Understanding Transformers and Attention Mechanisms: An Introduction for Applied Mathematicians
Abstract: This document provides a brief introduction to the attention mechanism used in modern LLMs based on the Transformer architecture. We first illustrate how text is encoded as vectors and how the attention mechanism processes these vectors to encode semantic information. We then describe Multi-Headed Attention, examine how the Transformer architecture is built and look at some of its variants. Finally, we provide a glimpse at modern methods to reduce the computational and memory cost of attention, namely KV caching, Grouped Query attention and Latent Attention. This material is aimed at the applied mathematics community and was written as introductory presentation in the context of the IPAM Research Collaboration Workshop entitled "Randomized Numerical Linear Algebra" (RNLA), for the project: "Randomization in Transformer models".


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper is a friendly guide to how modern AI LLMs (like chatbots and translators) work on the inside. It explains:
- how text gets turned into numbers,
- how “attention” helps a model decide which words matter most,
- how Transformers (the model family behind today’s AI) are built, and
- how engineers make attention faster and less memory-hungry so models can handle long conversations.
It’s written for people who like math, but here we’ll keep it clear and simple.
Key goals and questions
The paper sets out to answer a few basic questions:
- How do computers turn words and sentences into numbers they can understand?
- What is “attention,” and why is it so powerful for understanding language?
- How is a Transformer made (encoders, decoders, and their parts)?
- How do newer tricks—like KV caching, Grouped Query Attention, and Latent Attention—make models faster and more memory efficient?
Methods and approach (explained with everyday ideas)
Instead of running experiments, the paper walks you through the building blocks step by step, using simple examples and math. Here’s the big picture, with plain-language analogies:
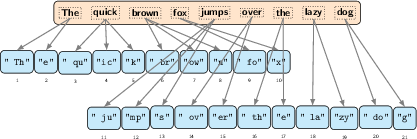
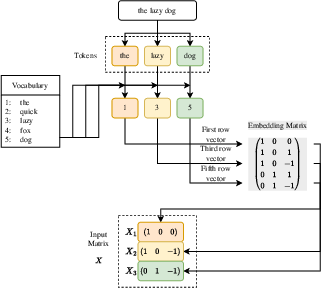
- Tokenization and embeddings: Text is split into small pieces called “tokens” (like words or word parts). Each token is turned into a list of numbers called a vector—think of it as a “fingerprint” that captures meaning. This step is called embedding.
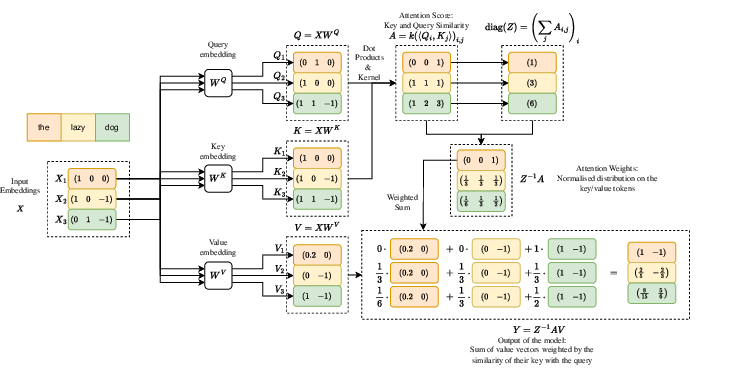
- Attention (the key idea):
- Each token creates a “query” (a question), and every other token provides a “key” (a label) and a “value” (the information).
- The model compares the query with all the keys to see which tokens are most relevant.
- It then mixes the values, giving more weight to the most relevant ones.
- A softmax step turns these relevance scores into percentages that add up to 100, like probabilities.
- Multi-Head Attention (many spotlights): Instead of one attention operation, the model uses many in parallel—called “heads.” Each head can focus on something different (like names, actions, or timing), and their outputs are combined.
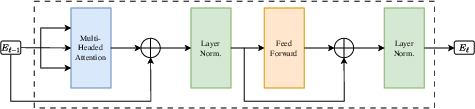
- Transformer layers:
- Self-attention: tokens in a sentence look at each other to understand context.
- Feed-forward network: a small neural “calculator” that transforms the information.
- Layer normalization: keeps the numbers stable so training is smoother.
- Skip connections: shortcut paths so information can flow easily through many layers without getting “lost.”
- Encoder and decoder:
- Encoders “read” and understand input (like a sentence in French).
- Decoders “write” an output (like the English translation).
- Cross-attention lets the decoder consult the encoder’s understanding.
- Masked/causal attention in decoders prevents “peeking into the future,” meaning the model only uses words it has already generated so it stays consistent.
- Popular variants:
- Encoder-only (like BERT) is great for understanding tasks (classifying, extracting info).
- Decoder-only (like GPT) is great for generating text (predicting the next word).
- Speed/Memory optimizations:
- KV caching: When chatting, the model saves “key” and “value” vectors for earlier tokens so it doesn’t recompute them every time. This speeds things up but uses more memory.
- Grouped Query Attention (GQA): Several attention heads share the same key/value “notes,” reducing the memory footprint.
- Latent Attention: Compresses the key/value information into a smaller shared “latent” space (like storing summaries instead of full notes). This can greatly cut memory and speed up calculations while keeping accuracy high.
Main takeaways and why they matter
Here are the core ideas you should remember:
- Attention lets models weigh the importance of words: It’s like aiming spotlights at the most helpful words when understanding or generating text.
- Multi-head attention captures different kinds of relationships at once: With multiple heads, the model can track who did what, when it happened, and how ideas connect.
- The Transformer is powerful because it stacks attention with simple neural layers and smart shortcuts: Layer normalization and skip connections make deep models easier to train and more stable.
- Masked/causal attention keeps generation honest: When writing a sentence one token at a time, the model doesn’t look ahead—it only uses what’s already written.
- Efficiency tricks make long conversations and big models practical:
- KV caching avoids repeating work during chat, speeding up responses.
- GQA shares key/value memory across multiple heads, saving space.
- Latent Attention compresses information into a smaller shared space and cleverly merges steps, cutting both compute and memory needs. This is especially helpful for long contexts and large models.
What this means going forward
- Better, faster AI: These techniques help models answer more quickly and handle longer inputs without running out of memory. That means smoother chats, better document analysis, and more capable tools.
- Smarter use of math: Ideas like low-rank compression (used in Latent Attention) show how mathematical tricks can make AI more efficient—important for making powerful models affordable and widely available.
- More flexible AI systems: Cross-attention is key to multimodal models that combine text with images or other data, opening the door to richer and more helpful AI assistants.
In short, the paper gives you a clear map of how Transformers and attention work, then shows modern, practical ways to make them faster and lighter—so they can keep up with bigger tasks and longer conversations.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of concrete gaps and open problems that remain unresolved in the paper and could guide future research.
- Tokenization design criteria: No quantitative framework is provided to select vocabulary size and granularity (e.g., morpheme-level vs subword) by task and language; actionable work includes deriving data-driven objectives that trade off semantic fidelity, compression, and compute/memory, especially for morphologically rich or low-resource languages.
- Embedding strategy choices: The paper does not analyze when to pretrain vs train-from-scratch token embeddings, nor the impact of jointly vs separately learned token and positional embeddings (e.g., concatenation vs addition) on downstream performance and stability.
- Kernel choice in attention: Beyond the softmax kernel, conditions on for normalization, expressivity, and stability are not characterized; there is no theoretical/empirical comparison of alternative kernels (e.g., cosine, Laplace, quadratic/NTK-inspired) or scaling strategies.
- Numerical stability of attention: The treatment omits overflow/underflow control (e.g., log-sum-exp softmax, scaling/clipping) and how low-precision formats (bf16/fp8) interact with masking () and long-sequence score magnitudes.
- Layer normalization variants: While Pre-LN, Post-LN, and RMSNorm are mentioned, there is no analysis of gradient flow, conditioning, or convergence guarantees across variants; open work includes formalizing stability criteria and predictive heuristics by depth and width.
- Complexity and throughput modeling: The asymptotic cost is given, but practical throughput/latency and memory models (including batch size, sequence length, fused kernels, FlashAttention-style tiling) are not provided.
- KV cache memory–bandwidth trade-offs: The paper introduces KV caching but does not quantify bandwidth/latency bottlenecks, cache placement (GPU vs CPU vs NVMe), sharding/slicing strategies, or eviction policies for very long contexts.
- Streaming/incremental attention: “Streaming attention” is mentioned without algorithms; missing are exact update rules, error bounds for approximations, and benchmarks for incremental computation under varying context growth patterns.
- GQA/MQA design choices: There is no guidance on head-to-group mappings, per-layer grouping, or adaptive grouping criteria; open questions include when K/V sharing degrades quality and how to select group sizes dynamically.
- Latent attention hyperparameterization: The paper does not provide rules or scaling laws for choosing and , nor quantify the expressivity–compression–throughput frontier relative to MHA/GQA.
- Expressivity and error bounds for MLA: Formal guarantees are missing on how close MLA can approximate MHA (with or without positional encodings); actionable work includes deriving approximation errors on attention weights and outputs as functions of , , and data spectra.
- Conversion between MHA/GQA and MLA: Only high-level remarks are given; needed are provable guarantees and practical procedures (with positional encodings) for converting pretrained models, along with bounds on degradation and recipes to recover performance post-conversion.
- Positional encodings compatible with MLA: The RoPE incompatibility with matrix merging is noted but not resolved; there is an open design problem to create position schemes that preserve MLA’s mergeability, maintain rotational invariances, and scale to long contexts.
- Efficient long-context mechanisms: Alternatives to caching (e.g., sliding-window/recurrence, ALiBi, position interpolation, linearized attention, Nyström/Performer/Linformer/Reformer, state-space models) are not surveyed or compared; missing are criteria to select methods by task, length, and hardware.
- Randomized/sketching approaches: Given the RNLA context, the paper does not develop randomized projections/sketches (e.g., Nyström, CountSketch) for , KV caches, or per-head compressions, nor provide error bounds and update rules for streaming contexts.
- Conditioning and spectral properties: No analysis of the spectrum/conditioning of under typical data distributions, nor how normalization and kernels affect concentration and gradient stability; results here could guide rank selection and sketch sizes.
- Precision and quantization of KV/L caches: The impact of per-layer/per-head quantization (int8/fp8) of caches on attention weights and quality is not addressed; actionable work includes dynamic-precision schemes with error control.
- Parallelism and distributed systems: The impact of pipeline/tensor/sequence parallelism on attention (compute-communication trade-offs), KV cache sharding, and cross-device synchronization is not modeled; guidelines for optimal partitioning by workload and hardware are missing.
- Mixture-of-Experts (MoE) interactions: DeepSeek V2 is MoE-based, but the paper does not analyze how MLA interacts with expert routing, memory footprints of expert-specific caches, or communication overheads; research is needed on cache sharing across experts.
- Masking implementation and efficiency: Alternative masking implementations (pre-/post-kernel, sparse layouts) and their memory/computation implications in fused kernels are not discussed; best practices for large masks and block-sparse patterns are needed.
- Causal vs bidirectional pretraining mismatch: The effect of causal masking (decoder-only) vs bidirectional objectives (encoder-only) on downstream tasks and fine-tuning is not explored; guidelines for selecting objectives by task and data regime are missing.
- Evaluation methodology: There are no empirical comparisons quantifying the perplexity/accuracy–throughput–memory trade-offs of MHA, GQA, and MLA across sequence lengths and hardware; standardized benchmarks and profiling protocols are needed.
- Notation and dimensional consistency: Several dimension annotations are inconsistent or ambiguous (e.g., , per-head shapes, indexing), which can hinder reproducibility; a precise catalog of tensor shapes and invariants across variants would aid implementation and verification.
- Multimodal cross-attention: The multimodal remark lacks treatment of alignment training (contrastive/ITC losses), calibration of shared spaces, and robustness under domain shift; open work includes systematic methods to co-train and regularize shared embeddings.
Practical Applications
Immediate Applications
Below are actionable, near-term use cases that can be deployed with today’s models and infrastructure, grounded in the paper’s formulations of attention, Transformer variants, and memory optimizations (KV caching, Grouped Query Attention, streaming attention).
- Memory‑optimized LLM serving using KV caching and Grouped Query Attention (GQA)
- Sectors: software/AI infrastructure, customer support, finance, e‑commerce
- Tools/products/workflows: cache‑aware inference servers that persist per‑layer KV across tokens/turns; configuration to reduce KV heads via GQA; quantized KV caches to fit GPU/TPU memory budgets; capacity planning using the paper’s cache size formulas (number of layers × heads × tokens × dimensions)
- Assumptions/dependencies: autoregressive/causal generation use cases; sufficient device/GPU memory bandwidth; acceptance of small quality trade‑offs when reducing KV heads or precision; session‑level privacy handling for cached content
- Low‑latency chat and assistant experiences via streaming attention
- Sectors: customer experience (CX), education/tutoring, internal productivity tools
- Tools/products/workflows: reuse KV from prior turns and compute only new queries; session managers to bind KV to conversation context; reduced per‑turn latency at steady‑state
- Assumptions/dependencies: consistent dialog session boundaries; secure and compliant storage of cached KV; primarily applicable to decoder‑only, causal attention workflows
- Task‑appropriate tokenization and embedding choices to control cost/quality
- Sectors: enterprise NLP, media, legal, multilingual products
- Tools/products/workflows: vocabulary selection tuned to task granularity (classification vs. generation) to minimize sequence length and memory; embedding dimension sizing guided by model/spec trade‑offs described in the paper
- Assumptions/dependencies: retraining or fine‑tuning required after tokenizer/vocabulary changes; language‑specific tokenization behavior; potential bias/coverage considerations
- Architecture selection aligned to task (encoder‑only vs. decoder‑only)
- Sectors: healthcare (clinical coding/classification), document processing, code review
- Tools/products/workflows: deploy encoder‑only models for classification/extraction; decoder‑only for generation/next‑token prediction; mixed encoder‑decoder for translation and structured seq‑to‑seq
- Assumptions/dependencies: availability of fine‑tuning data for the chosen head; latency/throughput constraints differ across architectures
- Multimodal prototyping through cross‑attention
- Sectors: media search, ecommerce (visual search), healthcare imaging annotation
- Tools/products/workflows: pair a vision encoder with a text decoder using cross‑attention to align image features with language tokens; build lightweight captioning or VQA pilots using shared embedding spaces
- Assumptions/dependencies: training data to align modalities; robustness of shared embeddings; compute budget for cross‑attention during inference
- Training stability/efficiency improvements via normalization choices
- Sectors: SMEs and labs training small/medium models; academia
- Tools/products/workflows: use Pre‑LayerNorm or RMSNorm for easier training and reduced compute; apply skip connections as recommended to mitigate vanishing gradients
- Assumptions/dependencies: potential performance trade‑offs versus Post‑LN; hyperparameter tuning needed to match task
- Long‑context features with budgeted KV management
- Sectors: legal and research (long documents), software engineering (long code contexts)
- Tools/products/workflows: windowed or chunked attention with KV eviction strategies; planning GPU memory using the paper’s KV sizing and per‑layer/head accounting; selective caching per head/layer
- Assumptions/dependencies: potential degradation from context truncation; task‑dependent sensitivity to long‑range dependencies
- Instructional and benchmarking materials for courses and internal upskilling
- Sectors: academia, industry L&D
- Tools/products/workflows: adopt the paper’s formal attention equations, masking schemes, and kernel choices to build clear lab assignments and reproducible baselines for MHA/GQA; compare softmax kernels and alternative normalizations
- Assumptions/dependencies: computing resources for hands‑on labs; alignment with institutional curriculum and licensing for datasets
Long‑Term Applications
These opportunities build on the paper’s latent attention formalism and optimization insights but require further research, training, tooling, or ecosystem support before broad deployment.
- Latent Attention (MLA)–based inference stacks and model conversion pipelines
- Sectors: software/AI infrastructure, cloud platforms, edge AI
- Tools/products/workflows: convert pre‑trained MHA/GQA models into latent‑attention form; serve a single per‑token latent cache across heads; integrate weight‑merging to reduce compute; specialized “latent‑cache” memory managers
- Assumptions/dependencies: robust positional embedding solutions for MLA (e.g., RoPE variants) to preserve quality; reliable conversion methods and retraining to recover performance; ecosystem support in inference runtimes
- Hardware and systems co‑design for cache‑centric attention
- Sectors: semiconductors, datacenter systems
- Tools/products/workflows: memory hierarchies optimized for KV/latent caches; fused kernels for merged weight paths; scheduler support for streaming attention at scale
- Assumptions/dependencies: multi‑year hardware roadmaps; standardized cache formats; proven workload benefits across model families
- Sub‑quadratic attention via randomized numerical linear algebra (RNLA)
- Sectors: research, large‑scale inference providers
- Tools/products/workflows: randomized low‑rank/sampling approximations for QKT; kernel alternatives to softmax that admit efficient estimation; hybrid exact/approximate attention regimes
- Assumptions/dependencies: rigorous accuracy–efficiency guarantees; stability across domains; integration with position encodings and masking
- Standardized cache compression and governance for privacy‑sensitive deployments
- Sectors: healthcare, finance, public sector
- Tools/products/workflows: on‑the‑fly encrypted KV/latent caches with time‑to‑live; cache scrubbing and audit trails; policy‑driven retention aligned to data protection rules
- Assumptions/dependencies: regulatory clarity on ephemeral model states; minimal latency overhead from encryption/compliance layers
- Green AI procurement and reporting frameworks focused on attention memory
- Sectors: policy, enterprise IT governance, sustainability
- Tools/products/workflows: require vendors to report KV/latent cache footprints and energy per token; incentives for memory‑efficient architectures (GQA/MLA) in public tenders
- Assumptions/dependencies: accepted measurement standards; third‑party verification; alignment with broader AI sustainability metrics
- Pervasive on‑device assistants with long context at lower cost
- Sectors: consumer devices, automotive, field service
- Tools/products/workflows: deploy latent‑ or GQA‑optimized models on phones/laptops for offline summarization, note‑taking, coding help; leverage compact caches for persistent local memory
- Assumptions/dependencies: mature MLA/GQA model zoo; efficient positional embeddings; device‑class accelerators
- Robust multimodal systems via advanced cross‑attention and shared embeddings
- Sectors: robotics, AR/VR, industrial inspection
- Tools/products/workflows: scalable cross‑attention pipelines that align language with vision/audio; domain‑specific pretraining for instruction following in the real world
- Assumptions/dependencies: large, high‑quality multimodal datasets; safety evaluation; real‑time constraints met by optimized attention
Each application’s feasibility hinges on the trade‑offs highlighted in the paper: memory–latency–quality balances in KV/GQA/MLA; the interaction of positional embeddings with latent factorization; and the task‑specific suitability of encoder/decoder architectures.
Glossary
- Attention heads: Parallel subcomponents in multi-head attention that attend to different representation subspaces. "multiple parallel attention heads can be used on the same input vectors."
- Attention mechanism: Module that computes weighted combinations of values based on query–key similarity to encode token relationships. "Attention mechanisms, the building blocks of the Transformer architecture \cite{vaswaniAttentionAllYou2017}, allow encoding of semantic information between tokens through a database-like structure"
- Attention weights: Normalized attention scores that act like a probability distribution over keys for each query. "Normalized attention scores, i.e., the product , are known in the literature as attention weights."
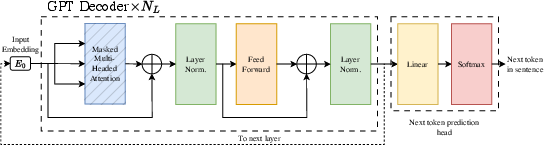
- Causal self-attention: Self-attention restricted so each position attends only to itself and past positions to preserve autoregressive causality. "In causal self-attention, the principle is that as the sentences are formed token by token in a sequential manner and the previous tokens are fixed, the addition of new tokens should not affect the previous parts of the sentence."
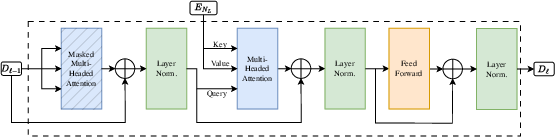
- Cross-attention: Attention where queries come from one sequence and keys/values from another, enabling conditioning on encoder outputs. "the cross-attention sublayer where the key/value vectors are constructed not from the decoder state but from the final encoder state"
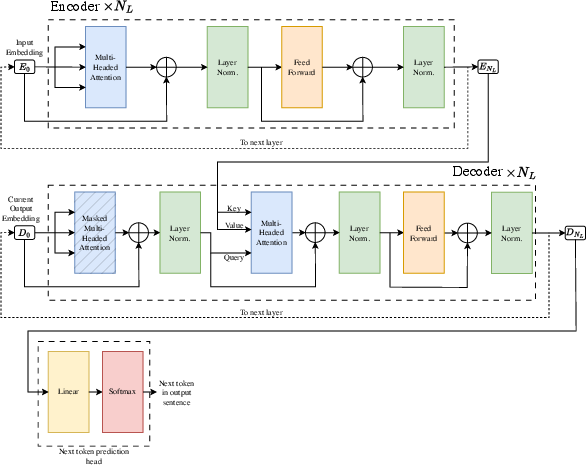
- Decoder layer: Transformer block that applies masked self-attention, cross-attention, and feed-forward transformations to generate outputs. "Decoder layers in the Transformer architecture have two differences with the encoder layers"
- Encoder-decoder architecture: Two-stage model where an encoder maps inputs to intermediate representations and a decoder generates outputs from them. "a common method used for machine translation of one language to another is the use of an encoder-decoder architecture"
- Encoder layer: Transformer block that applies self-attention and feed-forward transformations to encode inputs. "Each encoder layer consists of the following components, assembled as shown in Figure \ref{fig:t_enc},"
- Feed forward sublayer: Position-wise neural network sublayer applied after attention to transform representations. "Feed forward sublayer: It is the basic building block of neural networks, it outputs "
- Gated Linear Unit (GLU): Activation-based layer using gating mechanisms to improve feed-forward expressivity. "parametric Gated Linear Unit (GLU) variants \cite{shazeerGLUVariantsImprove2020} have been favored in state-of-the-art models"
- Grouped Query Attention (GQA): Technique where multiple query heads share the same key/value heads to reduce KV memory. "This is known as Grouped Query Attention (GQA), and in the limit of a single key-value head for all query heads it is sometimes referred to as Multi-Query Attention (MQA)."
- Hadamard product: Element-wise product of two matrices or vectors. "we denote by the Hadamard or term-wise product."
- Kernel (in attention): Function mapping query–key pairs to scalar similarity scores used to weight values. "The similarity metric is usually given in the form of a kernel"
- KV caching: Storing key and value vectors from prior tokens to avoid recomputation during incremental decoding. "One of the main memory bottlenecks of modern LLMs arises due to what is known as KV caching."
- KV heads: The number of independent key/value head groups shared across multiple query heads in GQA. "the number of key/value matrices is denoted as the number of KV heads above."
- Latent attention: Attention variant that builds keys/values (and possibly queries) from a shared low-rank latent space to reduce memory and compute. "The main idea behind Latent Attention is to construct a shared low-rank latent embedding from which the key and value vectors are formed for each head through a linear application."
- Latent subspace: Low-dimensional shared space from which per-head key/value (and query) projections are derived. "the latent attention method uses two latent subspaces, of dimensions and "
- Layer normalization: Normalization technique applied across features within a layer to stabilize training. "layer normalization\cite{baLayerNormalization2016} constructs a vector $\tilde { x}=\frac{ x-\mu}{\sqrt{\sigma^2+\epsilon}$ of mean $0$ and variance $1$"
- Masked attention: Attention with a mask that prevents certain query–key pairs from contributing, often to enforce causality. "More formally, masked attention consists in restricting the subset of key-value tokens seen by each query token"
- Mixture-of-Experts (MoE): Architecture that routes inputs to a subset of specialized expert networks to increase capacity efficiently. "Note that DeepSeekV2 is a mixture-of-experts model with latent attention"
- Multi-Headed Attention (MHA): Attention mechanism using multiple parallel heads and then combining their outputs. "Given the outputs of each head, the output of the multi-headed attention mechanism is combined into a single output $Y\inR^{N_{Q}\times d_{\text{out}$"
- Multi-Query Attention (MQA): Extreme case of GQA with a single shared key/value head across all query heads. "it is sometimes referred to as Multi-Query Attention (MQA)."
- Positional embeddings: Encodings added to token embeddings to inject position information into the model. "positional or feature embeddings (such as an embedding of the sentence to which the token belongs) can be applied to the sequence of token embedding vectors"
- Post-Layer Normalization: Architecture applying layer normalization after sublayers, as in the original Transformer. "have made use of both Pre-Layer and Post-Layer Normalization"
- Pre-Layer Normalization: Architecture applying layer normalization before sublayers to ease optimization and gradient flow. "have made use of both Pre-Layer and Post-Layer Normalization"
- RMS-Normalization: Normalization that rescales by the root-mean-square of features without centering or learned bias. "RMS-Normalization procedure which consists in only rescaling the input with respect to its Root-mean-squared norm without recentering or adding a bias"
- Rotary Position Embeddings (RoPE): Positional encoding method that rotates query/key components to encode relative positions. "Rotary Position Embeddings \cite{suRoFormerEnhancedTransformer2023} (RoPE)"
- Scaled exponential kernel: The exp of scaled dot products used to compute attention scores in the original Transformer. "The most common kernel is the scaled exponential kernel used in the original Transformer \cite{vaswaniAttentionAllYou2017}"
- Self-attention: Attention where queries, keys, and values come from the same sequence. "Multi-headed self-attention sublayer:"
- Skip connections: Residual connections that add a sublayer’s input to its output to improve gradient flow. "Skip connections consist in adding to the output of a sublayer its input."
- Softmax: Normalization function turning scores into a probability distribution over keys for each query. "The attention weights in this context are equal to the softmax function, $\sigma:R^N\toR^N$"
- Streaming attention: Incremental attention where new queries attend to cached past keys/values without recomputing the full sequence. "this is known as streaming attention \cite{hanStreamingAttentionApproximation2025}."
- Transformer architecture: Neural sequence model built from stacked attention and feed-forward layers with residual and normalization components. "The complete Transformer architecture, as can be seen in Figure~\ref{fig:t_arch}, is modelled for, and trained on, the task of machine translation"
Collections
Sign up for free to add this paper to one or more collections.