- The paper introduces a role-specialized LLM framework that decomposes information extraction into domain-specific roles for policy analysts, legal specialists, and food system experts.
- The methodology achieves significant accuracy gains, notably raising legal strategy extraction to 44.16% exact-match and enhancing multi-label food system classification.
- The approach offers a scalable and interpretable automation solution for complex health policy texts, addressing challenges like misclassification and hallucination.
Introduction
LLMs such as Llama-3-3-70B and Qwen-3-80B hold potential for automating information extraction (IE) from unstructured health policy texts, but commonly exhibit misclassification, omissions, and hallucinations due to the structural heterogeneity and semantic ambiguity present in policy documents. The paper "A Role-Based LLM Framework for Structured Information Extraction from Healthy Food Policies" (2604.01529) addresses these challenges by introducing a prompt-based, role-specialized methodology targeting U.S. healthy food policy data. Unlike resource-intensive agent-based or fine-tuning approaches, this framework decomposes IE into domain-expert roles with explicit, structured guidance, achieving high precision and interpretability without sacrificing deployment efficiency.
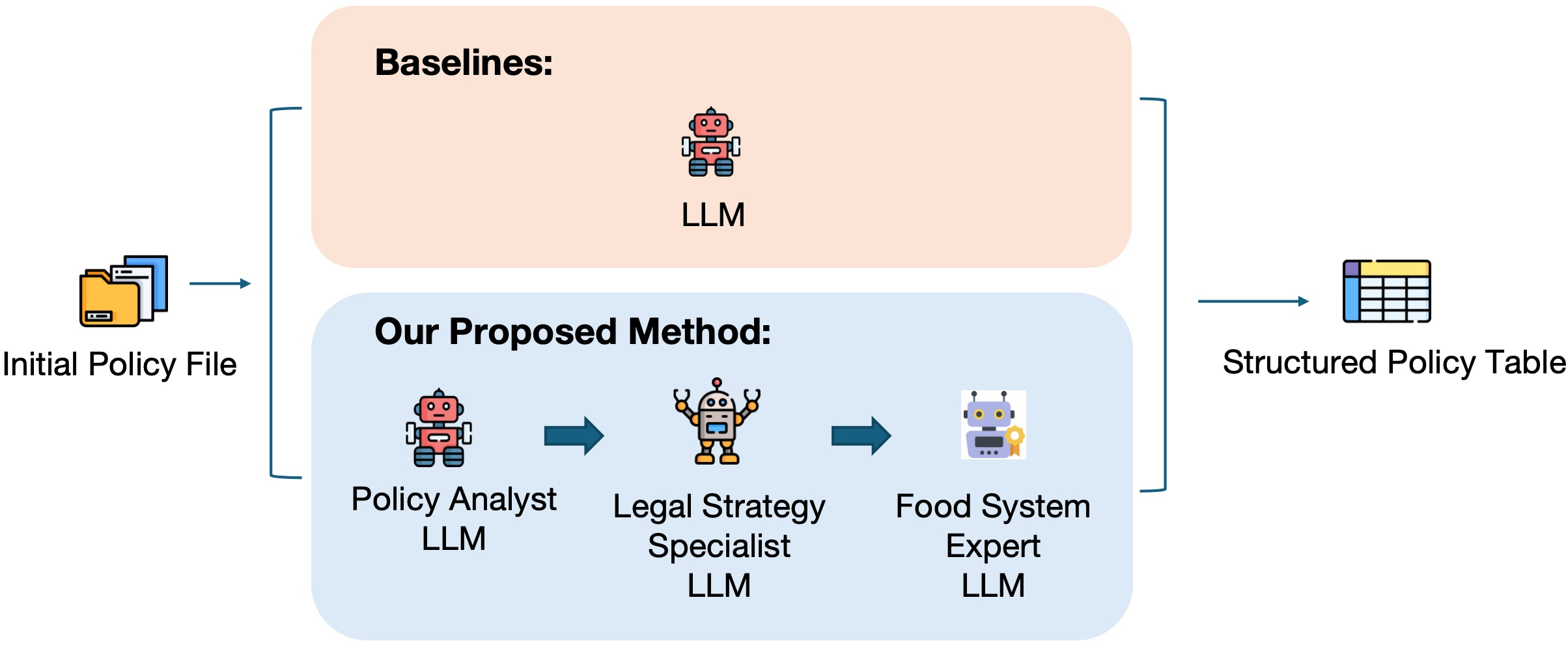
Figure 1: The role-based LLM framework for structured information extraction from healthy food policies, demonstrating the decomposition into Policy Analyst, Legal Strategy Specialist, and Food System Expert roles.
Traditional IE in health policy relies on narrow rule-based systems or supervised ML architectures with rigid schemas, which do not scale to diverse and evolving document distributions. Prompt-based LLM approaches (zero-shot, few-shot, chain-of-thought) have gained traction for their flexible deployment but frequently underperform in complex, multidimensional extraction tasks due to lack of structured reasoning and explicit domain constraints. LLM hallucinations, particularly in dense legal and policy text, are a well-documented concern, leading to unreliable outputs in downstream analytic workflows ji2023towards mustafa2025large. Recent LLM-IE advances have explored modularity (e.g., retrieval augmentation [liu2023improving, xu2025mega]) but have not systematically leveraged role-based task decomposition with domain-specific prompting in the policy context.
Methodology
The core contribution is a three-role LLM-based pipeline, each role realized via a domain-calibrated prompt. This structured modularization is designed to mimic the multi-dimensional analytic process used by human policy experts and produces robust JSON-formatted outputs across varied attribute types.
Role Decomposition
- Policy Analyst: Extracts surface-level metadata (state, enactment year, legal mechanism classification). The prompt provides taxonomy definitions (Administrative Rule, Law, Executive Order, Other) and decision criteria for each.

Figure 2: Prompt formulation for the LLM Policy Analyst, including explicit legal taxonomy and output structure instructions.
- Legal Strategy Specialist: Identifies up to two legal strategies from a controlled set of seven, focusing on regulatory levers (e.g., funding streams, exemptions, incentives, permissions, prohibitions, educational initiatives, requirements/standards). The prompt enforces strict assignment of strategies only when clearly evidenced, reducing hallucinations and ambiguous label drift.

Figure 3: Domain-specific Legal Strategy Specialist prompt, emphasizing explicit definitions and constraints for legal strategy identification.
- Food System Expert: Classifies each policy's impact stage within the food system using binary indicators (Grow, Process, Distribute, Get, Make, Surplus). The prompt provides granular definitions to constrain semantic boundaries and ensure inter-annotator consistency.

Figure 4: Prompt for LLM Food System Expert role, mapping healthy food policies to explicit food system intervention categories.
Prompt Engineering
All prompts articulate the LLM's putative expertise, enumerate structured task instructions, embed definition blocks for category boundaries, and require step-wise reasoning outputs in validated JSON, tightly constraining the model's reasoning and output format.
Experimental Evaluation
Dataset and Setup
Evaluation uses the Healthy Food Policy Project (HFPP) database hfpp, consisting of 608 expert-annotated municipal policy entries. Ground truth is sourced from HFPP's gold labels. LLMs are accessed via API with temperature 0, assuring reproducibility. Baselines include zero-shot (direct task statement), chain-of-thought (stepwise prompting without role specialization), and few-shot (labeled in-context exemplars), all using unified, all-in-one prompts.
Metrics
Performance is measured by exact-match and partial-match accuracy for legal strategies, micro-F1, Hamming loss for multi-label food system stages, and policy-level label correctness distributions.
Results
Factual fields such as state and year are consistently extracted with near-perfect accuracy (≥98%) across all methods, demonstrating that explicit surface-form data is within the capability of all prompting strategies. For policy type classification, the proposed framework achieves 89.47% accuracy (Llama-3.3), matching or slightly exceeding baselines.
Legal Strategy Classification
The critical differentiation arises in the legal strategy subtask. Here, all baselines plateau at low exact-match accuracy (19–27%), demonstrating clear brittleness for complex, abstract, and multi-label extraction. The role-based method using Llama-3.3 achieves 44.16% exact-match and 96.45% partial-match accuracy (vs. roughly 61% for zero-shot/CoT), nearly doubling task-level accuracy.
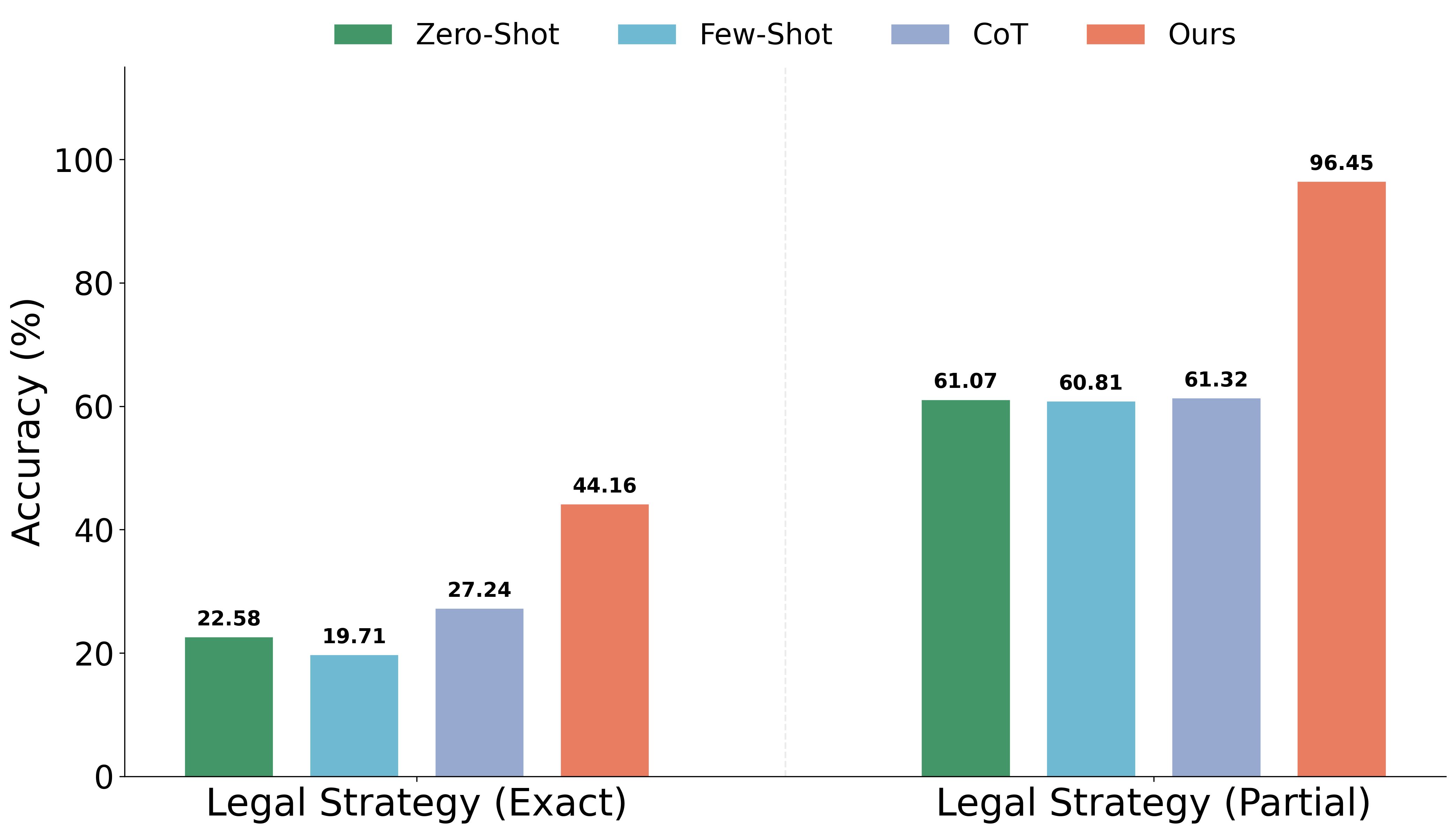
Figure 5: Comparative accuracy of legal strategy extraction for various prompting regimes; role-based prompts offer marked improvement in Llama-3.3-70B.
Food System Classification
For binary food system category assignment, the framework delivers 95.39% accuracy in "Grow" and 95.16% in "Make", outperforming baselines. Hard cases such as "Get" show a 27pt improvement over zero-shot (63.13% vs 36.01%), attributable to domain-constrained role prompting. Qwen-3 shows competitive category-level performance (e.g., 96.22% in "Surplus") but is less balanced.
Moreover, the framework increases the share of policies with fully or nearly correct multi-label food stage assignments: for Llama-3.3, 51.64% of policies exhibit 5/6 labels correct, versus a more diffuse and moderate baseline distribution.
Discussion
The empirical advantage of the role-based framework emerges most starkly in tasks requiring higher-order semantic mapping and multi-label disambiguation—legal strategy assignment and holistic food system coverage—where prompt-based baselines consistently underperform due to the absence of explicit, role-conditioned domain knowledge and structured reasoning constraints. The decomposition enables the LLM to simulate the workflows of subject matter experts and enforces interpretability, reducing model hallucinations and misclassifications. Attempts to improve baseline prompting via examples (few-shot) or sequential explanations (CoT) do not yield comparable advances without embedded role specialization and prompt-internal scaffolding.
Challenges persist in cases where policy texts are especially ambiguous or conflate several strategies without explicit lexicalization. For these, RAG or other retrieval-integrated prompt designs, as well as uncertainty-aware abstention, are proposed as promising future extensions xu2025mega.
Implications and Future Directions
The work establishes a middle ground between brittle, unstructured prompting and labor-intensive LLM fine-tuning or multi-agent architectures. Practically, this supports scalable, transparent, and replicable IE pipelines for policy research, regulatory tracking, and legal informatics. Theoretically, it demonstrates the value of structured prompt-based modular decomposition at the intersection of neuro-symbolic reasoning and domain-specific LLM alignment.
Extensions to other domains—e.g., environmental regulation, mental health ordinance, or international policy—are immediate. Future work could leverage retrieval-augmented architectures to further reduce ambiguity and introduce abstain mechanisms to down-weight unsupported model assertions.
Conclusion
The role-based LLM IE framework offers a practical yet structurally principled advance for extracting multi-dimensional, high-fidelity policy data from heterogeneous, unstructured corpora. By integrating explicit role-context, domain scaffolding, and template-based reasoning, it achieves significant improvements in multi-label and abstract semantic extraction over standard prompt-based approaches, with strong per-task accuracy and policy-level consistency. The approach is model-agnostic, reproducible, and directly translatable to other expert-analytic domains, providing a pathway to reliable automated evidence synthesis for evidence-based public health and beyond.
References
(2604.01529): https://arxiv.org/abs/(2604.01529)