- The paper introduces MoA-DepthCLIP, a parameter-efficient approach integrating CLIP's semantic priors with Mixture-of-Adapters for improved monocular depth estimation.
- It employs a dual-head strategy combining depth-bin classification and continuous regression, achieving superior metrics like δ1 accuracy and RMSE.
- The framework balances computational cost and precision by selectively fine-tuning a frozen ViT-B/32 backbone using globally-fused prompt embeddings.
Lightweight Prompt-Guided CLIP Adaptation for Monocular Depth Estimation: An Expert Analysis
Introduction
This work introduces MoA-DepthCLIP, a parameter-efficient framework that leverages large-scale vision-LLMs (VLMs)—notably, CLIP—for monocular depth estimation. The method builds on the observation that pretrained VLMs encode rich semantic representations, yet there remains a substantial adaptation gap when transferring these representations to fine-grained geometry-centric tasks such as monocular depth prediction. MoA-DepthCLIP addresses this by introducing Mixture-of-Adapters (MoA) modules into the visual backbone (a ViT-B/32 encoder), performing selective fine-tuning, and fusing global scene semantics derived from prompt embeddings. The approach is validated on the NYU Depth V2 benchmark and attained a marked improvement over previous VLM-based baselines, achieving a δ1 accuracy of 0.745 (vs. 0.390 for DepthCLIP) and a root mean squared error (RMSE) of 0.520 (vs. 1.176) while using significantly fewer trainable parameters.
Methodology
Architecture Overview
MoA-DepthCLIP employs a frozen CLIP text encoder to generate a global scene context vector from predefined prompts. An image is processed by a frozen (except for the top four layers) ViT-B/32 backbone augmented with sparsely-placed MoA modules (at layers 2, 5, 8, 11). The image and context features are fused and passed to a dual-head output: one head for depth-bin classification (128 fixed bins), the other for direct regression. The final depth map is a fusion of these two outputs. This design enables spatially-aware adaptation guided by global semantic context.
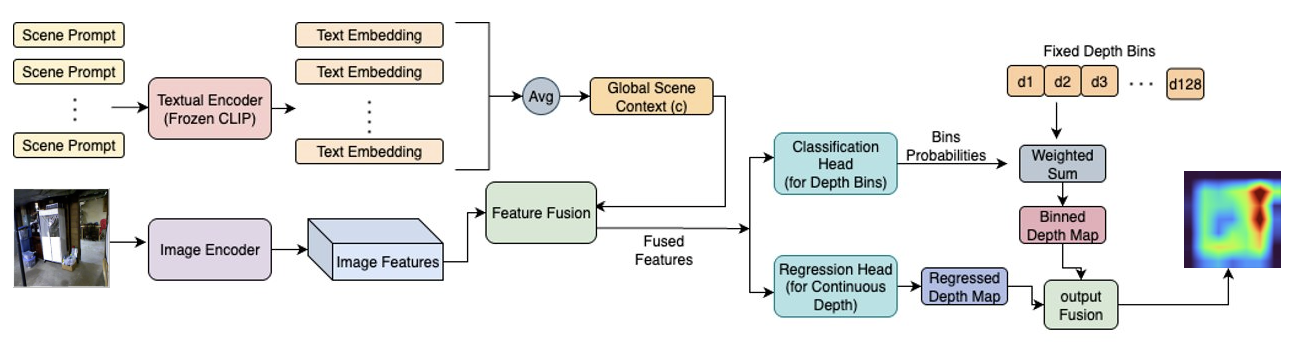
Figure 1: The MoA-DepthCLIP architecture, integrating global scene context and mixture-of-adapters for dual-head depth prediction.
Mixture-of-Adapters and Selective Fine-Tuning
The MoA modules adapt the ViT-B/32 encoder with minimal parameters. Each consists of K=4 lightweight experts (two-layer MLPs with GELU activations and bottleneck size 64), a gating network (per-token softmax outputs via a 2-layer MLP), and a residual pathway that injects adapted representations back into the main flow. Unlike prior stochastic routing schemes, MoA-DepthCLIP applies a deterministic, differentiable gating at train and test time, favoring stability. The experts are selectively placed only at specific backbone layers, balancing computation and expressivity.
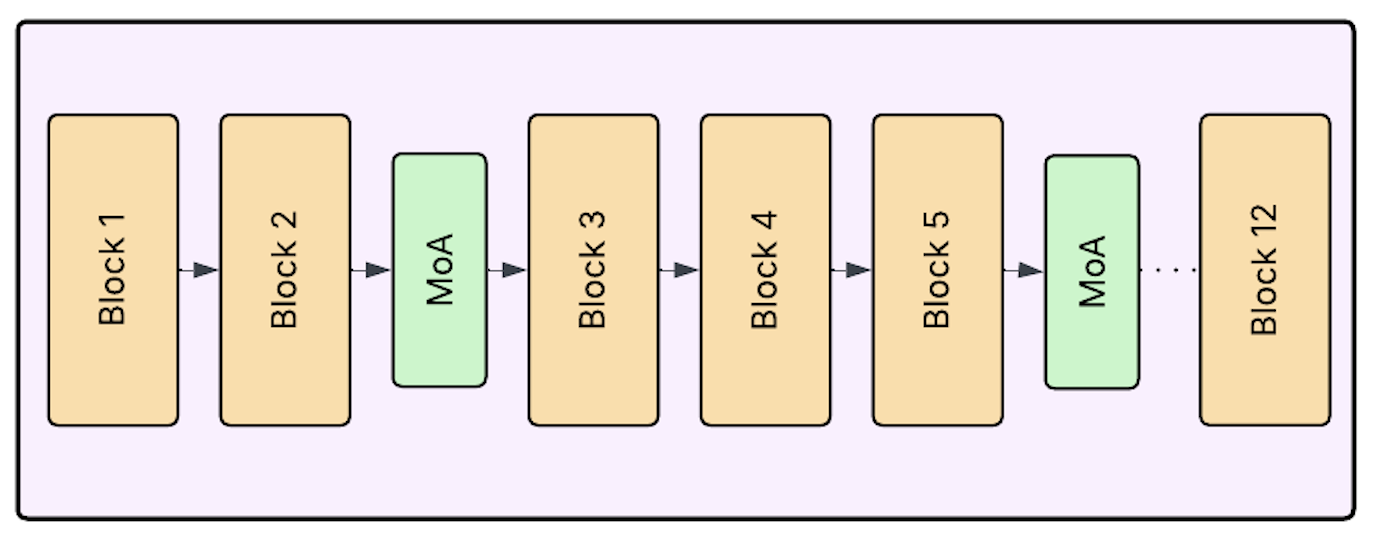
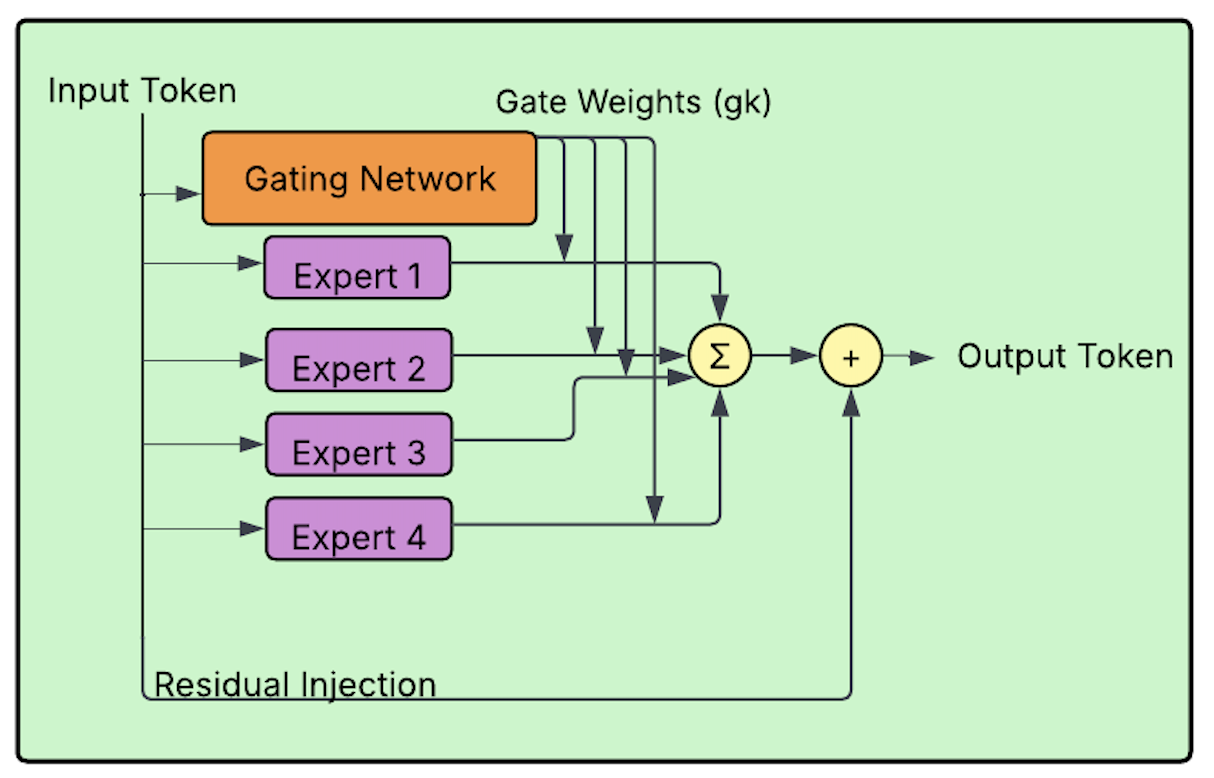
Figure 2: MoA modules (green) are selectively inserted at layers 2, 5, 8, 11 of the ViT-B/32 encoder; right, the internal structure of a MoA module.
Entropy of gating assignments is monitored during training to verify expert specialization and discourage collapse, though no explicit auxiliary loss is imposed.
Global Scene Context Fusion
Rather than using pixel-local or learned prompts, a global semantic context representing "indoor scene" is computed by averaging static CLIP text embeddings for a collection of relevant scene categories. This context is broadcast and concatenated to visual features before the prediction heads. The approach preserves the zero-shot transferability of CLIP’s semantics while providing robust, task-relevant priors in a parameter-free manner.
Dual-Head Depth Prediction and Discretization
The output module follows a hybrid architecture: depth bin classification with 128 discrete, fixed bins (determined optimal via ablation) and continuous regression. Classification benefits from stable supervision and coarse structure, while regression achieves fine-grained metric fidelity. The final prediction is a weighted sum of class and regression-based maps.
Composite Loss
Training combines per-pixel cross-entropy (classification), L1 loss (regression), and SI-Log loss (scale-robust regression), with hand-tuned weights (1.0, 1.0, 0.5). This composite enforces both categorical and geometric consistency, a critical requirement for dense prediction tasks.
Experimental Evaluation
Main Results
MoA-DepthCLIP is evaluated on NYU Depth V2 and compared to a reproduced DepthCLIP baseline. With the final configuration (ViT-B/32 + MoA + composite loss + 128 bins), the model attains δ1=0.745, δ2=0.841, RMSE=0.520, and AbsRel=0.321. This surpasses the baseline by a large margin in all metrics, especially the stricter thresholds, demonstrating the effect of fine-grained, globally-aware adaptation.
Notably, increasing from 10 (DepthCLIP) to 128 bins yields large gains in the more challenging accuracy metrics (δ1, δ2), confirming the value of high-resolution discretization when paired with semantic adaptation. The approach maintains a low parameter footprint relative to full fine-tuning or foundation model retraining.
Ablation Studies
Systematic ablation identifies 4 as the optimal number of experts in each MoA, balancing accuracy and computation. Bin count ablation shows accuracy monotonically improves up to 128 bins but degrades at 180 and 200 (likely due to label sparsity and over-discretization effects).
Implementation
All models are trained for 30 epochs on NYU Depth V2, using an H100 GPU, with AdamW (lr=$1e-5$), and batch size 8. Most of the ViT backbone is kept frozen, limiting adaptation parameters to MoA blocks and prediction heads.
Theoretical and Practical Implications
By introducing MoA-based adaptation into the domain of dense geometric prediction, this work demonstrates that VLMs’ semantic priors can be efficiently transferred for monocular depth prediction with minimal supervision and computational cost. The method provides empirical evidence that judicious placement of lightweight, parameter-efficient modules and global context fusion suffices to drastically improve geometric performance over prior zero-shot baselines. The framework offers a compelling alternative to monolithic foundation models, reducing memory and compute requirements while scaling gracefully to more complex tasks.
On the theoretical side, the deterministic MoA design suggests new directions for stable, interpretable specialization of vision transformers in settings where data or compute constraints preclude full fine-tuning. The fused prompt approach also provides a template for leveraging VLMs globally rather than locally, maximizing semantic coverage without overfitting.
Prospects for Future Research
Potential extensions include dynamic prompt selection via context-dependent attention, further sparsification/pruning of the adaptation pathways, or generalization to outdoor and scene-diverse datasets. Recoupling CLIP adaptation with other forms of geometric supervision (e.g., multi-tasking with segmentation or normals) could further unlock latent capabilities in large-scale VLMs. Additionally, the ablation-validated binning strategies inform future hybrid architectures balancing categorical and continuous prediction objectives. Application to low-data or resource-constrained settings is also strongly motivated by the framework’s efficiency.
Conclusion
MoA-DepthCLIP establishes a new benchmark in efficient CLIP adaptation for monocular depth estimation by synergizing a ViT-B/32 backbone, sparse Mixture-of-Adapters, and global scene prompt fusion, culminating in a hybrid output architecture and composite objective. Its strong performance, low parameter overhead, and versatility affirm the potential of modular, prompt-guided adaptation for vision-language transfer in dense prediction tasks. The framework invites broad extensions to further exploit VLM priors across geometric and scene understanding applications.