- The paper presents multi-mode quantum annealing integrated into VAEs with general Boltzmann priors, enabling unbiased gradient updates and efficient sampling.
- It demonstrates faster convergence and improved sample diversity using diabatic QA for training and slow QA for unconditional generation on canonical datasets.
- It introduces conditional QA for fine-grained attribute control, paving the way for versatile generative modeling with physical interpretability.
Multi-Mode Quantum Annealing for VAEs with General Boltzmann Priors: A Comprehensive Assessment
Theoretical and Algorithmic Framework
This work advances the intersection of quantum hardware and deep generative modeling by instantiating variational autoencoders (VAEs) with general Boltzmann machine (BM) priors, and enabling their training and deployment via multi-mode quantum annealing (QA). The architecture supplants the standard factorized Gaussian prior with an energy-based latent distribution parameterized as an Ising Hamiltonian. Unlike restricted BMs (RBMs), the general BM here incorporates arbitrary pairwise interactions, obviating architectural constraints and enabling richer latent representations.
The critical technical bottleneck—sampling from the resultant intractable prior for both gradient estimation and generation—is directly addressed through QA, leveraging the native ability of quantum hardware to efficiently sample from dense, arbitrary Ising energy landscapes. The authors systematically connect the QA schedule to effective Boltzmann temperatures, rigorously grounding the physical interpretation of the sampled distributions and allowing precise control of the sampling regime.
The model is comprised of a standard encoder–decoder pair and a learnable BM prior. The encoder outputs Bernoulli logits, the decoder reconstructs data from binary latent vectors, and the prior enforces structure through learned couplings. Training is performed via ELBO maximization; the prior’s gradient splits into the classical positive/negative phase, but the negative phase employs quantum-annealed samples. The explicit decomposition of the KL divergence into terms interpretable as variational and true free energies highlights the thermodynamic duality of the model: optimization can be seen as minimizing a free energy gap, driving the approximate posterior toward the equilibrium of the BM prior.
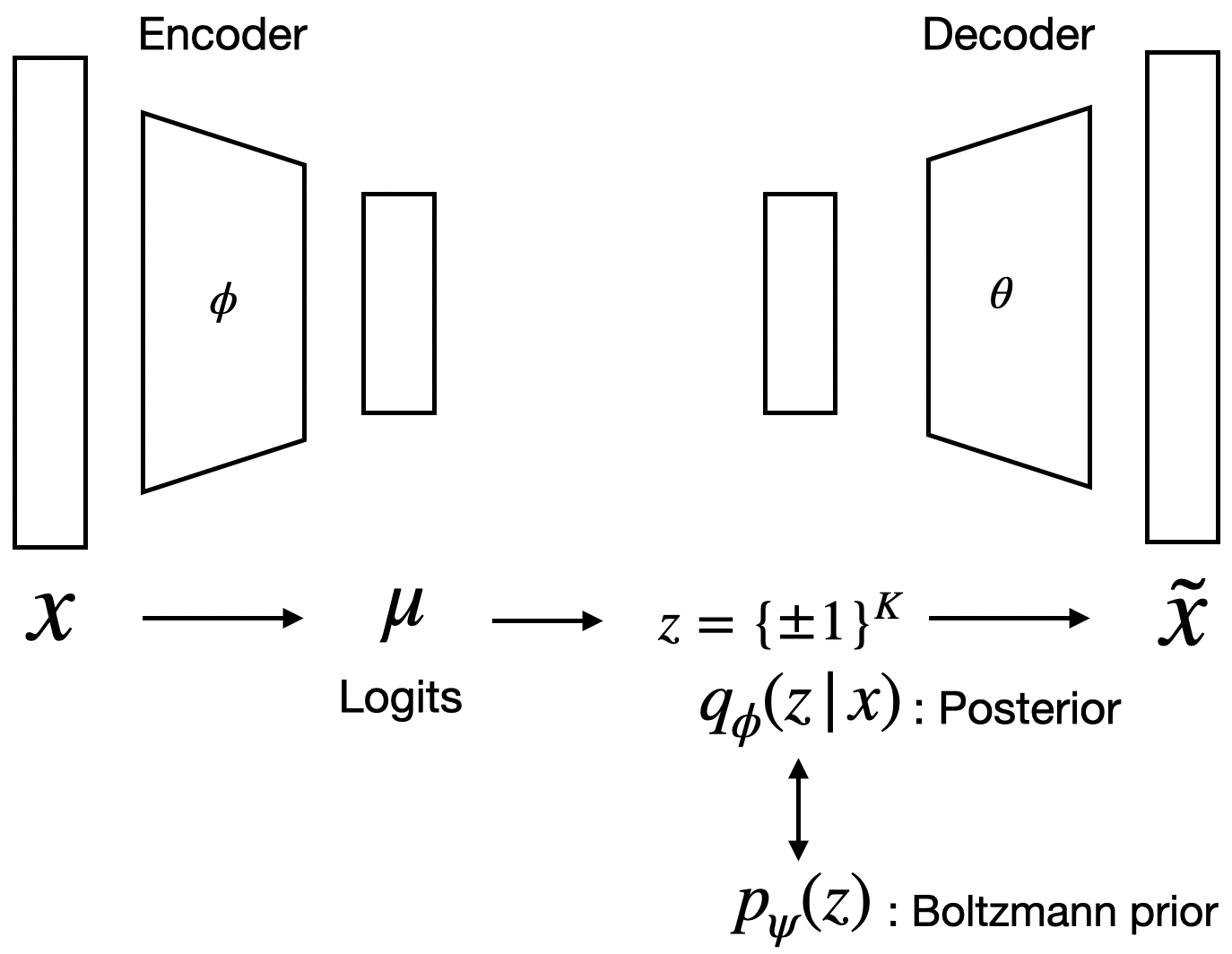
Figure 1: Schematic of the BM-VAE architecture, with an encoder, binary latent variables, a BM prior, and a decoder.
Multi-Mode Quantum Annealing: Training and Generation Paradigms
The model exploits QA in three distinct regimes using a unified energy landscape:
- Diabatic QA (DQA) for Training: Fast annealing (5\,ns) produces unbiased Boltzmann samples, allowing correct estimation of the negative phase for prior learning. This regime ensures the prior parameters are updated using physically motivated, accurate gradients.
- Slow QA for Unconditional Generation: Longer annealing schedules (0.5\,μs) concentrate samples near low-energy minima, facilitating high-fidelity, diverse generative samples from the learned distribution. This explicit physical concentration supplements the decoder with meaningful, coherent latent codes.
- Conditional QA (c-QA) for Attribute Steering: External bias fields, derived from encoder statistics for particular attributes, modulate the energy landscape, directing sampling toward latent subspaces associated with user-specified semantic features. This conditional regime does not require retraining and exploits the expressive interactions learned by the prior.
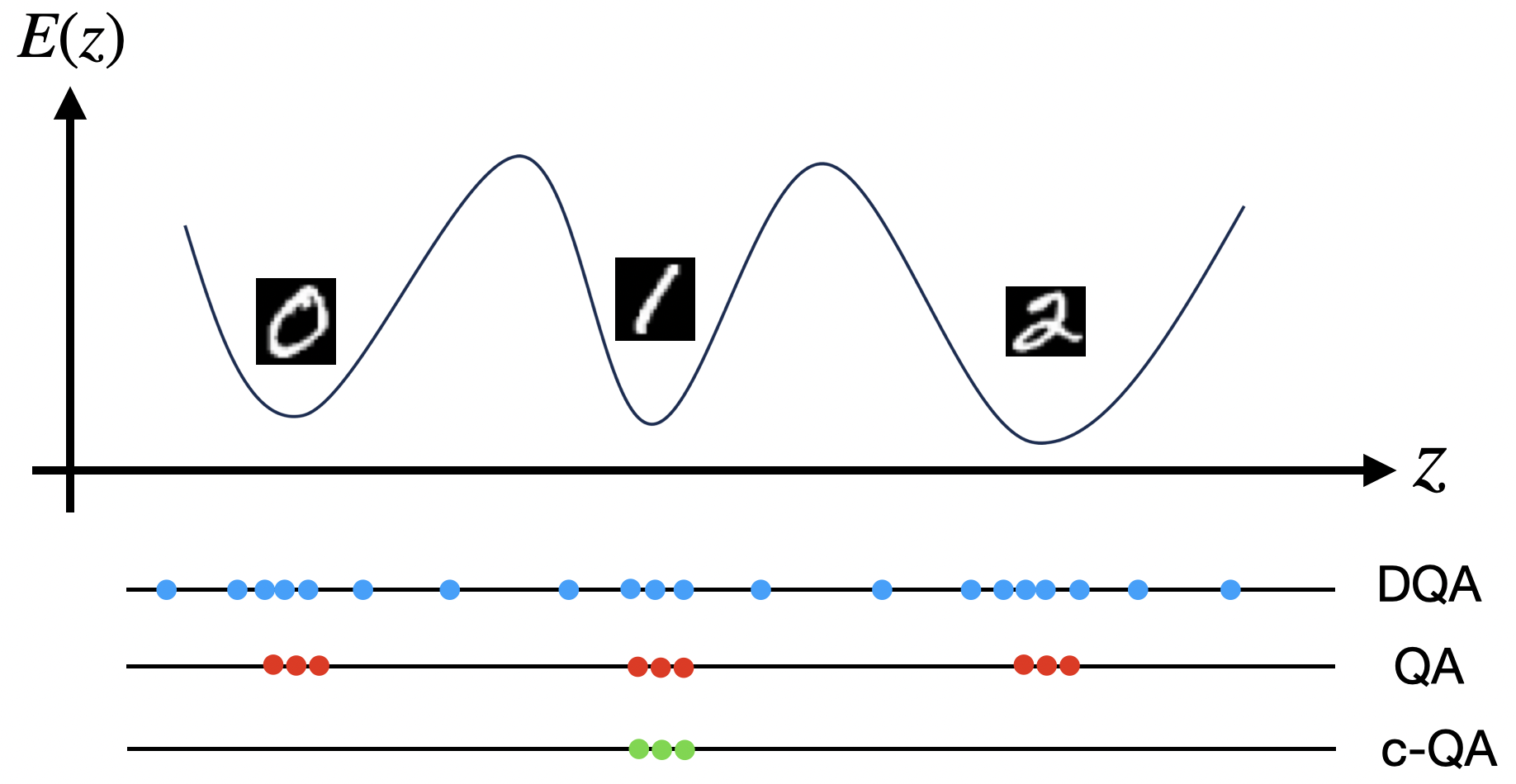
Figure 2: Illustration of the three QA modes: Boltzmann-distributed training samples (DQA), concentrated low-energy samples (QA), and attribute-steered samples via bias fields (c-QA).
Empirical Results: Training Dynamics, Generation, and Attribute Control
Training Efficiency
Experiments on canonical datasets (MNIST, Fashion-MNIST, and CelebA) compare the BM-VAE with a matched Gaussian-prior VAE (G-VAE). The BM-VAE consistently demonstrates faster convergence and lower final reconstruction loss. The learnable energy-based prior alleviates the tension imposed by factorized priors, as the BM adapts to the posterior rather than requiring the encoder to conform to a rigid prior.
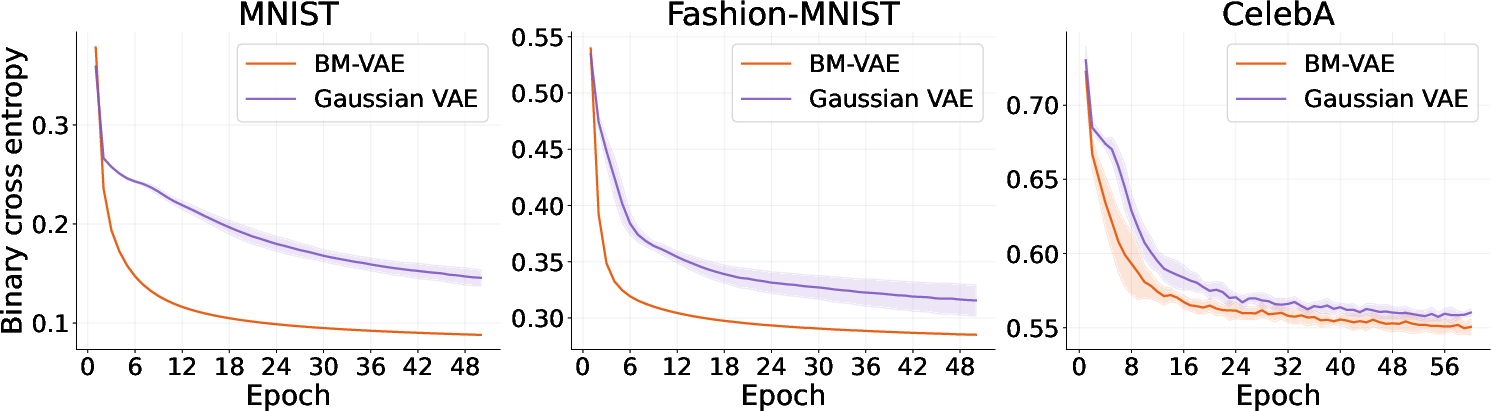
Figure 3: Training curves of BM-VAE and G-VAE on MNIST, Fashion-MNIST, and CelebA, showing faster convergence and lower loss for BM-VAE.
Unconditional Generation
When generating samples from the prior, the BM-VAE produces diverse, semantically rich outputs due to the structured latent space enforced by the BM. Unconditional samples drawn from the QA-based prior cover multi-modal face variations (pose, hair, expression) in CelebA, validating the hypothesis that general BMs can encode complex, expressive dependencies unreachable by factorized priors.

Figure 4: Unconditional CelebA samples decoded from quantum-annealed BM prior configurations, showcasing semantic diversity and visual coherence.
Conditional Generation and Attribute Manipulation
Conditional generation is achieved by augmenting the energy function with attribute-based bias fields. The effects are measured both at the dataset level (generating averages for a semantic property, e.g., "Bangs") and for single-image attribute editing. Deterministic binarized encoder outputs yield rigid samples, while the BM-guided c-QA approach introduces attribute-consistent, visually coherent, and diverse generations. Notably, single-image attribute editing preserves subject identity while stochastically varying attribute details, which demonstrates finer-grained semantic control enabled by the learned interactions.

Figure 5: Attribute-conditioned samples on CelebA (e.g., with "Bangs") generated via c-QA. Baseline deterministic decoding is rigid; c-QA provides diversity and realism.

Figure 6: Attribute manipulation of test images via c-QA, adding "Bangs" while maintaining identity and diversity across samples.
Practical and Theoretical Implications
The principal practical implication is the demonstration that general, fully-connected BMs—long considered intractable for classical VAEs—can be trained and deployed at meaningful scale (up to 2000 latents/qubits) using contemporary QA hardware. This expands the design space for expressive energy-based priors in deep learning models.
Theoretically, the explicit connection between the annealing protocol and the effective Boltzmann temperature eliminates reliance on heuristic a posteriori temperature fitting, providing a foundation for interpretable, controllable sampling and suggesting a clear recipe for future hardware-informed generative modeling.
The modularity introduced by multi-mode QA supports a flexible "train once, sample many ways" paradigm: after a single training regime, the same energy-based prior can be used for unconditional synthesis, attribute-controlled sampling, and post hoc semantic editing—all driven by physical fields or schedule modulation without additional retraining steps or neural modifications. This decoupling of generative and conditional constraints enhances the model’s versatility for real-world and scientific applications where control and interpretability are paramount.
Future Directions
Several avenues are open for extension. Adaptive or data-driven annealing schedules may further enhance sample fidelity and training efficiency. More granular or compositional forms of conditioning—potentially exploiting the full structure of the learned energy function or hybridizing with neural prompt engineering—could enrich control mechanisms. Continued improvements in QA hardware (more qubits, higher connectivity, reduced noise) will allow for ever-larger BMs and, correspondingly, more sophisticated and nuanced latent spaces.
Moreover, connecting these results to advances in classical hardware (e.g., accelerated BM sampling on classical Ising machines) could clarify the qualitative and quantitative boundaries of quantum versus classical sampling for deep generative modeling.
Conclusion
This work operationalizes a general BM prior within a VAE, trained and sampled via multi-mode QA on contemporary quantum hardware. The results demonstrate superior training convergence, high-fidelity generative and conditional sampling, and attribute manipulation capabilities at previously unattainable latent scales. The multi-mode QA approach transforms quantum annealing from a black-box heuristic into a task-specific, physically interpretable module within modern probabilistic generative models, opening new experimental and theoretical horizons for quantum machine learning and energy-based modeling.