- The paper introduces a debiased estimator that corrects LASSO bias to restore asymptotic normality for valid inference.
- The methodology employs convex optimization to compute a correction matrix that ensures tighter confidence intervals and controlled Type I errors.
- Empirical evaluation on simulated and gene expression data demonstrates the robust performance and trade-offs of debiased LASSO compared to projection methods.
Debiased Estimators in High-Dimensional Regression: Summary and Analysis
High-dimensional regression, characterized by p≫n, poses fundamental challenges for statistical inference due to the inherent bias introduced by regularized estimators such as the LASSO. The nonlinearity and the lack of an explicit closed-form for the LASSO estimator preclude classical inferential procedures based on the sampling distribution. Javanmard and Montanari (2014) proposed a debiased estimator which restores asymptotic normality, enabling the construction of valid confidence intervals and hypothesis tests under high-dimensional regimes. This review rigorously analyzes the theoretical framework of their approach, replicates critical empirical studies, and provides comparative evaluation with the desparsified LASSO estimator, explicitly addressing claims regarding coverage, power, and robustness to correlation structure.
Theoretical Framework for Debiasing
The model considered is Y=Xθ0+W with W∼N(0,σ2In) and X of dimension n×p. The classical LASSO estimator is defined via the L1 penalized objective, which induces sparse solutions but also introduces bias. The debiasing methodology centers on augmenting the LASSO solution θ^n with a correction proportional to the subgradient, parameterized by a matrix M designed to minimize generalized coherence with respect to the sample covariance Σ^.
The debiased estimator is:
θ^u=θ^n+n1MX⊤(Y−Xθ^n)
where Y=Xθ0+W0 is obtained through a convex optimization ensuring Y=Xθ0+W1 for each coordinate.
Figure 1: A visualization of the symmetric circulant matrix Y=Xθ0+W2 specified mathematically in Equation (\ref{eq:circulant_mat}).
Theoretical analysis demonstrates that Y=Xθ0+W3 decomposes as the sum of a Gaussian term with mean Y=Xθ0+W4 and a bias term which is probabilistically controlled under compatibility and coherence conditions. The bias magnitude is Y=Xθ0+W5, and the error bounds converge rapidly to zero as Y=Xθ0+W6 provided the sparsity Y=Xθ0+W7 is not too large.
Inference Procedures: Confidence Intervals and Hypothesis Testing
Leveraging asymptotic normality, the framework yields valid confidence intervals:
Y=Xθ0+W8
and Y=Xθ0+W9-values for tests of W∼N(0,σ2In)0:
W∼N(0,σ2In)1
This construction extends directly to simultaneous inference, with procedures for controlling FWER via Bonferroni correction, and remains valid for non-Gaussian noise distributions under appropriate moment and Lindeberg conditions, enforced by additional W∼N(0,σ2In)2 constraints during debiasing.
Empirical Evaluation: Simulation and Real Data
The simulation study utilizes circulant symmetric covariance matrices with controlled off-diagonal correlations to benchmark interval coverage and power (see Figure 1 for structure). Replication demonstrates improved confidence interval tightness and accurate coverage relative to the original study; notably, the Javanmard–Montanari method controls Type I error while maintaining reliable coverage across both signal and null components. However, the LASSO projection estimator shows superior power in low-signal regimes without inflating false positives.
Analysis of the real-world riboflavin gene expression dataset (W∼N(0,σ2In)3, W∼N(0,σ2In)4) reinforces the robustness of the debiased estimator against complex correlation structures encountered in biological data. The debiased LASSO provides narrower confidence intervals and isolates genuine signals that are ambiguous under multisample splitting and standard projection estimators.
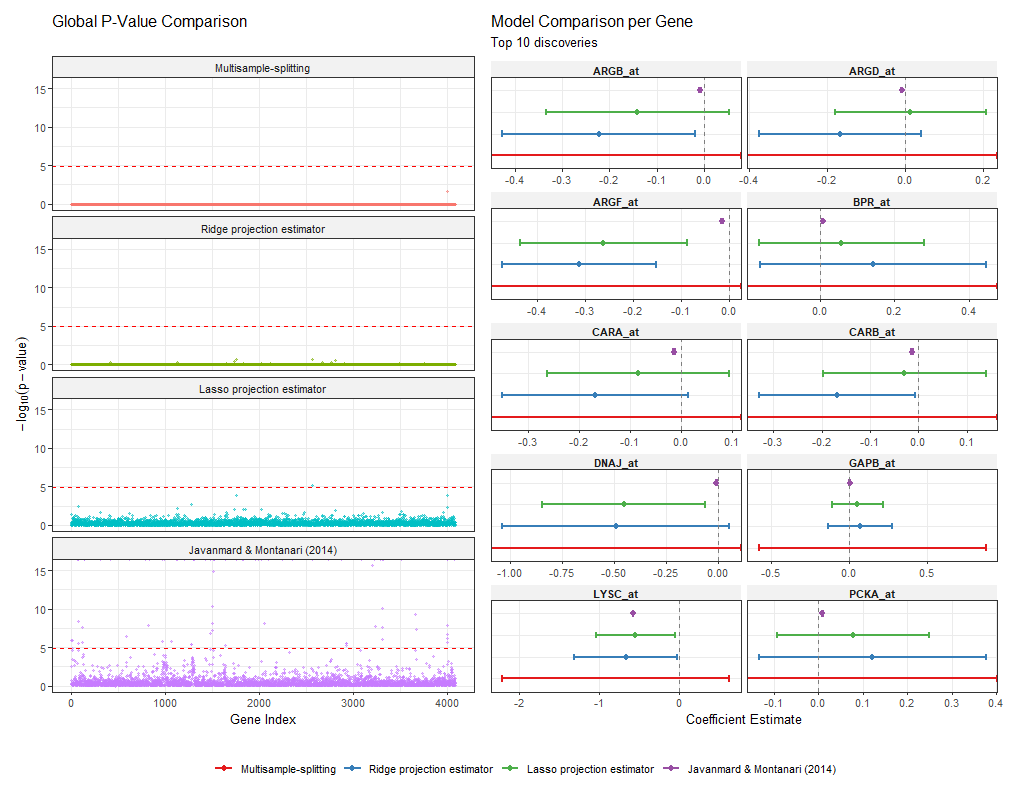
Figure 2: Comparative high-dimensional inference on the riboflavin dataset (n=71, p=4,088); Manhattan plot (left) shows global p-value distribution relative to Bonferroni threshold, forest plot (right) provides 95% confidence intervals for top ten genes.
Practical and Theoretical Implications
The formal guarantees of asymptotic unbiasedness and normality enable classical inferential methods in regimes where traditional estimators fail. The convex optimization required for matrix W∼N(0,σ2In)5 adapts the procedure to the correlation topology of the design, offering resilience in applications where standard compatibility conditions may not hold. As demonstrated, practical trade-offs exist: projection-based methods excel in idealized (near-orthogonal) designs, while optimized debiasing is dominant in real-world data with dense correlations.
Future theoretical research should address inference when compatibility or restricted eigenvalue conditions are violated, and simulation studies should evaluate estimator robustness under structured dependence. Practically, the methodology provides a rigorous uncertainty quantification toolkit for genomics, neuroimaging, and other high-dimensional domains, supporting reproducible science without resorting to sample splitting or other conservative alternatives.
Conclusion
Javanmard and Montanari's debiased estimator for high-dimensional regression yields valid, near-optimal confidence intervals and hypothesis tests, bridging the gap between sparse selection and formal inference. Empirical replication and extension reveal its robust performance in both synthetic and real-data settings, especially under severe correlation. Comparisons with the LASSO projection estimator highlight practical trade-offs, tailored by the correlation structure evolving over real-world applications. Theoretical guarantees and empirical precision position debiased LASSO as a standard for high-dimensional statistical inference, underpinning practical developments in AI-driven statistics.