- The paper introduces an open-ended narrative paradigm for wearable HAR that maps variable-length sensor streams to natural language descriptions, challenging fixed-taxonomy methods.
- The methodology leverages spectral tokenization and a Q-Former module, achieving 38.5% R@1 in retrieval and 65.3% Macro-F1 in closed-set classification.
- The framework demonstrates robust performance across cross-subject, cross-position, and missing-sensor scenarios, highlighting its potential for real-world applications.
Open-Vocabulary Narratives for Wearable Human Activity Recognition with ActivityNarrated
Paradigmatic Shift in HAR: From Closed-Set Labels to Open-Ended Narratives
Prevailing pipelines in wearable human activity recognition (HAR) operate under a closed-set classification paradigm—fixed temporal windows, canonical sensor placements, and predefined activity vocabularies dominate both benchmarks and modeling practice. This paradigm yields high benchmark accuracy but fails under real-world variability such as sensor placement shift, missing sensors, and semantically complex, long-tail behaviors. Critically, scaling dataset taxonomy or model parameter counts does not resolve the inherent limitations of the closed taxonomy (Figure 1).
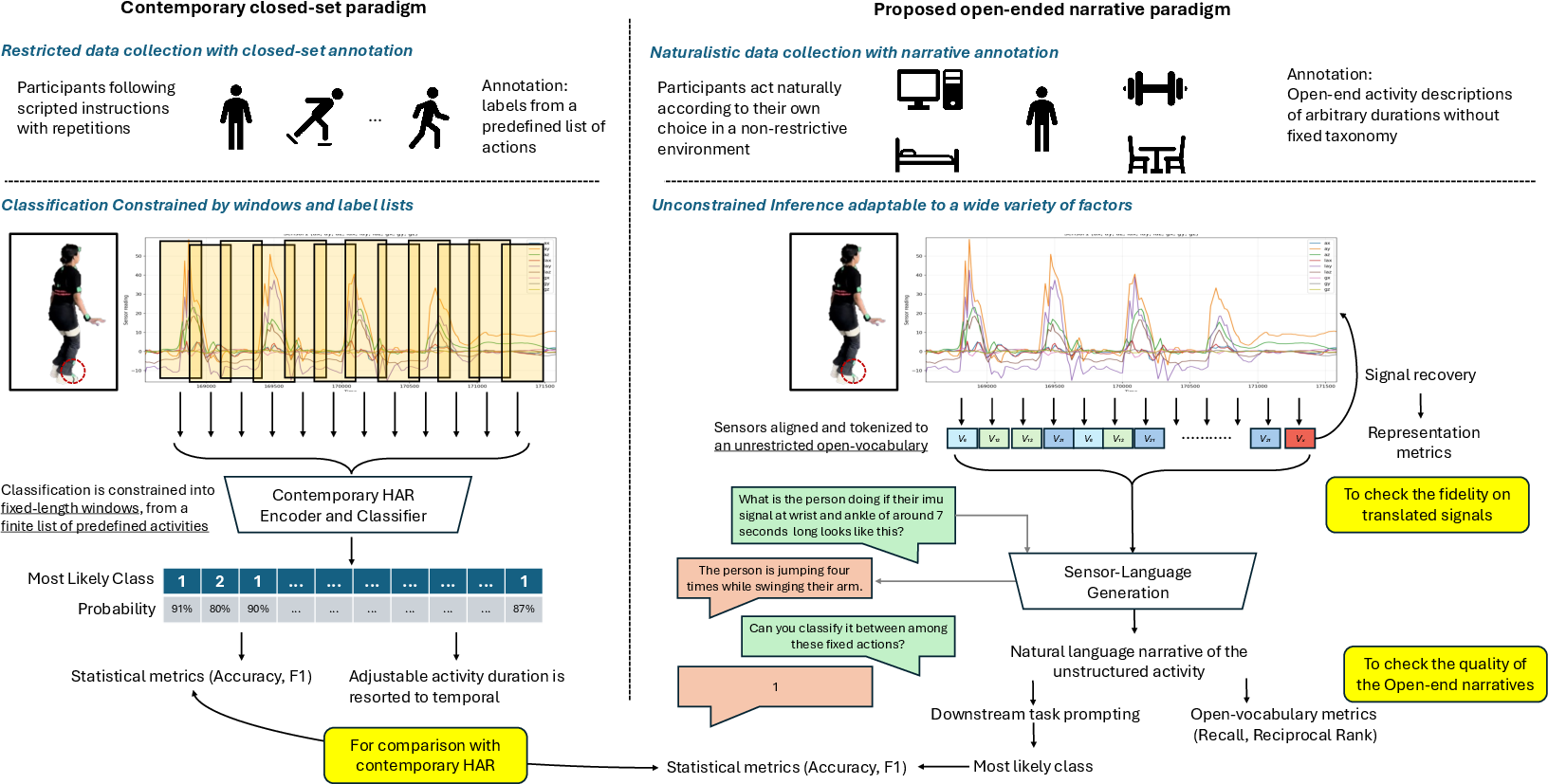
Figure 1: Conceptual comparison between traditional closed-set HAR and the open-vocabulary narrative paradigm; open-vocabulary HAR subsumes closed-set classification as a downstream task by grounding sensor signals in a language embedding space.
"ActivityNarrated: An Open-Ended Narrative Paradigm for Wearable Human Activity Understanding" (2604.00767) directly challenges the closed-set paradigm. It introduces a framework where activities are modeled as open-ended narratives, with activity semantics discovered through the alignment of multi-position wearable IMU sensor data and natural language descriptions.
This approach reframes recognition: activity understanding is no longer the selection of a class index but the retrieval or generation of narrative descriptions that are temporally aligned with ongoing sensorial evidence. The system explicitly models the real-world properties of human behavior—unscripted, compositional, long-tailed, and personalized.
The ActivityNarrated Dataset: Naturalistic, Multi-Position, and Language-Grounded
To support rigorous evaluation of this paradigm, ActivityNarrated is collected with three pillars:
- Unscripted, Open-Ended Behavior: 22 participants naturally interact in a controlled environment (Figure 2) with seven activity hotspots facilitating diverse, concurrent activities without imposed order or segmentation.
Figure 2: Room-scale testbed containing seven activity hotspots with multi-view camera coverage to capture unconstrained, multitask behaviors.
- Dense Multi-Position IMU Sensing: Each participant is instrumented with up to 15 IMU sensors on various body locations (Figure 3), capturing both the diversity and heterogeneity of real-world deployments.
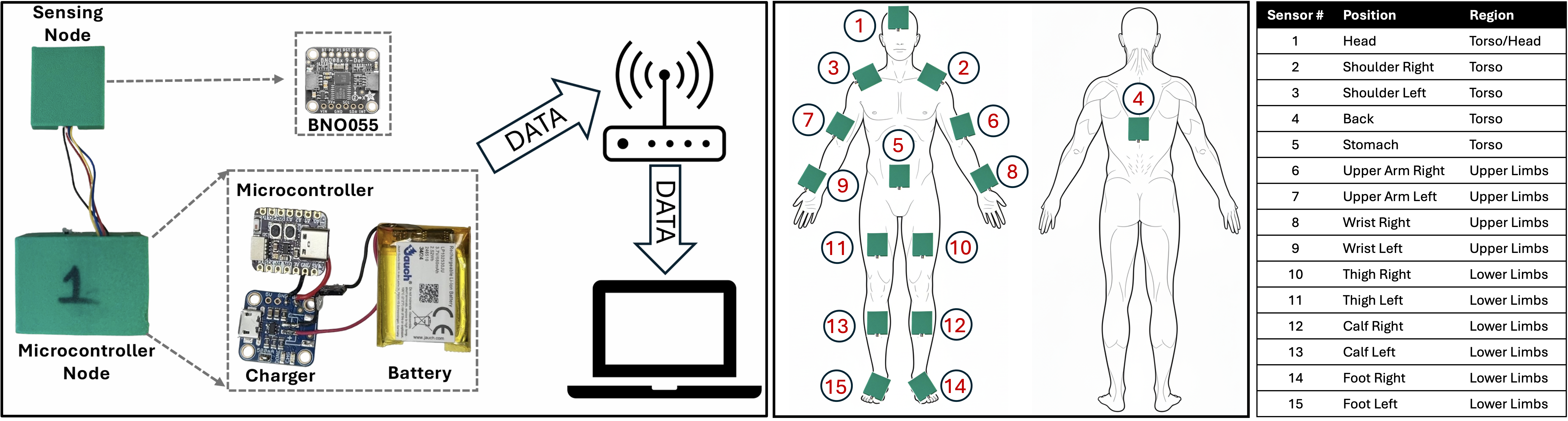
Figure 3: Platform for multi-position IMU sensing, highlighting extensive body coverage and supporting explicit test of sensor placement invariance.
- Rich, Layered Annotation: Three sources of semantic supervision are paired to each activity segment: free-form participant narrations, VLM-derived weak labels, and expert post-hoc annotations (both in natural language and mapped to a 23-class taxonomy).
This design induces highly variable sensor configurations, segment durations, and narrative forms, producing a challenging regime for both open-vocabulary and closed-set HAR tasks.
Open-Vocabulary Benchmarking: Metrics and Tasks
HAR evaluation in this paradigm eschews accuracy and Macro-F1 as sole targets. Instead, three axes are used for benchmarking:
- Sensor–Language Retrieval: The core metric is R@K (Recall at K) for retrieval given a segment and a candidate pool of descriptions, supplemented with MRR (Mean Reciprocal Rank) and nDCG for ranking quality amid description paraphrases and semantic granularity differences.
- Discretization Metrics: Quality and invariance of the learned IMU representations are assessed with time- and spectral-domain ℓ1 reconstruction error and JS divergence for token stability across placements and subjects.
- Downstream Closed-Set Classification: As a diagnostic, closed-set recognition metrics are reported by mapping generated narratives to fixed taxonomies.
The ActNarrator Architecture: Discrete Motion Lexicon Meets LLMs
The proposed system, ActNarrator, consists of two principal modules (Figures 4 and 5):
- Spectral VQ-VAE Discretization: IMU streams are split into overlapping windows processed with multiple encoders: time-domain, STFT, and wavelet (Figure 4). The resulting fused latent is quantized via a codebook (typically K=128 entries) to yield robust, compositional motion tokens.
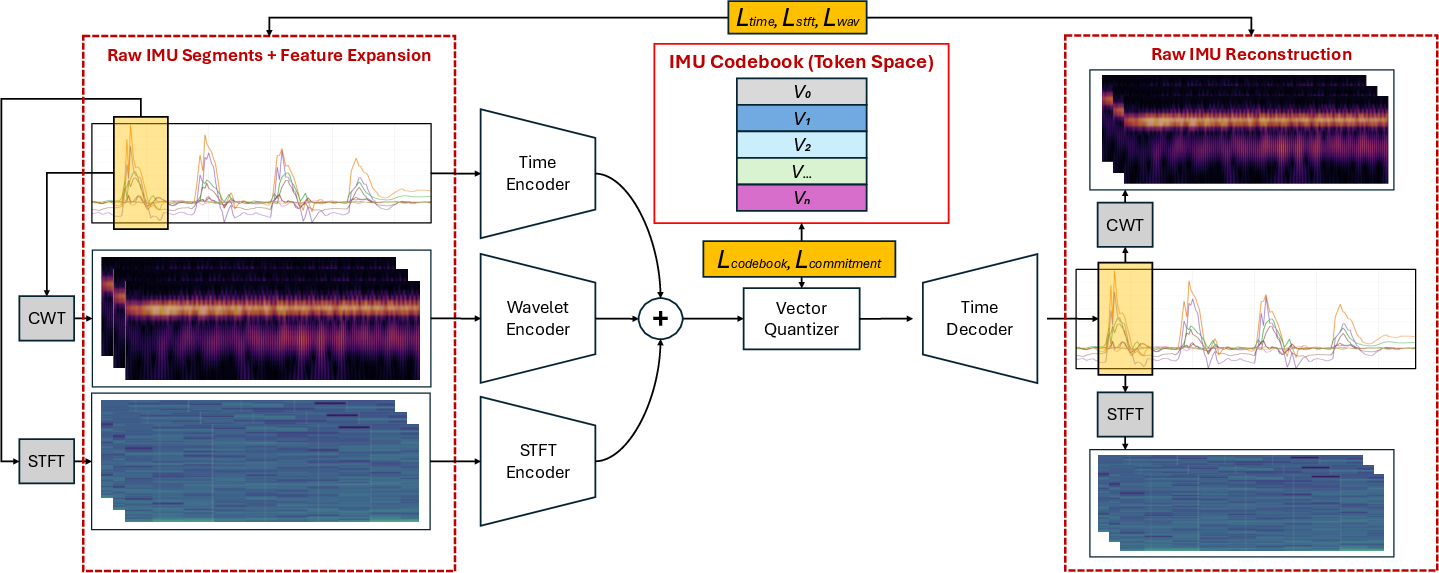
Figure 4: Spectral VQ-VAE encodes multi-view IMU streams into discrete tokens, facilitating robust motion primitive extraction suitable for cross-modal alignment.
- Sensor-to-LLM Generation: Variable-length, multi-position token sequences are embedded and aggregated via a Q-Former, with a textual header encoding sensor configuration and segment duration (Figure 5). The fused prompt is input to a frozen LLM (e.g., Qwen 7B), which generates the open-vocabulary narrative conditioned on the sensor evidence.
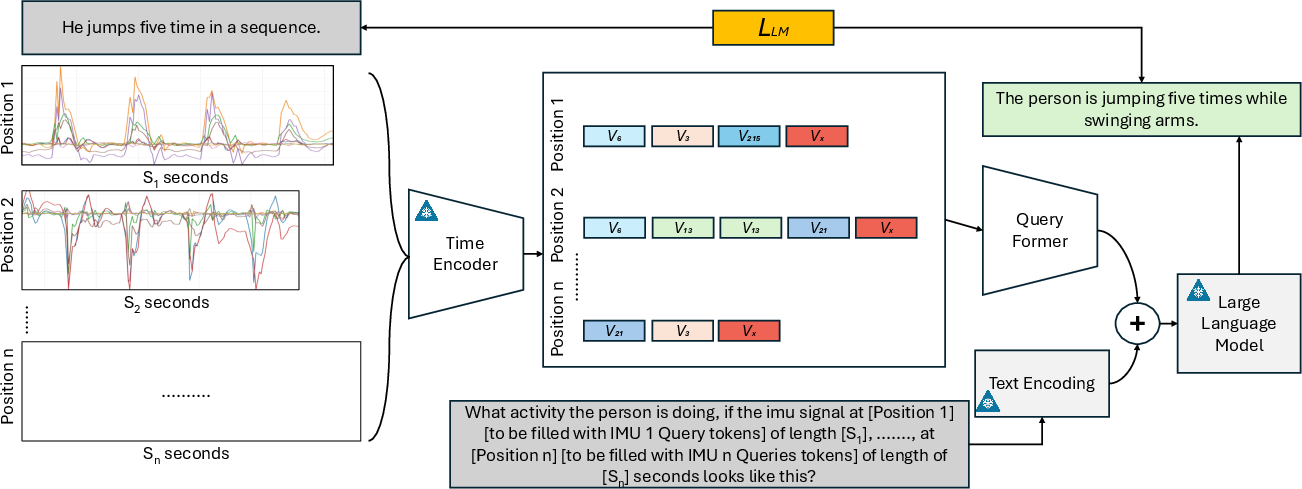
Figure 5: Sensor-to-LLM generation pipeline: Q-Former aggregates arbitrary sensor tokens and formats them for LLM-driven narrative generation.
Token-based augmentations (Figure 6) are used during training to improve compositionality and robustness to annotation and sensor irregularities.
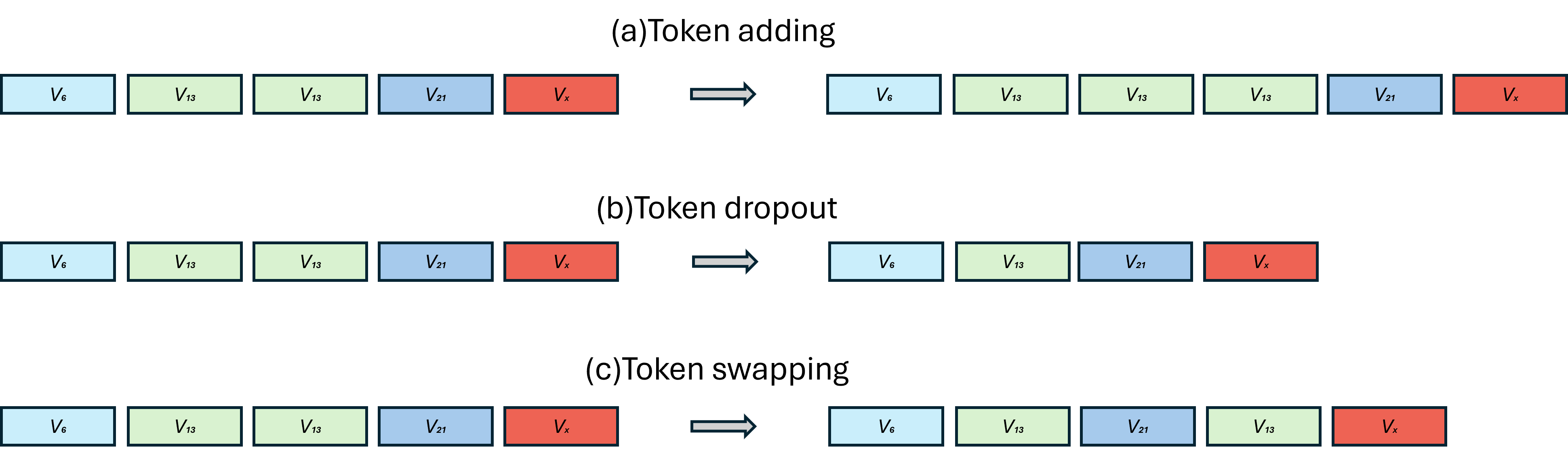
Figure 6: Token-level augmentations for increased variability and transferability of motion primitives in the learned lexicon.
Micro-activity decomposition emerges naturally as recurring token patterns, reflecting shared motion primitives across activities and participants (Figure 7).
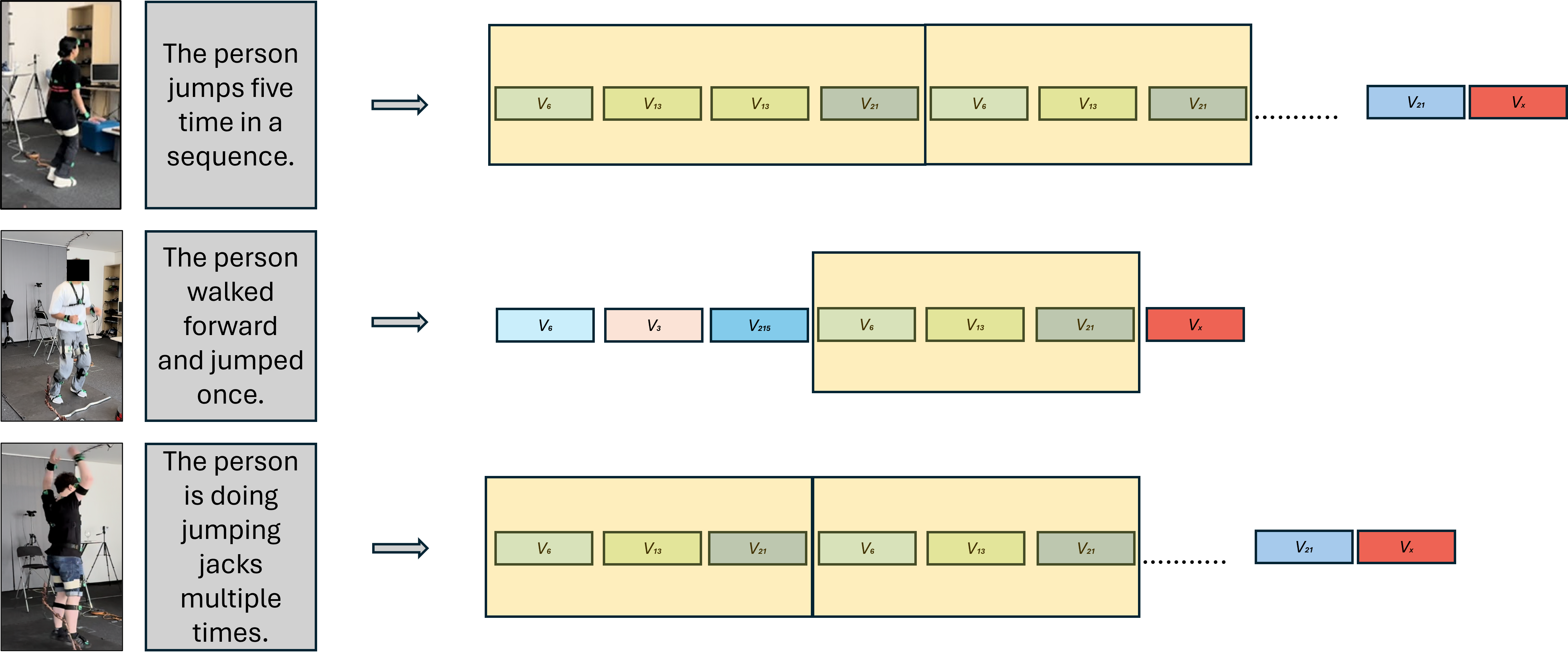
Figure 7: Micro-activity decomposition — similar activities yield related token subsequences, highlighting compositionality in real-world activity streams.
Empirical Results: Robust Sensor–Language Alignment and HAR Generalization
Open-vocabulary Retrieval
Compared to recent sensor–language alignment baselines (IMU2CLIP, OVHAR, PaLM-E), ActNarrator achieves substantial improvements. With Spectral VQ-VAE tokens and Q-Former, R@1 rises to 38.5% (XS) and 34.0% (XP), compared to the strongest baseline at ~23%. Improvement persists across R@5 and MRR. Missing-sensor experiments show graceful degradation, with models retaining >30% R@1 with just one or two sensors.
Closed-Set Classification
When evaluated for 23-class activity recognition, ActNarrator's cross-subject Macro-F1 is 65.3%, nearly doubling DeepConvLSTM and TinyHAR baselines (31–34%). Under cross-position shift (XP), classical pipelines degrade to <20% Macro-F1, while ActNarrator remains at >50%. Notably, the classification head is derived from LLM narrative outputs rather than direct classifier training.
Tokenization Ablations
A dictionary size of K=128 with 2-second windows provides the optimal trade-off in representation fidelity and transfer, as evidenced by minimal time/spectral ℓ1 error and low JS divergence. Discretization yields reusable, placement-invariant primitives necessary for robust sensor–language alignment.
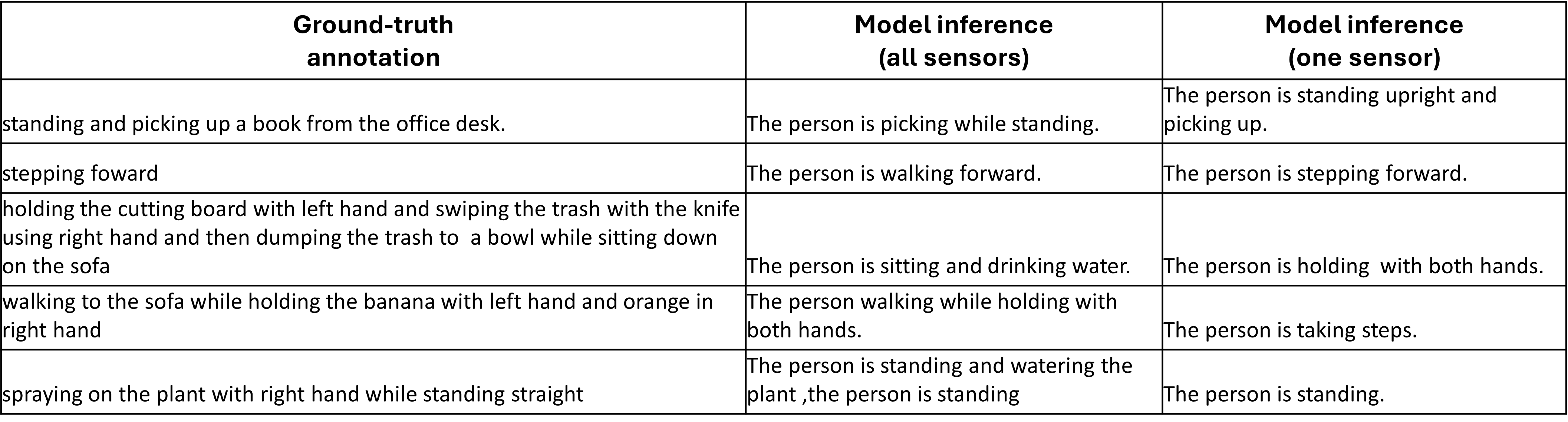
Figure 8: Open-vocabulary outputs for segments using all sensors versus minimal input; LLM generation remains semantically aligned, demonstrating grace under missing-sensor regimes.
Theoretical and Practical Implications
Theoretical Repercussions
- Closed-set Labeling Becomes a Downstream Special Case: Once sensor streams are grounded in open-vocabulary narratives, fixed-class HAR is reduced to constraining the natural language output space. The learned representation is inherently compositional and robust to label set expansion, semantic drift, and taxonomy shift.
- Discretized, Multi-View Motion Tokens Enable Cross-Modal Generalization: Robust sensor–language alignment is enabled by quantized spectral tokens, not by simple scaling of LLM capacity or classifier width.
Practical Consequences
- Deployment Suitability: The framework demonstrates graceful degradation under missing sensors and variable placements, aligning with practical requirements for longitudinal health monitoring, context-aware interfaces, and unscripted field deployments.
- Supervision Efficiency and Extensibility: Expert-annotated soft labels yield the most stable alignment, but narrative-based pipelines can, in principle, leverage user-driven or partially automated annotation expansion without redefinition of the model objective.
- Model Size vs. Inductive Bias: LLMs in the 7–8B parameter range yield best results; further scaling is not efficient without enhanced cross-modal alignment structures.
Future Directions
- Dataset Scaling and Personalization: The open-vocabulary paradigm inherently supports expansion to larger or more demographically diverse datasets, continual learning of personalized or rare activity narratives, and inter-dataset semantic transfer.
- Multi-Modal Integration: Extending the pipeline to handle vision, audio, and physiological streams as equivalently tokenized modalities could facilitate richer, context-aware narratives.
- Evaluation Beyond Label Recovery: Future benchmarks must move towards multi-label, compositional, concurrent, and temporally overlapping activity narratives, exploiting the flexibility of language supervision.
Conclusion
ActivityNarrated (2604.00767) operationalizes a departure from closed-set wearable HAR towards a semantically open, robust, and extensible narrative framework. By unifying multi-position discrete motion tokenization and LLM-based generation, it achieves performance that simultaneously dominates both open-vocabulary and closed-set benchmarks, especially under sensor and annotation variability. This approach subsumes classical classification as a downstream task and offers a scalable path towards adaptive, real-world activity understanding.