- The paper presents a comprehensive audit of Gemini 2.5 Pro by evaluating 11,943 video-grounded claims using triplicate LLM judges.
- It employs metrics like transcript similarity and noun overlap to assess verifiability, revealing notable rates of unsupported, overstated claims.
- The study highlights that strong semantic alignment reduces error rates, underlining critical implications for trust in multimodal generative search systems.
Auditing the Reliability of Multimodal Generative Search: A Large-Scale Forensic Evaluation
Introduction
Multimodal LLMs (MLLMs) serve increasingly as generative search engines, synthesizing responses by retrieving and integrating multimedia content, notably YouTube videos, and projecting authority via explicit source citations. Given the rapid adoption of such systems for high-stakes queries in medical, financial, and general contexts, establishing whether video-grounded claims genuinely align with cited sources has become critical. This paper presents an extensive black-box audit of Gemini 2.5 Pro—the flagship MLLM underpinning Google Search's generative video retrieval—focusing on the factual verifiability of 11,943 video-grounded claims across medical, economic, and general domains (2604.00944).
Methodology
The audit proceeds by structuring queries across three domains, prompting Gemini 2.5 Pro to autonomously generate fact-based responses that cite YouTube videos as evidence. For each claim–video pair, the audit extracts textual evidence from the cited video: Whisper ASR-based transcript, title, description, and upload date. Triplicate LLM judges (Gemini 3 Flash, Grok 4.1 Fast, gpt-5.2) independently verify whether claims are adequately supported by their corresponding video evidence, classifying unsupported claims by failure taxonomy (contradiction, overstatement, unverifiability, etc.).
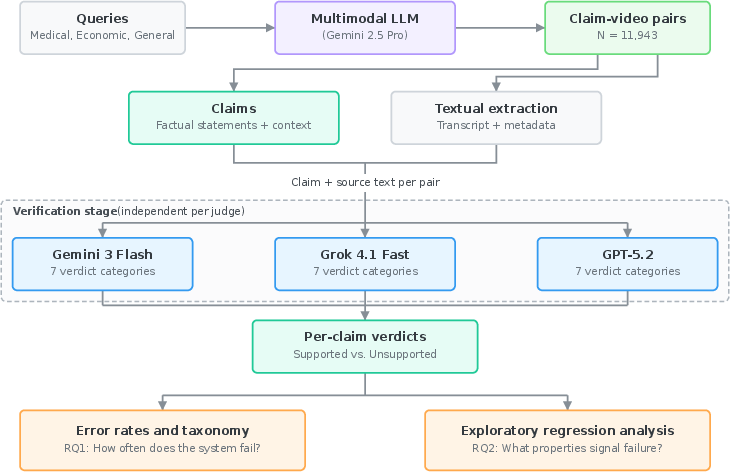
Figure 1: Overview of the audit pipeline, including multi-domain query submission, video content extraction, and independent LLM judge-based claim verification.
The dataset reflects strict filtering of claims for length, attributions, and metadata validity, with detailed distributions by claim length, video duration, and temporal profile examined across domains.
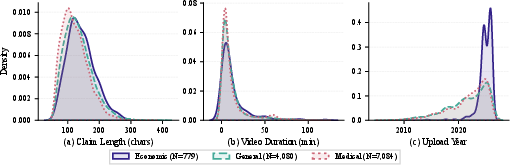
Figure 2: Dataset characteristics including claim length, video durations, and the temporal span of cited videos, demonstrating domain consistency and coverage.
Verification protocol ensures claims are only judged based on textually extractable evidence, without leveraging visual cues, and LLM judgements are systematically validated against expert human annotation for reliability.
Results
Judge Agreement and Error Rate Variance
Pairwise agreement is high across judges (mean 87.7%), but strictness varies, with gpt-5.2 flagging significantly more unsupported claims than Gemini-3 and Grok-4.1 (up to 18.7% versus 3.7%–6.5%). Notably, judge discordance is most pronounced for claims at the ambiguous boundary between extractive summary and unsupported extrapolation.
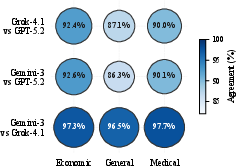
Figure 3: LLM judge agreement rates; high concordance between Gemini-3 and Grok-4.1, lower agreement between these and gpt-5.2 due to stricter criteria.
Unsupported rates stratified by judge and domain reveal systemic under-verification relative to citation guarantees, with strict scrutiny resulting in one-fifth of general claims not grounded in their cited source.
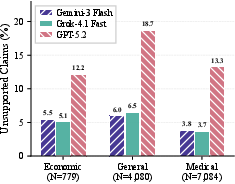
Figure 4: Unsupported claim rates by domain and judge, indicating substantial undetected overstatement propensity.
Failure Taxonomy
A dominant proportion of failures is not due to explicit source contradiction, but to overstated claims or injection of unverifiable specificities—precise details or entities not present in the source, but which increase the appearance of authority. gpt-5.2 is significantly more likely to flag overstatements, while Gemini-3 and Grok-4.1 more frequently detect unverifiable claims.
Feature Attribution for Verification Failure
Logistic regression across judge–domain combinations identifies two robust protective factors: high lexical concordance (noun overlap) and semantic transcript similarity between a claim and video transcript content. These operate as independent, additive detectors of faithful claim generation, with minimal multicollinearity and high predictive value.
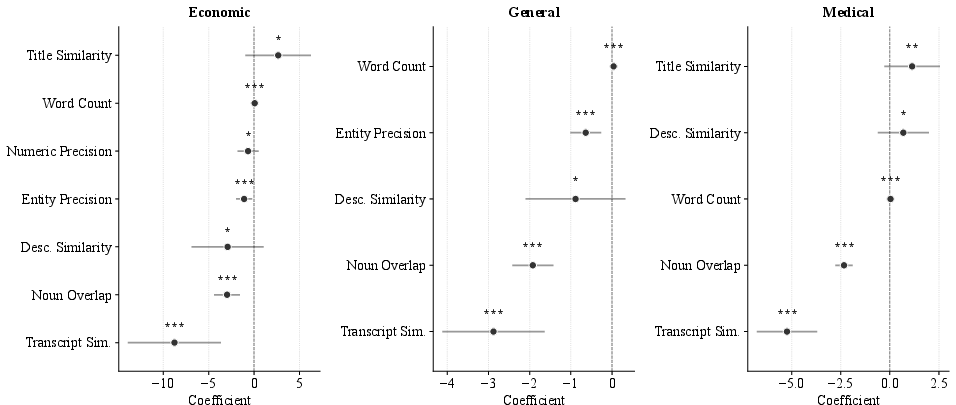
Figure 5: Significant regression coefficients by domain, revealing transcript similarity and noun overlap as consistent, strong predictors of support.
Strong semantic alignment to the transcript drastically reduces error probability, as visualized in the monotonic downward relationship between transcript similarity and error rate.
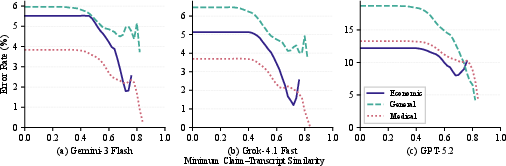
Figure 6: Error rates decline sharply as claim–transcript semantic similarity increases, across all judges.
Joint analysis of transcript semantic similarity and lexical overlap reveals a synergistic safe zone: departures from the video's vocabulary and meaning both sharply elevate error rates.
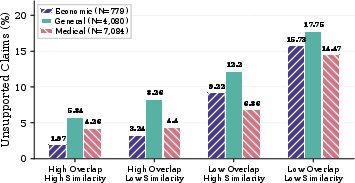
Figure 7: Error rates stratified by lexical overlap and transcript similarity, highlighting maximal risk when both fidelity indicators are low.
Supplementary Visual Grounding
A stratified re-evaluation allowing direct access to video tokens recovers support for an additional ~12.5% of claims, indicating a non-trivial but minority subset require visual information (e.g., on-screen text, diagrams) for verification. However, the predominant source of support—and failure—remains the transcript.
Discussion
Epistemic and Social Implications
The findings establish that, while the majority of video-grounded claims are supported, a non-negligible tail of unsupported statements—often subtly unverifiable or overstated—remains. These forms of epistemic drift exploit user trust by virtue of precise, authoritative citation formatting, yet are largely irrecoverable by end users due to the high cost of audiovisual verification. This presents a materially distinct trust liability when compared to text retrieval-augmented paradigms, where citations are more easily scrutinized.
The systematic association between semantic/lexical divergence and unfaithfulness points to the risk of MLLMs synthesizing detailed statements from parametric knowledge while projecting evidence-backed accountability they do not substantiate. Given the increasing use of such generative search agents for sensitive domains, this misalignment has direct implications for the spread of misinformation and the calibration of user trust.
Methodological Limitations
This black-box audit does not disentangle errors arising at the retrieval stage versus parametric claim fabrication. Only claims verifiable through text-based evidence are scored; subset analysis indicates modest additional verification capacity from visual modalities. The audit is restricted to Gemini 2.5 Pro, the only currently deployed generative search MLLM with integrated video retrieval, limiting immediate generalization to other emerging systems.
Conclusion
This work delivers the first comprehensive audit quantifying verifiability and failure modes in multimodal generative search via large-scale LLM judge analysis. A significant minority of video-grounded claims are inadequately supported, predominantly by subtle overstatement and unverifiable specificity. Claims with lower transcript similarity and reduced vocabulary overlap are statistically much more likely to be unsourced, comprising a precise operational risk for user trust in AI search systems. As MLLMs further mediate access to video knowledge, systematic, domain-wide audits and advances in fine-grained content attribution are essential to uphold factual grounding and mitigate emergent vectors for mis- or disinformation.
Reference:
Erfan Samieyan Sahneh, Luca Maria Aiello. "Auditing the Reliability of Multimodal Generative Search" (2604.00944).