- The paper demonstrates that LLMs exhibit robust strategic reasoning in IPD tournaments by adapting tactics based on environmental conditions and opponent behavior.
- The methodology employs a 2x2 factorial design and evolutionary reproduction across diverse tournament settings to compare model capabilities under varying termination probabilities.
- Key findings reveal distinct strategic fingerprints, with Google's Gemini showing aggressive retaliatory tactics and OpenAI models favoring cooperative strategies.
LLMs Exhibit Strategic Intelligence in Iterated Prisoner's Dilemma Tournaments
This paper (2507.02618) explores the strategic intelligence of LLMs by deploying them in Iterated Prisoner's Dilemma (IPD) tournaments against canonical strategies. The study investigates whether LLMs can reason about goals in competitive settings and adapt their strategies based on environmental conditions. By varying the termination probability ("shadow of the future") in each tournament, the authors introduce complexity to challenge memorization and stochastic parroting. The analysis combines population-level evolutionary metrics with natural language justifications, offering insights into algorithmic cooperation.
Experimental Design and Methodology
The authors implemented a series of evolutionary tournaments, each consisting of five phases where a population of agents engages in round-robin IPD matches. After each phase, agents reproduce in proportion to their average per move score. The core experiment follows a 2 × 2 factorial design, crossing model capability (basic vs. advanced) with the "shadow of the future" (10% vs. 25% per-round termination probability). Additional tournaments were conducted as stress tests, including a 75% termination regime and a persistent mutation regime that re-injects a Random agent each phase. The agent set included ten canonical IPD strategies (e.g., Tit-for-Tat, Grim Trigger) and LLM agents from OpenAI, Google, and Anthropic. LLM agents received a standardized prompt for every move decision, including game rules, payoff matrix, termination probability, and complete paired move history. The reproduction procedure amplifies selection pressure, favoring strategies that perform well relative to the average performance of all unique strategies present in a given phase.
Key Findings and Strategic Fingerprints
The study found that LLMs are competitive in all variations of the tournament, demonstrating the ability to survive and proliferate in complex ecosystems. The models exhibited distinctive and persistent "strategic fingerprints," with Google's Gemini models proving strategically ruthless, exploiting cooperative opponents and retaliating against defectors, while OpenAI's models remained highly cooperative. Analysis of nearly 32,000 prose rationales revealed that models actively reason about both the time horizon and their opponent's likely strategy, which is instrumental to their decisions.
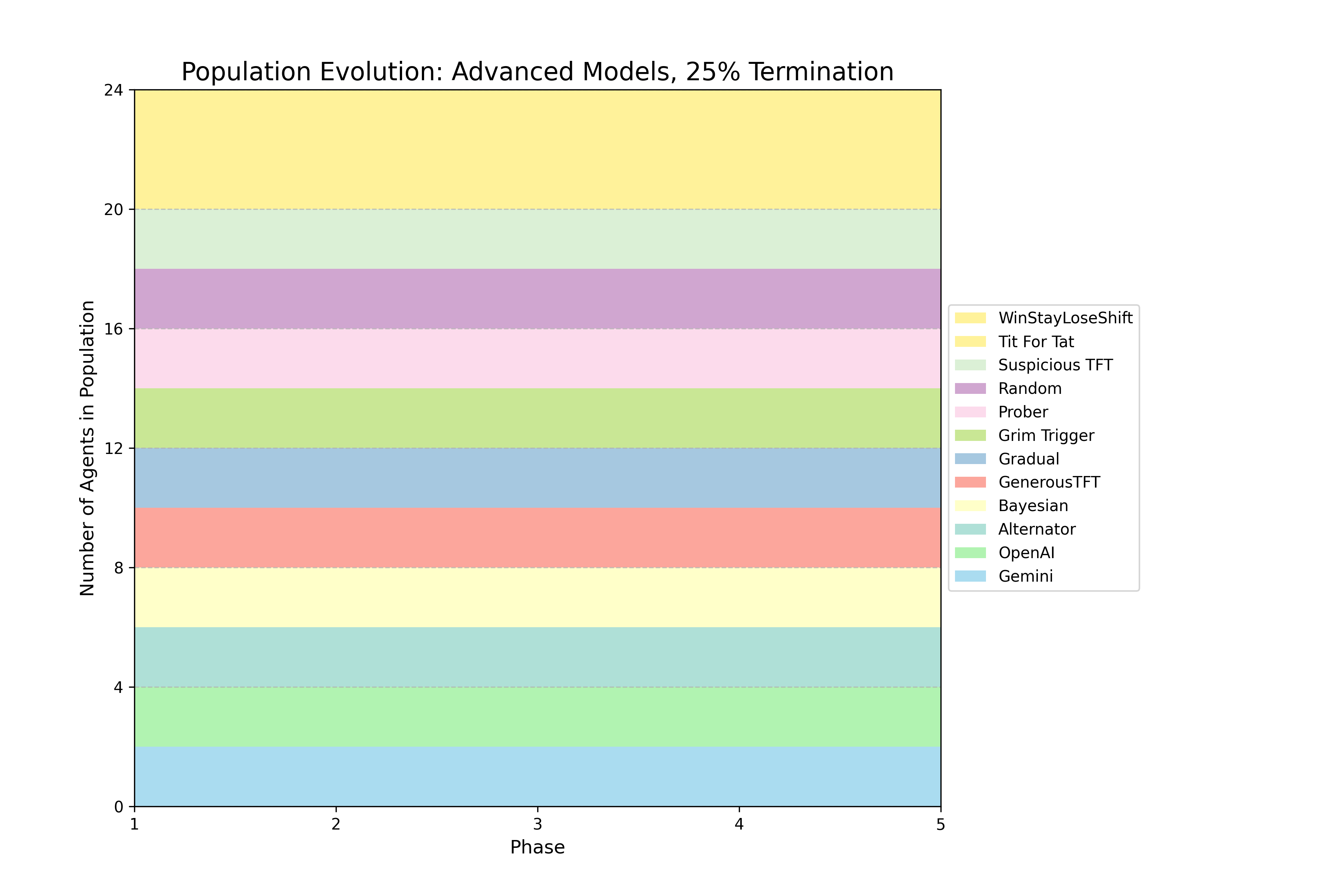
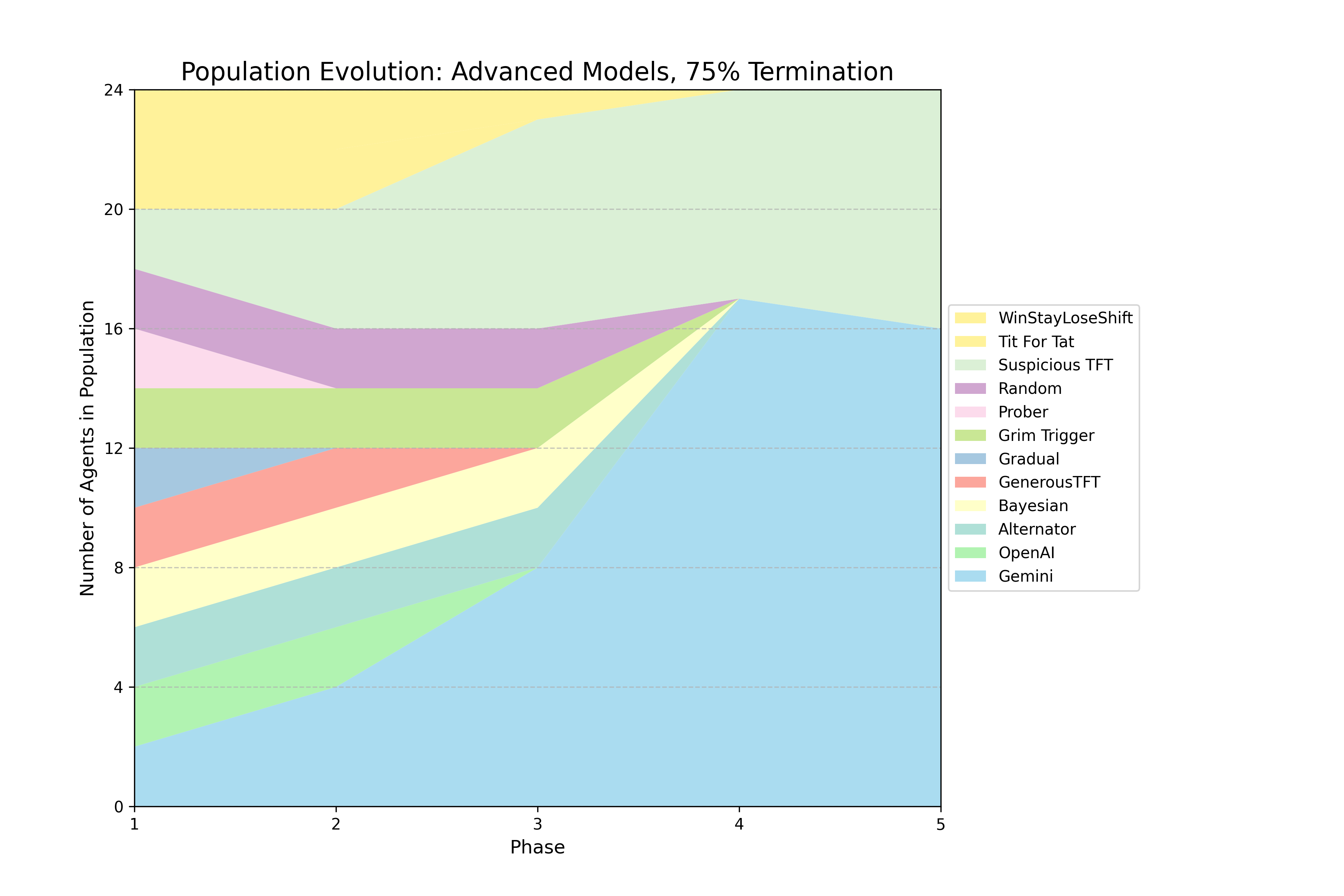
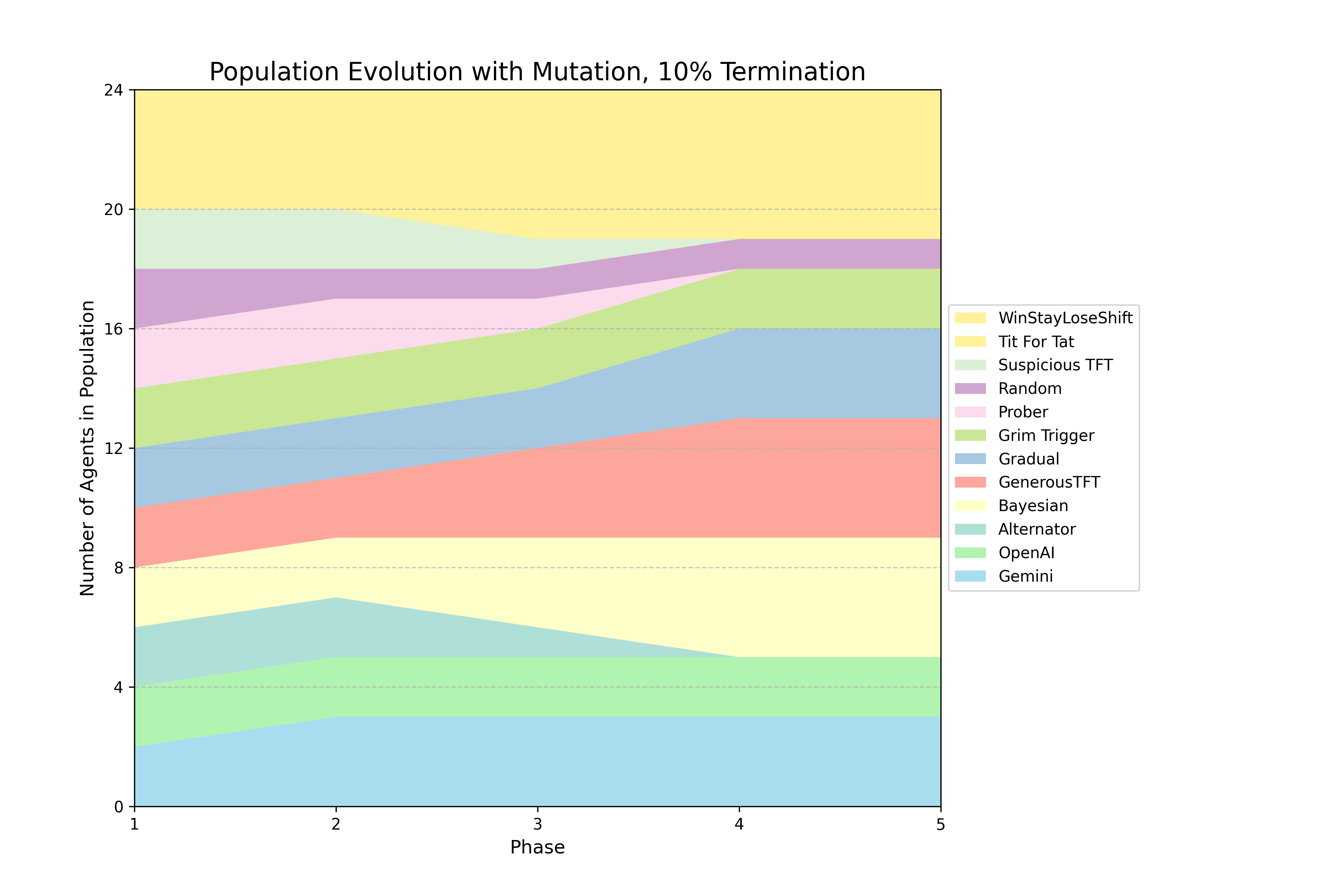
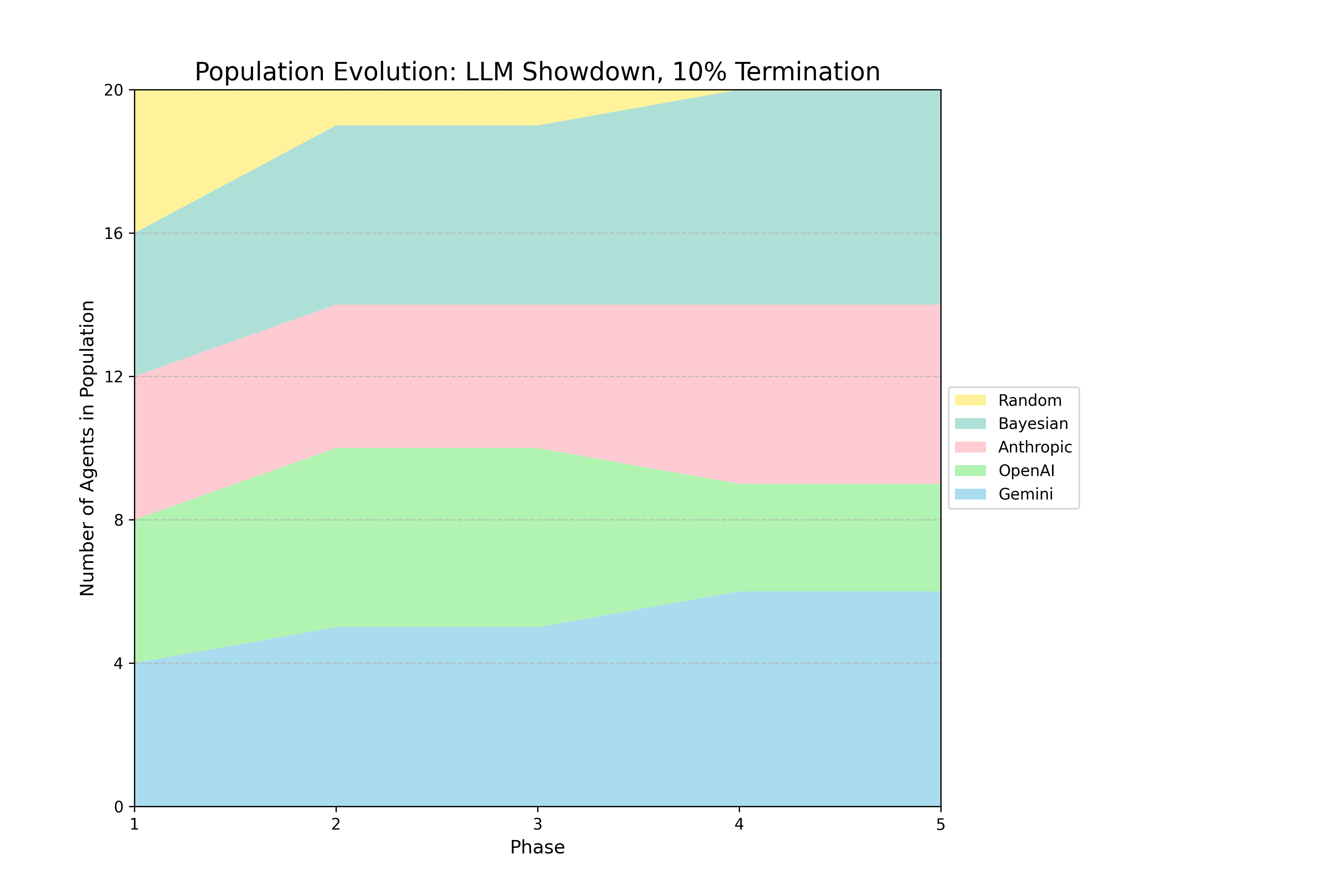
Figure 1: Selected Evolutionary Dynamics
The strategic fingerprints (Figure 2) visualize agent logic as a response to the prior round's outcome, contrasting Gemini's smaller, "spiky" fingerprint with OpenAI's more rounded shape. Gemini's fingerprint indicates a strategic actor, willing to retaliate and prepared to exploit over-cooperators; OpenAI has a more forgiving, and generally cooperative strategy. In the LLM Showdown tournament (Figure 3), Gemini remained strategic, willing to retaliate and exploit, while OpenAI was much more forgiving and trusting, though not as much as the Anthropic agent.
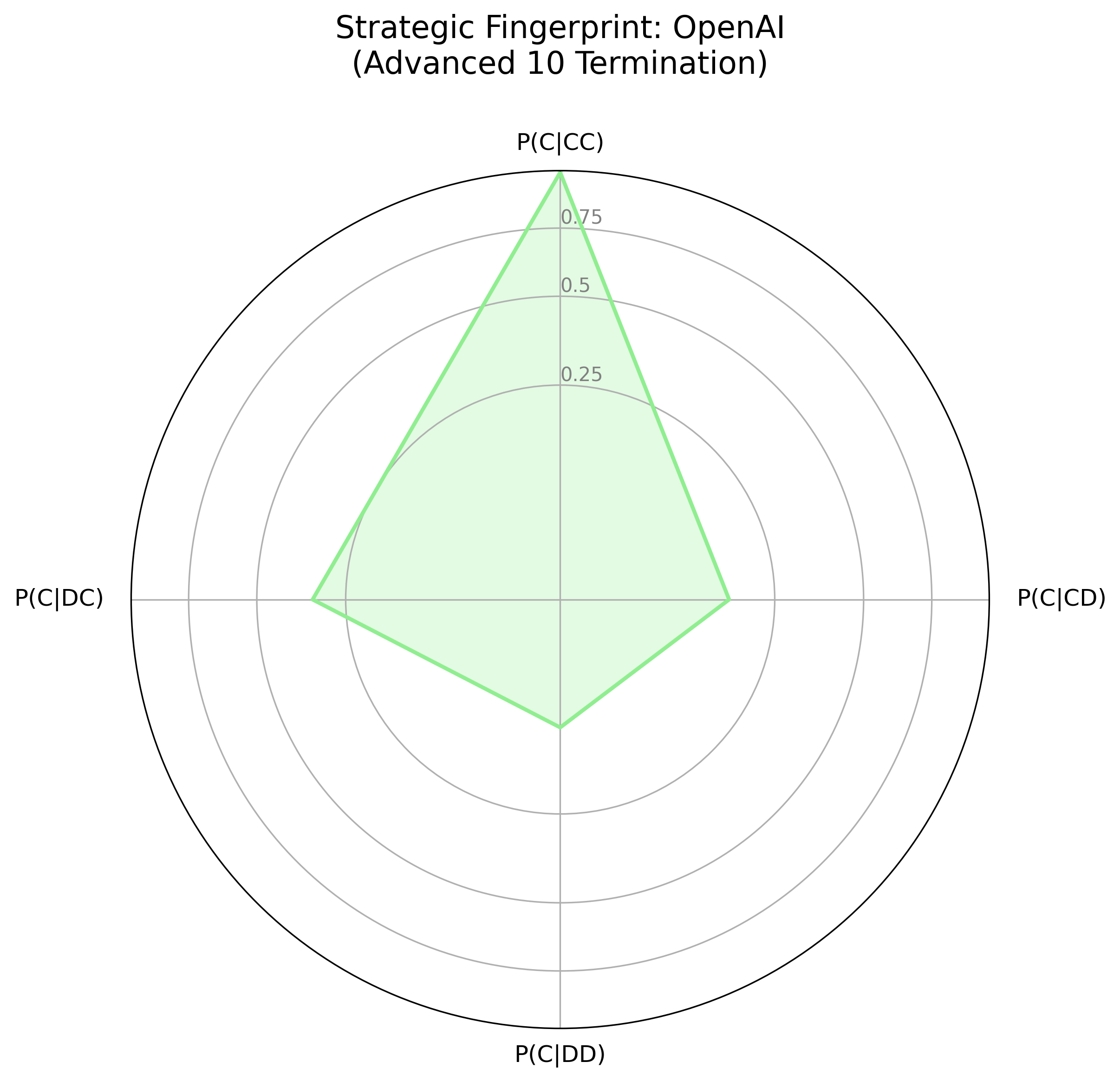
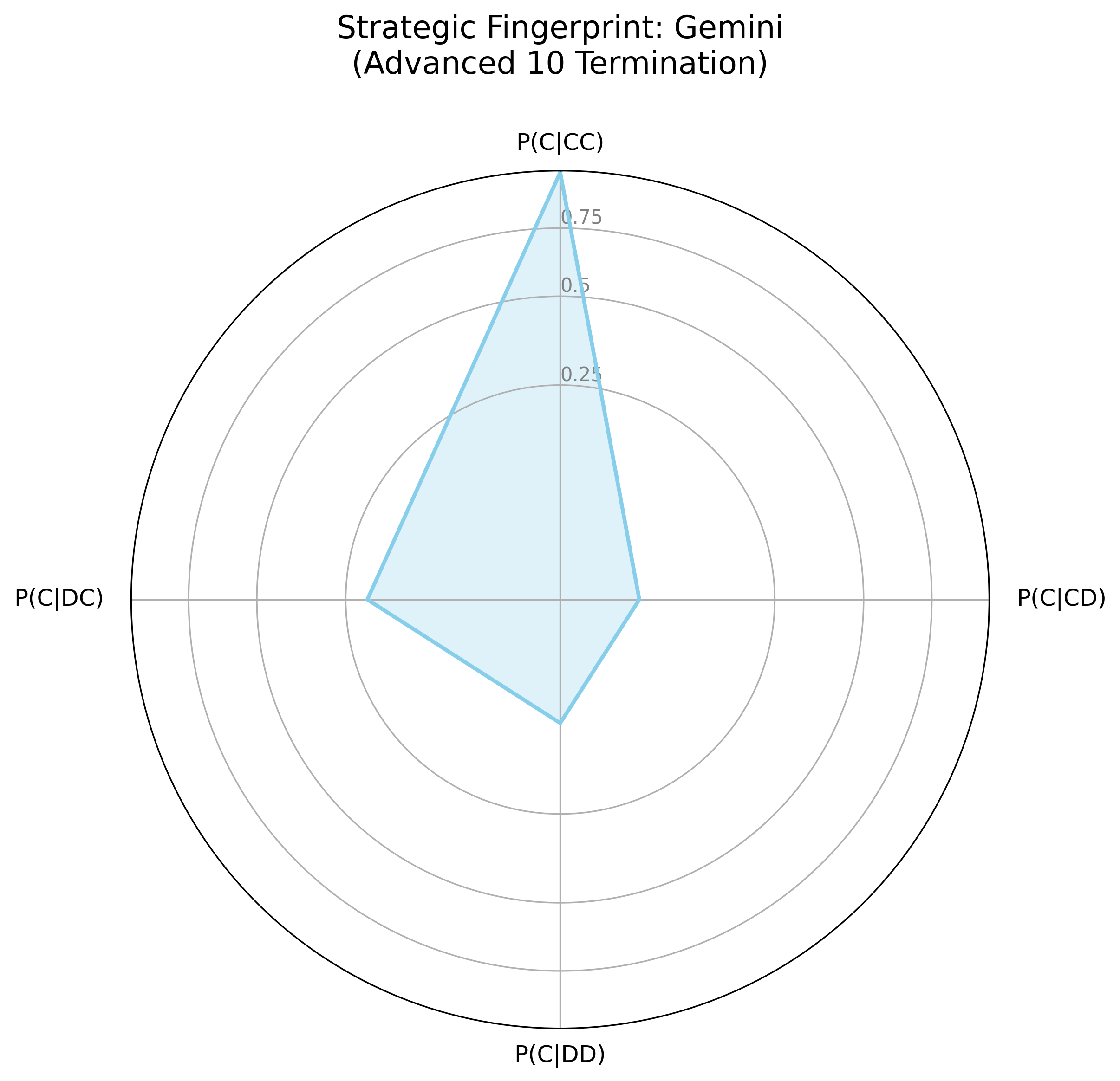
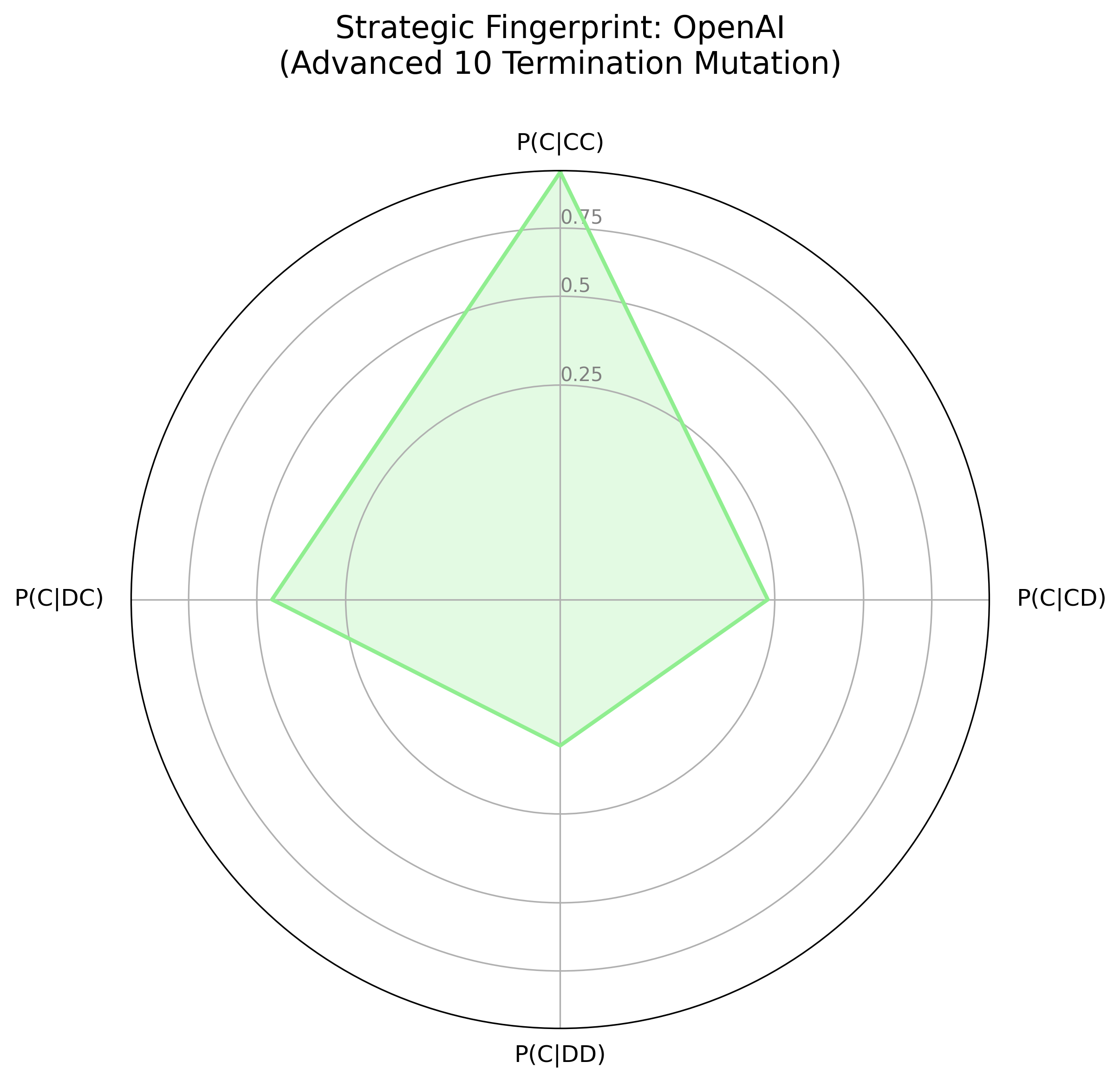
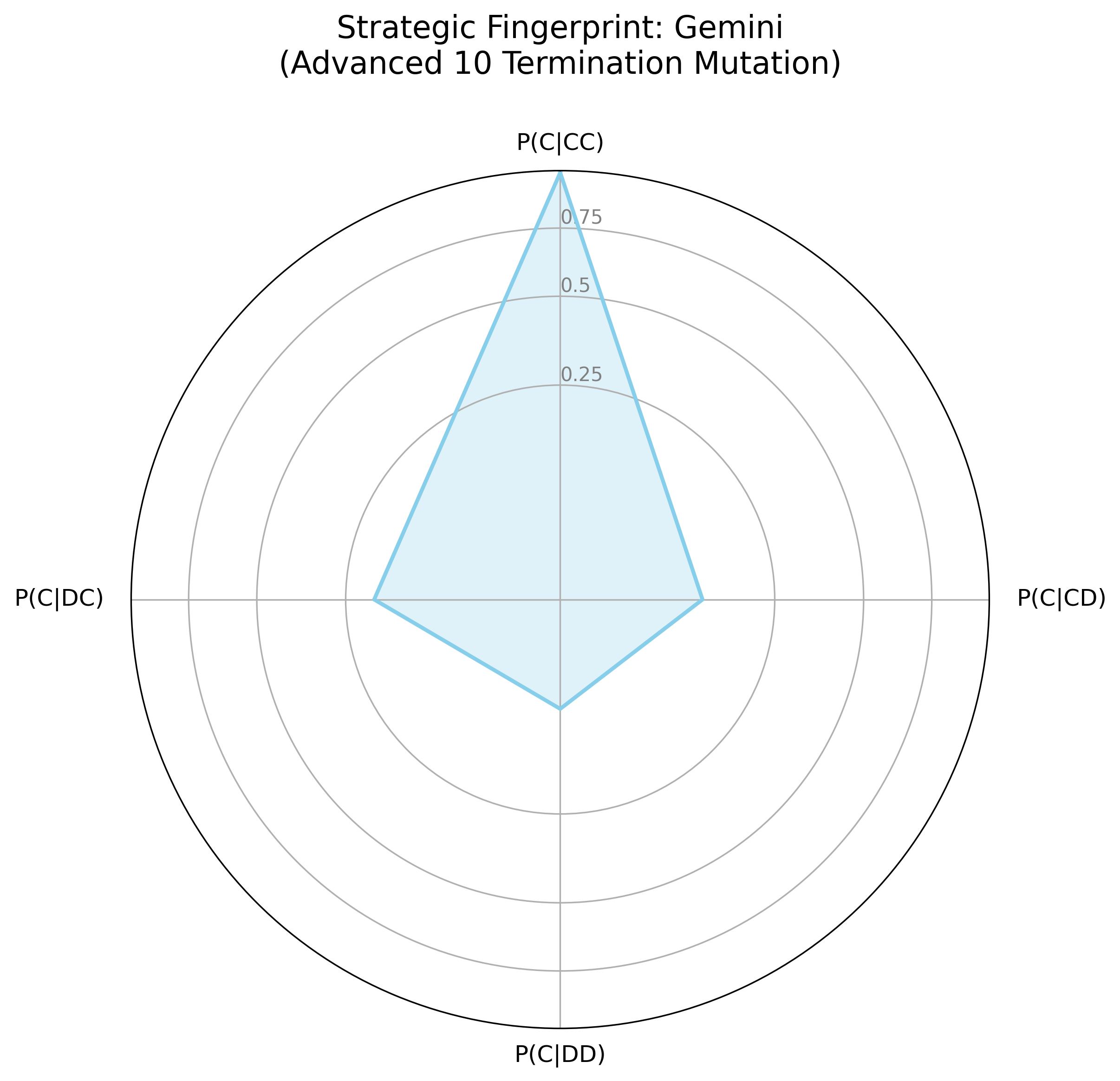
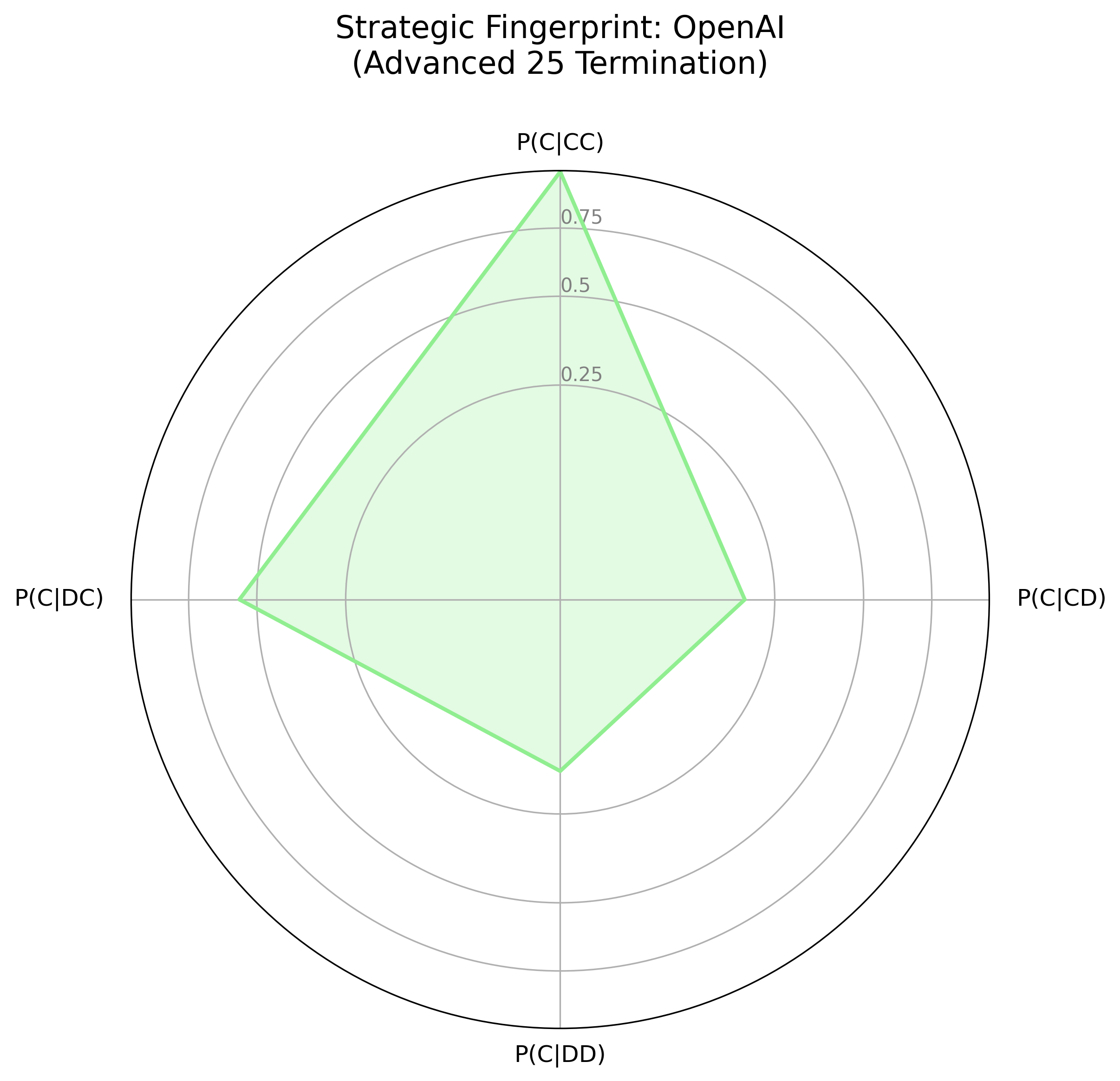
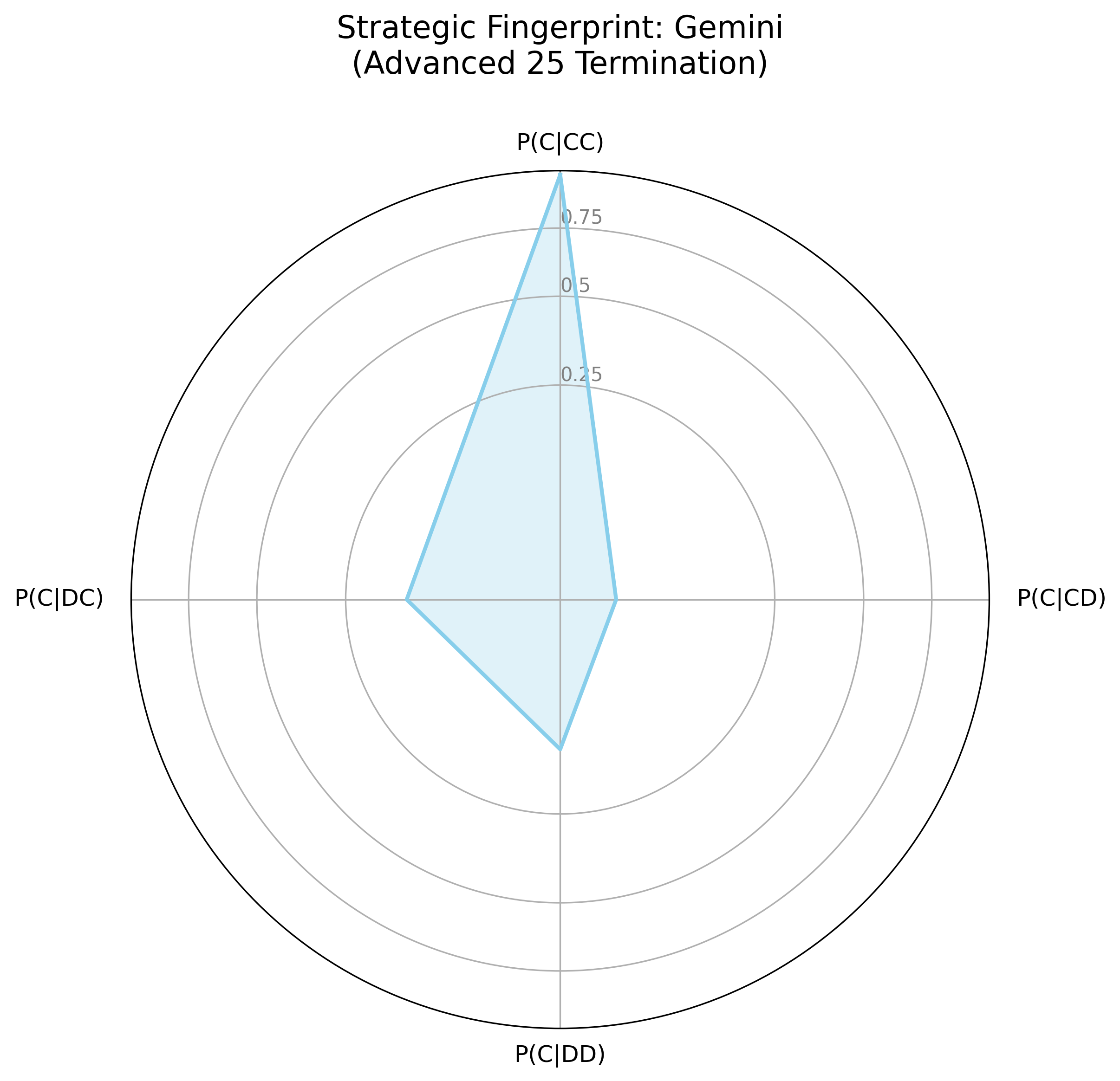
Figure 2: Strategic Fingerprints for OpenAI and Gemini Models Across Tournament Conditions
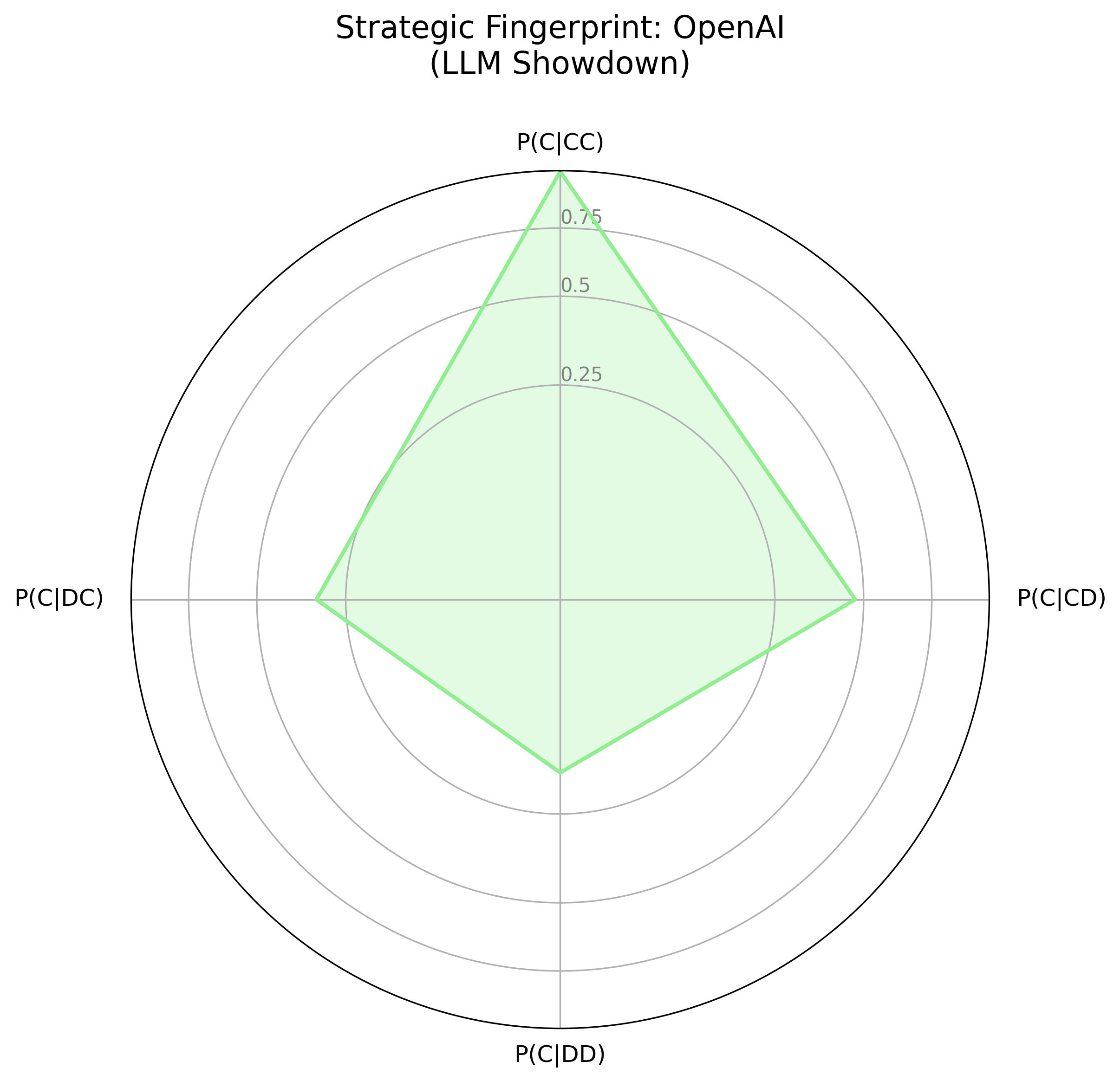
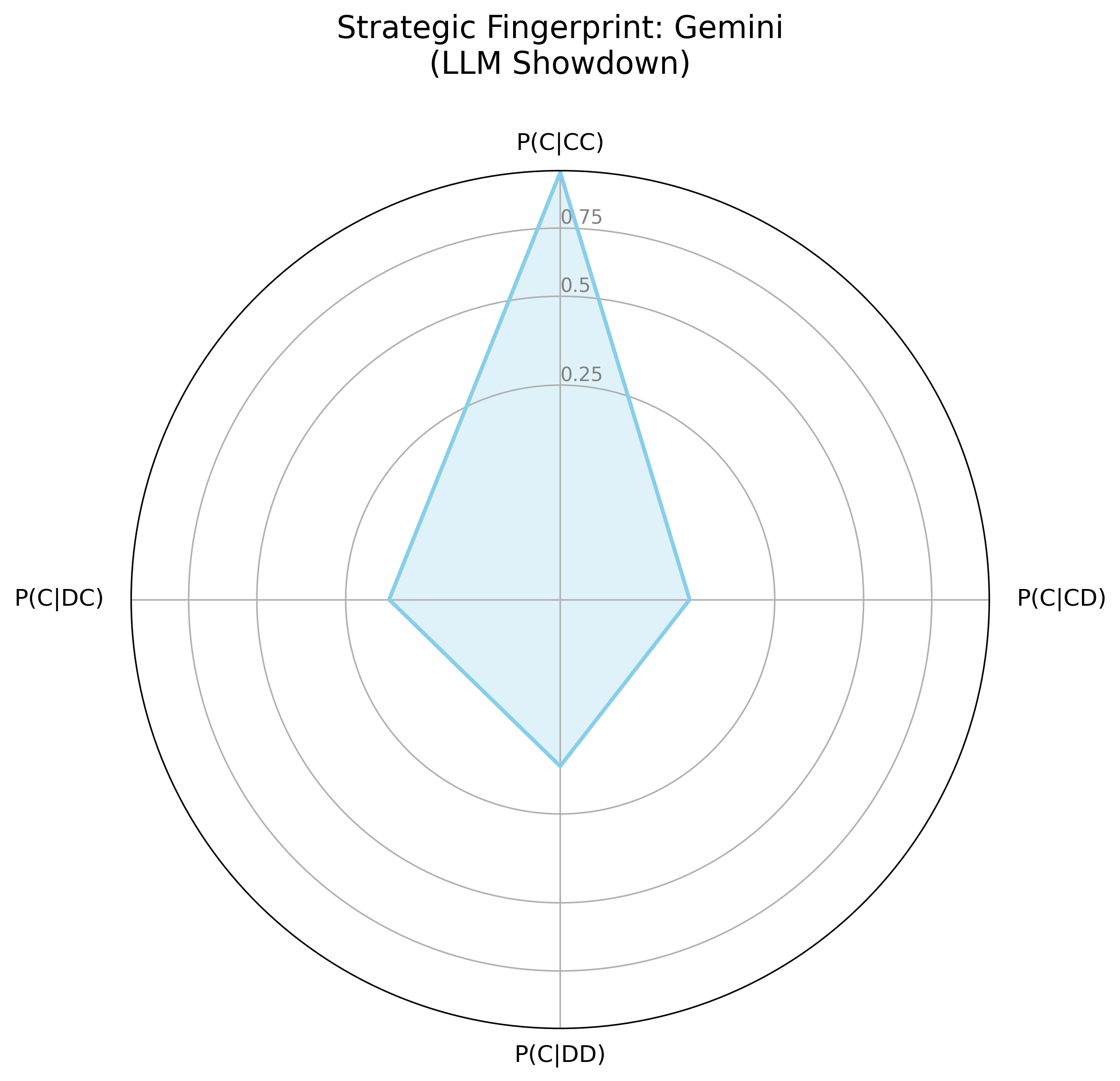
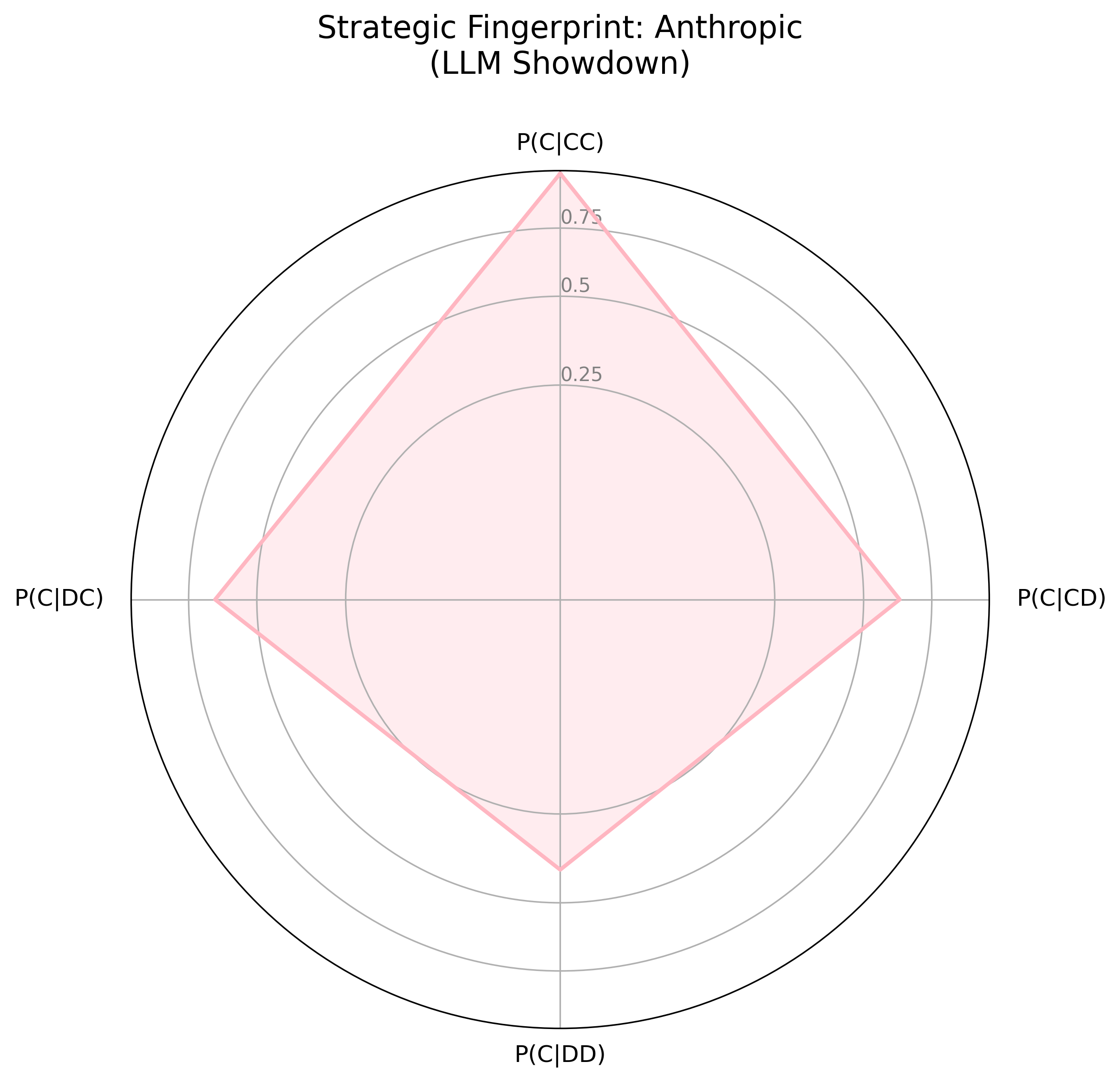
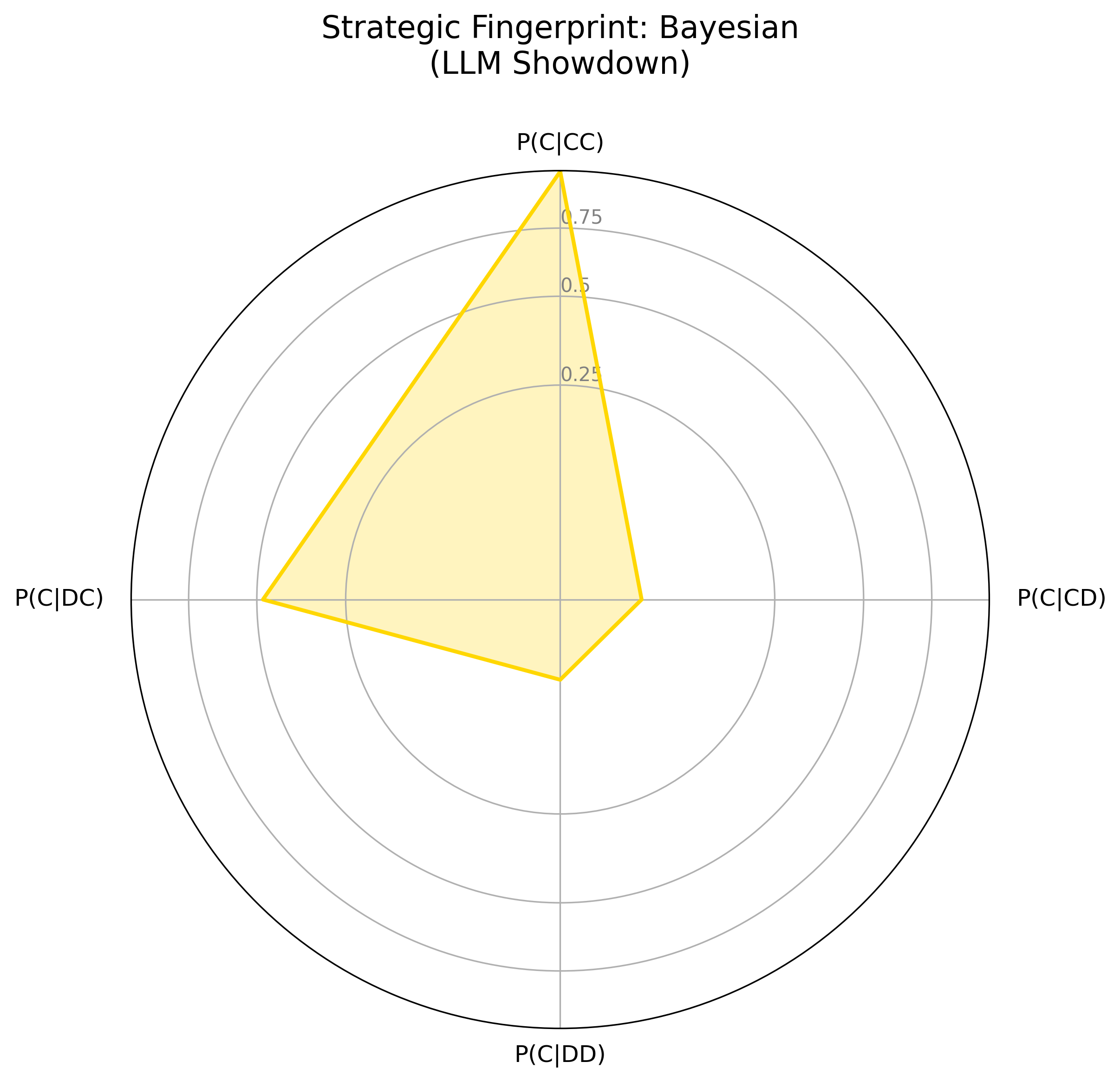
Figure 3: Visual Strategic Fingerprints from the LLM Showdown
Impact of Horizon Length and Adversary Modeling
The study provides evidence that models perform differentially under different shadow-lengths and explicitly factor it into their rationales. The models consider and respond to adversary behavior when making decisions, often figuring out what classic agent they are facing and adjusting accordingly. This is particularly true of Gemini, which exhibits a greater willingness to experiment with defection.
Discussion and Analysis of Reasoning
The authors performed qualitative content analysis of the textual rationales generated by the LLM agents. Results show that the LLM agents consistently reflect on both the temporal and social dimensions of the game. They are not just following simple, pre-programmed rules; they are actively reasoning about their environment in a way that has parallels with human strategic thought.
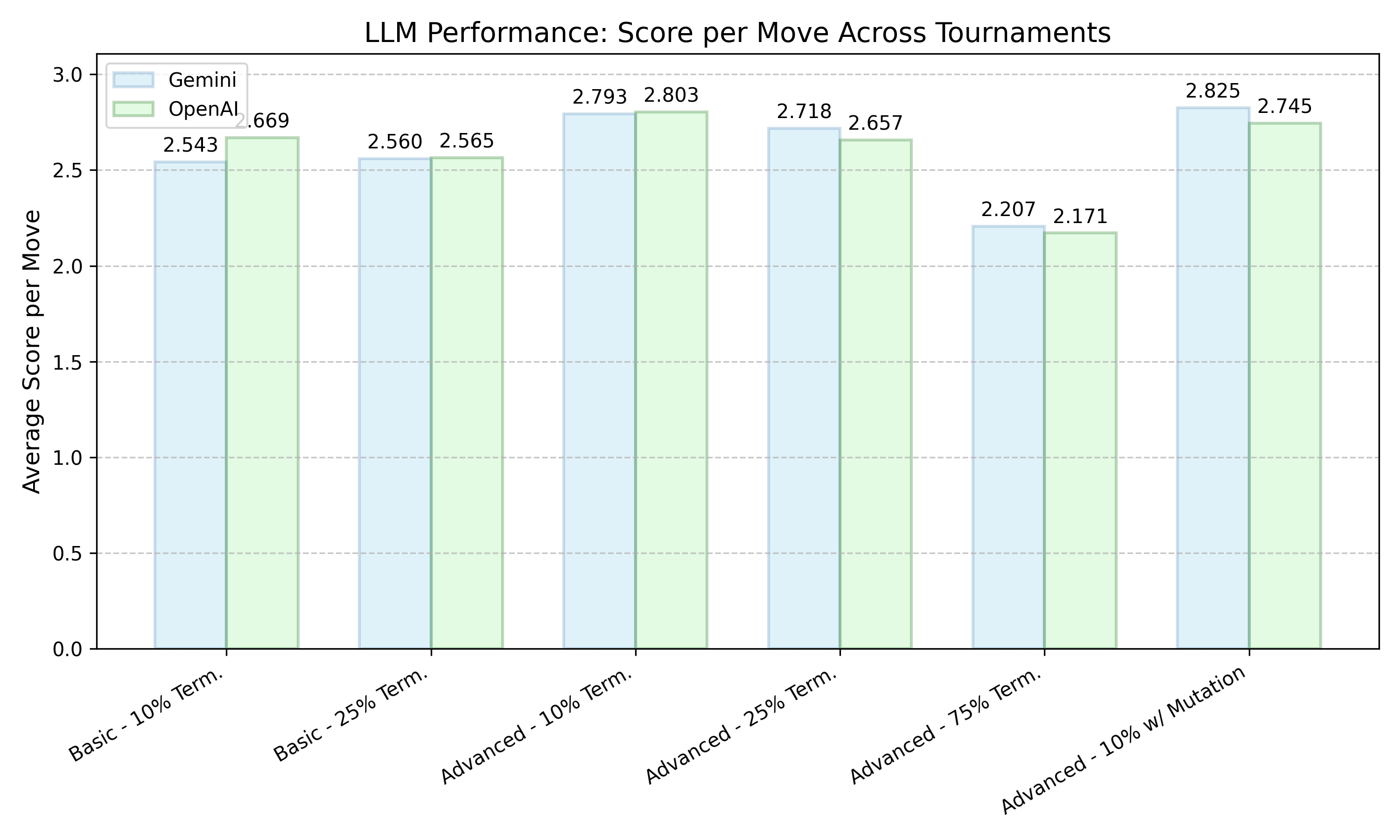
Figure 4: Comparison of average scores per move for Gemini and OpenAI across different tournament conditions. While the absolute scores can be close, the relative performance against the field determines evolutionary success.
The models reason about the time horizon of the games and the likely strategy of their adversary, based on their previous moves. Both forms of reasoning have a clear, demonstrable effect on their decision-making, and that effect differs between models. Gemini's cooperation rate varied much more than OpenAI's, being more cooperative when it suited the conditions of the tournament and less so when it did not. OpenAI models, by contrast, remained highly cooperative even as the shadow-of-the-future diminished.
Conclusion
The study concludes that LLMs are strategic actors in IPD tournaments, holding their own against classical models and engaging in reasoning during gameplay. The findings support the notion that LLMs are capable of strategic reasoning, and the contrasting strategic styles of the models further reinforces this conclusion. The paper contributes to the debate over memorization versus reasoning in LLMs by demonstrating that LLMs can adapt to novel situations and make decisions based on reasoning rather than simply retrieving memorized patterns. The ability of LLMs to engage in strategic reasoning has implications for the development of AI agents that can operate in complex, competitive environments.