- The paper introduces a neural multi-target attenuation system that selectively suppresses bothersome sounds in real time.
- It details a three-layer architecture combining live listening, context reasoning, and personalization to customize sound suppression.
- Empirical evaluations show stable SI-SNR improvement and low latency on mobile devices, supporting practical deployment.
Sona: Real-Time Multi-Target Sound Attenuation for Noise Sensitivity
Introduction and Contextualization
Noise sensitivity—including hyperacusis, misophonia, and general decreased sound tolerance—affects a significant proportion of neurodivergent and general populations. Conventional mitigation approaches, notably active noise cancellation (ANC) headphones and earplugs, achieve global suppression of environmental acoustic energy, but fundamentally limit selective awareness by uniformly attenuating both target (distressing) and non-target (meaningful) signals. Sona introduces a new paradigm for real-time on-device soundscape mediation, leveraging a neural, target-conditioned, multi-source attenuation pipeline that directly addresses the limitations of classically global approaches by enabling fine-grained, compositional, and personalized selective attenuation.
User Needs Analysis and Motivation
A formative survey was administered to 68 diagnosed noise-sensitive individuals, quantifying both heterogeneity and prioritization in sound bothersomeness (Figure 1):
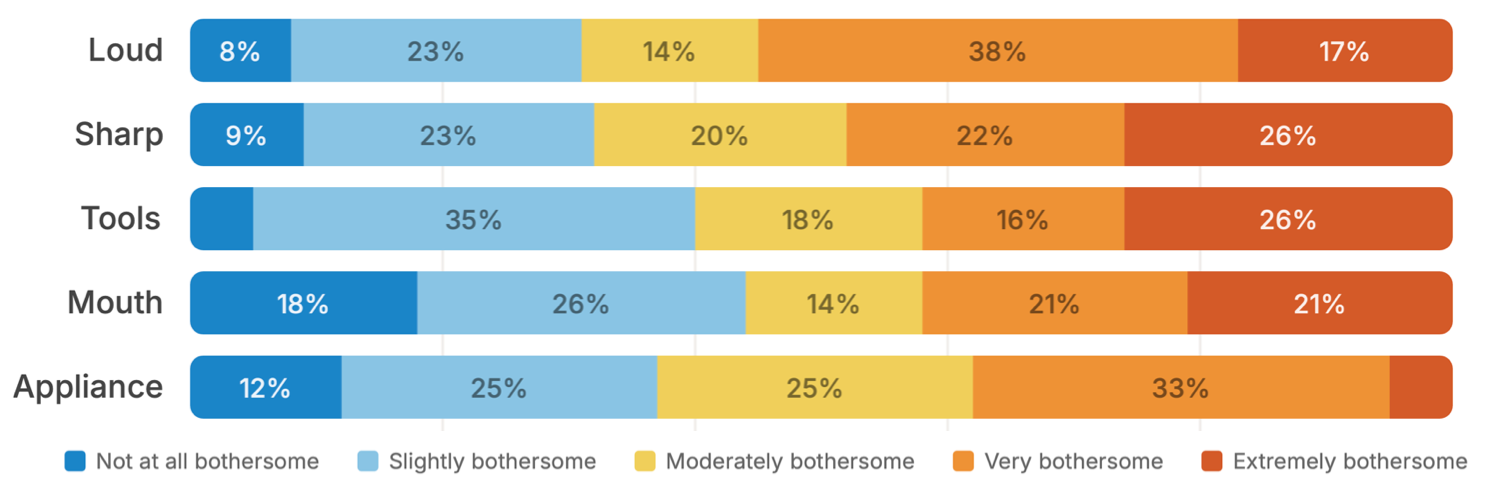
Figure 1: Distribution of participants' reported bothersomeness across sound categories, illustrating both high inter-individual variability and categorical saliency for certain triggers such as mechanical noise, tool sounds, and mouth sounds.
Key findings confirm that bothersome sounds are highly individualized, but mechanical and repetitive noise categories are most salient. Critically, users express a consistent preference for selective reduction or removal over global suppression, and require the ability to personalize mitigation strategies at the sound-class level.
System Architecture
Sona is implemented via a layered architecture that integrates target-conditioned audio processing, context reasoning, and user-driven personalization workflows (Figure 2).
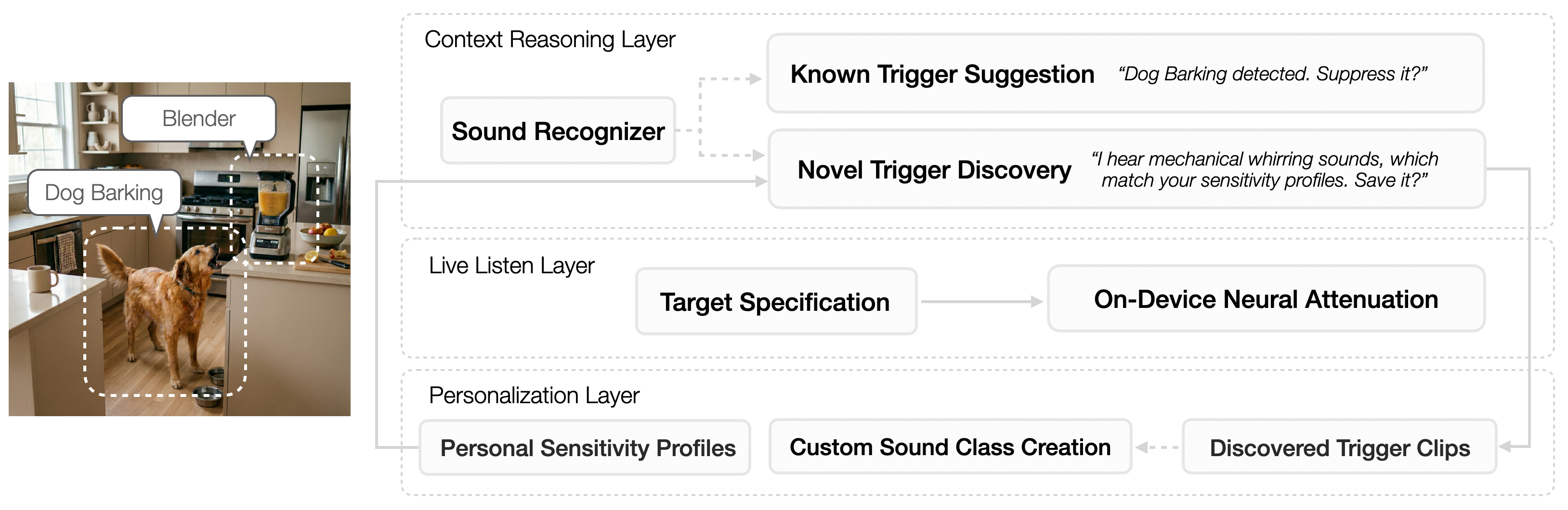
Figure 2: Sona’s three-layer architecture, integrating contextual sound classification, live multi-target attenuation, and extensible personalization via user sensitivity profiles and custom example-driven sound classes.
Live Listen Layer
The core real-time pipeline runs on commodity mobile hardware, capturing ambient acoustic data and (optionally) attenuating up to three user-selected sound classes with continuous strength control. Attenuation is compositional and can be dynamically adjusted, blending original and suppressed signals in real time.
Context Reasoning Layer
Parallel to live processing, this layer performs continuous lightweight classification of ambient sounds and proactively surfaces suggestions when new or supported target triggers are detected. It also enables trigger discovery—flagging previously unsupported sounds that match personalized sensitivity profiles for in-situ extension of the system’s vocabulary (Figure 3).
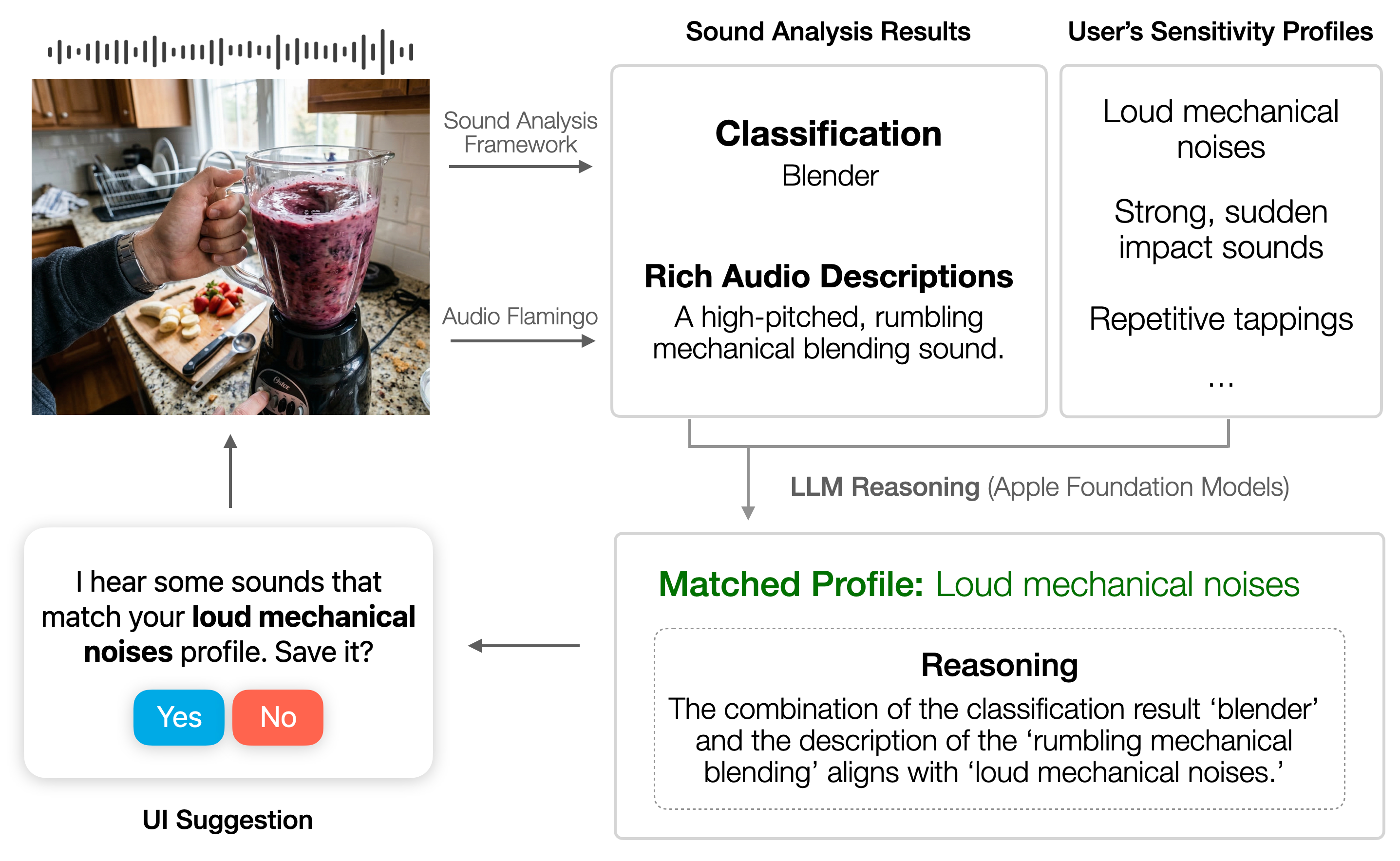
Figure 3: Sona’s trigger discovery pipeline, showing how detection and matching of unknown sounds to sensitivity profiles enables longitudinal personalization.
Personalization Layer
Users manage sensitivity profiles and can record novel trigger sounds to define new custom sound classes, enabling the model to support attenuation of arbitrary idiosyncratic triggers without retraining. These extensions are handled as first-class citizens in the runtime embedding space (see below), and facilitate an evolving, user-aligned mitigation strategy.
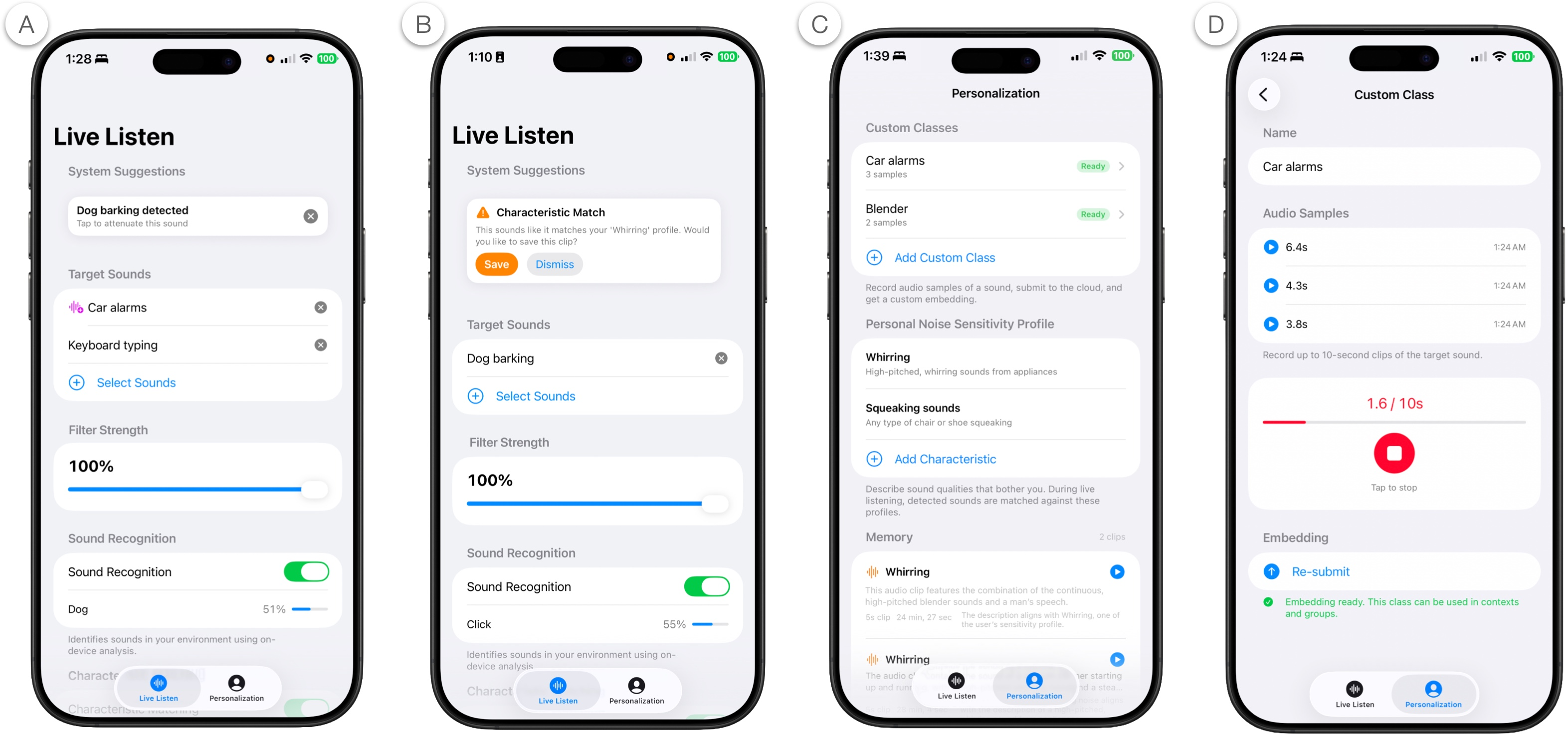
Figure 4: Sona’s user interface: (A) real-time suggested targets and attenuation control, (B) prompt for recording new triggers, (C) custom class/profile management, and (D) custom sound class creation via example recording.
Neural Multi-Target Attenuation Pipeline
Sona’s suppression framework is based on a modified Deep Complex Convolutional Recurrent Network (DCCRN), adapted to support target-conditioned multi-source suppression. The system decouples the specification of “what to suppress” (via a semantic embedding of the selected targets) from “how to suppress,” allowing variable-length, permutation-invariant composition of target sets via learned fusion of sound-class embeddings.
The system maintains an external, extensible store of sound class embeddings. Built-in classes are derived from large-scale pretrained models such as AudioSep (Liu et al., 2023), while user-defined embeddings are synthesized from short in-situ recordings. At runtime, multiple selected target embeddings are fused via a two-layer permutation-invariant projection module, inserted into the DCCRN bottleneck using FiLM modulation. Suppression is regression-optimized to maximize scale-invariant SNR improvement, and training utilizes synthetic environmental mixtures with varying SNR and target co-occurrence configurations, ensuring generalization to compositional multi-target scenarios.
The pipeline achieves 42 ms end-to-end latency on mobile devices, supporting real-time use for auditory mediation.
Technical Benchmarking
Benchmarks on held-out synthetic mixtures from 25 built-in sound classes show robust SI-SNR improvement under increased target count:
- 1-target: SI-SNRi = 3.29 dB
- 2-target: SI-SNRi = 3.00 dB
- 3-target: SI-SNRi = 3.23 dB
Absolute SI-SNR decreases as degrees of suppression increase (as expected, given greater information removal), but relative improvement is maintained, demonstrating architectural stability and robustness in compositional application contexts.
Profiling across diverse acoustic scenes and multi-target settings yielded consistently low latency (<42 ms), stable CPU usage (most runs 17–18%, peaking at 23%), and sustainable battery drain (16.9%/hour), supporting daylong interactive deployment.
In-Situ User Evaluation
A 2-hour scenario-based, in-situ study with 10 noise-sensitive participants confirmed that Sona enables meaningful reduction of bothersome sounds (μ=5.7), robust preservation of desired audio (μ=5.8), and improved subjective manageability of the soundscape (μ=5.8) (Figure 5).
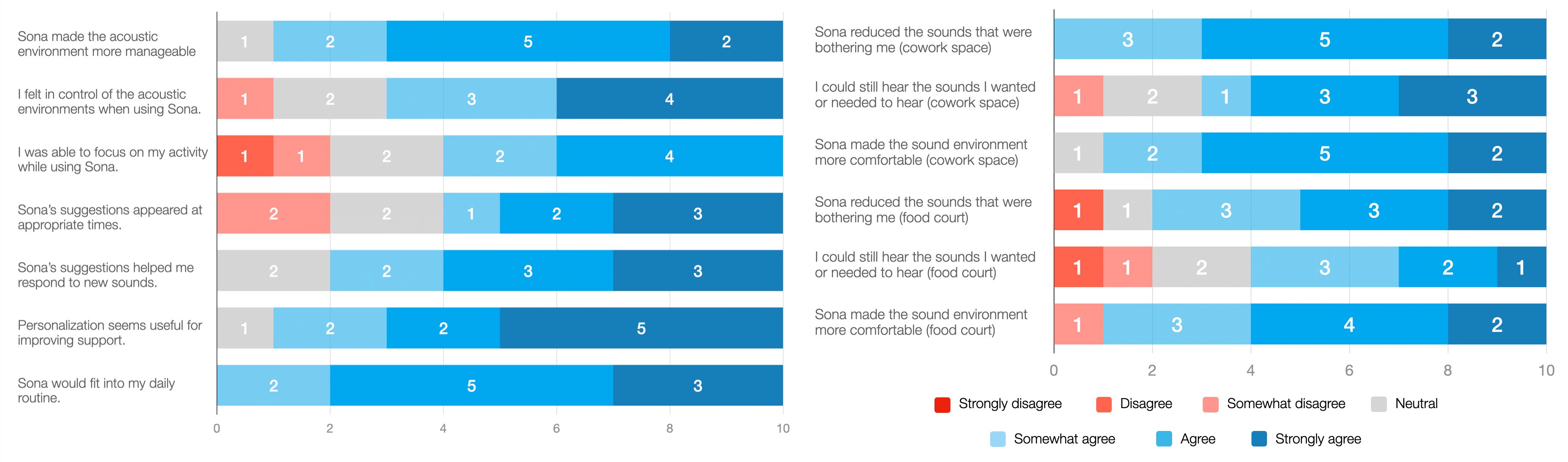
Figure 5: The rating distribution for Sona (1 = strongly disagree, 7 = strongly agree) across relief, awareness preservation, and fit for routine use.
Participants particularly valued selective attenuation for repetitive/mechanical triggers and found compositional target specification to reflect real-world needs. Speech preservation at high suppression strength and with multiple targets remains a challenge, with artifact risk and attenuation of non-target cues being notable failure points under heavy load.
Personalization workflows—especially the ability to add custom triggers—were identified as essential, enabling adaptation to highly individualized profiles that fixed-vocabulary approaches cannot address. Most participants preferred configuring Sona in advance or using environmental presets, and cited acceptability and agency advantages in user-driven over fully autonomous adaptation.
Implications, Limitations, and Future Directions
Theoretical Implications: Sona reframes the sound technology design space from rigid global suppression to interactive, negotiated soundscape mediation, explicitly recognizing the requirement for ongoing, user-steerable, and context-aware balancing of relief, awareness, and participation. This paradigm aligns with broader accessibility research on teachable, personalized end-user AI [kacorri_teachable_2017, jain_protosound_2022].
Limitations: Open issues include speech intelligibility under aggressive multi-source suppression, residual artifact management, and saliency shift to previously backgrounded sounds as dominant triggers are suppressed. Short-duration field studies—while positive—cannot capture sustained personalization dynamics or adaptation across environmental contexts.
Practical Utility/Future Directions: Solutions need to incorporate robust speech preservation mechanisms, artifact minimization, and more legible, low-friction personalization UX (e.g., capture widgets, environmental/preset profiles). Longitudinal deployments are necessary to drive further refinement and to understand agency/adaptivity trade-offs as user needs, routines, and acoustic ecologies evolve.
Conclusion
Sona demonstrates a technically rigorous, architecturally extensible, and empirically validated system for compositional, user-extensible, real-time selective sound attenuation. It offers a concrete step toward personal, negotiated auditory mediation, supporting not only acute relief from overwhelming soundscapes but, crucially, ongoing participation and environmental awareness in everyday life for noise-sensitive individuals.
References
- "Separate Anything You Describe" (Liu et al., 2023)
- Jain, D., et al., "ProtoSound: A Personalized and Scalable Sound Recognition System for Deaf and Hard-of-Hearing Users" (Jain et al., 2022)
- Kacorri, H., "Teachable machines for accessibility" [3167902.3167904]
- Additional citations as per original.
For more detailed evaluation metrics, ablation analyses, or deployment guidance, refer to the original paper (2604.00447).