- The paper demonstrates that instruction-based unlearning fails to reduce concept embedding similarity in diffusion models.
- Controlled experiments reveal that neither explicit nor implicit prompts alter cross-attention dynamics to effectively suppress targeted concepts.
- The study highlights the need for architectural changes or model adaptations to reliably remove sensitive or undesired content.
Instruction-Based Unlearning in Diffusion Models: Empirical Evidence for its Failure
Introduction
The proliferation of text-to-image diffusion models has led to new challenges regarding the removal of sensitive, non-consensual, or copyrighted content after deployment. Machine unlearning seeks to address the requirement to selectively remove learned information from large generative models, and inference-time instruction-based unlearning has emerged as a promising direction in NLP, with LLMs capable of adhering to explicit unlearning instructions during inference. The central question addressed in "Why Instruction-Based Unlearning Fails in Diffusion Models?" (2604.01514) is whether comparable instruction-based unlearning can function in text-conditioned diffusion models. This work conducts comprehensive empirical and mechanistic analyses to demonstrate that diffusion models systematically fail to suppress targeted concepts through natural language unlearning instructions at inference time.
Motivating Experiments in Diffusion Unlearning
The study begins with diagnostic experiments using explicit unlearning prompts, such as "Please forget anything about [target concept]. Please help me generate a picture of [target concept].", and evaluates the generated outputs across multiple diffusion architectures and concepts. Despite explicit negation instructions, generated images consistently retain strong alignment with the targeted concepts, both in terms of recognizable content and distinctive style. Prompt rephrasings and reinforced instructions do not materially affect this outcome.

Figure 1: A motivating experiment demonstrating that explicit unlearning instructions fail to suppress the targeted concept in generated images.
The findings indicate that, unlike in LLMs, model behavior in diffusion pipelines cannot be negated or suppressed by semantic instruction-level manipulation during inference.
CLIP Encoder Analysis: Representation-Level Perspective
To investigate the mechanism underlying this failure, the paper systematically analyzes the impact of unlearning instructions at the representation level using the CLIP text encoder, which provides the conditioning input for diffusion models. The hypothesis is that, for unlearning to be effective, the text embedding of the unlearning prompt should have substantially diminished similarity to the concept anchor embedding.
Text-only CLIP embedding analyses compare the cosine similarity between prompt embeddings (with and without unlearning) and concept anchor embeddings. The observed reduction in similarity from unlearning instructions is minimal (mean −0.045), and absolute similarity remains high for unlearning prompts—comparable to repeat-control prompts that reinforce the concept rather than suppress it. Token ablation reveals that concept-related tokens dominate the embedding space, while instruction tokens (e.g., "forget") exert negligible influence on the representation.
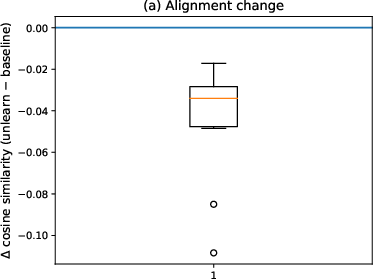
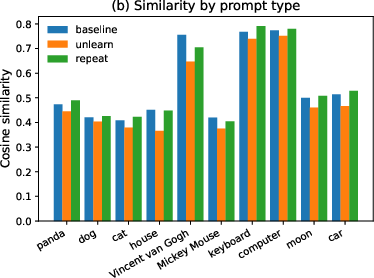
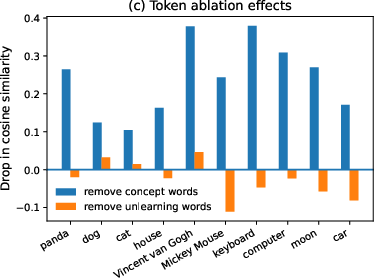
Figure 2: Text-only CLIP analyses reveal unlearning instructions negligibly affect embedding similarity to the concept anchor; concept tokens dominate semantic representation.
The image-based analysis extends this investigation to the CLIP similarity between generated images and concept anchors. Again, unlearning prompts result in a near-zero average change in similarity, and neither explicit unlearning, repeat-control, nor prompt negation achieves reliable suppression of concept evidence in generated outputs.
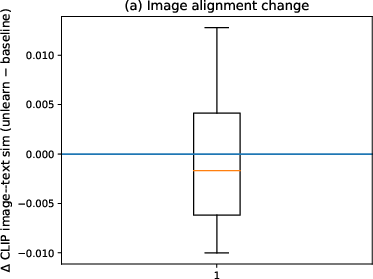
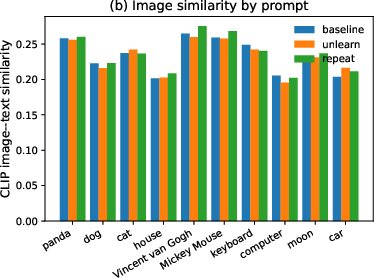
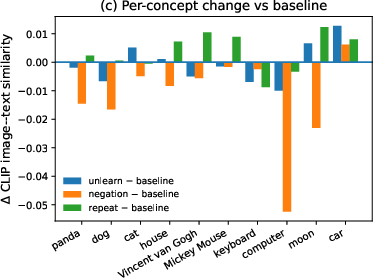
Figure 3: Image-based CLIP analyses confirm that similarity to the concept anchor remains high across prompts, indicating persistent concept features in generated images.
Collectively, these analyses demonstrate that any representational suppression induced by unlearning instructions is trivial and easily overwhelmed by the contribution of explicit concept tokens.
Diffusion Cross-Attention Dynamics
To further understand why unlearning instructions fail to influence image generation, the cross-attention patterns in the U-Net backbone of diffusion models are examined throughout the denoising process. The hypothesis is that effective unlearning would require reduced attention allocation to concept tokens in favor of unlearning instruction tokens.
Empirical measurements show that instruction tokens do receive non-trivial attention, but the concept tokens maintain high cross-attention mass across timesteps. The area under the attention curve (AUC) for concept tokens decreases only marginally under unlearning prompts (mean ΔAUC ≈−4.1×10−3), and the change is insignificant compared to total attention mass. Thus, the conditioning mechanism in diffusion fails to robustly gate the influence of concept representations even when explicit unlearning instructions are present.
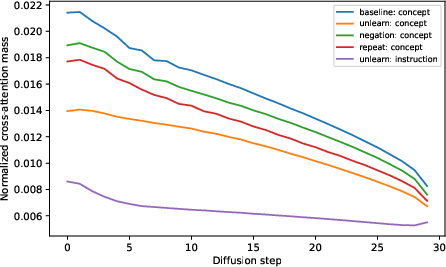
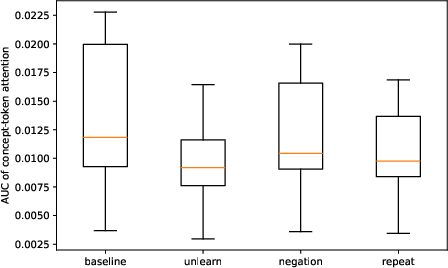
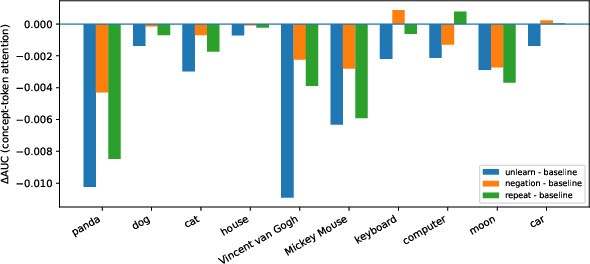
Figure 4: Cross-attention analysis shows persistent attention mass on concept tokens during denoising, regardless of unlearning instructions.
Controlled Appendix Experiments
The authors also explore both explicit and implicit prompt-level unlearning in SD-XL, including prompts rewritten by LLMs to avoid explicit reference to the targeted concept or style. In both cases, the generated images remain closely aligned with the original concept, underscoring the model’s tendency to preserve semantic and stylistic elements despite negation cues.

Figure 5: Explicit instruction use: the unlearning prompt still yields outputs with the targeted concept's features.

Figure 6: Implicit instruction use (via prompt rewriting) also fails to eliminate the concept from generations.
Implications and Future Directions
The evidence presented in this work has significant implications for safety, intellectual property compliance, and post-deployment content control in generative vision models. Specifically, it contradicts claims of universal efficacy for instruction-based unlearning across modalities and suggests that the current prompt-conditioning mechanisms in diffusion are fundamentally less capable of semantic negation than those in transformer-based LLMs.
This work indicates that practical unlearning for deployed diffusion models will require interventions beyond textual prompt manipulation. Promising directions include architectural changes in token integration, fine-tuning or adaptation methods that explicitly degrade concept representations, or hybrid techniques incorporating both prompt engineering and targeted model parameter updates. The results also motivate further analysis of text encoder architectures, as CLIP-style transformers dominate the conditioning space, restricting the expressivity available for instruction-based control.
Conclusion
This study provides a rigorous empirical and mechanistic demonstration that instruction-based unlearning is ineffective for current generation diffusion models. Unlearning instructions have minimal impact at the text embedding level and are further diluted during the iterative denoising process, preventing reliable suppression of targeted concepts. The findings delineate the sharp limitations of prompt-level control in diffusion-based generation and emphasize the necessity for direct model interventions for robust unlearning. Future research should pursue modifications to conditioning paradigms, model adaptation techniques, and new architectures capable of robustly supporting post hoc concept erasure in generative vision systems.