- The paper introduces a novel task for spatial semantic segmentation that handles overlapping sound sources and target-absent mixtures.
- It details an innovative dataset synthesis method using multi-channel Ambisonics recordings and controlled spatial separation.
- It adopts a new permutation-invariant evaluation metric (CAPI-SDRi) and a two-stage baseline combining audio tagging and source separation.
Spatial Semantic Segmentation of Sound Scenes: DCASE 2026 Challenge Task 4
Introduction
The DCASE 2026 Challenge Task 4 addresses the problem of spatial semantic segmentation of sound scenes (S5), an advanced task that requires the joint detection and separation of sound events from complex spatial audio mixtures. Building upon its inaugural presentation in the DCASE 2025 challenge, the 2026 iteration introduces two substantial modifications aimed at better modeling real-world acoustic environments: (1) the allowance for mixtures containing multiple spatially distinct sources of the same class, and (2) the inclusion of mixtures with no target sources. These extensions significantly heighten the complexity of both the detection and separation problem and demand new evaluation protocols and system architectures.
The S5 paradigm has direct implications for immersive communication applications, extended reality (XR), and context-aware monitoring in smart environments, among others. This summary provides a technical review of the task definition, novel dataset construction, updated evaluation metrics, and the baseline system architecture and results.
Task Setting and Innovations
S5 takes as input a multichannel (first-order Ambisonics, FOA) audio mixture that, in the new setting, can include zero to three target events, with the possibility of repeated class labels (i.e., multiple sources of the same class occurring simultaneously and spatially apart) as well as interference events and diffuse background noise. The expected output is a set of estimated waveforms for all detected target events, each correctly mapped to its semantic class.
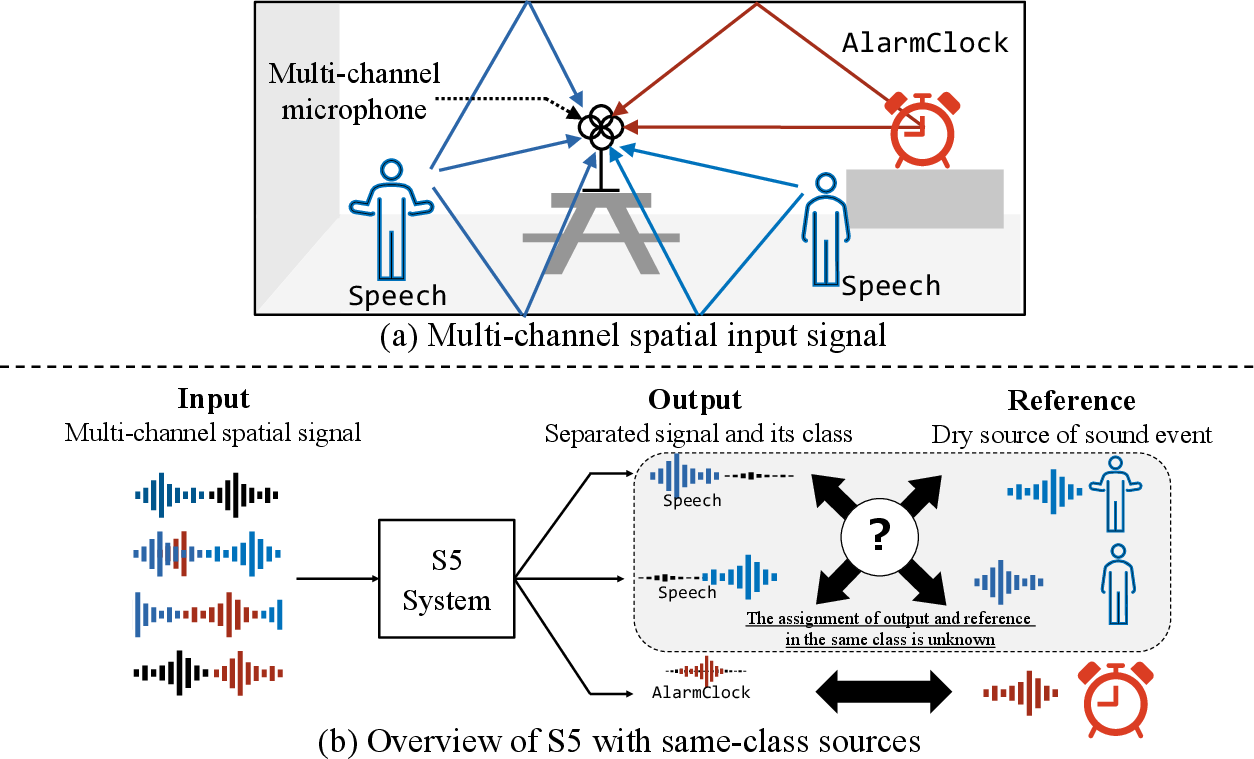
Figure 1: Overview of S5 task with same-class sources, illustrating the presence of multiple spatially distinct events from the same class in a single mixture.
This setting introduces label ambiguity due to the possible duplication of class labels and mandates the explicit utilization of spatial cues. Furthermore, the system must robustly predict the absence of targets under challenging signal-to-noise conditions and non-stationary backgrounds.
Dataset Construction
The new dataset is synthesized from a combination of freshly recorded material and curated public datasets, utilizing SpAudSyn, a dedicated spatial audio synthesis tool. It comprises:
- 1703 internally recorded isolated target events across 18 classes, augmented with samples from public datasets (e.g., FSD50K, EARS, Semantic Hearing) to address class imbalance.
- Interfering events and background noise from public sources and custom recordings, with target absence explicitly reflected in a substantial portion of the mixtures.
- Fine-grained spatial simulation using individually measured first-order Ambisonics RIRs (1296 in total), ensuring spatial diversity and realism.
- Controlled synthesis where same-class target events are spatially separated by at least 60°.
Mixtures are generated to a fixed 10 s duration at 32 kHz, with up to three overlapping targets and up to two interference events, and SNRs controlled to span realistic regimes. The dataset is partitioned into training (with on-the-fly mixture synthesis), validation, and test splits with carefully balanced event-count distributions. The evaluation split is completely held out with all-new recordings to guarantee generalization assessment.
Evaluation Metrics
Assessment of S5 systems in the new setting requires a metric that is both permutation- and class-aware. The previous Class-Aware SDR improvement (CA-SDRi) cannot handle label duplication; hence, the new Class-Aware Permutation-Invariant SDRi (CAPI-SDRi) is adopted. This metric performs optimal matching between reference and estimated sources per class, accounting for possible mismatches in event count due to false positives and false negatives. The full metric definition leverages both permutation and combination operations over source indices and penalizes misdetections appropriately.
In addition to the main ranking metric (CAPI-SDRi), complementary measures such as CASA, PESQ, STOI, and PEAQ are used to probe different perceptual and signal-level aspects of system performance.
Baseline System Architecture
The baseline system comprises a two-stage pipeline modeled after state-of-the-art approaches for joint detection and separation tasks:
- Audio Tagging (AT): A M2D-based model predicts presence and count of target event classes in the mixture. Two input variants are instantiated:
- M2DAT_1c: single-channel (omnidirectional).
- M2DAT_4c: four-channel FOA input, exploiting spatial cues for tagging.
- Label-Queried Source Separation (LQSS): A ResUNetK model receives mixture waveform along with detected class queries and extracts the corresponding time-domain source estimates.
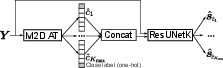
Figure 2: Overview of the baseline system, which follows a two-stage approach: audio tagging followed by label-queried source separation.
Key enhancements over the previous baseline include the support for repeated labels (multi-one-hot outputs in AT), and the introduction of a spatial (4-channel) AT model. AT and separation modules are trained independently, with the separation network trained using oracle detection labels and a permutation-invariant SDR objective tailored for the new task ambiguities.
Results and Analysis
Experimental results on the development set test partition reveal:
- M2DAT_4c (multi-channel tagging) outperforms the single-channel variant in both CAPI-SDRi and classification accuracy, demonstrating the value of spatial information in both detection and separation.
- For the M2DAT_4c + ResUNetK system, CAPI-SDRi reaches 8.49 dB, with a mixture-level accuracy of 60.71% and source-level detection accuracy of 70.39%. These numbers highlight ongoing challenges in the presence of same-class overlap and in mixtures without targets, yet they quantitatively surpass the performance achieved with single-channel tagging.
Implications and Future Directions
The DCASE 2026 Task 4 formulation pushes the boundary of label-permutation- and spatially-aware source separation research. By including mixtures with repeated classes and event-absent mixtures, it explicitly addresses real-world scene complexity and the need for robust negative event detection.
The adoption of the CAPI-SDRi metric resolves evaluation-pathologies related to label ambiguity and sets a rigorous standard for future work. The multi-stage baseline, while effective, still exposes challenges in cross-task errors (e.g., tagging mistakes propagating to separation errors), and motivates further research into end-to-end trainable/self-correcting architectures. The task provides a benchmark and data ecosystem that could stimulate developments in universal source separation, joint detection-localization-separation models, and cross-modal integration (e.g., with XR visual cues).
Given the rise of multichannel and object-based spatial audio in communication and XR standards, the practical relevance of robust semantic spatial scene decomposition is set to increase. The methods and standards advanced in DCASE S5 will likely inform next-generation architectures for AI-embedded media systems, ambient intelligence, and adaptive hearing devices.
Conclusion
DCASE 2026 Challenge Task 4 redefines the state-of-the-art in spatial semantic segmentation of sound scenes by introducing critical complexities reflective of real-world audio. Through revised task design, robust datasets, advanced permutation-invariant metrics, and a multi-stage spatial baseline system, the challenge sets a comprehensive benchmark for the community. Ongoing and future work will need to address elevated sources of ambiguity, leverage richer spatial and signal representations, and move towards unified, highly generalizable models to achieve the task goals.