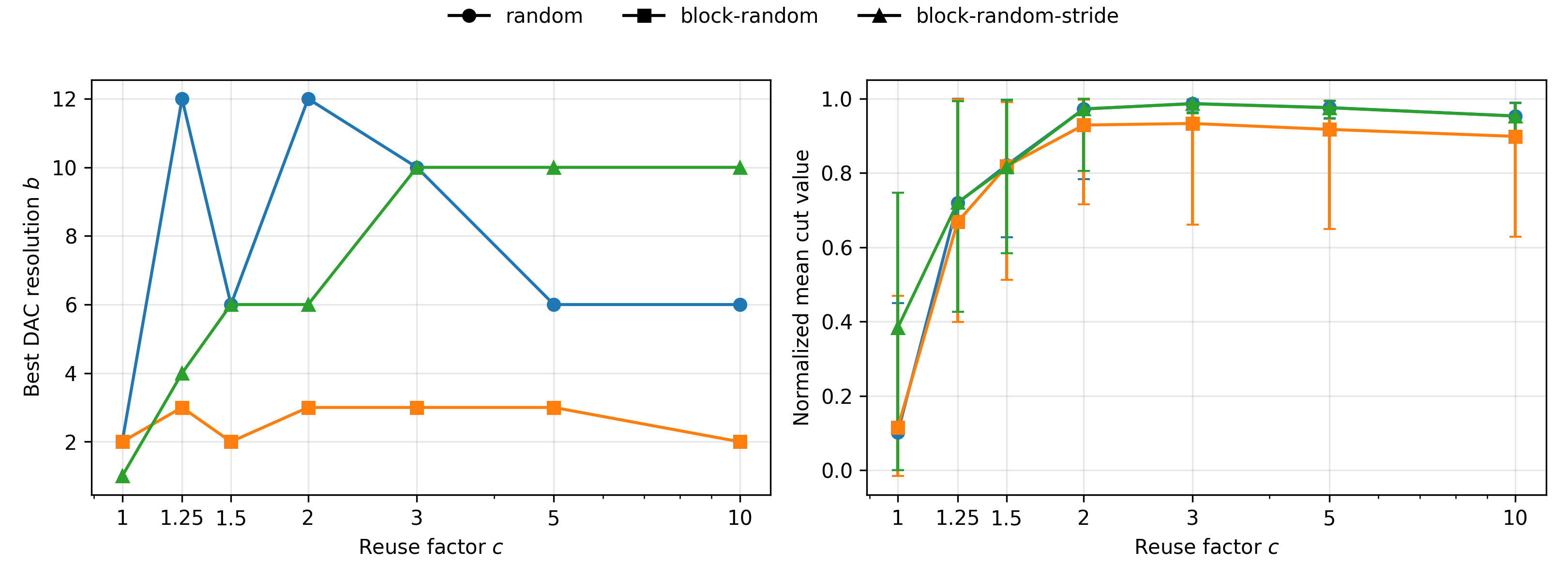
Figure 4: Comparison of optimal DAC resolutions and mean normalized cuts for various synchronous update policies across reuse factors.
DAC Precision, Annealing Time, and Time-Multiplexing
The results demonstrate that low-resolution DACs (3–4 bits) can achieve normalized cut values above 0.95 when annealing time is moderately increased. Synchronous policies, particularly with time-multiplexed reuse (c≥3), exhibit smoother degradation curves and superior tolerance to coarse quantization.
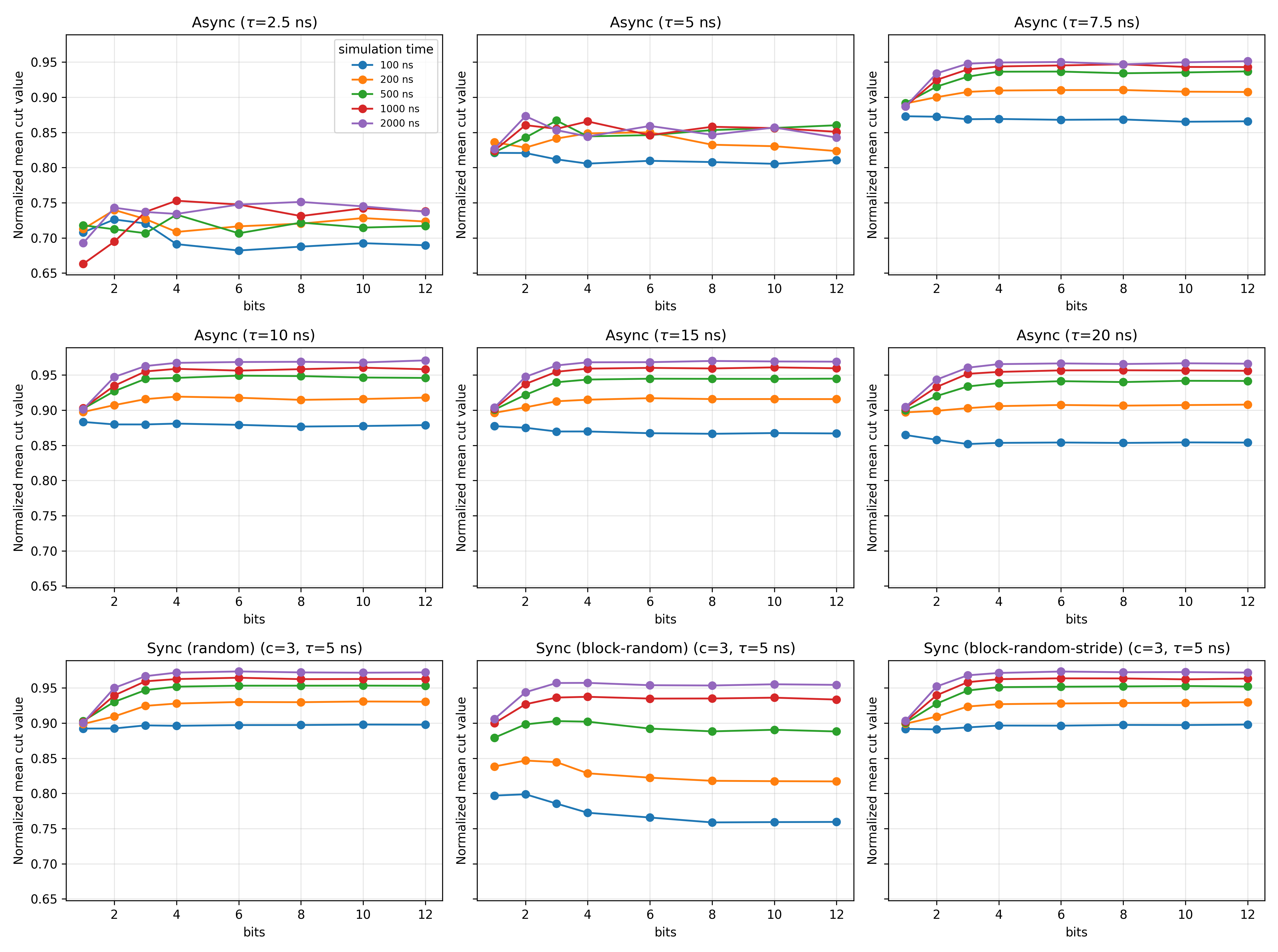
Figure 5: Dependence of normalized cut on DAC resolution and annealing time for both synchronous and asynchronous update schemes.
Algorithmic Reference and Hardware Constraints
A sequential Gibbs-like baseline outperforms both synchronous and asynchronous parallel modes in normalized cut, but is not practical for large-scale hardware due to prohibitively high clocking requirements for serialized operation. Synchronous settings (block-random-stride, c=3) offer competitive performance under realistic timings.
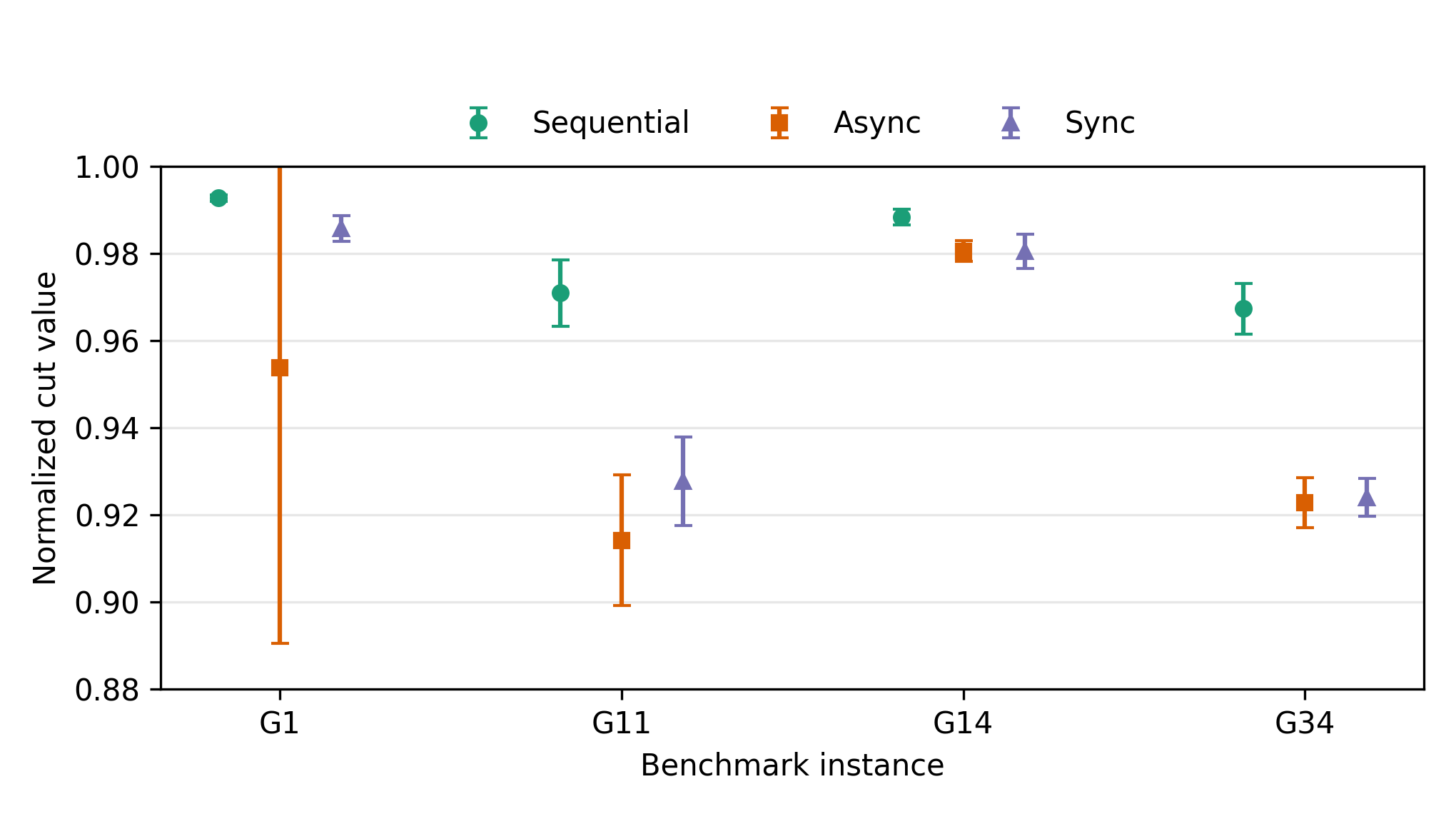
Figure 6: Comparison of representative sequential, asynchronous, and synchronous settings on selected G-set instances.
Hardware cost constraints are further visualized in the cost–latency plane, reinforcing that synchronous architectures can exploit time-multiplexed reuse for substantial cost reductions, inaccessible to asynchronous designs.
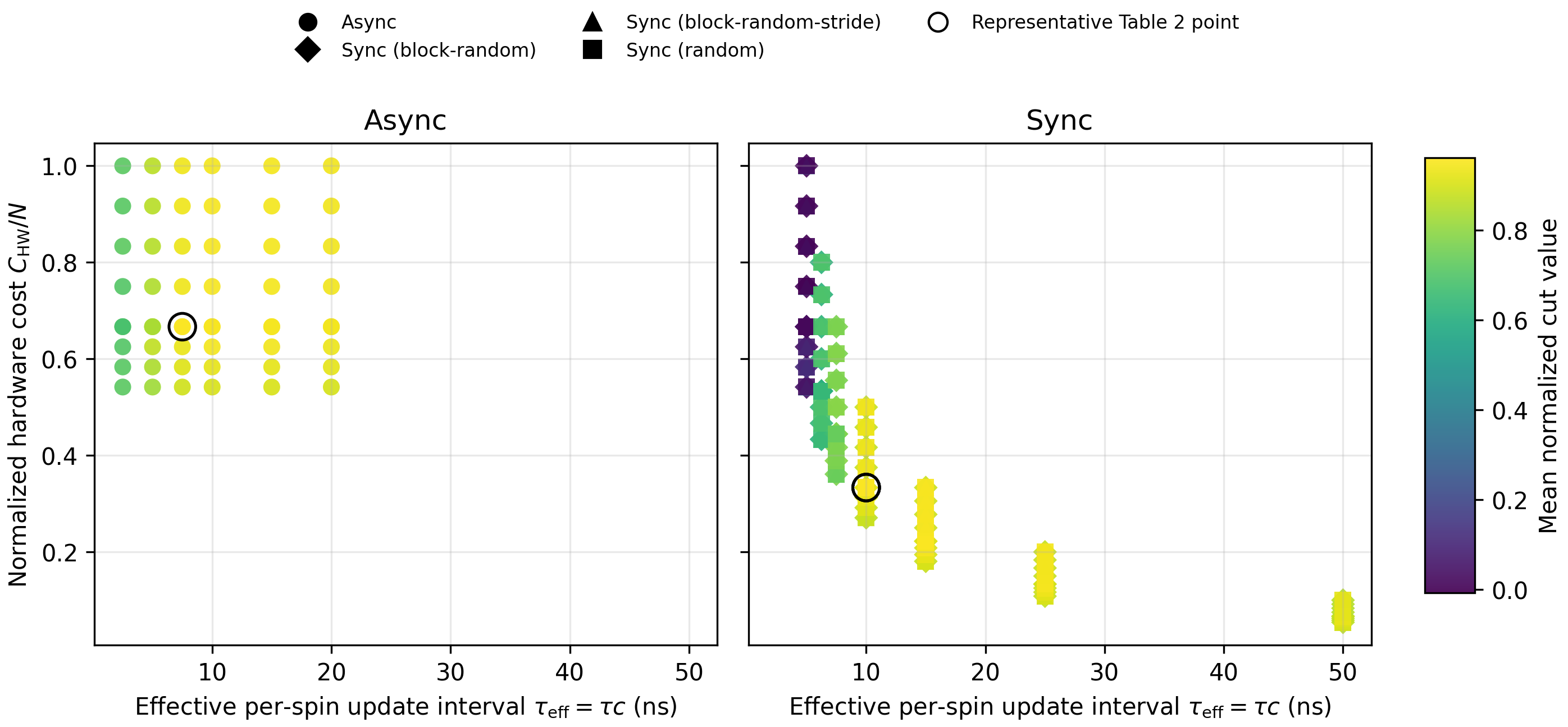
Figure 7: Visualization of effective update interval versus normalized hardware cost for representative synchronous and asynchronous configurations.
Practical and Theoretical Implications
The formal decoupling between statistical correctness and physical resource count enabled by time-multiplexing fundamentally shifts the design paradigm for probabilistic hardware. Synchronous architectures, with explicit scheduling and deterministic control, emerge as the preferred path for scalable p-bit Ising machines—achieving efficiency via coordinated updates and structured memory access, while tolerating low precision without bias.
The results also generalize to emerging DAC-free p-bit architectures, where stochastic control and self-coloring are realized through digital delay modulation. The landscape sets a foundation for system-level design with resource-flexible mapping, applicable to both optimization and probabilistic inference tasks.
The limitations of abstract cost modeling and the absence of device-level variability analysis suggest future directions: extending the landscape to capture technology-dependent noise, power, and area; and investigating the impact of large-scale interconnect and bandwidth constraints.
Conclusion
This paper rigorously establishes that coordinated time-multiplexed p-bit reuse, combined with structured synchronous control policies, is the principal architectural lever for scalable, efficient probabilistic Ising machines. Synchronous architectures dominate the performance–cost frontier, tolerating hardware delays and quantization, while asynchronous designs remain fundamentally constrained. These findings provide both practical design guidelines and theoretical insights for the development and scaling of domain-specific p-bit accelerators in combinatorial optimization.