- The paper introduces a dual-stage system integrating a Transformer-based SED model with a ResUNet separator, employing temporal conditioning and iterative refinement.
- It utilizes Time-FiLM and embedding injection to improve separation, enhancing event detection by 8 percentage points and lifting CA-SDRi from 11.03 to 13.42.
- Iterative refinement enables progressive error correction, with optimal gains observed after three cycles, underscoring its practical value in acoustic scene analysis.
Temporal Guidance and Iterative Refinement for Audio Source Separation
Introduction
This work addresses the spatial semantic segmentation of sound scenes (S5), focusing on the joint detection and separation of active sound events from complex acoustic mixtures. The standard two-stage pipeline—event detection followed by class-conditioned source separation—has been limited by the lack of temporally precise guidance from the detection stage to the separator. The authors propose a system that tightly integrates a fine-tuned Transformer-based SED model with a ResUNet separator, introducing temporal conditioning, embedding injection, and iterative refinement. The system achieves strong empirical results, including a second-place finish in the DCASE 2025 Task 4 challenge.
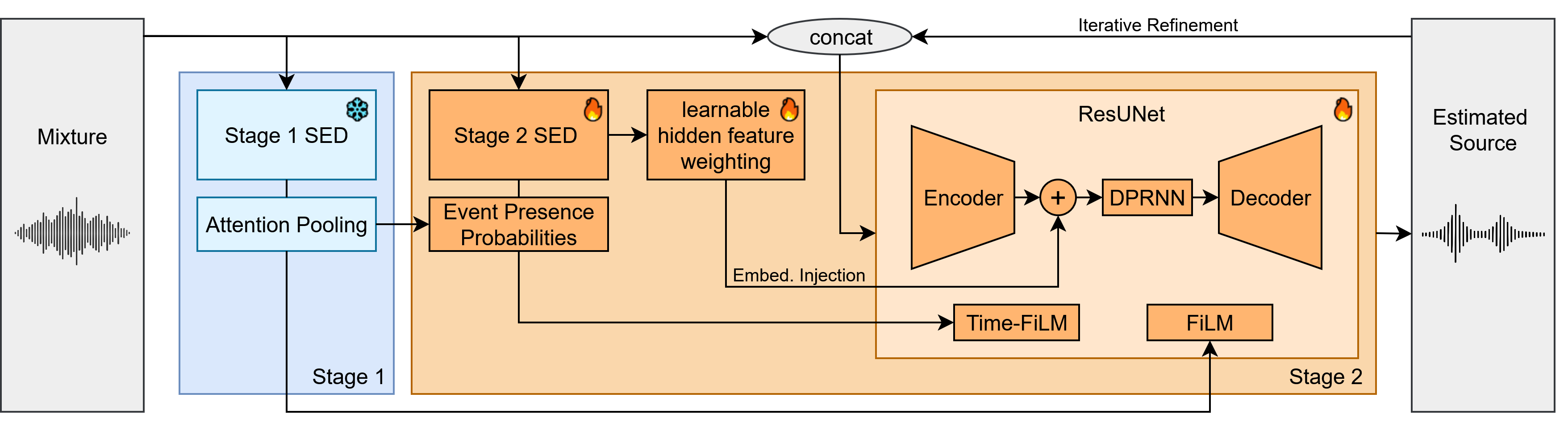
Figure 1: Overview of the proposed two-stage audio source separation system, highlighting the integration of SED-based temporal guidance, embedding injection, and iterative refinement within a ResUNet separator.
System Architecture
The proposed system consists of two tightly coupled stages:
- Sound Event Detection (SED): A fine-tuned M2D Transformer model predicts frame-level class activity, providing temporally resolved event information.
- Source Separation: A ResUNet separator, enhanced with temporal conditioning (Time-FiLM), embedding injection from a dedicated SED model, and an optional Dual-Path RNN (DPRNN), performs class-conditioned separation. An iterative refinement mechanism allows the separator to recursively improve its output.
Temporal Conditioning (Time-FiLM)
Time-FiLM generalizes standard FiLM conditioning by modulating separator features with temporally resolved class activity maps. The SED model, jointly trained with the separator, produces frame-wise class probabilities, which are transformed into time-aligned scale and shift parameters for each FiLM layer in the ResUNet. This enables the separator to leverage fine-grained temporal cues about event activity, improving separation in the presence of overlapping or transient events.
Embedding Injection
Intermediate hidden representations from the SED model are fused via a learnable weighted sum and projected into the ResUNet's latent space. This process injects temporally and semantically aligned features, enriching the separator's internal representations and facilitating more accurate source estimation.
Dual-Path RNN Integration
A DPRNN is incorporated into the ResUNet's embedding space to capture long-range dependencies along both time and frequency axes. This is particularly beneficial for modeling events with extended temporal structure or frequency-specific patterns.
Iterative Refinement
The separator is trained to refine its output over multiple iterations. At each step, the estimated source is concatenated with the original mixture and reprocessed by the separator. This recursive process allows the model to progressively correct residual errors and improve separation quality. During training, the number of iterations is randomly sampled, and only the final output is used for loss computation, with gradients detached between iterations to manage memory usage.
Experimental Setup
The system is evaluated on the DCASE 2025 Task 4 dataset, which comprises 4-channel, 10-second mixtures synthesized from 18 target classes and 94 interference classes, with realistic room impulse responses and background noise. The evaluation metric is Class-Aware Signal-to-Distortion Ratio improvement (CA-SDRi), which jointly assesses detection and separation performance.
The SED model is initialized from a pre-trained M2D checkpoint and fine-tuned with both strong (frame-level) and weak (clip-level) labels. The separator is based on AudioSep's ResUNet, further fine-tuned with the proposed enhancements. Hyperparameters, including learning rates and batch sizes, are carefully tuned for each component.
Results
The proposed system demonstrates consistent improvements over the DCASE baseline across all configurations. Notably:
- The fine-tuned SED model increases event detection accuracy by 8 percentage points (from 59.8% to 67.8%).
- The AudioSep-SED configuration (ResUNet + Time-FiLM + Embedding Injection + trainable SED) achieves a CA-SDRi of 13.42, compared to 11.03 for the baseline.
- Ablation studies show that both Time-FiLM and Embedding Injection contribute to performance, with the largest gain from making the Stage 2 SED model trainable.
- Adding a DPRNN further improves validation performance, though test set gains are less consistent, likely due to distribution mismatch.
Iterative refinement yields additional improvements:
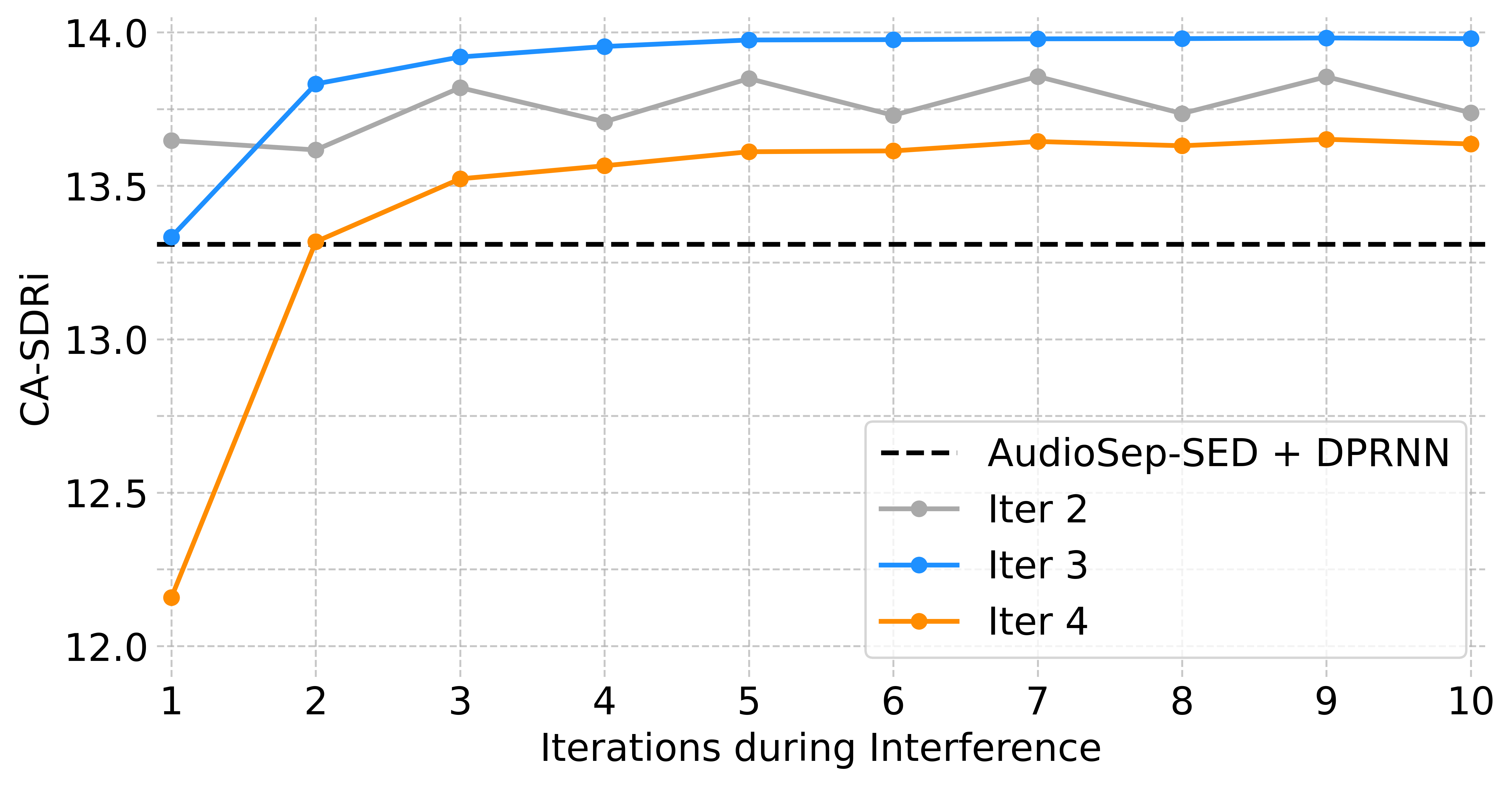
Figure 2: CA-SDRi performance of iterative refinement models compared to AudioSep-SED + DPRNN, showing gains with increasing inference iterations and convergence after a few cycles.
- Models trained with 2, 3, or 4 iterations show that most gains occur in early iterations, with diminishing returns beyond 3–4 cycles.
- Using more inference iterations than seen during training can still yield incremental improvements.
- Odd-even iteration effects are observed, with odd-numbered iterations often outperforming even-numbered ones, especially in models trained with fewer iterations.
- The best trade-off is achieved with 3 training iterations, balancing complexity and output quality.
Implications and Future Directions
The integration of temporally resolved SED guidance into the separator represents a significant advance in the design of S5 systems. By leveraging frame-level event activity and semantically rich embeddings, the separator can more effectively disentangle overlapping sources and handle transient events. The iterative refinement strategy further enhances separation quality, suggesting that recursive correction is a promising direction for future research.
Practically, these techniques can be applied to a wide range of real-world audio scene analysis tasks, including smart home monitoring, assistive listening devices, and audio forensics. The modularity of the approach allows for straightforward adaptation to new event classes or acoustic environments.
Theoretically, the work highlights the importance of tight coupling between detection and separation stages, moving beyond the traditional pipeline where these components are trained and operated independently. Future research may explore end-to-end joint optimization, more sophisticated temporal conditioning mechanisms, or integration with multimodal (e.g., audio-visual) cues.
Conclusion
This paper presents a two-stage audio source separation system that leverages temporally guided SED models for both event detection and separator conditioning, augmented with embedding injection and iterative refinement. The approach yields substantial improvements over established baselines on the DCASE 2025 S5 task, demonstrating the value of temporal guidance and recursive refinement in complex sound scene analysis. The findings motivate further exploration of tightly integrated, temporally aware architectures for audio source separation and related tasks.