- The paper introduces PDA, a training-free defense that uses text-side interventions to significantly improve adversarial accuracy by over 30 points on benchmark datasets.
- It leverages a three-step process—paraphrase, decomposition, and aggregation—to diversify queries and cross-validate responses, mitigating the effects of adversarial noise.
- Experimental evaluations under white-box and black-box scenarios demonstrate PDA’s scalability, model-agnosticism, and compatibility with proprietary APIs as a practical defense strategy.
PDA: A Training-Free Text-Side Defense for Robust Vision-LLMs
Introduction and Motivation
Vision-LLMs (VLMs) underpin multimodal systems across application domains but remain fundamentally vulnerable to imperceptible adversarial image perturbations. Existing defenses, primarily leveraging adversarial training, prompt tuning, and test-time adaptation, are often hampered by high computational cost, limited generalization beyond seen attack types, and dependence on model internals. These regimes especially struggle in black-box or API-only deployment scenarios, where fine-grained gradient information or model weights are inaccessible.
The Paraphrase-Decomposition-Aggregation (PDA) framework (Figure 1) directly targets these limitations by offering a training-free, black-box defense mechanism that operates exclusively on the text interface of the victim VLM. Inspired by randomized smoothing, but crucially adapted to the multimodal and open-ended reasoning context of VLMs, PDA stabilizes inference by diversifying and cross-validating the linguistic queries without requiring modification or retraining of model parameters.
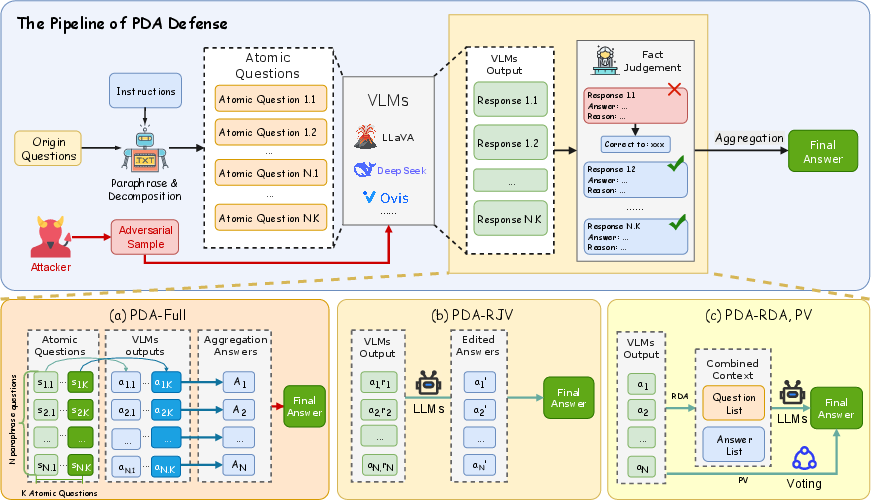
Figure 1: Pipeline of the proposed PDA defense and its variants. The architecture decomposes the original prompt into paraphrased forms, factors them into atomic questions, queries the VLM, and aggregates answers for the final robust output.
PDA Framework Design
PDA comprises three compositional steps:
- Paraphrase: An LLM-based paraphrase agent generates multiple semantically equivalent, linguistically distinct variations of the input query. This constructs a localized semantic neighborhood in prompt space, analogous to an Expectation-over-Transformations (EOT) principle, shifting the model's predictive anchor away from spike regions near adversarial decision boundaries.
- Decomposition: For each paraphrased prompt, a second LLM decomposes the complex or holistic query into atomic sub-questions targeting constrained visual facts—object existence, attribute verification, spatial relations, or counts. This step injects interpretable redundancy and minimizes reliance on holistic features likely to be flipped by adversarial noise, enhancing the interpretability and stability of the reasoning chain.
- Aggregation: The sub-questions are posed to the base VLM with the (potentially adversarial) image. Answer aggregation employs confidence- and consistency-aware rules, often leveraging additional LLM invocations to synthesize final predictions. Aggregate voting is guided by both majority and agreement, suppressing outlier or hijacked responses arising from adversarial corruption.
Multiple PDA variants instantiate this mechanism at different cost-robustness trade-offs, controlling where and how to elide decomposition or LLM-based aggregation, ranging from the full pipeline (PDA-Full) to the logically paraphrased voting wrapper (PDA-PV).
Robustness Evaluation
White-Box Threats
Under white-box PGD-based attack scenarios (ℓ∞ perturbation, ϵ=2/255), PDA achieves substantial gains over vanilla VLM inference and over text-side smoothing baselines. For instance, on VQA-v2 and ImageNet-D, PDA raises adversarial accuracy (ADV) by over 30 points in some backbones while maintaining near-identical clean accuracy; the aggregation of paraphrased and decomposed queries mitigates the effect of image-space adversarial perturbations (Figure 2).
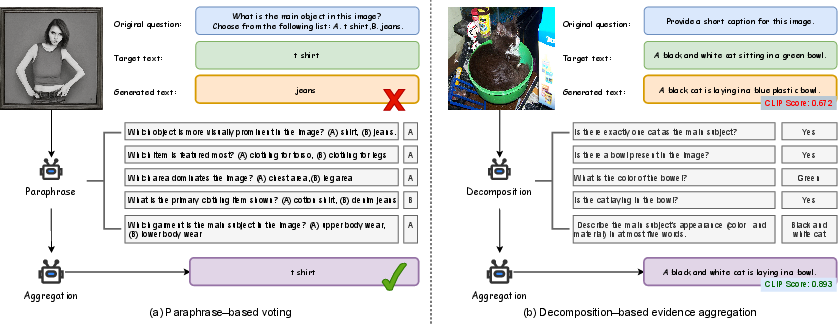
Figure 2: Qualitative effect of PDA. PDA corrects adversarial misclassification and generates faithful outputs by paraphrasing and decomposing the input.
Further stress-testing under increased perturbation budgets and adaptive EOT-based attacks demonstrates that PDA's robustness gains do not collapse even when the attacker optimizes over randomness in paraphrase and decomposition. Adversarial accuracy at higher ϵ values ({4,6,8}/255) degrades slowly for PDA but catastrophically for baselines, evidencing the efficacy of linguistic redundancy as a smoothing kernel.
Black-Box and Transfer Attacks
PDA demonstrates strong resilience under practical black-box scenarios, including transfer-based and query-based attacks (e.g., AttackVLM, AnyAttack). Robustness improvements remain consistent across attack modalities and target models, even when defending closed-source commercial LVLM APIs (e.g., GPT-5, Claude, Gemini). The defense remains model-agnostic and requires no information beyond black-box API access.
Comparison to Alternative Defenses
Relative to image-side pre-processing defenses such as JPEG compression and test-time random augmentation, PDA yields larger robustness improvements and the two regimes are largely complementary. Stacking image and text defenses produces additive effects. Reasoning-based prompt manipulation (CoT, self-consistency voting) are less successful under adversarial attack—these approaches amplify hallucination and do not recover perception corrupted by adversarial examples, underscoring the necessity of PDA's semantic diversification and atomic verification.
Qualitative examples in Figures 4–6 illustrate the stabilization of fine-grained recognition, repair of adversarially corrupted captions, and the down-weighting of inconsistent evidence across multiple tasks.
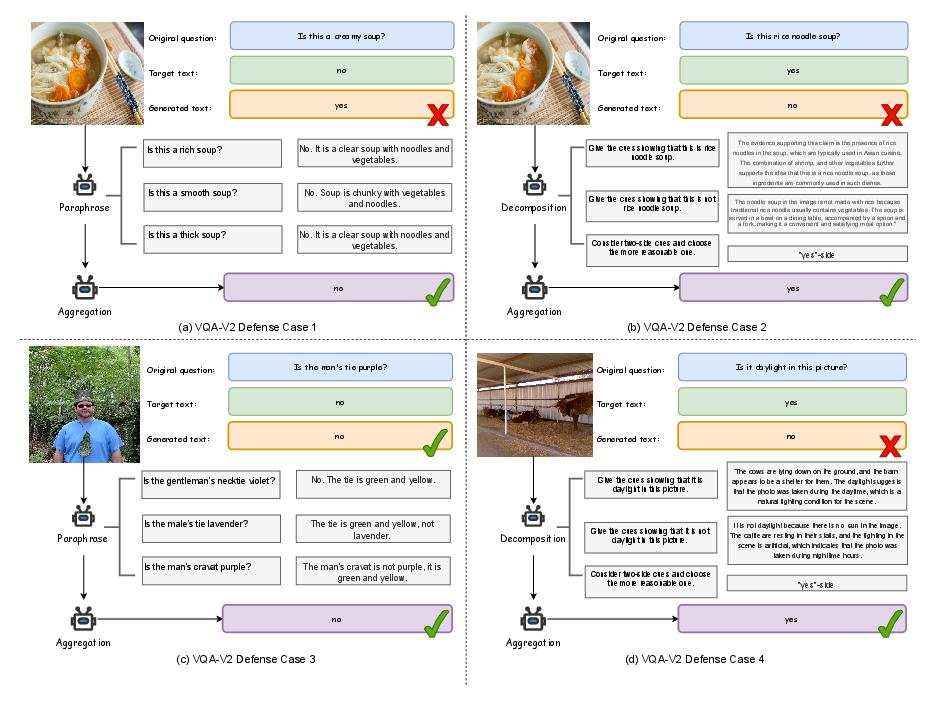
Figure 3: VQA-v2 qualitative examples demonstrating PDA's correction of adversarial errors.
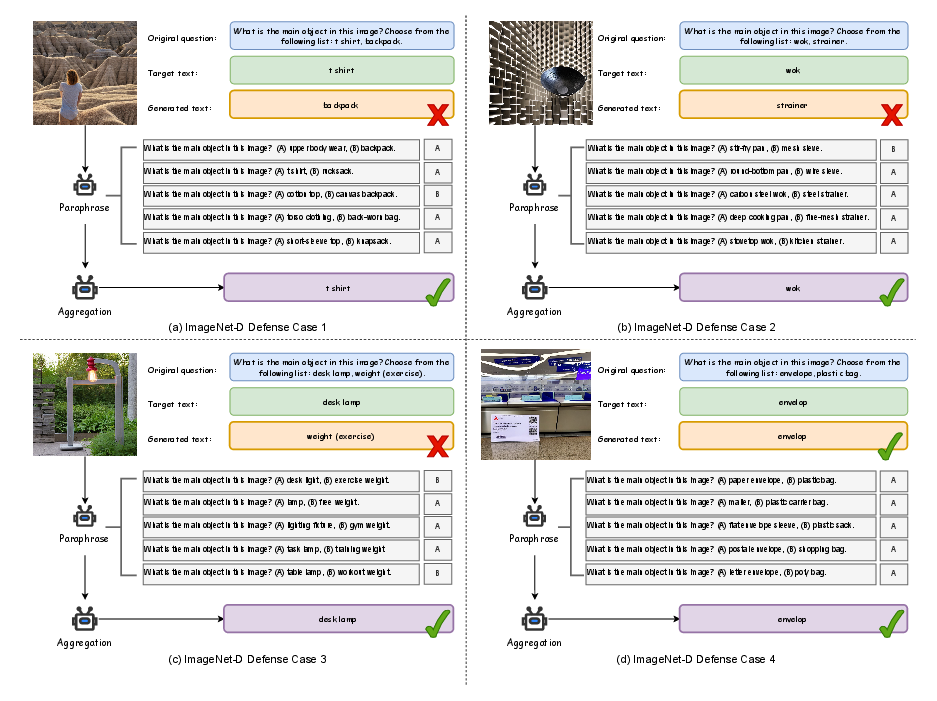
Figure 4: ImageNet-D examples showing PDA's ability to aggregate shape, part, and material cues for robust classification.
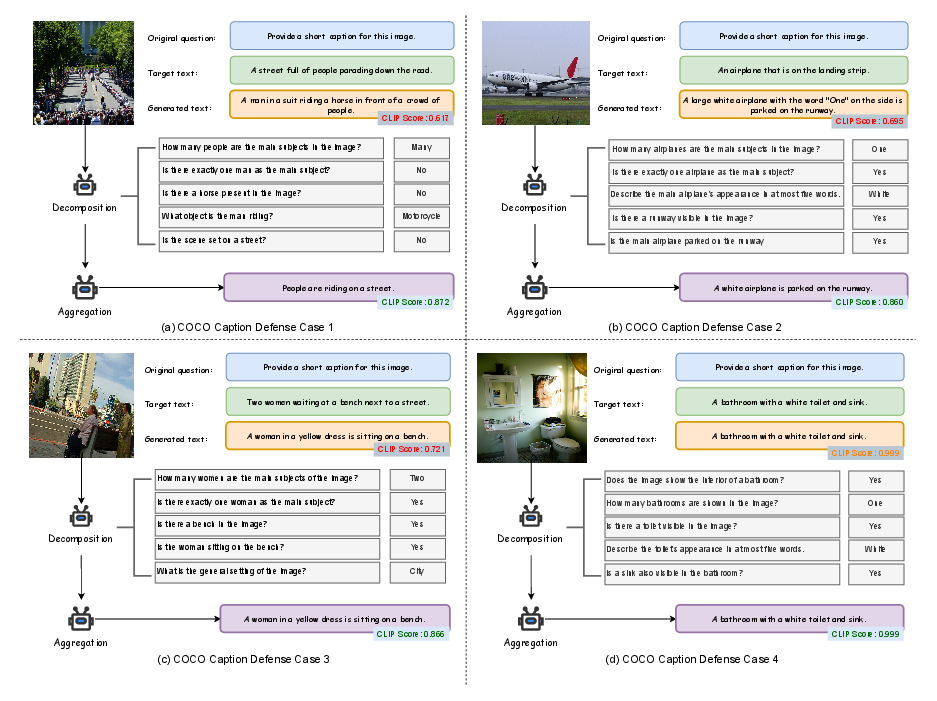
Figure 5: COCO captioning examples—PDA detects and revises conflicts, preserving visual consistency in spite of adversarial corruption.
Ablation: Variants and Design Choices
Systematic sweep experiments across PDA variants show that, while the full pipeline (PDA-Full) achieves peak robustness under challenging conditions, significantly compressed alternatives (PDA-RJV, PDA-PV) recover most of the accuracy at a fraction of the cost, particularly for structured closed-category tasks. The number of paraphrases (K) quickly saturates in terms of gains, and three to five paraphrases suffice. Aggregator agent strength plays a role in open-ended reasoning tasks, but compact LLMs suffice for binary options or short-answer aggregation.
Implications and Future Directions
PDA embodies a paradigm shift toward training-free, deployment-agnostic robustness interventions for VLMs. By shifting the defense to the test-time, text-side interface, it decouples robustification from finetuning and large-scale data requirements and can be universally applied to both open and proprietary models. Theoretically, PDA aligns with the rationale for randomized smoothing but expands semantic coverage beyond pixel and embedding noise to high-level linguistic transformations. Its success challenges blanket assumptions that adversarial robustness requires cost-intensive adversarial training or white-box access.
Future work may extend PDA by formalizing certified robustness guarantees—quantifying the protection radius in semantic prompt space and exploring optimal linguistic perturbation kernels. Further work is warranted on adaptive attack strategies that may attempt to co-opt paraphrasing agents or decompose the aggregation logic, as well as on the integration of PDA with on-the-fly model calibration or automated claim verification pipelines.
Conclusion
PDA establishes a robust, scalable, and training-free text-side defense strategy for vision-LLMs against adversarial image attacks. Its empirical and qualitative results demonstrate robustification of VLM inference under both white- and black-box conditions without degrading clean accuracy. PDA’s plug-and-play interface, architectural agnosticism, and validation across tasks and closed commercial APIs point toward its applicability as a practical defense primitive for deployed multimodal AI systems.
Reference:
"PDA: Text-Augmented Defense Framework for Robust Vision-LLMs against Adversarial Image Attacks" (2604.01010)