- The paper introduces LDMDroid, a framework using state-aware LLM planning to trigger and validate data manipulation functionalities in Android apps.
- It employs UI state tracking and vision-based DUM extraction to synthesize adaptive test sequences for various DMF operations.
- Evaluations demonstrate 75.7% DMF coverage and a 61.6% true positive rate in bug detection, outperforming existing automated testing tools.
LDMDroid: LLM-Guided Detection of Data Manipulation Errors in Android Applications
Introduction and Problem Motivation
Correctness in Data Manipulation Functionalities (DMFs)—comprising CRUDS (create, read, update, delete, search) operations—is central to Android app reliability. Data Manipulation Errors (DMEs) often manifest due to semantic or logic bugs intricately tied to user-specific UI event sequences rather than explicit crashes. Traditional UI testing frameworks either inadequately cover semantically rich DMF paths, or require intensive manual scripting, making systematic detection of DMEs infeasible at scale.
The core insight of "LDMDroid: Leveraging LLMs for Detecting Data Manipulation Errors in Android Apps" (2604.00458) is the automated use of LLMs to both synthesize interaction sequences for DMFs and to verify via state-aware oracles whether the resulting data state transitions are logically correct. The LDMDroid framework integrates UI state tracking, event planning, and semantic change analysis to operationalize this paradigm.
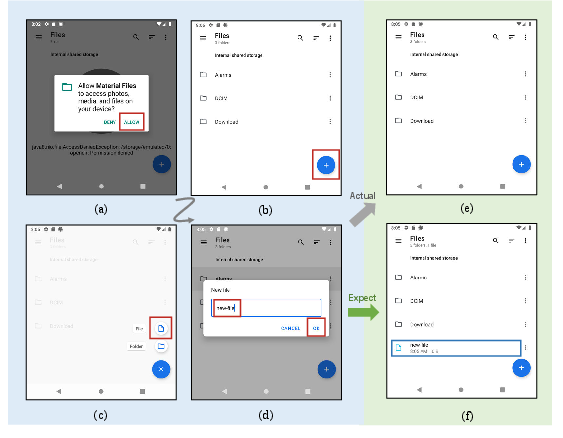
Figure 1: Data Manipulation Error in the Material Files app—expected creation of a new file fails to update the UI list, causing a DME.
Prior work in Android UI testing, such as Monkey, DroidBot, Fastbot2, and Genie, predominantly utilizes random, rule-based, or model-guided event generation, but they cannot robustly trigger app-specific DMFs, nor can they validate logical success in non-crashing scenarios. Some recent approaches (PBFDroid, DMSDroid, Kea) attempt to address DME detection but rely heavily on handcrafted rules and require extensive manual identification of DMF scripts and test oracles, thus limiting scalability and coverage. Other LLM-powered systems (e.g., Guardian, AutoDroid, VisionTasker) offer promising UI semantics understanding but lack mechanisms for context-rich DMF identification or reliable automated oracle design.
LDMDroid represents a unified, fully automated solution targeting both the triggering and correctness validation phases for DMFs by explicitly leveraging state-aware LLM reasoning and vision-based DUM (Data Under Manipulation) extraction without handcrafted logic for each app or operation type.
LDMDroid Framework
DUM Identification
LDMDroid first utilizes both UI tree structure analysis and LLM-guided exploratory interaction to locate DUMs (e.g., lists displaying user-created entities). The mechanism relies on clustering structurally similar widgets and filtering statically defined views, focusing on dynamic containers.
DMF Instance Collection
Upon identifying a DUM, LDMDroid synthesizes UI event sequences for the five DMF types using prompt-based LLM planning. A key method is the integration of general step workflows (for each DMF type) and state-aware context—where the LLM is informed after every action not only about the event history but also about the semantic UI changes as deduced from pre- and post-action screenshots at each step. This closed-loop design enables adaptive planning that aligns actual UI progress with the abstract DMF triggering procedure.
State-Aware Verification Oracle
Correctness is validated by comparing the DUM state before and after a DMF operation, mapped to natural language definitions of logical DME conditions (e.g., for Create: the new entity must be visible and identifiable in the list post-operation). LLMs receive a consolidated prompt with all relevant input/output DUM states, user input data, and domain-specific criteria.
Automated Exploration and Bug Detection
LDMDroid interleaves DMF-triggering sequences with randomized UI actions (to simulate real usage variability) and applies its oracle after each DMF trigger. A bug report is generated if logical errors are consistently detected in multiple runs. Both crash and non-crash functional bugs are covered.
Evaluation
Experimental Setup
The framework was evaluated on 24 diverse, actively maintained open-source Android apps from F-Droid/GitHub, pre-filtered to exclude apps in prior datasets to avoid overfitting. Comparative evaluation was conducted against Guardian, DMSDroid, Fastbot2, Genie, Odin, PBFDroid, and relevant ablation variants of LDMDroid (removing UI change tracking and progress modules, or DUM-based oracle).
DMF Triggering and Exploration
LDMDroid demonstrated a DMF coverage of 75.7% and a sequence success rate of 62.5%—substantially outperforming Guardian (54.2% coverage, 29.9% success) and DMSDroid (11.6% coverage, 5.9% success). The inclusion of state-aware UI change tracking and progress awareness modules proved critical: removing either caused coverage and success to drop below 65%, illustrating the impact of semantic feedback in LLM planning.
Notable failure cases arose where DUMs had non-canonical structure (e.g., data displayed as graphical nodes, not lists) or where LLMs prematurely deemed DMFs complete based on misleading UI cues—highlighting limitations when handling heterogeneous UI modalities or complex-timed workflows.
DME Detection Efficacy
On the full DME detection task, LDMDroid generated 255 bug reports, distilled into 17 unique bugs (61.6% true positive rate), with 14 confirmed and 11 fixed by developers after report submission. Most discovered bugs were non-crashing logic errors that could not be exposed by other automated tools. All bugs found by competing methods were also found by LDMDroid; however, LDMDroid found additional bugs undetected by others.
Removal of the DUM-guided oracle dropped the true positive rate to 39.5%, underscoring the necessity of precise data state tracking for high-precision DME verification. Notably, LLM hallucinations remain a contributing factor in false positives, motivating further research in robust oracle design.
Manual Effort and Model Sensitivity
LDMDroid reduces human time compared to the semi-automated PBFDroid: 173.9 seconds/app for post-hoc filtering versus 627.7 seconds/app for property specification. Although raw bug counts were similar (17 vs 18), LDMDroid covered a distinct subset unable to be specified by PBFDroid, reflecting better generalization. Ablation studies and cross-model evaluation (GLM-4V-Plus, GPT-4o, Qwen2.5-VL) demonstrated stable effectiveness, indicating architectural robustness to LLM backend choice.
Theoretical and Practical Implications
This work demonstrates that state-machine-in-the-loop LLM guidance—where each step's context is calibrated by runtime UI and application state—significantly increases the fidelity of both test generation and verification, especially for semantically rich, non-trivial application functionalities. The findings suggest that integrating vision-based state abstraction as first-class prompt context for LLMs in agentic loop architectures can overcome key limitations of logic-driven or black-box approaches in UI testing.
Practically, LDMDroid's design principles can be generalized to other platforms with similar data-centric logic and dynamic UI composition (e.g., iOS, web apps). The reduction in manual effort for high-value logic bug detection will be especially relevant for app store security and reliability vetting pipelines, continuous integration frameworks, and QA outsourcing enterprises.
Theoretically, these results motivate further work on automated abstraction of application semantics from runtime state, improved prompt engineering for robust logical inference under UI ambiguity, and hybrid symbolic–LLM agent designs for other problem domains.
Conclusion
LDMDroid establishes a practical, scalable paradigm for automated detection of logic bugs in Android DMF routines by leveraging LLM-based state-aware planning and verification. Empirical evidence supports strong gains in DMF coverage, error detection yield, and reduction in manual human scripting as compared to prior art. Remaining open problems include robust handling of heterogeneous UI representations and minimizing LLM hallucination in complex logical oracle tasks. The framework is openly available, providing a basis for further extension toward generalized logic bug detection, cross-modal interface testing, and dynamic application analysis (2604.00458).

