Multimodal Fact-Level Attribution for Verifiable Reasoning
Abstract: Multimodal LLMs (MLLMs) are increasingly used for real-world tasks involving multi-step reasoning and long-form generation, where reliability requires grounding model outputs in heterogeneous input sources and verifying individual factual claims. However, existing multimodal grounding benchmarks and evaluation methods focus on simplified, observation-based scenarios or limited modalities and fail to assess attribution in complex multimodal reasoning. We introduce MuRGAt (Multimodal Reasoning with Grounded Attribution), a benchmark for evaluating fact-level multimodal attribution in settings that require reasoning beyond direct observation. Given inputs spanning video, audio, and other modalities, MuRGAt requires models to generate answers with explicit reasoning and precise citations, where each citation specifies both modality and temporal segments. To enable reliable assessment, we introduce an automatic evaluation framework that strongly correlates with human judgments. Benchmarking with human and automated scores reveals that even strong MLLMs frequently hallucinate citations despite correct reasoning. Moreover, we observe a key trade-off: increasing reasoning depth or enforcing structured grounding often degrades accuracy, highlighting a significant gap between internal reasoning and verifiable attribution.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces MuRGAt (Multimodal Reasoning with Grounded Attribution), a new way to test AI models that look at more than one kind of input at once—like video, audio, and graphs. The big idea is simple: when an AI answers a question and explains its reasoning, it should also show exactly where in the input (which modality and what time range) each factual claim comes from. That makes the answer verifiable, like showing your work and pointing to the page and line in a book—or the exact timestamp in a video—where you found it.
What questions are the researchers asking?
The authors focus on a few easy-to-understand questions:
- Can AI models not just answer questions, but also back up each factual claim with precise evidence across different media (video, audio, figures)?
- Can we fairly score how well models “show their sources” at a detailed, fact-by-fact level?
- Do models still give correct answers when we make them cite evidence, or does that make them worse?
- Can we build an automatic scoring system that agrees with human judges about whether the citations are good?
How did they study it?
Think of this like grading a school essay where the student must:
- answer the question,
- explain their steps,
- and include footnotes that point to exact parts of a video, audio clip, or figure that prove each fact.
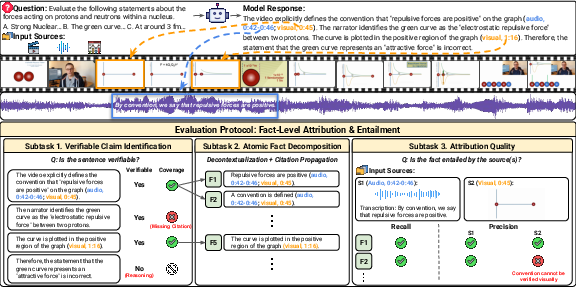
The MuRGAt task
- The model is given multimodal inputs (e.g., video plus audio) and a question.
- It must write an answer with reasoning.
- For each sentence that states something you can directly check in the inputs (a “verifiable claim”), it must add citations like (audio, 0:42–0:46) or (video, 1:10–1:14).
The three-step checking process
To fairly judge these answers, the authors break the evaluation into three simple steps:
- Step 1: Verifiable claim identification Separate sentences that can be directly checked from those that are just reasoning or opinions. Only the checkable ones need citations.
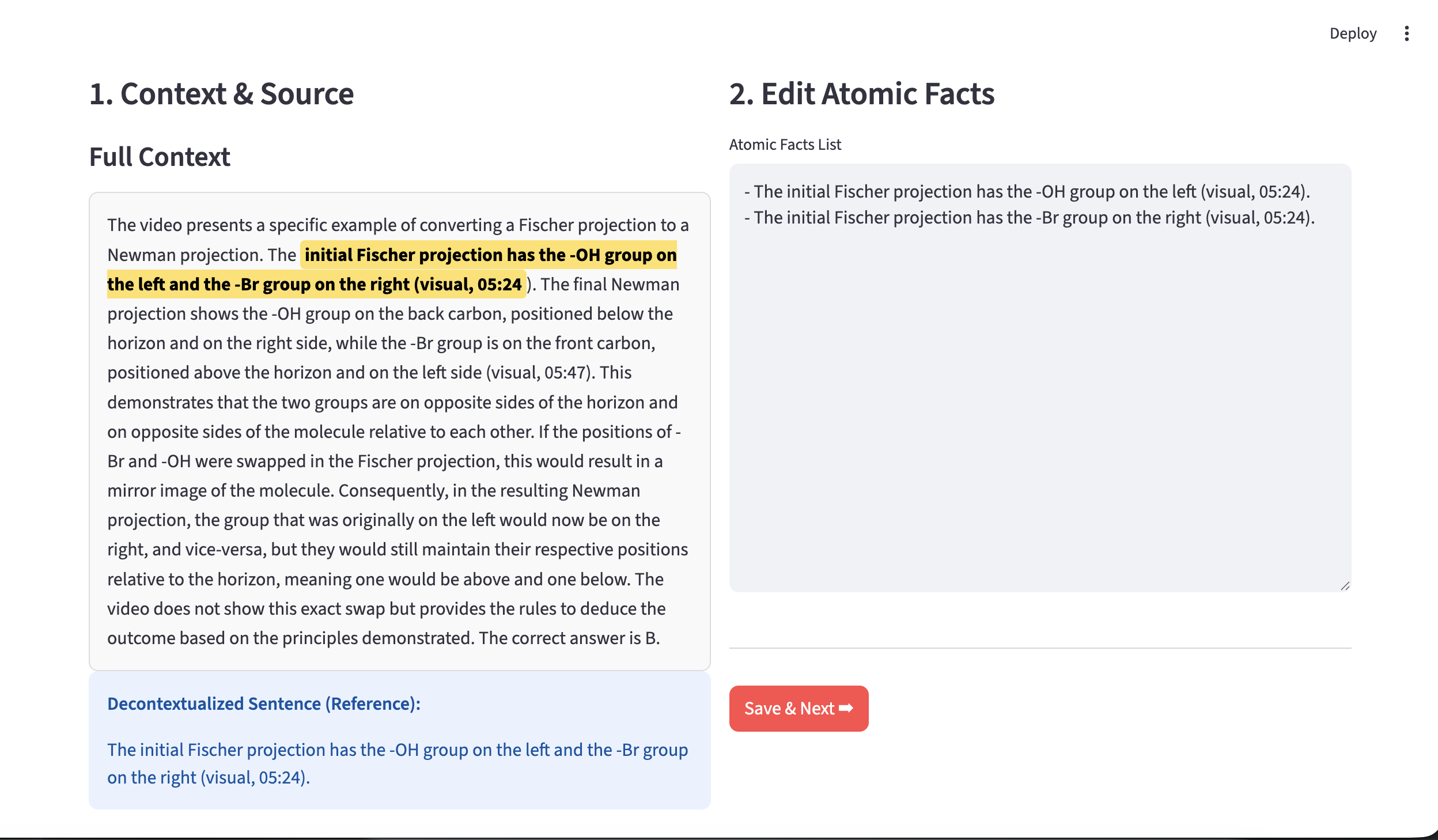
- Step 2: Atomic fact decomposition Break each checkable sentence into tiny, single facts (“atomic facts”). Example: “The chart shows a red line” and “The red line goes up” are two separate facts.
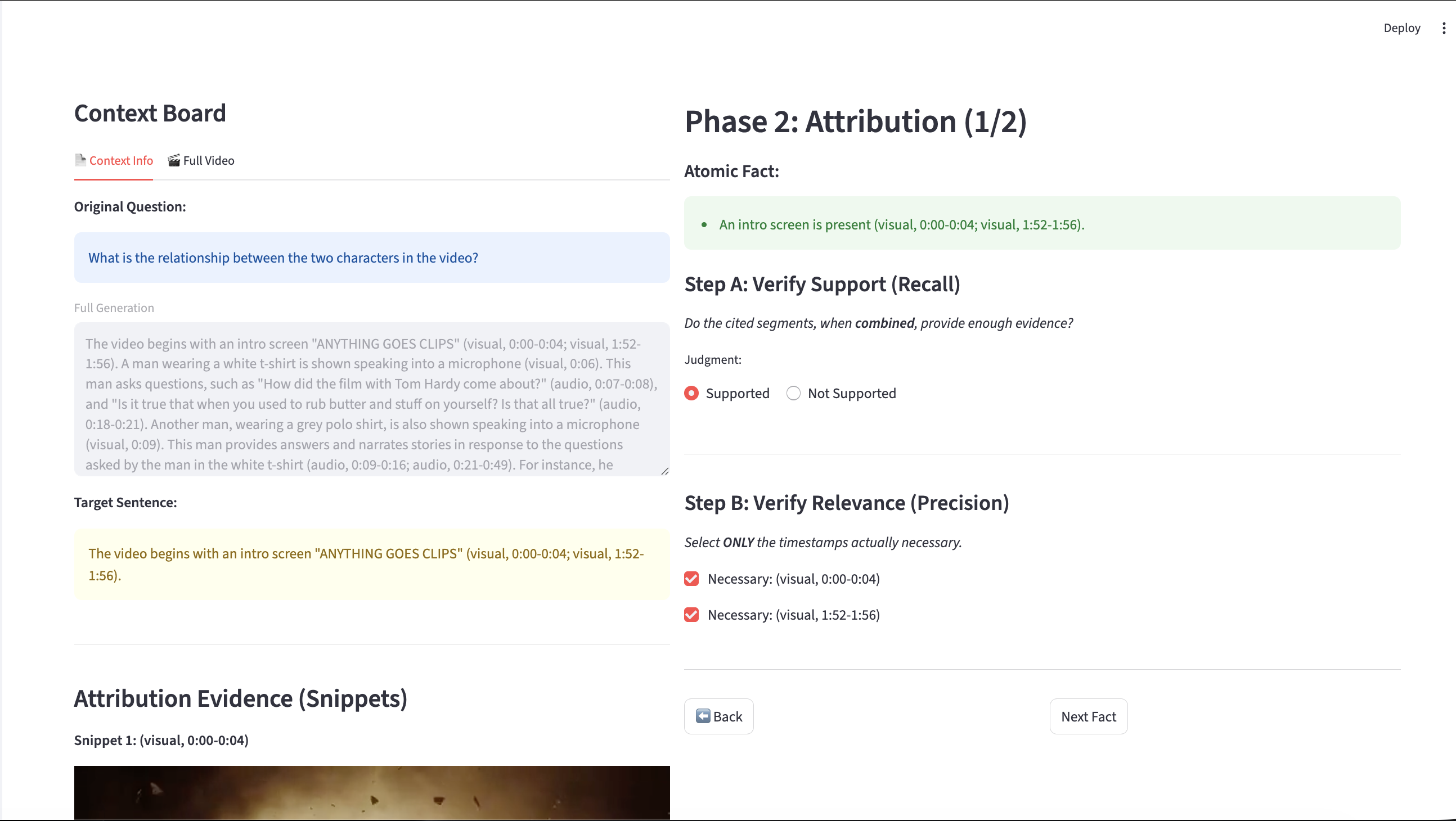
- Step 3: Attribution quality
- Recall: Did the model cite enough evidence to prove the fact?
- Precision: Did the model avoid citing extra, unnecessary clips?
Analogy: If you’re proving “The player scored at 2:15,” recall asks, “Did you include the clip where the goal happens?” Precision asks, “Did you avoid including unrelated clips that don’t help?”
The scoring system
- Citation Coverage: Of all the sentences that are verifiable, how many actually have citations?
- Attribution Quality: How correct and necessary the citations are (using Precision, Recall, and their F1).
- MuRGAt-Score: A single number that combines both—Coverage × Attribution—so models can’t “cheat” by doing well on one and failing on the other.
Automatic evaluation
Human judging is slow, so the authors also build MuRGAt-Score, an automatic evaluation pipeline that simulates the three steps above. They test different strong LLMs as “judges” and pick the combo that best matches human ratings. Their automatic score correlates strongly with human judgment (Pearson r ≈ 0.86 overall), which is much better than common one-shot “LLM-as-judge” baselines.
They test everything on two challenging datasets:
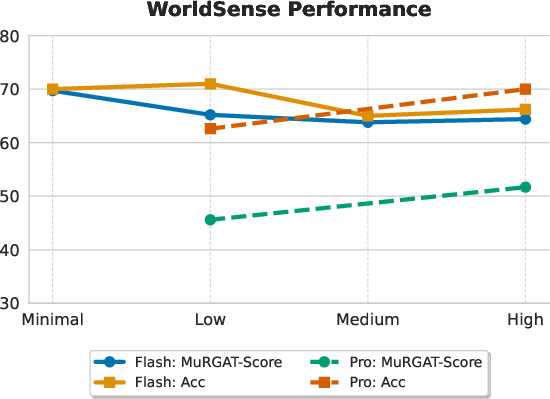
- WorldSense: real-world multimodal questions (often recognition-heavy).
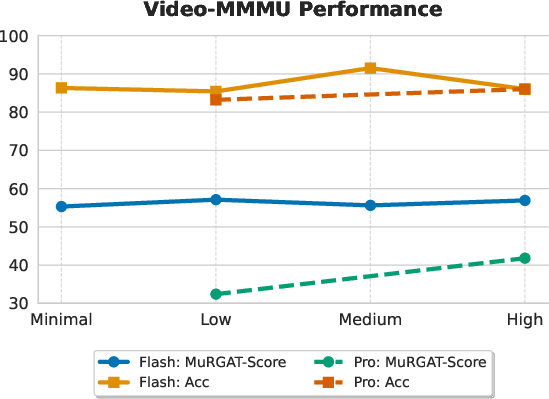
- Video-MMMU: complex video/figure reasoning tasks (often reasoning-heavy).
What did they find?
Here are the main takeaways, explained simply:
- Correct answers without good evidence are common. Even very strong models often give the right final answer but point to the wrong clips—or no clips at all. This is called “hallucinated grounding.”
- Adding citations helps or hurts depending on the task.
- On simple recognition tasks (e.g., “What color is the car?”), making models cite can act like a “reasoning tax” and slightly lower answer accuracy (extra effort can distract).
- On complex reasoning tasks (e.g., combining chart reading with audio narration), requiring citations often improves accuracy because it encourages the model to structure its thinking.
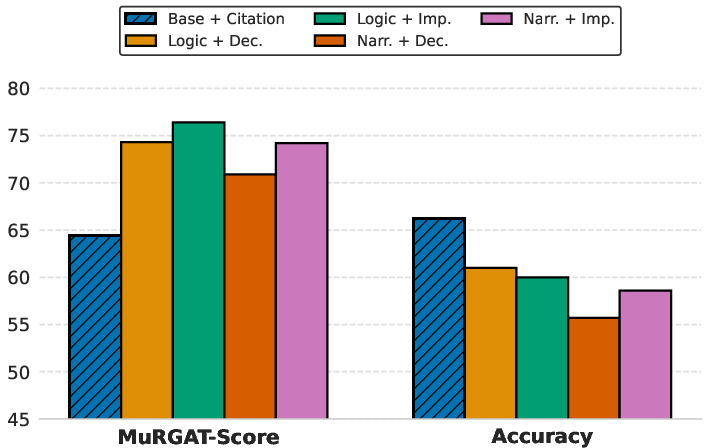
- Post-hoc citations (adding sources after writing the answer) are a mixed bag.
- They boost coverage (more sentences get citations), and help in recognition tasks.
- But in reasoning-heavy tasks, they often attach the wrong evidence to complex steps, lowering attribution quality.
- More “thinking” time isn’t always better.
- For some models, forcing more chain-of-thought or longer reasoning reduces grounding quality (they rely on internal guesses rather than checking the input).
- For stronger models, extra thinking can improve both accuracy and grounding—showing that ability to align reasoning with evidence matters.
- Program-like methods can improve grounding but may hurt accuracy. Approaches that make the model plan steps and search for exact timestamps (like a small program that queries the video) raise the grounding score by about 10 points on average. But they can reduce final answer accuracy because they’re stricter and less flexible.
Why this matters: It shows there’s a real gap between “thinking” (internal reasoning) and “proving” (grounded evidence). Good answers aren’t enough; we also need trustworthy, checkable evidence.
Why does this matter?
- For trust and safety: In real life—education, news, medical advice—people need to verify claims. MuRGAt pushes AI to not only reason but also show exactly where the facts come from.
- For better AI design: The benchmark and scoring method reveal hidden weaknesses in even top models, guiding researchers toward models that align their reasoning with solid evidence.
- For practical tools: The automatic MuRGAt-Score lets developers quickly test and improve their systems without needing human judges every time.
- For the future: The work highlights trade-offs (accuracy vs. verifiability; speed vs. structure) and points toward new methods that balance strong reasoning with reliable, precise grounding.
In short, this paper moves AI one step closer to “answers you can trust,” by making models prove their claims with clear, checkable evidence from the right place and time.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved by the paper. These are framed to guide actionable follow-up research.
- Limited human-annotated gold data: Only 20 problems (80 responses) were human-annotated, constraining statistical confidence, ablation breadth, and granular error analyses; scale up annotations and report inter-annotator agreement.
- Weak reporting on annotation reliability: No inter-annotator agreement, adjudication protocol, or timing/cognitive-load analysis; quantify consistency and annotation variance, especially for temporal boundaries and modality labels.
- Evaluator dependence on proprietary APIs: The automatic pipeline relies on closed-source Gemini models that can drift over time; develop open-source, frozen evaluators or release evaluator checkpoints for reproducibility.
- Small-sample correlation estimates: High Pearson correlations (e.g., r≈0.86) were computed on limited data; validate correlations on substantially larger, diverse sets and report CIs and robustness to prompt/seed changes.
- Scope of modalities: Experiments focus on video, audio, and some figures/plots; extend to documents, tables, webpages, OCR-heavy sources, sensor streams, and multimodal mixtures with conflicting cues.
- Language and acoustic diversity: Audio evaluation is limited to English-like settings; assess multilingual speech, code-switching, non-speech audio events, noisy/overlapped speech, and ASR-free grounding.
- Evidence timing granularity: Temporal citation granularity and tolerance are unspecified; define and evaluate IoU-like temporal matching criteria and study human sensitivity to boundary errors.
- No ground-truth timestamp sets: Entailment of cited timestamps is judged by LLMs rather than by a gold set of annotated segments; build timestamped ground truths to calibrate and stress-test the judge.
- Per-fact vs per-sentence citations: All atomic facts inherit the same sentence-level citation set; introduce per-fact citation generation and per-fact evidence selection to prevent over- or under-citation.
- Penalizing unnecessary citations on non-verifiable content: The metric filters out reasoning sentences and does not penalize gratuitous citations on unobservable claims; extend metrics to discourage citation “padding.”
- Minimality formalization: “Strictly necessary” evidence is judged qualitatively; formalize minimal proof sets and evaluate evidence minimality (e.g., set cover optimality, ablation tests).
- Chain faithfulness beyond observable facts: Reasoning steps not directly observable are excluded from evaluation; design measures to check consistency of intermediate reasoning with grounded premises (e.g., proof-style auditing).
- Modality-consistency checks: VL-only models hallucinate audio citations; add modality-consistency diagnostics that verify that cited modalities are actually accessible and supportive for that model.
- Open-world uncertainty and abstention: Models are not rewarded for saying “insufficient evidence”; add abstention-aware scoring that credits correct uncertainty and penalizes confident but unsupported claims.
- Long-horizon and streaming scenarios: The benchmark does not explicitly vary video length or streaming constraints; evaluate attribution under long-context memory, temporal drift, and online processing.
- Multi-source and cross-document grounding: Inputs mainly come from a single video/audio source; introduce tasks with multiple heterogeneous sources requiring cross-document alignment and conflict resolution.
- Complex relational/temporal reasoning: Current evaluation focuses on atomic fact entailment; add tests for temporal relations (before/after/causal), numerical reasoning over plots, and cross-modal aggregation.
- Metric aggregation effects: MuRGAt-Score (Coverage × Attribution) may mask trade-offs; report per-modality and per-step breakdowns, calibration curves, and cost-adjusted variants for fair comparisons.
- Judge-model bias and circularity: Evaluators from the Gemini family assess outputs from Gemini and competitors; quantify cross-family bias, swap judges (e.g., Qwen-as-judge), and run tri-judge arbitration.
- Robustness and adversarial tests: No stress tests for spurious correlations, misleading B-roll, off-screen narration, or timestamp spoofing; curate adversarial suites to probe failure modes systematically.
- Training-time methods left unexplored: Work emphasizes prompting, post-hoc, and programmatic scaffolds; investigate supervised/contrastive fine-tuning for attribution, reinforcement learning on MuRGAt-Score, and preference optimization for grounding.
- Retrieval/tooling design space: Programmatic methods use limited executors; study richer multimodal retrieval, temporal proposal networks, ASR-free audio indexing, and learned planning–execution interfaces.
- Computation–grounding trade-offs: “Thinking effort” yields model-specific trends; map the Pareto frontier across compute budgets, grounding quality, and accuracy, and identify controllable levers (e.g., step limits, verifier loops).
- Format adherence and parsing: Models often fail timestamp schemas; explore constrained decoding, structured generation (JSON schemas), and robust post-parsers with error recovery.
- Answer evaluation scope: Accuracy is string-matched to multiple-choice keys; extend to free-form long-form answers with calibrated semantic matchers and attribution-aware correctness scoring.
- Causal attribution vs evidential correlation: Current metric checks entailment but not causal relevance; add interventions or counterfactual tests to distinguish causally necessary evidence from merely co-occurring cues.
- User-centered validation: No human trust/usability studies; test whether higher MuRGAt-Score improves end-user trust, error detection, and decision quality in realistic tasks.
- Data and license constraints: The benchmark reuses external datasets; specify licensing, redistribution rights, and ethical considerations for releasing extended annotations (timestamps, segment labels).
- Generalization across domains: Benchmarks center on WorldSense and Video-MMMU; evaluate on scientific talks, medical videos, surveillance, egocentric video, and education content to assess domain transfer.
- Cost and latency: Attribution pipelines may be expensive and slow; report compute/latency costs per subtask and explore efficient judges, caching, and lightweight verifiers for practical deployment.
Practical Applications
Overview
The paper introduces MuRGAt (Multimodal Reasoning with Grounded Attribution) and MuRGAt-Score—an evaluation benchmark and automated metric for fact-level, verifiable grounding in multimodal LLMs (MLLMs). Given inputs spanning video, audio, and figures, models must produce multi-step reasoning with precise, modality-aware, timestamped citations. The evaluation pipeline decomposes responses into (1) verifiable claim identification, (2) atomic fact decomposition (with decontextualization), and (3) attribution quality (precision/recall), and achieves high correlation with human judgments. Experiments highlight a gap between correct reasoning and faithful grounding, task-dependent effects of citations, and trade-offs when enforcing structured grounding or scaling “thinking.”
Below are concrete applications across sectors, grouped by deployment horizon.
Immediate Applications
These can be deployed with today’s models and tools, using MuRGAt-Score and the paper’s workflows primarily for evaluation, QA, and product integration.
- AI model selection and regression testing for multimodal products (Software/ML Ops)
- Use case: Integrate MuRGAt-Score into CI/CD to gate model updates for assistants that analyze videos, audio, and charts; track Coverage and Attribution F1 over time.
- Tools/workflows: Batch evaluation harness; sentence-level decomposition + entailment checks; dashboards that visualize per-claim precision/recall and coverage.
- Assumptions/dependencies: Access to the MuRGAt pipeline and datasets; compute budget for LLM-as-judge inference; domain-relevant test sets.
- Trust and transparency UI for multimodal assistants (Software/Consumer)
- Use case: Show timestamped, modality-specific citations for each verifiable claim in long-form answers (e.g., “seen in audio 00:42–00:46”).
- Tools/workflows: Front-end timeline scrubber linked to claims; citation schema enforcement; backend that stores per-claim evidence sets.
- Assumptions/dependencies: Reliable timestamp alignment; UX for distinguishing reasoning vs. evidence; user consent for media processing.
- Meeting/lecture summarization with verifiable citations (Education/Enterprise)
- Use case: Generate meeting minutes or lecture notes with sentence-level, timestamped evidence to help users jump to the exact segments.
- Tools/workflows: ASR/diarization; atomic fact decomposition; per-fact entailment verification; export to notes with deep links.
- Assumptions/dependencies: High-quality ASR for noisy rooms; speaker diarization; long-context video/audio indexing.
- Analyst tools for earnings calls, webinars, and podcasts (Finance/Media Intelligence)
- Use case: Extract claims and decisions from audio/video with timestamped citations; support auditability for investment theses or risk reviews.
- Tools/workflows: Audio-first processing; claim extraction and per-claim recall checks; spreadsheet exports with timecodes and confidence.
- Assumptions/dependencies: Accurate ASR and punctuation; domain-specific lexicons; privacy/compliance controls.
- Journalist and fact-checking assistants for multimedia (Media/Policy)
- Use case: Verify claims in speeches, debates, and investigative footage; flag sentences lacking sufficient evidence (low recall) or spurious citations (low precision).
- Tools/workflows: Pipeline for verifiable claim identification; evidence triage UI; report generation with precision/recall per claim.
- Assumptions/dependencies: Rights to process media; varying audio-visual quality; editorial guidelines on evidence sufficiency.
- Ad verification and brand safety on video (Advertising/Media)
- Use case: Check whether specific spoken or on-screen claims actually occur; verify brand placements with temporal grounding.
- Tools/workflows: Query-by-claim checks using entailment; precision filtering to avoid broad or incorrect citation spans.
- Assumptions/dependencies: OCR for text-in-video; logo/brand detectors; robust temporal localization.
- Customer support on user-submitted videos (Consumer/IoT)
- Use case: Diagnose device issues from uploaded clips with verifiable references to fault indicators in video/audio segments.
- Tools/workflows: Evidence-aware reasoning; enforce non-empty citations for observable claims; per-claim verifiability filtering.
- Assumptions/dependencies: Privacy and consent flows; heterogeneity of user footage; scalable video indexing.
- Safety/compliance dashboards for AI-generated content (Cross-sector)
- Use case: Block or flag outputs with low Coverage or Attribution scores; require minimum MuRGAt-Score thresholds before publishing.
- Tools/workflows: Automated content review; policy-driven thresholds; audit logs of claim-evidence mappings.
- Assumptions/dependencies: Calibrated thresholds per use case; governance alignment; storage of evidence segments.
- Research benchmarking and ablations (Academia/AI Research)
- Use case: Evaluate new MLLM variants, prompting strategies (e.g., JSON vs. CoT), or program-aided methods against MuRGAt-Score to study grounding-reasoning trade-offs.
- Tools/workflows: Reproducible scripts; cross-model comparisons; error analyses on hallucinated grounding vs. correct answers.
- Assumptions/dependencies: Dataset licenses (WorldSense, Video-MMMU); access to tested MLLMs (e.g., Gemini, Qwen).
- Multimodal RAG for video/audio (Software)
- Use case: Replace direct timestamp prediction with “executor-discovered” retrieval of segments; improves grounding when paired with runtime refinement.
- Tools/workflows: Segment-level indexing; search API for temporal evidence; per-operation entailment checks.
- Assumptions/dependencies: High-quality video/audio indexing; latency constraints for interactive use; tool reliability.
Long-Term Applications
These require further research, scaling, domain adaptation, or regulatory maturation, motivated by gaps identified in the paper (e.g., reasoning–grounding trade-offs, audio-visual heterogeneity, programmatic execution reliability).
- Clinically grounded decision support from procedure videos and audio (Healthcare)
- Use case: Support ultrasound/endoscopy reporting with per-finding timestamps and linked frames; enable peer review with fine-grained evidence.
- Tools/workflows: Domain-trained MLLMs; verified claim identification tailored to clinical primitives; regulatory-grade attribution auditing.
- Assumptions/dependencies: FDA/CE approvals; stringent precision/recall; privacy; curated, expert-annotated datasets.
- Legal e-discovery and deposition analysis (Legal)
- Use case: Extract and justify claims from hours of depositions or surveillance with court-admissible citation trails.
- Tools/workflows: Chain-of-custody evidence logs; tamper-proof timestamping; robust decontextualization for references.
- Assumptions/dependencies: Authenticity verification (deepfake detection); strict chain-of-custody; judicial standards for AI-derived evidence.
- Self-explaining autonomous systems (Robotics/Autonomy)
- Use case: Robots generate grounded rationales for actions, citing sensor segments (video/audio/LiDAR) supporting each decision.
- Tools/workflows: Real-time verifiable claim filtering; low-latency evidence retrieval; program-aided reasoning with executor-discovered grounding.
- Assumptions/dependencies: On-device compute; streaming ASR/sensor fusion; safety validation; latency budgets.
- Platform-scale multimedia misinformation mitigation (Policy/Social Platforms)
- Use case: Automatically flag viral videos with ungrounded claims or mismatched citations; provide transparent evidence for moderation decisions.
- Tools/workflows: Scalable claim extraction and attribution scoring; triage interfaces; appeal workflows with evidence playback.
- Assumptions/dependencies: Adversarial robustness; multilingual ASR; policy design for acceptable evidence standards.
- Standards and certifications for “verifiable multimodal AI” (Policy/Standards)
- Use case: Incorporate MuRGAt-style metrics into procurement and compliance checklists for public-sector or regulated deployments.
- Tools/workflows: Reference test suites; auditable scoring; sector-specific benchmarks (e.g., healthcare imaging, public safety).
- Assumptions/dependencies: Consensus on metrics and thresholds; periodic benchmark refresh; transparency and reproducibility requirements.
- Training-time optimization for grounding without sacrificing reasoning (AI Research)
- Use case: Reinforcement learning or multi-objective training to jointly maximize accuracy and MuRGAt-Score; align internal reasoning with externally verifiable evidence.
- Tools/workflows: Reward design that uses fact-level precision/recall; curriculum over simple-to-complex video/audio reasoning tasks.
- Assumptions/dependencies: Compute budgets; stable reward signals; avoiding degenerate strategies (e.g., over-citation).
- Programmable multimodal agents with robust executors (Software/Robotics)
- Use case: Logic-centric and executor-discovered frameworks that plan, search, and verify across heterogeneous modalities with runtime refinement.
- Tools/workflows: API ecosystem for video OCR, ASR, temporal localization; stateful planners; verification loops that enforce entailment.
- Assumptions/dependencies: Reliable tool APIs; error recovery strategies; monitoring to avoid “force-alignment” artifacts.
- Education assessment and feedback from lecture media (Education)
- Use case: Auto-grade student explanations that must cite lecture segments; provide pinpoint feedback tied to timestamps.
- Tools/workflows: Domain rubrics; claim-level coverage checks; LMS integrations with video links.
- Assumptions/dependencies: Curriculum alignment; academic integrity safeguards; equitable access to lecture media.
- Lifelogging and quantified-self assistants with grounded narratives (Consumer)
- Use case: Produce daily summaries from personal videos/audio with timestamped events; searchable, verifiable personal archives.
- Tools/workflows: On-device or private cloud indexing; evidence-linked reminiscence features; privacy-preserving processing.
- Assumptions/dependencies: Consent and data governance; battery and storage limits; high-quality on-device ASR.
- Enterprise knowledge governance for AI-generated reports (Enterprise IT)
- Use case: Policies that require minimum Coverage and Attribution for reports summarizing trainings, safety briefings, or ops walkthroughs.
- Tools/workflows: Compliance dashboards; audit trails; automated rejection of low-score outputs.
- Assumptions/dependencies: Integration with DLP and content repositories; change management; workforce training.
- Expanded multimodal benchmarks (Academia/Community)
- Use case: Extend MuRGAt to specialized domains (e.g., scientific figures, industrial inspections) with richer audio and figure modalities.
- Tools/workflows: Annotation protocols for verifiable claims and atomic facts; shared task competitions.
- Assumptions/dependencies: Annotation cost; inter-annotator agreement; data licensing and ethics.
Cross-Cutting Dependencies and Risks
- Data quality and rights: Accurate ASR/diarization, OCR, and timestamp alignment; legal rights to process video/audio.
- Model access and cost: Current pipeline uses strong MLLMs (e.g., Gemini). Cost and availability may constrain adoption; open alternatives may lag in audio handling.
- UX and human factors: Clear distinction between reasoning and evidence; avoiding over-citation; intelligible timelines.
- Robustness: Adversarial media, poor audio/visual quality, and domain shift can degrade attribution precision/recall.
- Governance: Sector-specific thresholds for “sufficient evidence” must be defined; auditability and storage of cited segments must meet compliance rules.
By operationalizing MuRGAt’s fact-level pipeline and MuRGAt-Score, developers and organizations can move beyond answer accuracy toward verifiable, auditable multimodal reasoning—enabling safer, more trustworthy deployments across industries.
Glossary
- Atomic fact decomposition: The process of breaking a sentence into minimal, independently verifiable claims for fine-grained evaluation. "Atomic fact decomposition further breaks each verifiable sentence into atomic facts, enabling fine-grained evaluation, as a single sentence often contains multiple claims~\citep{min-etal-2023-factscore}."
- Attribution F1: The harmonic mean of precision and recall used to summarize the quality of evidence supporting atomic facts. "Attribution F1: We derive the final attribution score (Attribution) as the harmonic mean of Precision and Recall."
- Attribution quality: An assessment of whether cited multimodal evidence correctly supports each atomic fact. "(3) Attribution quality evaluates whether each atomic fact is entailed by the multimodal evidence cited for it."
- Balanced Accuracy (BAcc): A metric for binary classification on imbalanced data, averaging true positive and true negative rates. "As this task involves a binary decision, we evaluate performance based on Balanced Accuracy (BAcc), a standard practice for unbalanced labels \cite{laban-etal-2022-summac}."
- Chain-of-Thought (CoT): A prompting style that elicits intermediate reasoning steps before the final answer. "a Chain-of-Thought (CoT) prompt that requests reasoning before the answer;"
- Citation coverage: The proportion of verifiable sentences that include at least one citation. "Citation coverage measures the model's ability to correctly provide citations for sentences that require grounding."
- Citation propagation: Ensuring that citations attached to an original sentence are carried over identically to each derived atomic fact. "We also check whether citations are correctly propagated to the corresponding atomic facts (citation propagation)."
- Decontextualization: A process that resolves pronouns and implicit references to explicit entities using context to make facts independently verifiable. "To ensure accurate evaluation, we apply decontextualization \cite{choi-etal-2021-decontextualization, wei2024longform}, where pronouns are resolved to specific entities using the preceding context."
- Disentangled metric: A scoring approach that provides separate evaluations for coverage, attribution recall, and precision instead of a single aggregate score. "Disentangled, which asks the model to provide distinct scores for coverage, attribution recall, and precision;"
- Entailment: The logical condition that evidence fully supports a claim. "we evaluate the entailment of each atomic fact with respect to its cited sources."
- Hallucinated grounding: Citations that are incorrect or not supported by the input evidence, often produced despite correct answers. "frequently producing ``hallucinated grounding'' where incorrect citations are given."
- Holistic metric: A single overall score for an output, typically coarse and less granular. "Holistic, which provides a single score ranging from 1--5;"
- JSON structured prompt: A schema-enforced prompt format that requires structured reasoning before a final verdict. "a JSON structured prompt, a structured variant of CoT that enforces a schema requiring reasoning prior to the verdict which is identified by \citet{jacovi2025factsgroundingleaderboardbenchmarking} as a top-performing method."
- LLM-as-judge: Using a LLM to evaluate or score outputs. "substantially outperforming the next-best LLM-as-judge baseline ()."
- LLM-based verifier: A LLM prompted to determine whether a sentence is directly verifiable from inputs. "we prompt an LLM-based verifier to determine whether the sentence is verifiable \cite{liu-etal-2023-evaluating}, i.e., whether its claims can be grounded to the multimodal inputs ."
- Modality: The type of input channel (e.g., audio, video, figures) referenced by a citation. "each citation specifies both modality and temporal segments."
- Multimodal LLM (MLLM): A LLM that can process and reason over multiple input modalities. "Multimodal LLMs~(MLLMs) are increasingly used for real-world tasks involving multi-step reasoning and long-form generation, where reliability requires grounding model outputs in heterogeneous input sources and verifying individual factual claims."
- Multimodal retrieval-augmented generation: A generation paradigm that retrieves supporting evidence across modalities during or before response generation. "and multimodal retrieval-augmented generation~\citep{dong2025mmdocrag, yu2025mramgbenchcomprehensivebenchmarkadvancing, chen2022muragmultimodalretrievalaugmentedgenerator}"
- MuRGAt (Multimodal Reasoning with Grounded Attribution): A benchmark task that evaluates fact-level multimodal attribution in reasoning beyond direct observation. "We introduce MuRGAt (\underline{Mu}ltimodal \underline{R}easoning with \underline{G}rounded \underline{At}tribution), a benchmark for evaluating fact-level multimodal attribution in settings that require reasoning beyond direct observation."
- MuRGAt-Score: A holistic metric defined as coverage multiplied by attribution, penalizing sparse or incorrect grounding. "MuRGAt-Score scales the attribution quality by the coverage."
- Parametric knowledge: Information encoded in a model’s parameters, used directly during generation without external retrieval. "Direct generation approaches \citep{weller-etal-2024-according} use attribution from parametric knowledge by prompting LLMs to cite supporting sources during generation."
- Pearson correlation: A statistic measuring linear association, used to compare automatic evaluation with human judgments. "we observe a high Pearson correlation of 0.84 when averaged over all steps, substantially outperforming the next-best LLM-as-judge baseline ()."
- Post-hoc attribution: Adding citations after the answer is generated, often by prompting the model to locate supporting segments. "a post-hoc attribution method~(Post-hoc Attribution), which simulates temporal visual grounding by prompting the model to provide citations for each sentence if necessary."
- Program-aided generation: A framework that structures reasoning through executable or declarative steps to improve grounding and attribution. "we extend prior work on program-aided generation~\citep{wan2025generationprograms, slobodkin-etal-2024-attribute} to our challenging multimodal setting."
- Set-based evaluation protocol: An approach that assesses whether the union of cited segments entails a fact and whether individual segments are necessary. "We adopt a set-based evaluation protocol used in prior work~\cite{liu-etal-2023-evaluating, gao-etal-2023-enabling}."
- Temporal alignment: Ensuring citations are aligned to the correct time intervals relevant to the claim. "while accounting for both temporal alignment and modality."
- Temporal visual grounding: Localizing the relevant segment in video by timestamps to support a textual claim. "simulates temporal visual grounding by prompting the model to provide citations for each sentence if necessary."
- Verifiable claim identification: The subtask of detecting which sentences contain observable claims that require grounding. "(1) Verifiable claim identification identifies sentences that contain directly observable claims requiring grounding, as opposed to sentences that reflect reasoning steps."
- Video grounding tasks: Tasks that localize relevant video segments given text queries. "Video grounding tasks, which aim to localize a relevant segment given a textual query~\cite{hendricks2017localizingmomentsvideonatural, lei-etal-2021-mtvr, xiao2024can}, are also related."
- Vision-Language (VL) model: A model that processes visual inputs and language but not audio. "We also include vision-LLMs that can only process vision information but not audio: Qwen3-VL-instruct, Qwen3-VL-thinking, and Molmo2-8B."
Collections
Sign up for free to add this paper to one or more collections.