- The paper introduces a dual-stream training paradigm that decouples global and fine-grained audio representations via heterogeneous supervision.
- It employs a specialized audio adapter with cluster-based negative sampling, boosting performance in retrieval, classification, and temporal grounding.
- The method constructs a scalable synthetic dataset (FineLAP-100k) to mitigate sparse frame-level annotations, enhancing real-world applicability.
FineLAP: Fine-grained Language-Audio Pretraining with Heterogeneous Supervision
Introduction
Fine-grained alignment between audio signals and natural language is essential for a broad spectrum of multimodal tasks, including open-vocabulary sound event detection (SED), text-to-audio retrieval, and temporal audio grounding. While contrastively pretrained audio-LLMs (CLAP) have demonstrated strong results in clip-level tasks through global alignment, their efficacy diminishes in frame-level tasks that require local, temporally resolved audio-text correspondence. The core challenge lies in leveraging ubiquitous coarse-grained clip-level textual descriptions alongside scarce frame-level annotations. The FineLAP framework systematically addresses this by introducing a joint training paradigm on heterogeneous data with tailored loss formulations, an architecture to decouple global and fine-grained learning, and a scalable synthetic SED dataset.
Model Architecture and Training Paradigm
FineLAP extends the CLAP bi-encoder paradigm by incorporating frame-level aligned supervision in conjunction with abundant clip-level annotated data streams. The key architectural advancement is the decoupled audio adapter, which differentiates pathways for extracting global (clip-level) and dense (frame-level) audio representations. The global branch operates via a linear two-layer projection for holistic semantics, while the frame-level pathway leverages pooled and temporally processed embeddings refined through additional Transformer layers for precise alignment. The text branch is anchored by RoBERTa and is similarly mapped into the shared embedding space, supporting both caption and short-phrase representations.

Figure 1: Schematic of FineLAP’s architecture, highlighting the decoupled adapter for multi-granular alignment and the dual-stream supervision paradigm.
The training objective comprises a dual-stream sigmoid loss: a clip-level sigmoid loss aligns audio clips and captions irrespective of batch normalization, while a frame-level sigmoid loss with cluster-based negative sampling aligns temporal audio frames with event phrases. Phrase sampling is strongly regularized using clusters defined over the semantic space, enhancing negative diversity and generalization.
Synthetic Dataset Construction: FineLAP-100k
To offset the deficit of frame-level annotated data, FineLAP introduces FineLAP-100k: a large-scale synthetic SED corpus generated by mixing clean event-centric clips (extracted via a window-based dynamic energy thresholding over FSD50K) and high-quality ambiance backgrounds. Foreground events are randomly repeated, temporally positioned with independently controlled SNRs, and combined using a formalized mixing procedure. Captions are systematically produced using LLM-driven template prompting over event descriptions, offering coverage and variability.
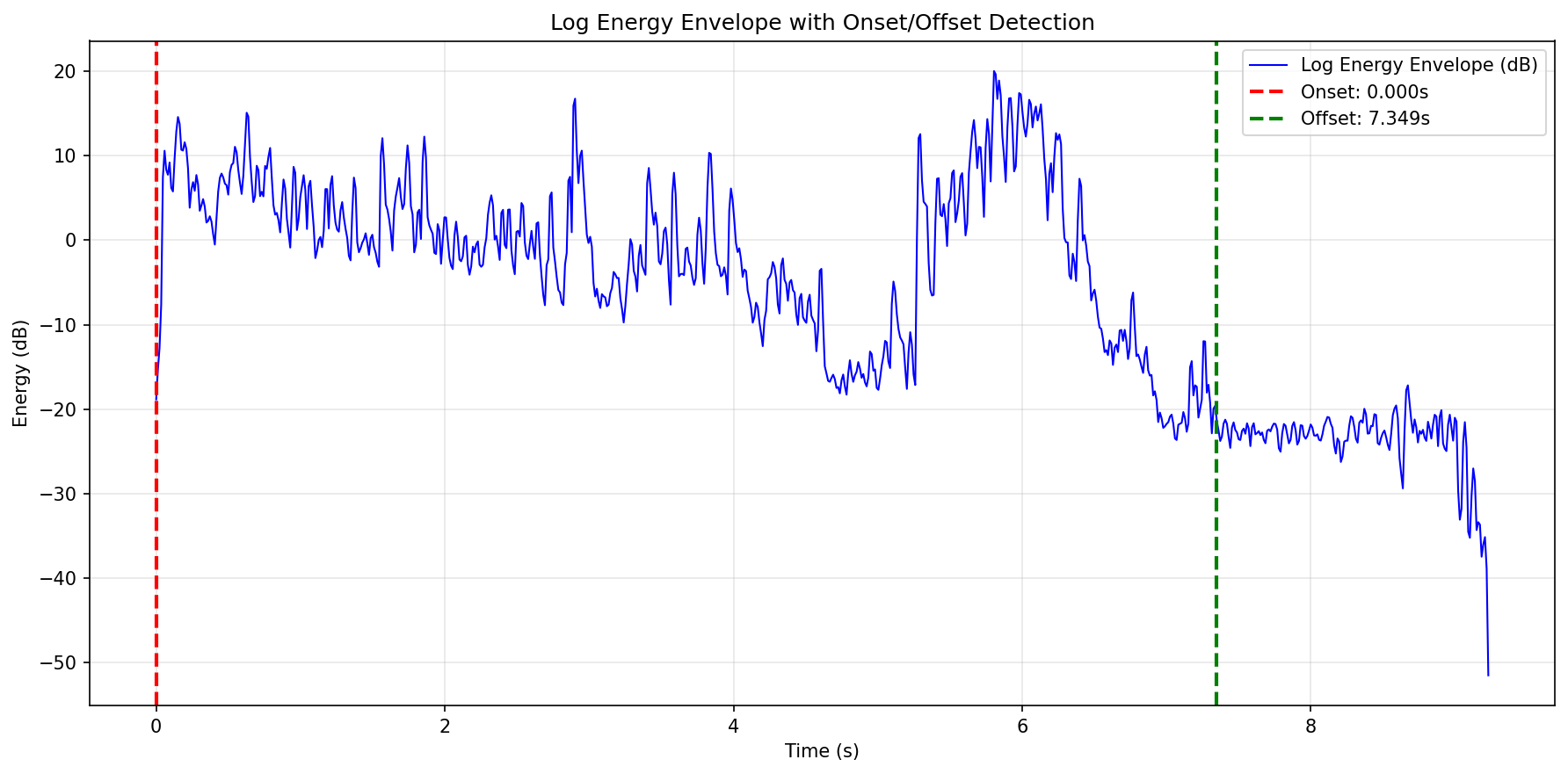
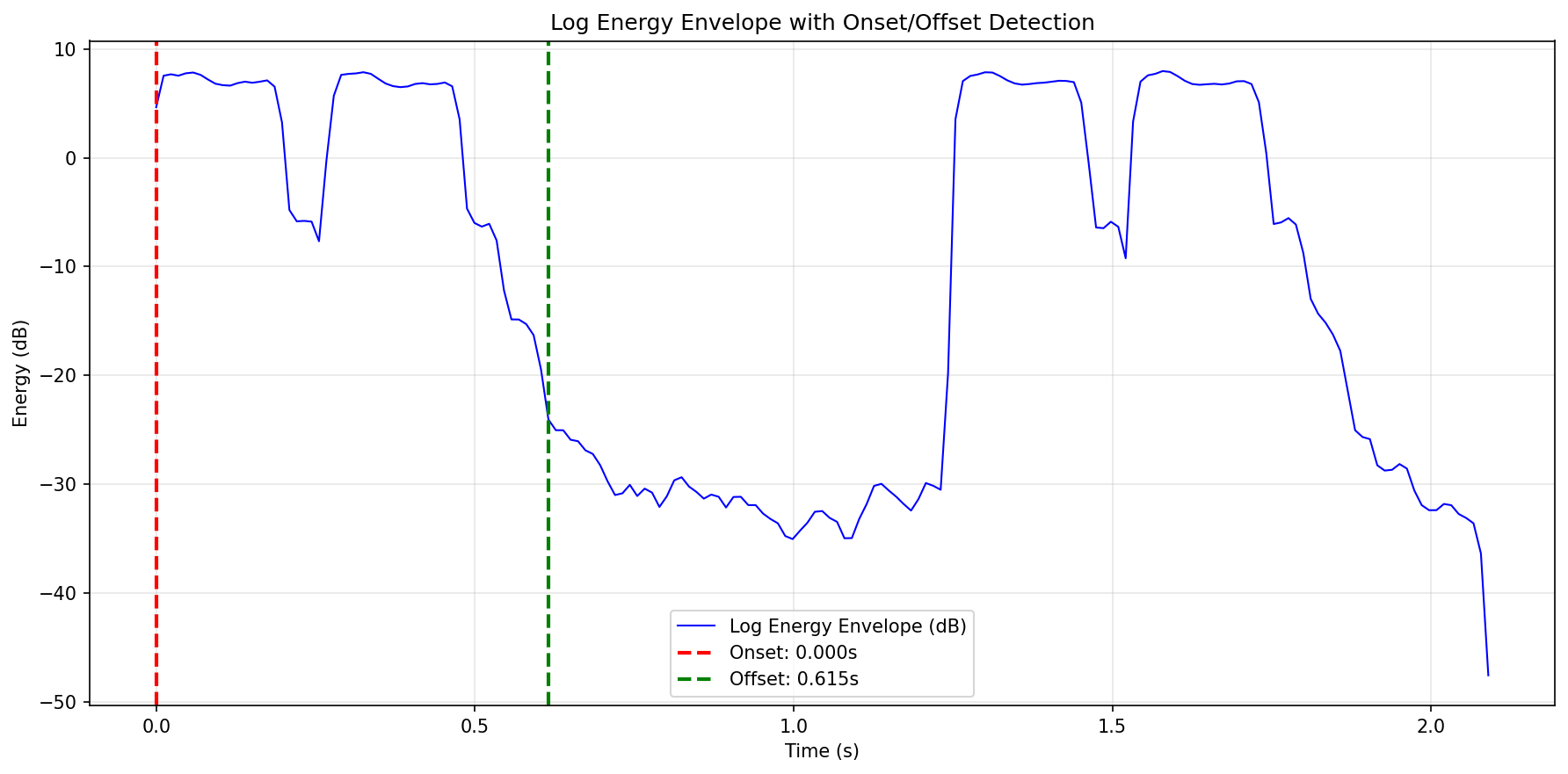
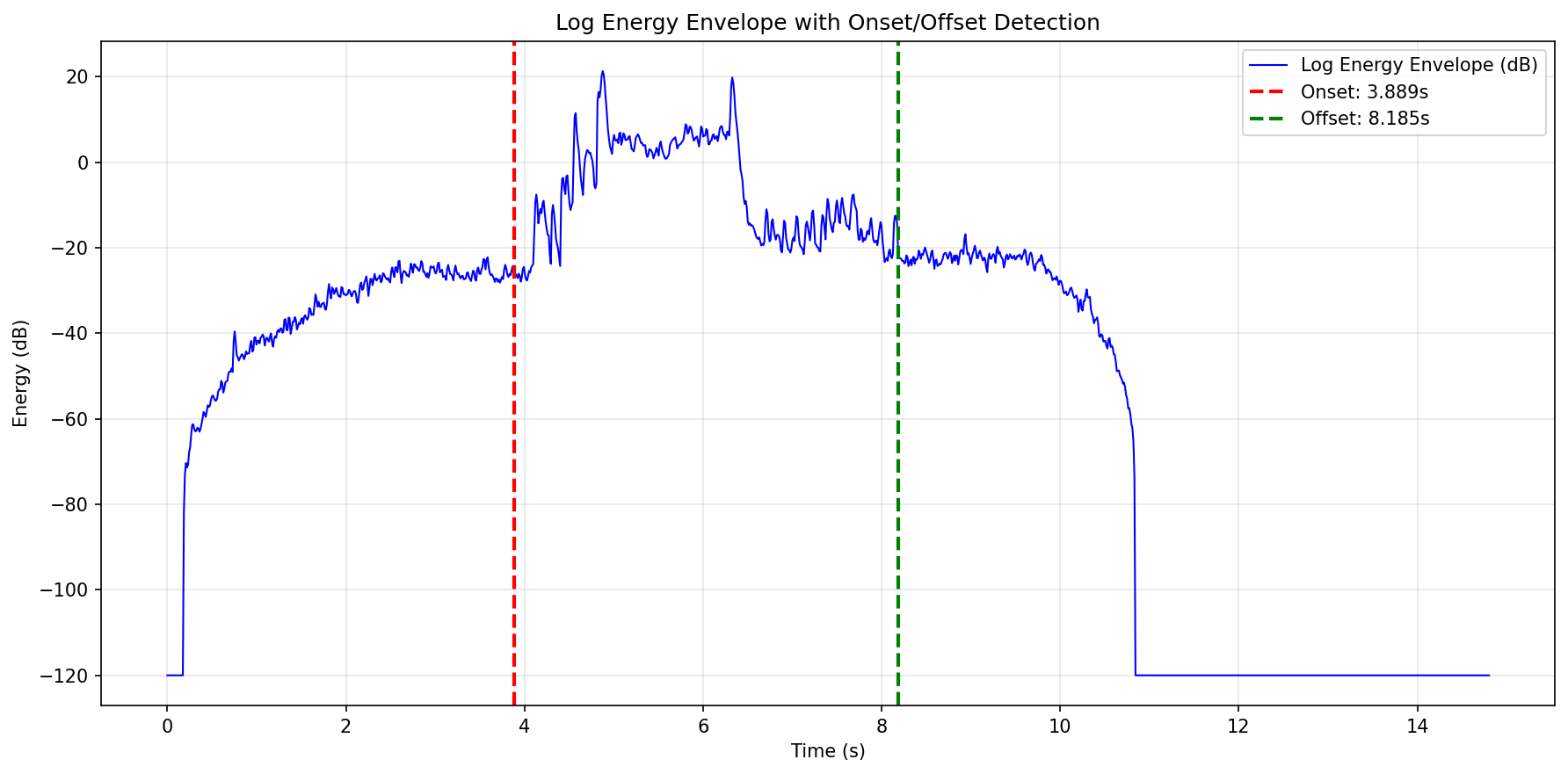
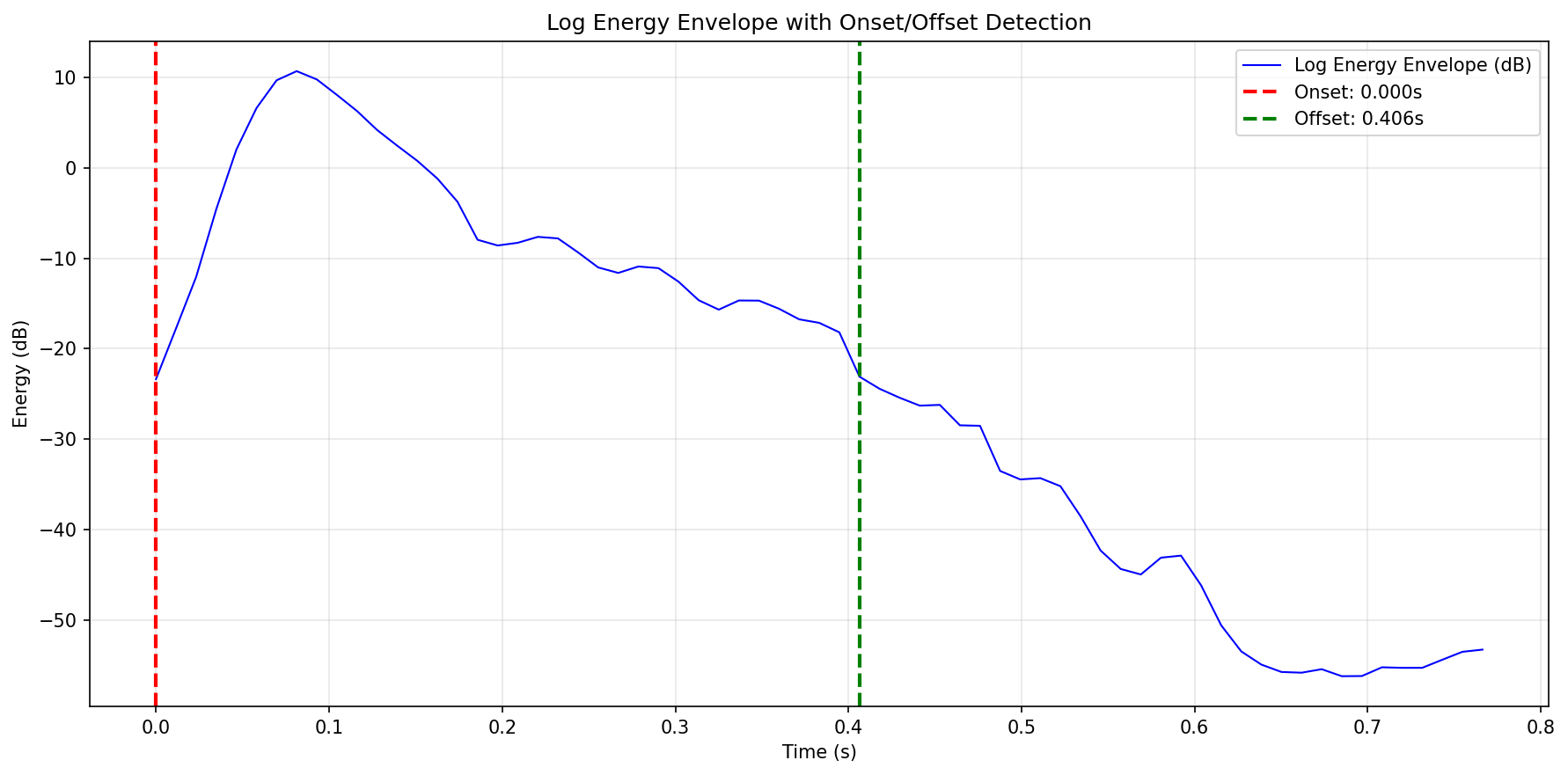
Figure 2: The window-based audio clipping process detects high-energy regions, removing silence and ensuring single-event purity for SED dataset synthesis.
Experimental Results
FineLAP was benchmarked on multiple audio-language understanding datasets spanning retrieval, classification, SED, and temporal grounding. The architecture achieves state-of-the-art (SOTA) performance at both global and local alignment levels.
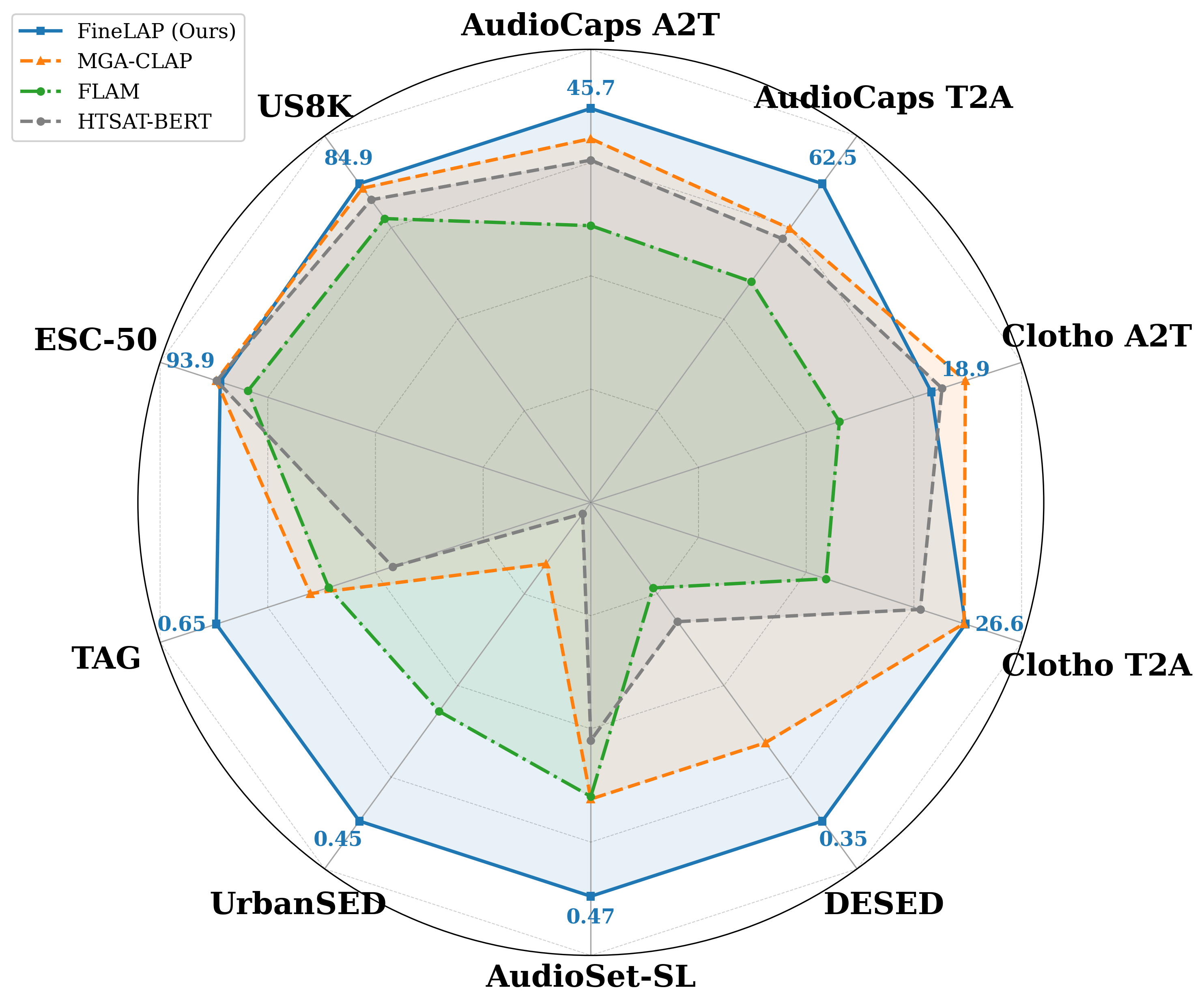
Figure 3: FineLAP achieves SOTA across both clip- and frame-level tasks, based on standardized benchmarks.
Retrieval and Classification
On the AudioCaps evaluation set, FineLAP outperforms all baselines, with Recall@1 of 45.7 (text-to-audio, T2A) and 62.5 (audio-to-text, A2T). Performance on Clotho is also on par with or better than leading models, demonstrating robust global alignment. In audio classification, FineLAP attains leading accuracy on UrbanSound8K (84.9%) and competitive scores on ESC-50 and VGGSound.
Sound Event Detection and Temporal Grounding
On SED benchmarks, FineLAP achieves 0.344 on DESED, 0.474 on AudioSet-Strong, 0.446 on UrbanSED, and 0.649 on AudioGrounding (TAG), all outperforming both closed- and open-vocabulary SED baselines. Notably, these improvements corroborate the advantage of heterogeneous multi-granularity supervision.
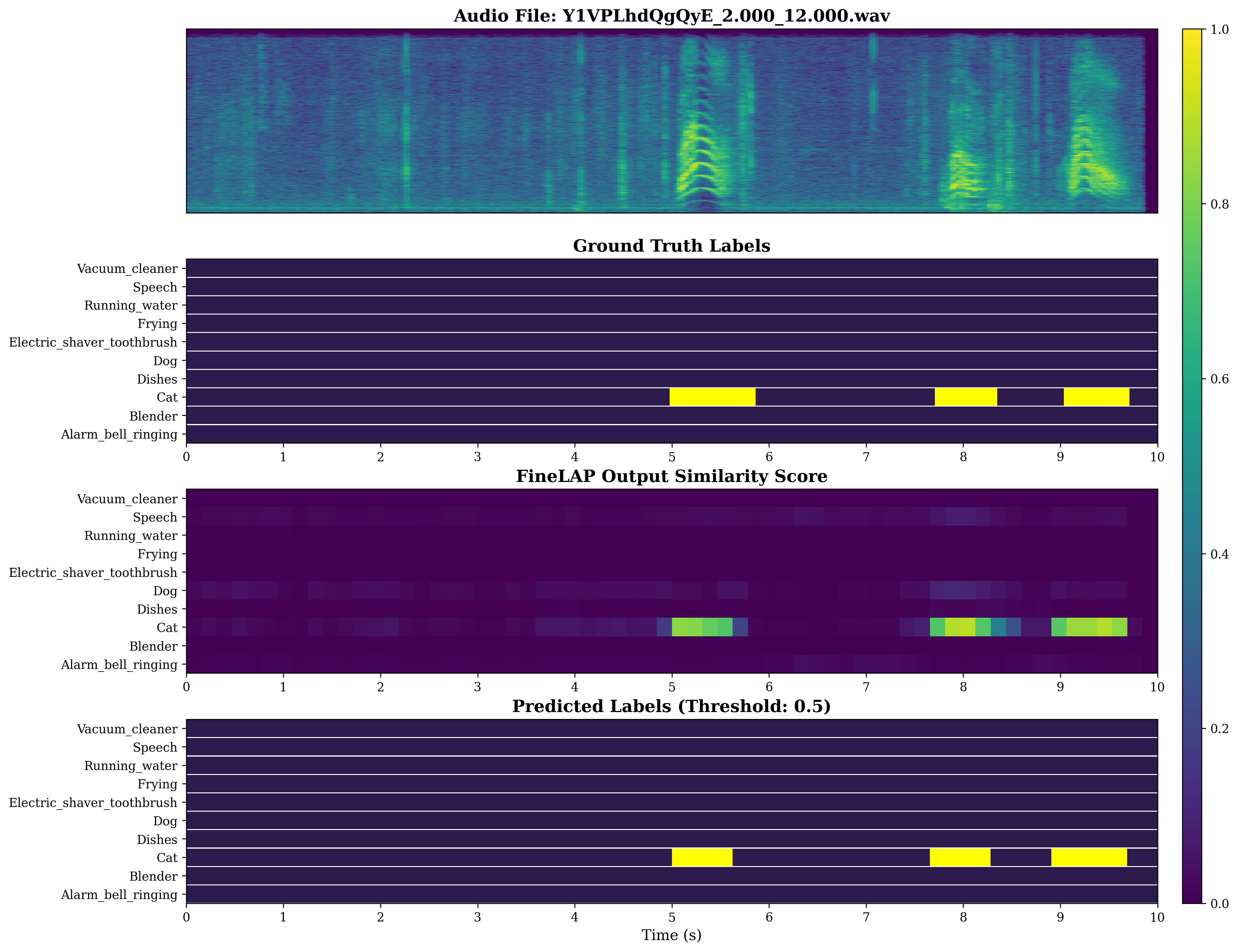
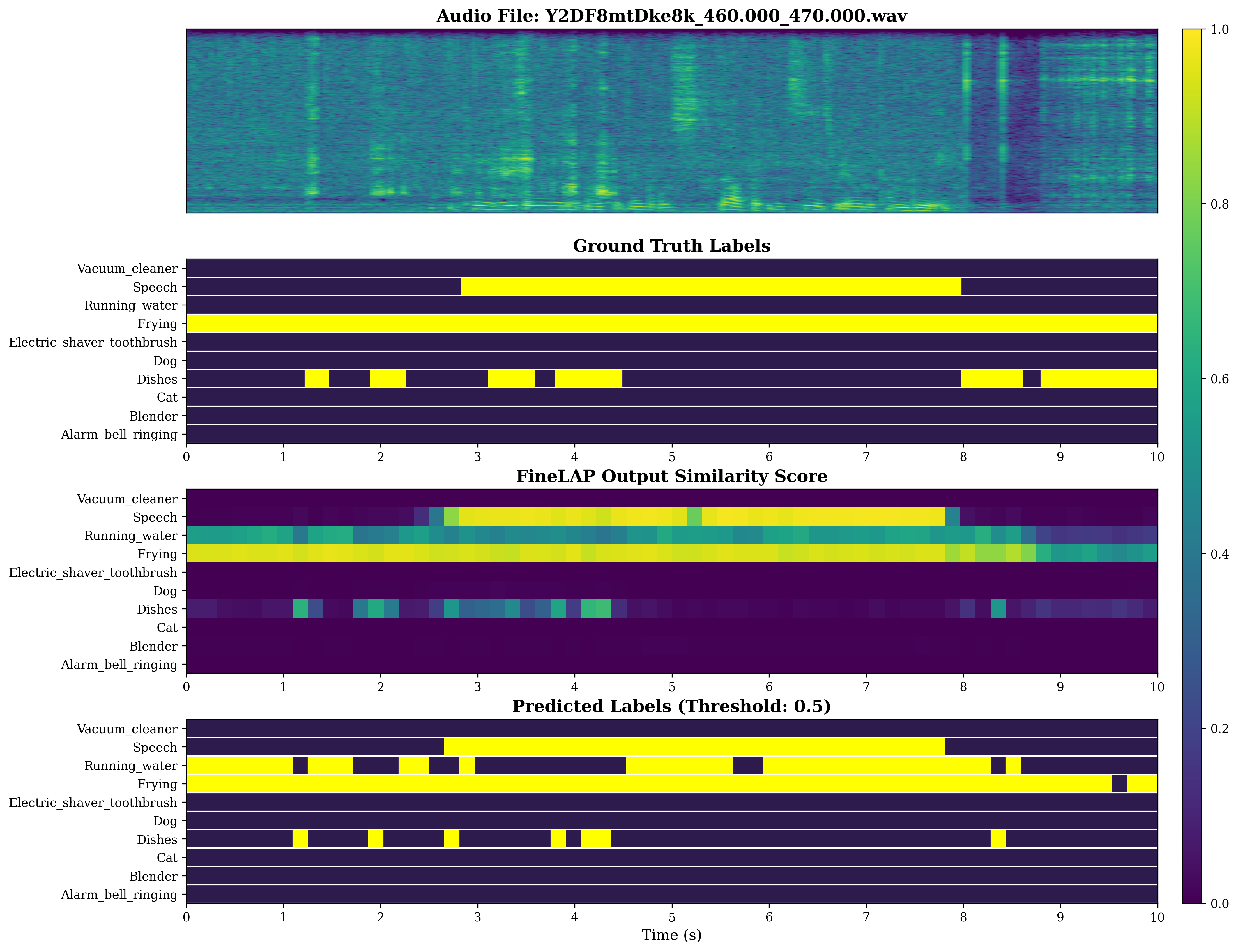
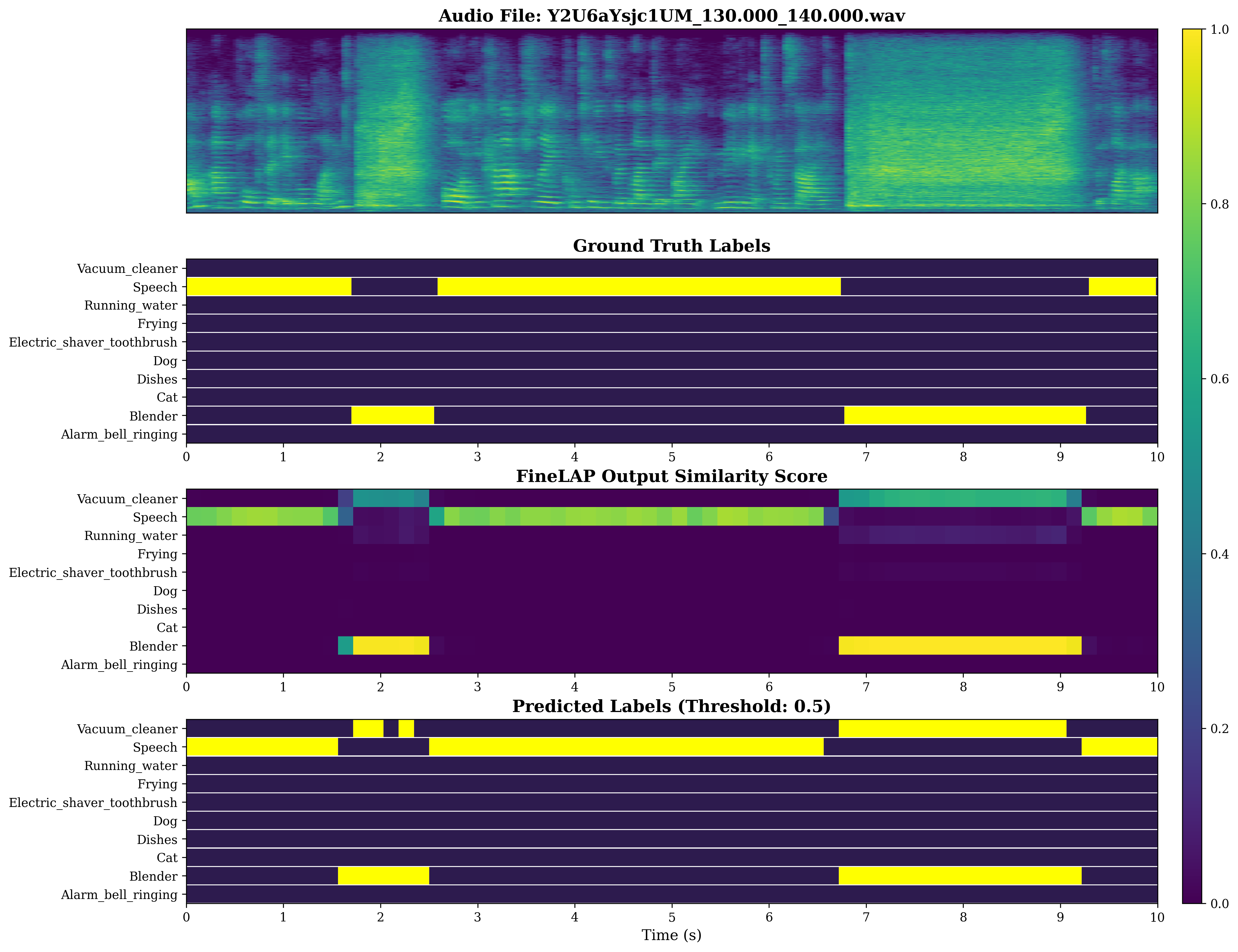
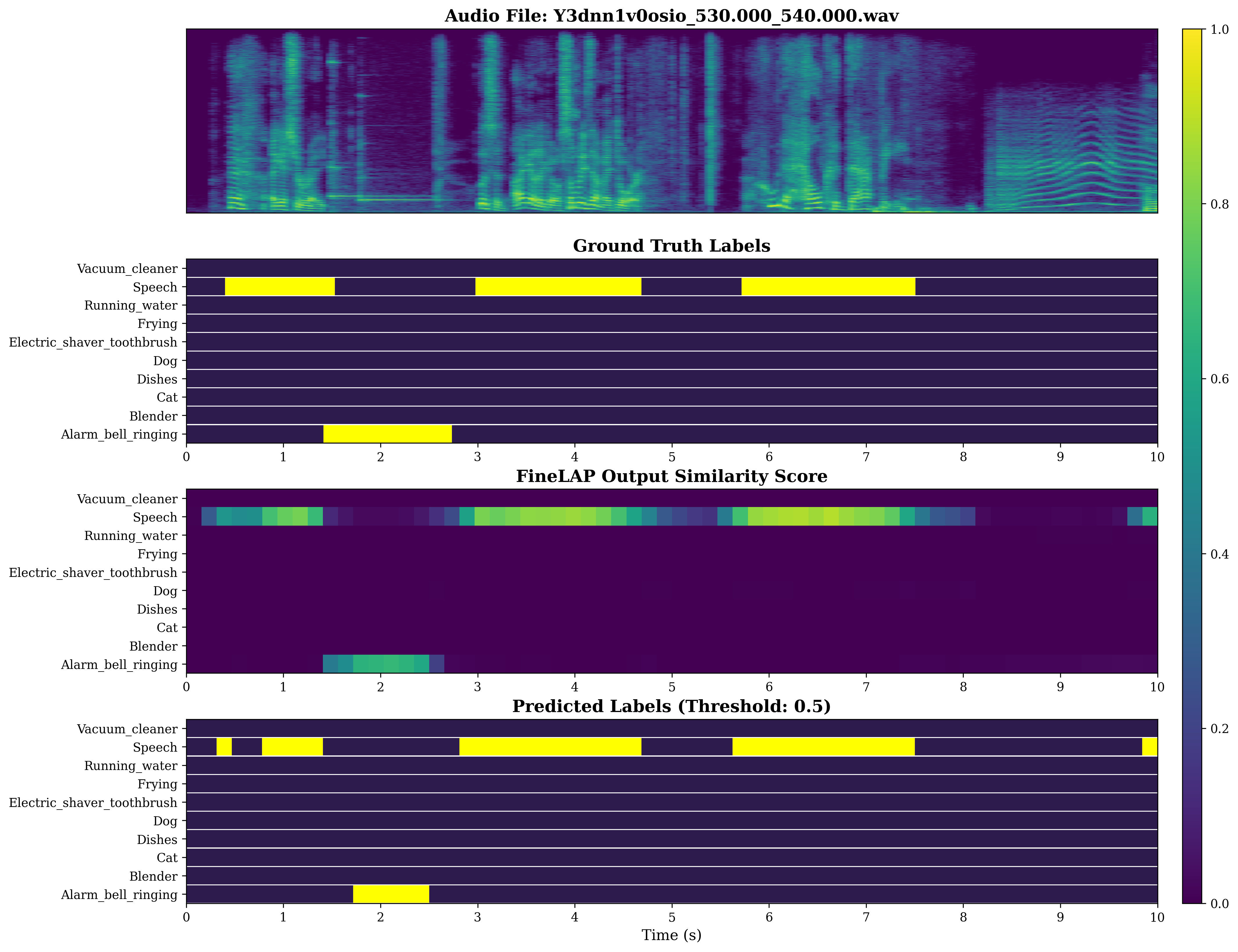
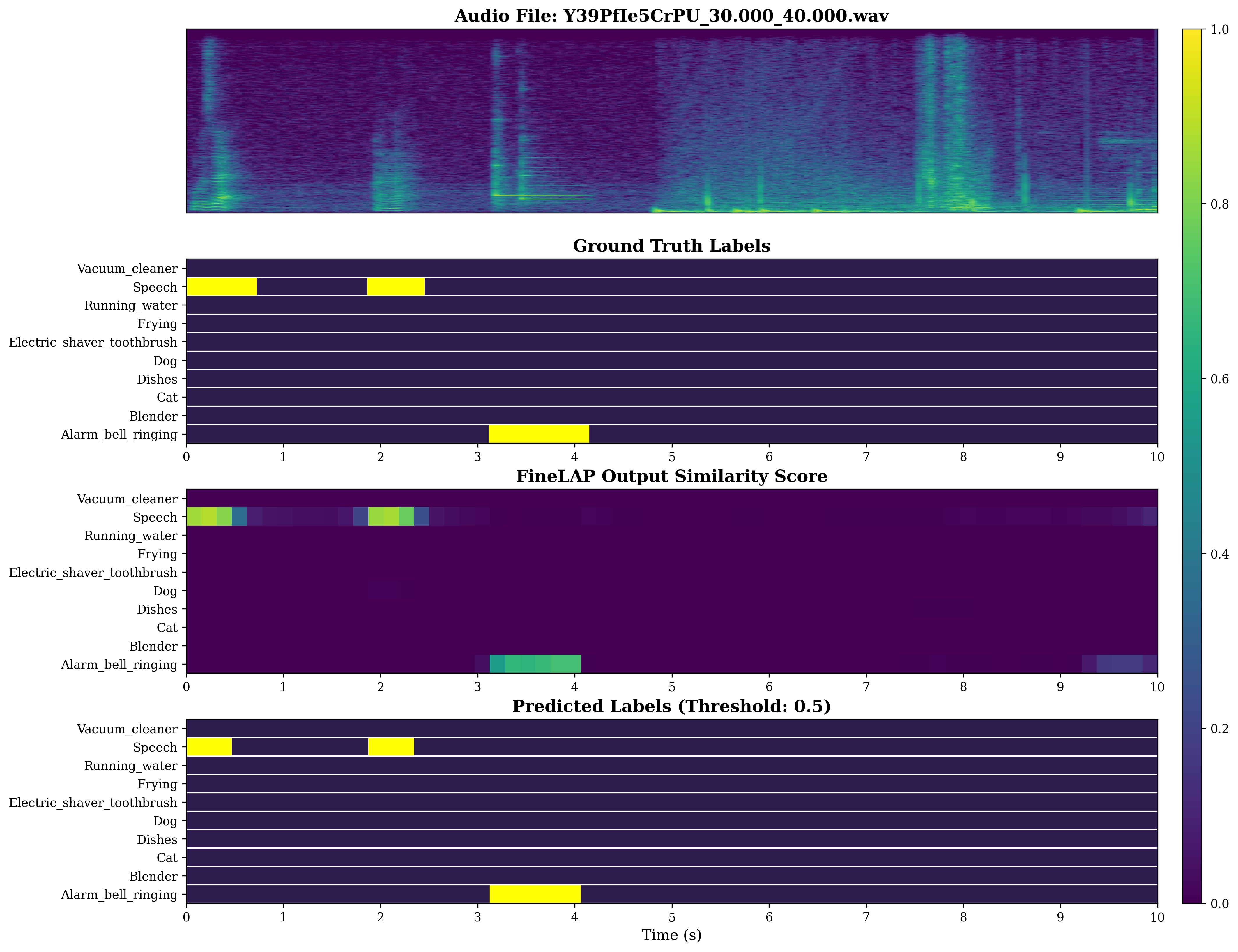
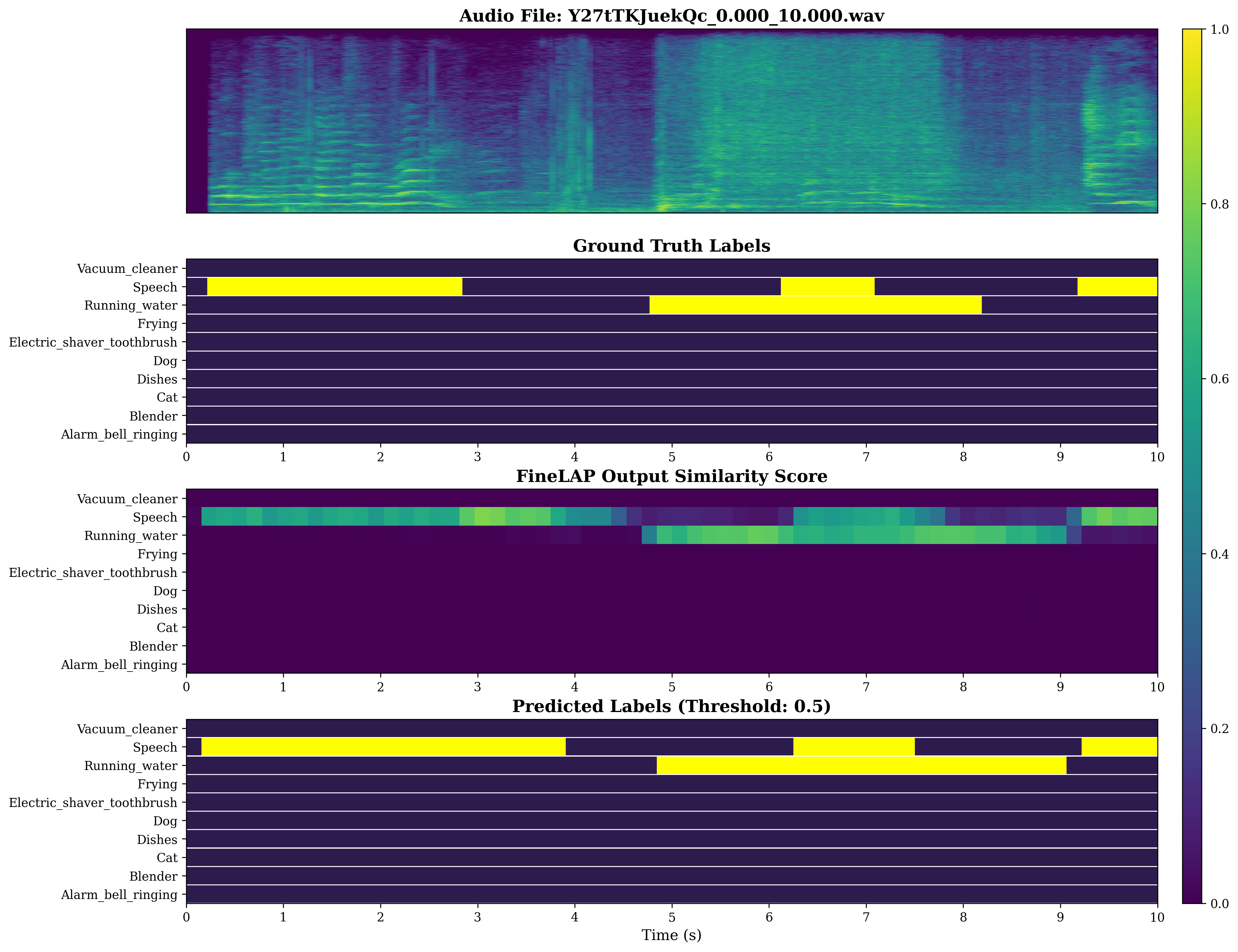
Figure 4: Visual analysis of sound event detection on DESED evidences FineLAP’s precise temporal boundary detection for overlapping events.
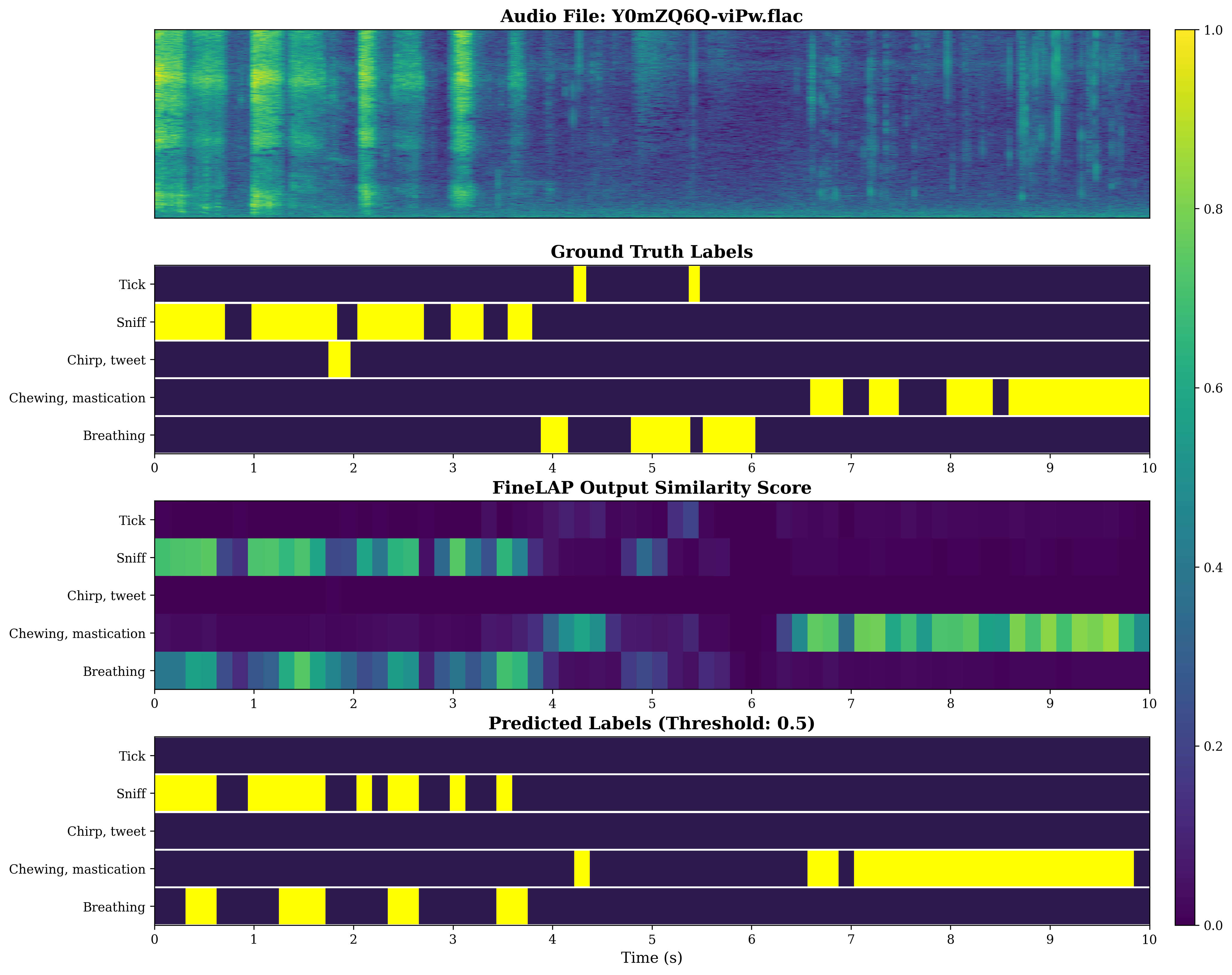
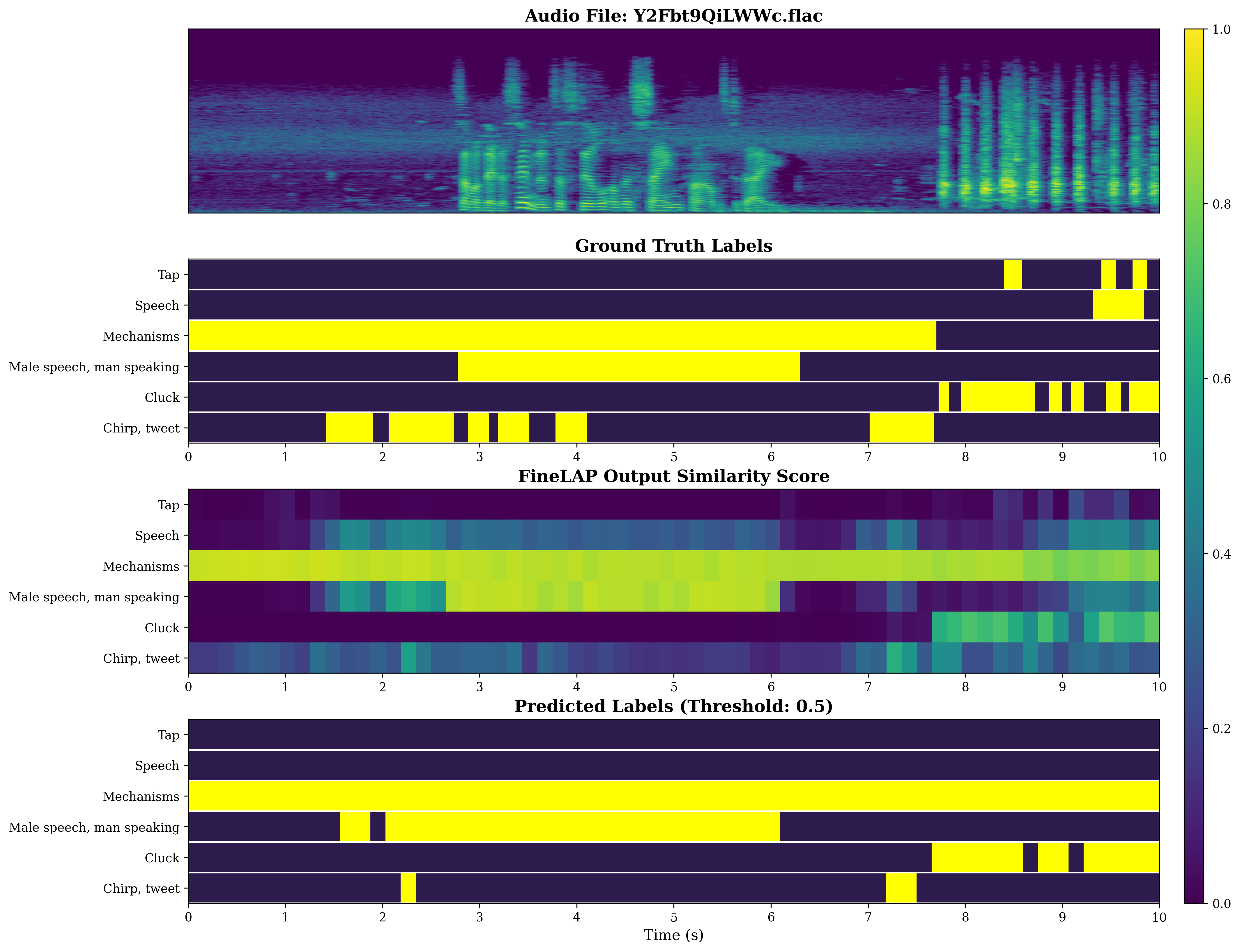
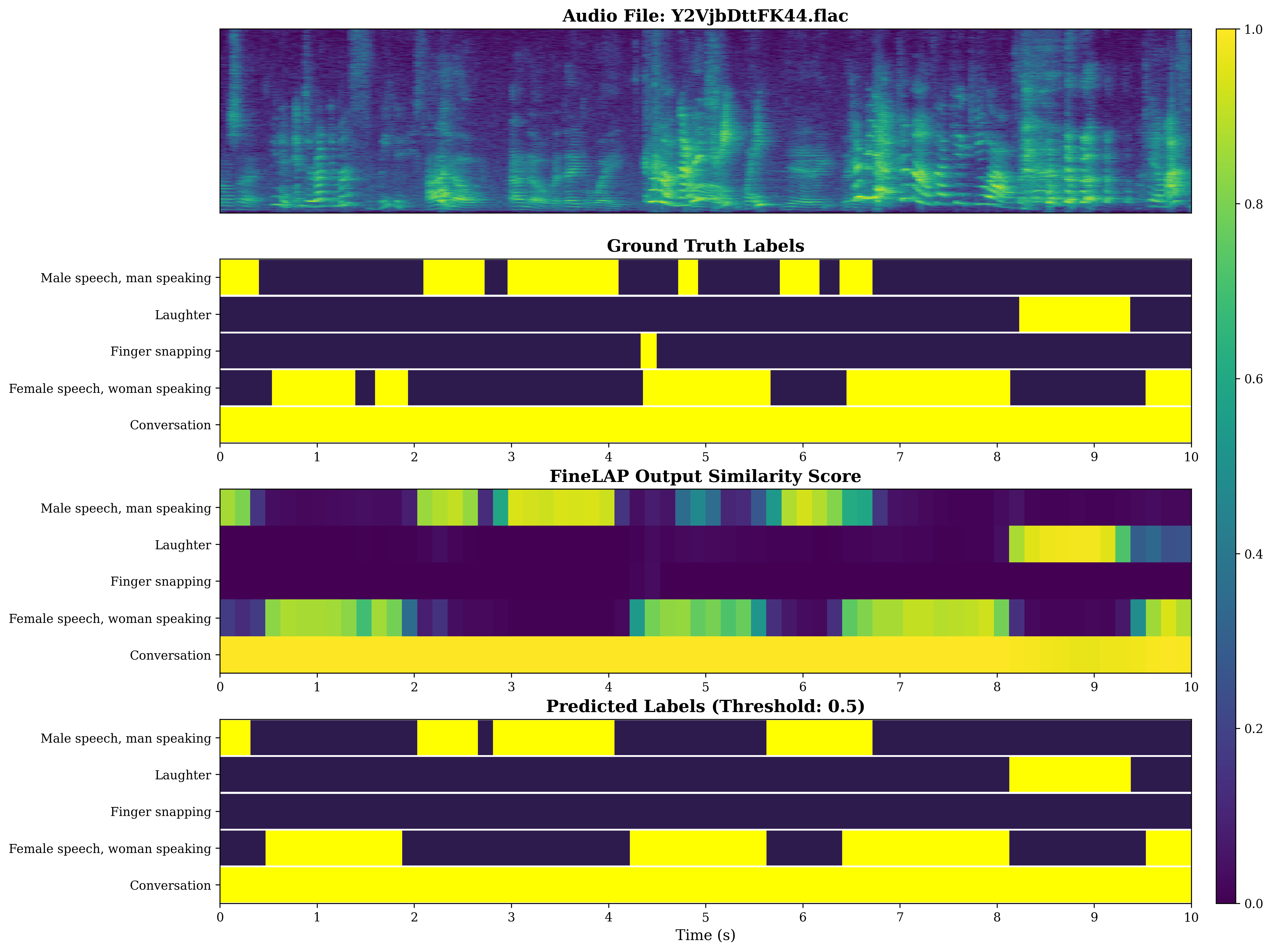
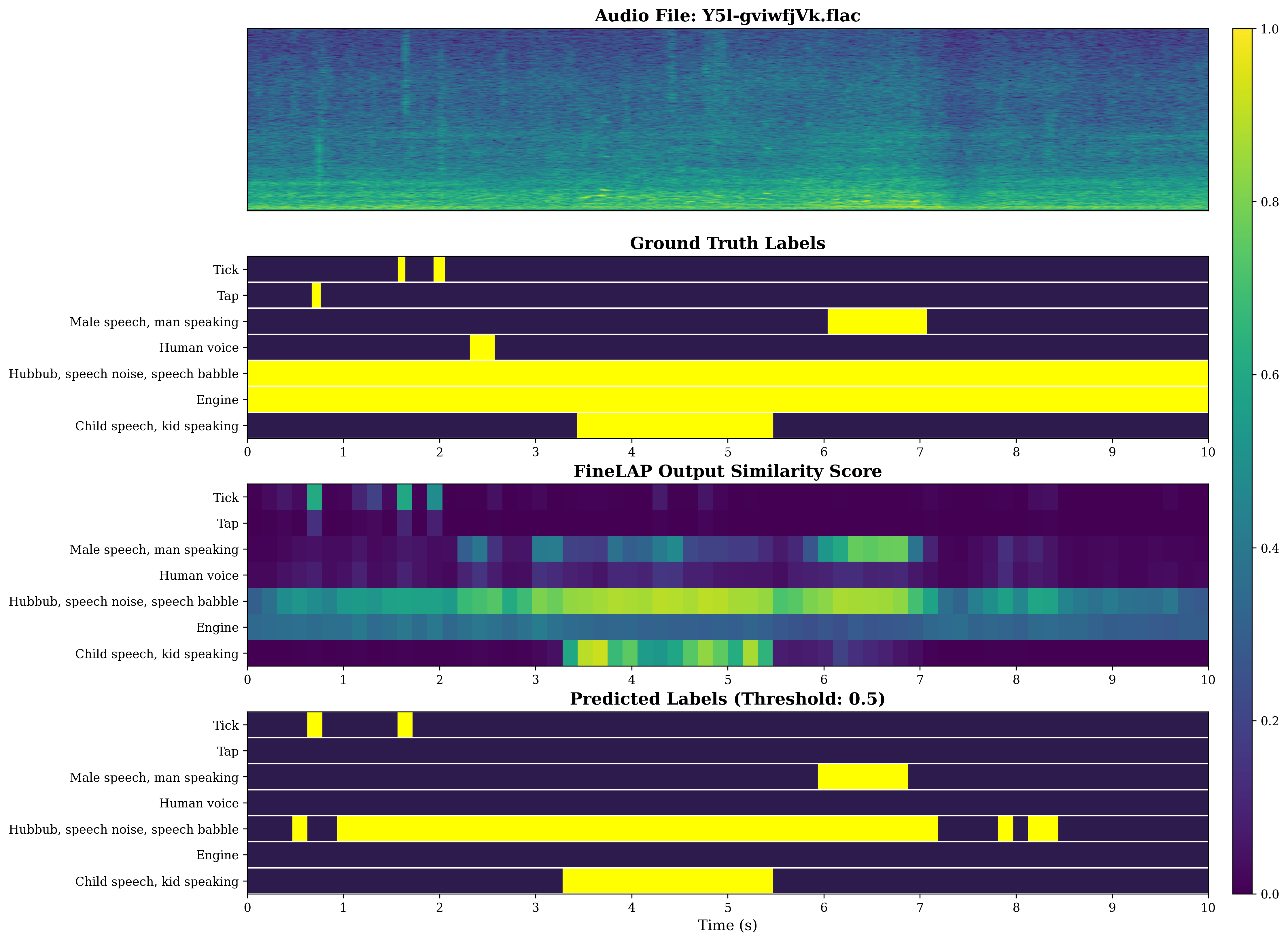
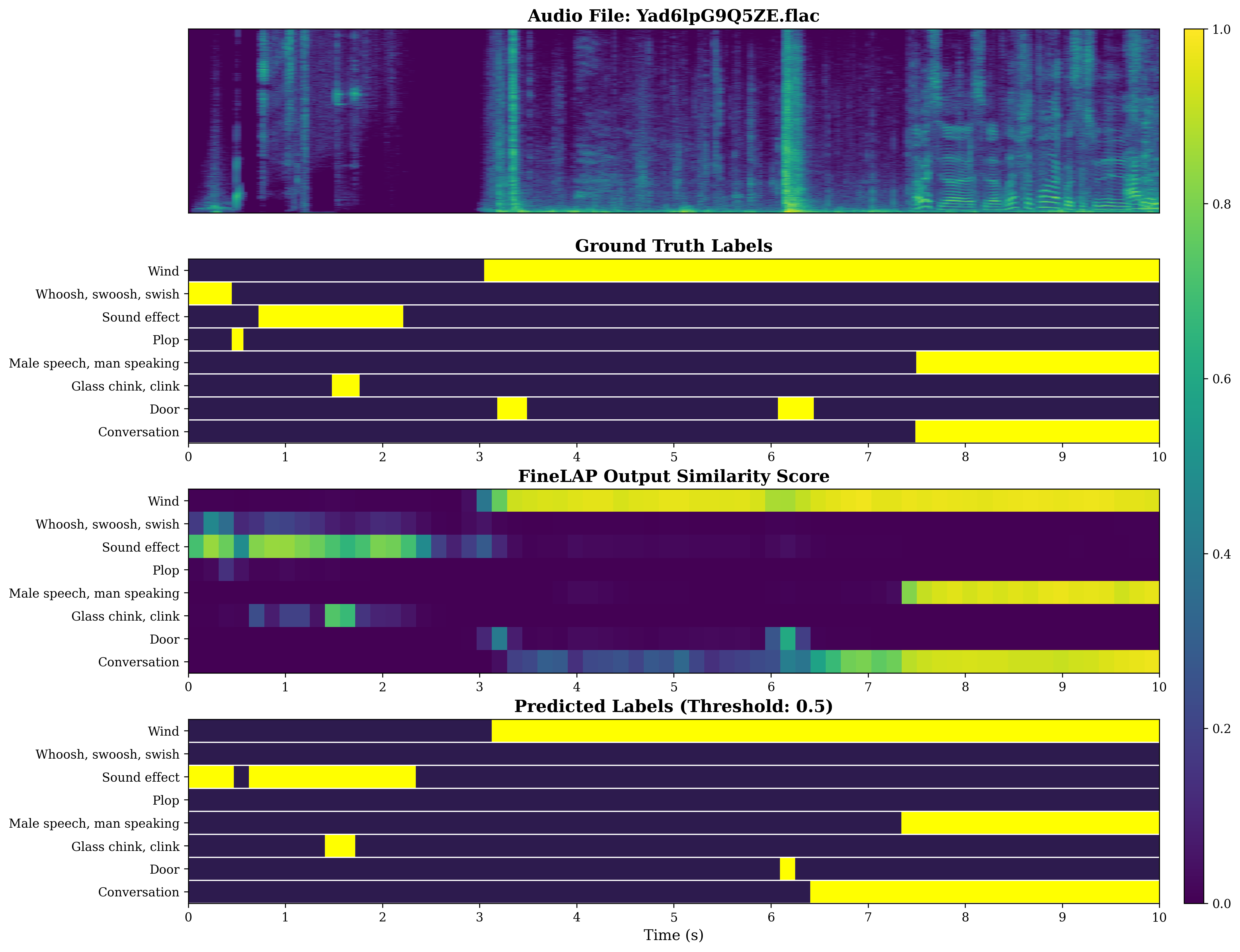
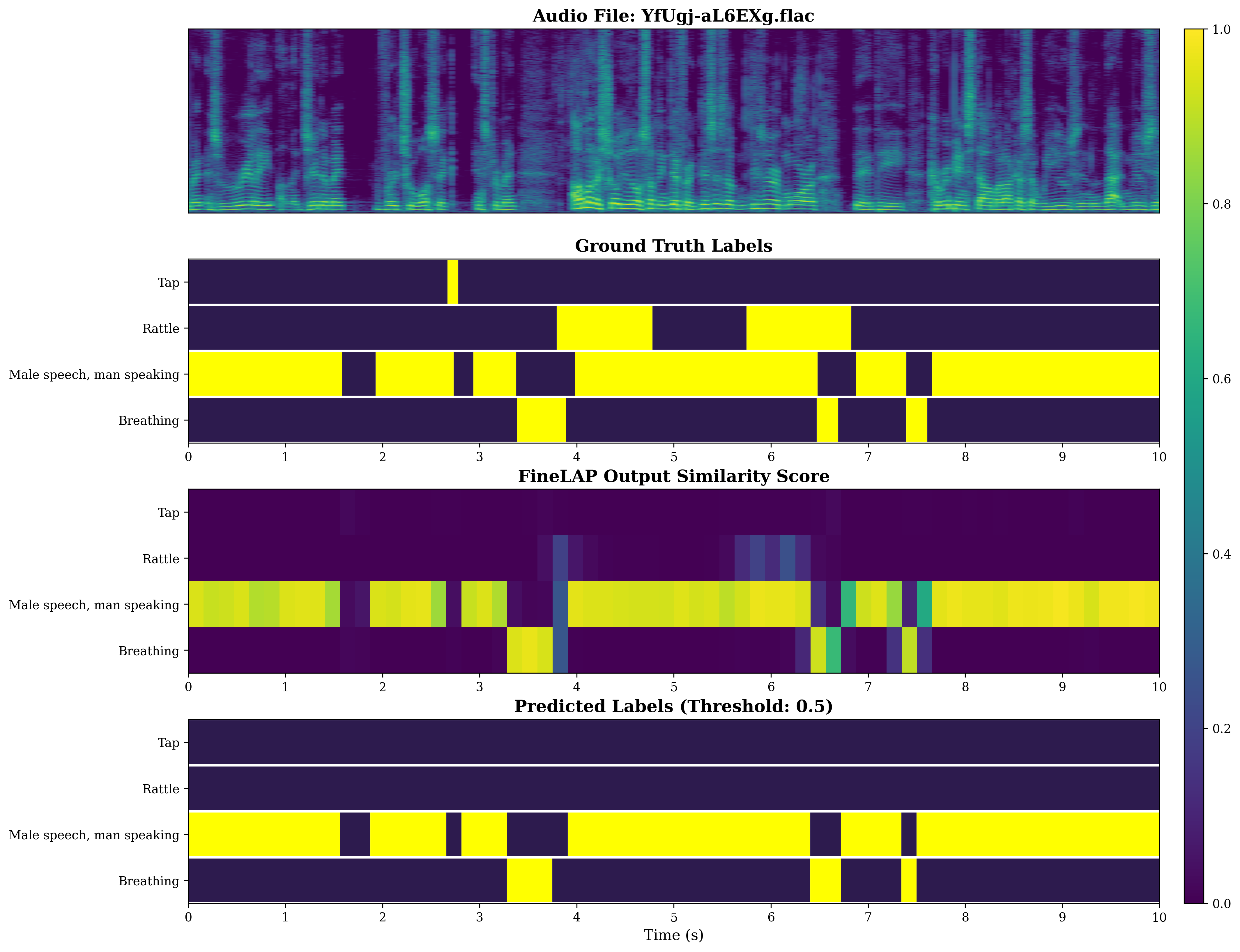
Figure 5: FineLAP’s performance on AudioSet-Strong demonstrates effective detection and temporal localization across diverse events.
Ablation Analysis
A series of ablations quantify the contribution of each design aspect. Removing frame-level or clip-level supervision sharply degrades respective and overall performance, demonstrating the necessity and synergy of heterogeneous objectives. The decoupled projection design (rather than a single shared projector) is also validated, yielding consistent improvements in both retrieval and detection. The inclusion of FineLAP-100k synthetic data significantly enhances frame-level metrics, particularly in highly compositional scenarios.
Theoretical and Practical Implications
FineLAP decisively demonstrates that multi-granularity, heterogeneous supervision yields mutually reinforcing benefits for audio-text models, contrasting with pipeline or staged approaches that treat global and local alignment as disjoint. The dual-stream sigmoid loss demonstrates better stability and downstream transfer compared to InfoNCE objectives, particularly in low-signal frame-level regimes. Furthermore, the adoption of cluster-based negative sampling enhances open-vocabulary discrimination, essential for compositional and long-tail sound event coverage.
Practically, FineLAP's flexible, open-vocabulary design is superior for event detection, semantic retrieval, and temporal grounding across general and specialized domains. The scalable synthetic pipeline for SED data generation may serve as a template for future multimodal training regimens where annotation scarcity is prevalent.
Future Directions
While FineLAP advances the state-of-the-art, several avenues remain open. The framework currently processes fixed-length (short to medium duration) clips; extending it to unconstrained long-form or streaming audio presents both architectural and optimization challenges. Expansion of temporally grounded tasks – beyond SED, towards temporal question answering or retrieval with dense event annotations – would further stress-test FineLAP’s alignment fidelity. Finally, dynamic and continual curriculum learning over synthetic and real frame-level datasets may yield further improvements in real-world distribution shifts.
Conclusion
FineLAP introduces a systematic, technically rigorous framework for multi-granularity language-audio pretraining under heterogeneous supervision. Through a dual-stream loss formulation, a decoupled audio-text architecture, and the construction of FineLAP-100k, it sets a new baseline across a range of clip-level and frame-level audio-language benchmarks. The architecture and training paradigm concretely demonstrate the value of unifying coarse and fine alignment, and the methods for phrase-level negative sampling and synthetic frame-level data creation will likely inform multimodal learning regimes for years to come.