- The paper introduces a dual-model architecture that leverages self-speech anchoring and turn-taking cues to isolate conversational partners.
- It achieves up to 11.95 dB SISDRi improvement and 80–92% speaker accuracy while operating with 12.5 ms latency per audio chunk.
- Training on synthetic spatialized datasets enables robust real-world performance across diverse languages, speaker counts, and noisy conditions.
Proactive Hearing Assistants for Egocentric Conversational Isolation
Introduction
This paper introduces a real-time, proactive hearing assistant system capable of autonomously identifying and isolating the conversational partners of a wearable device user in multi-party environments (2511.11473). The distinguishing characteristic is the system's proactive adaptation to conversational dynamics, leveraging binaural egocentric audio and self-speech anchoring—eliminating the need for explicit user prompt or manual enrollment. This addresses key limitations of current “reactive” hearing aids that rely heavily on manual selection and spatial filtering, which are impractical in complex, real-world conversational scenarios.
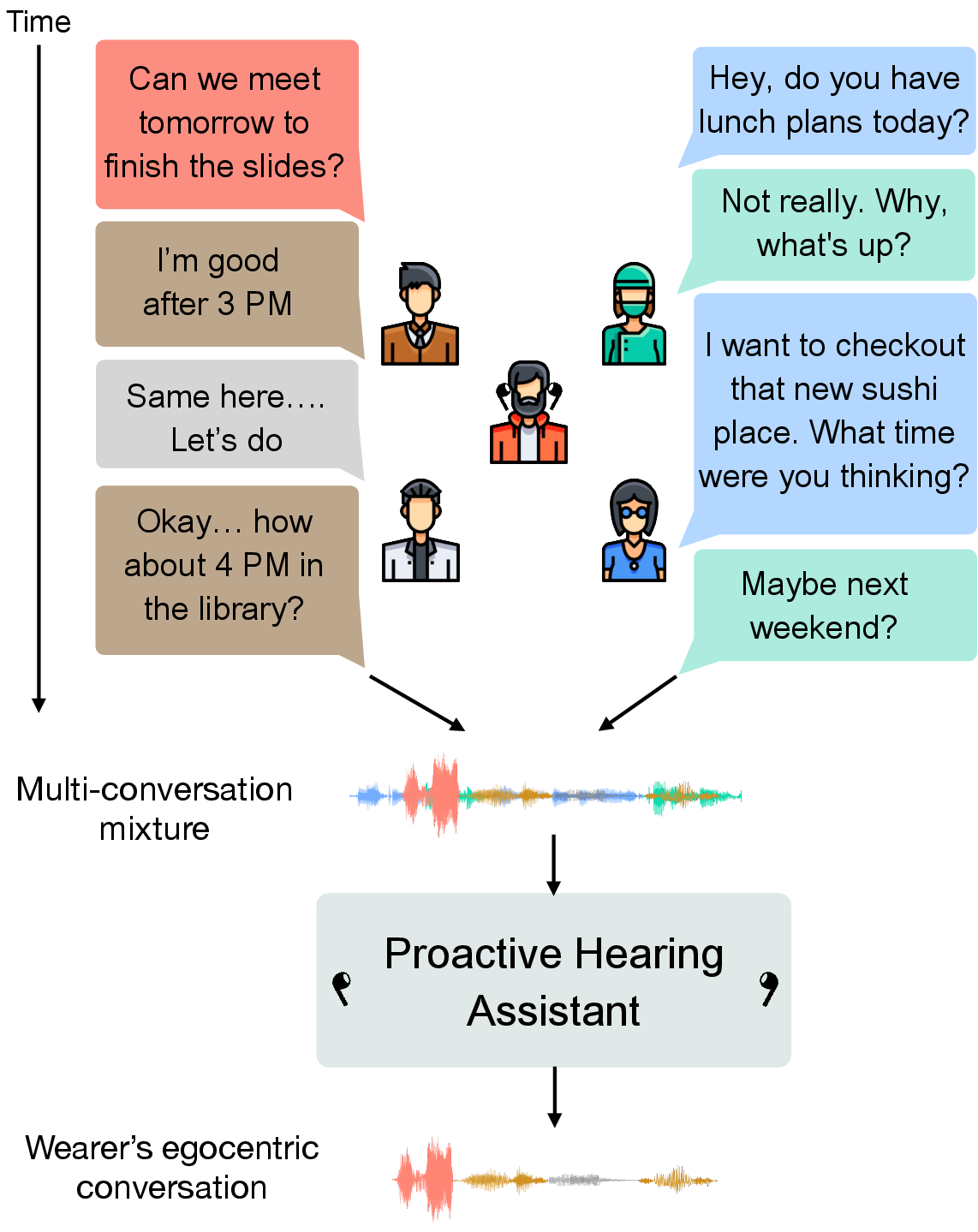
Figure 1: The assistant uses conversational turn-taking to automatically identify and enhance partners while suppressing non-partner speech in real time.
Model Architecture and Processing Pipeline
The authors propose a dual-model architecture: a lightweight streaming model for ultra-low latency partner voice extraction running at 12.5 ms intervals, and a slower model tracking long-term conversation embeddings every 1 s for deeper contextual understanding. The system anchors its inference process on the wearer's self-speech, extracted from binaural mixtures via a dedicated beamformer, using turn-taking and dialogue interaction cues for dynamic tracking and suppression of interfering sources.
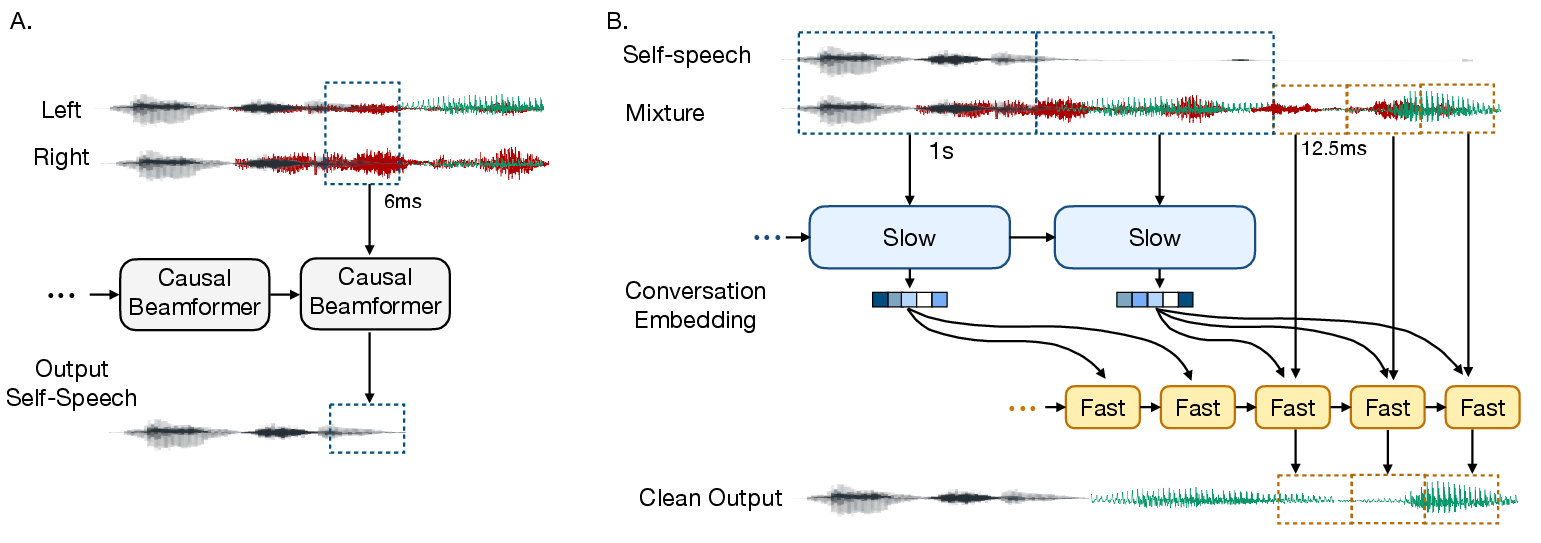
Figure 2: Model pipeline: A streaming beamformer extracts self-speech; a dual-model pipeline recomputes conversation embeddings at a slower cadence to guide real-time voice separation.
The architectural separation is motivated by hardware constraints—long-attention models are memory-intensive and unsuitable for real-time, embedded execution. The solution leverages a fast LSTM-based model for immediate local context, conditioned by embeddings from a slower, attention-based component that processes a broader conversational context. This fusion enables both long-term partner tracking and low-latency audio output.
Training Data and Synthetic Dataset Strategy
Given the scarcity of egocentric multi-party conversational corpora, the authors synthesize training data by spatializing clean conversational datasets to emulate egocentric conditions. Multiple synthetic datasets are created using time-alignment methods and speaker reassignment on corpora such as Candor, LibriTTS, and RAMC, covering 2-/3-speaker scenarios, speaker-leaving events, and even evaluation with 4-/5-speaker mixtures—although training is limited to up to 3 speakers.
A three-stage procedure is used: initial joint training on synthetic data mixtures, spatialization for egocentric simulation, and augmentation to introduce variability in silence/overlap durations, improving out-of-distribution generalization.
Evaluation Metrics and Results
Model evaluation focuses on the partners’ speech quality, using metrics such as SISDRi (scale-invariant signal-to-distortion ratio improvement), ΔPESQ (perceptual speech quality), speaker selection accuracy, and confusion rate (rate of enhancing interfering speakers). The dual-model approach delivers a marked improvement:
Robustness is demonstrated both in out-of-distribution scenarios (SpokenWOZ, RAMC Mandarin, Japanese Duplex datasets) and with unseen speaker counts (4-/5-speaker test sets)—the system maintains high SISDRi (11.85–11.94 dB), suggesting scalability and generalization beyond trained conversational cardinality.
Real-World Egocentric Evaluation
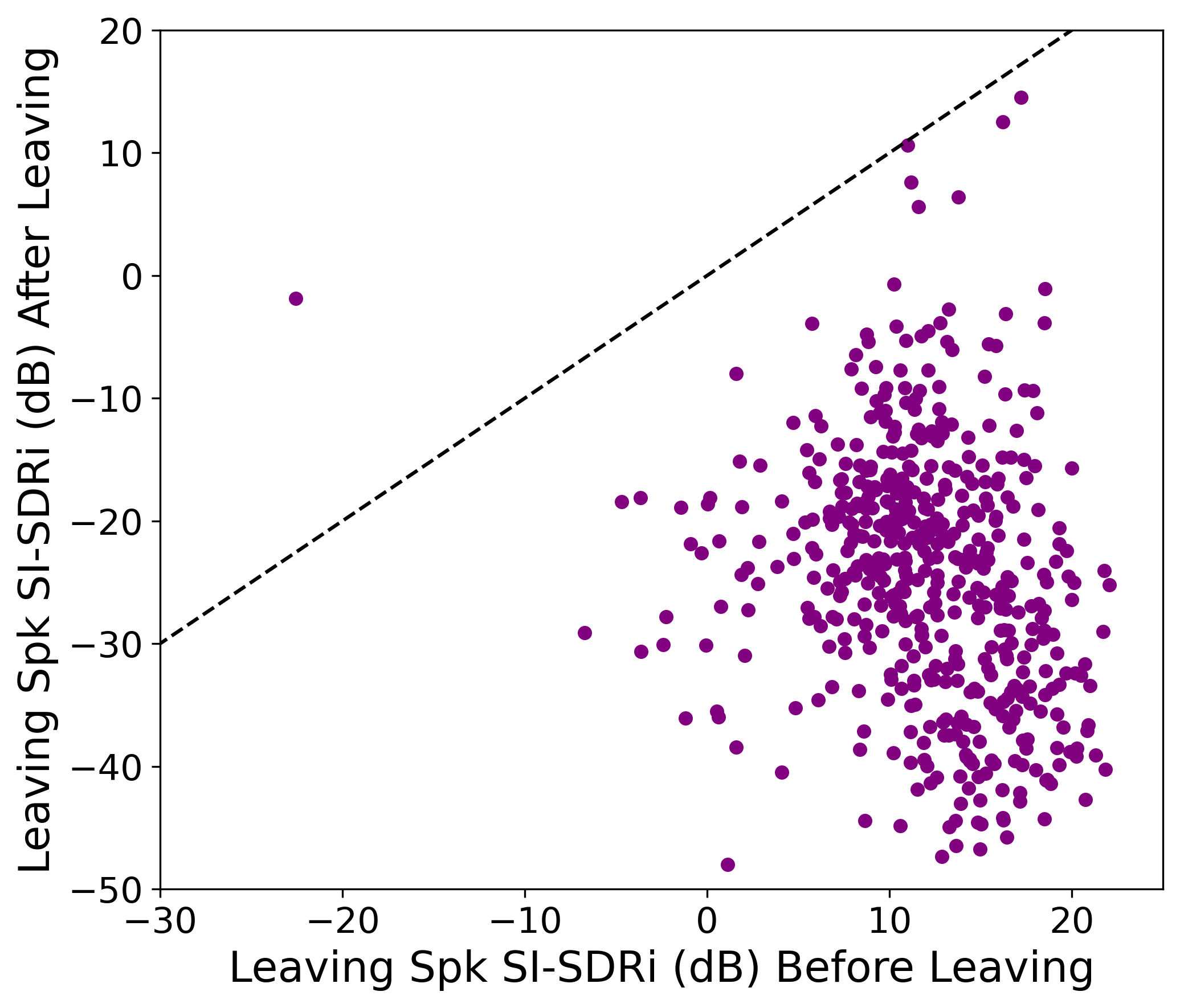
6.8 hours of egocentric audio from 11 participants in realistic environments validate the system's effectiveness when exposed to natural conversational variability, background noise, and speaker transitions. The majority of samples show positive enhancement (Fig. 4). Performance dips when extended wearer silence occurs, as self-speech is the anchor for the partner inference. When the wearer resumes speaking, target partner enhancement recovers.
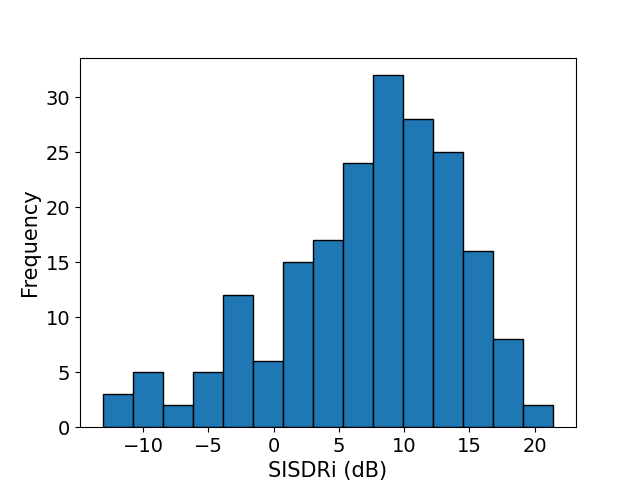
Figure 4: Distribution of SISDRi across egocentric test recordings demonstrates typical positive enhancement for most samples.
A temporal analysis confirms rapid system adaptation—after a partner begins speaking, SISDRi exceeds 8 dB within 2 seconds. Model resilience to turn-change collisions (close temporal overlaps between turn transitions of target and interfering conversations) is lower, indicating directions for future refinement with content-aware features.
Silence-induced anchor loss is visually evident, with enhancement sharply dropping when the wearer ceases to contribute (Fig. 5).
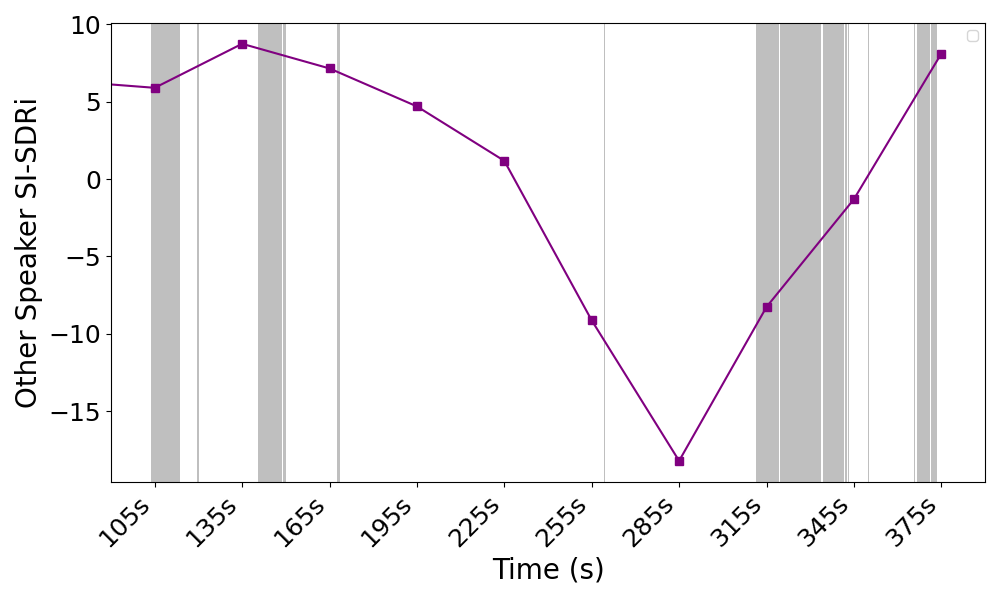
Figure 5: Extended wearer silence correlates with decreased target partner enhancement, highlighting reliance on self-speech anchoring.
Ablation and Subjective Assessment
Ablation studies confirm each system design choice:
- The dual-model architecture outperforms single-model approaches by >10 dB (SISDRi).
- Models utilizing self-speech as anchor outperform speaker embedding methods by 2.65 dB.
- Fine-grained updating of context embeddings (1 s vs 4 s) yields better responsiveness.
- Context length directly impacts SISDRi: limiting to 1 s degrades performance by 5.74 dB.
- Training augmentation with silence/overlap perturbation increases generalization to real-world turn-taking variability.
Subjective user studies reveal substantial improvements in perceived noise suppression, comprehension, effort, and overall experience (mean opinion score raised from 1.88 to 4.30 on a 5-point scale).
Profiling on embedded devices (Orange Pi 5B for the fast model, Apple M2 for the slow model) confirms that real-time constraints are met—streaming inference on typical audio chunk sizes completes comfortably within recording intervals.
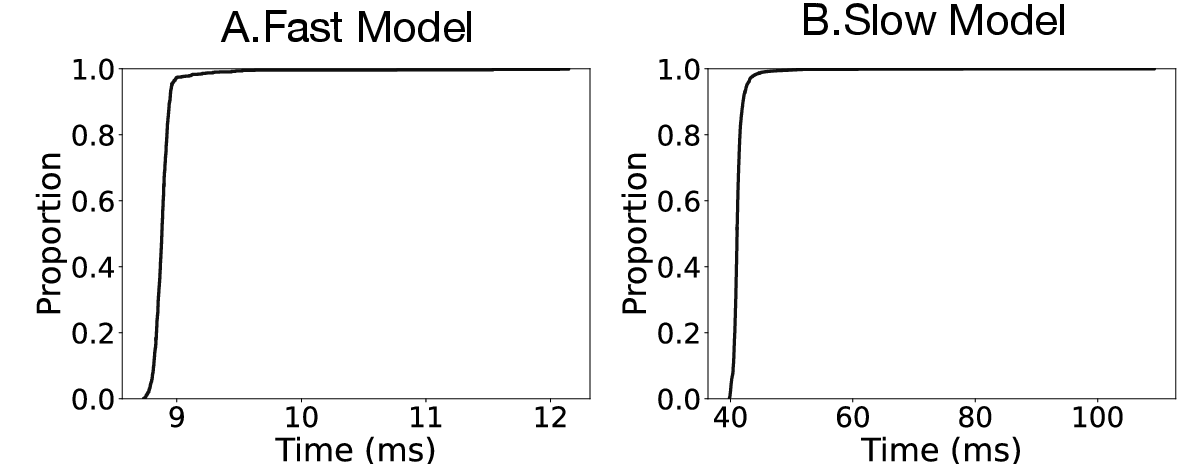
Figure 6: Streaming and embedding model inference time meets real-time constraints for embedded and mobile silicon.
Implications and Future Directions
The method demonstrates that self-speech-anchored, turn-taking-aware neural networks can robustly isolate partners in challenging multi-party, noisy environments using only egocentric audio streams. The system generalizes across languages and speaker counts—despite not being explicitly trained for all cases—by exploiting universals of conversational structure, especially turn-taking.
Practical deployment can improve accessibility for populations with hearing loss, removing the need for manual enrollment and controls. The ability to infer user intent implicitly through conversation participation opens possibilities for seamless, intelligent hearing augmentation. Theoretically, the approach bridges dialogue modeling and source separation, pointing toward future multimodal systems that blend speech understanding, speaker tracking, and conversational modeling for robust human-AI interaction.
Limitations include reduced accuracy during extended silence, high overlap, or culture-specific turn-taking, as well as absence of passive listening support. Mitigation could include integration of content-aware models or cross-modal semantic cues. Transparent, user-centric control mechanisms and further supervised adaptation to the real-world environment are recommended prior to large-scale deployment.
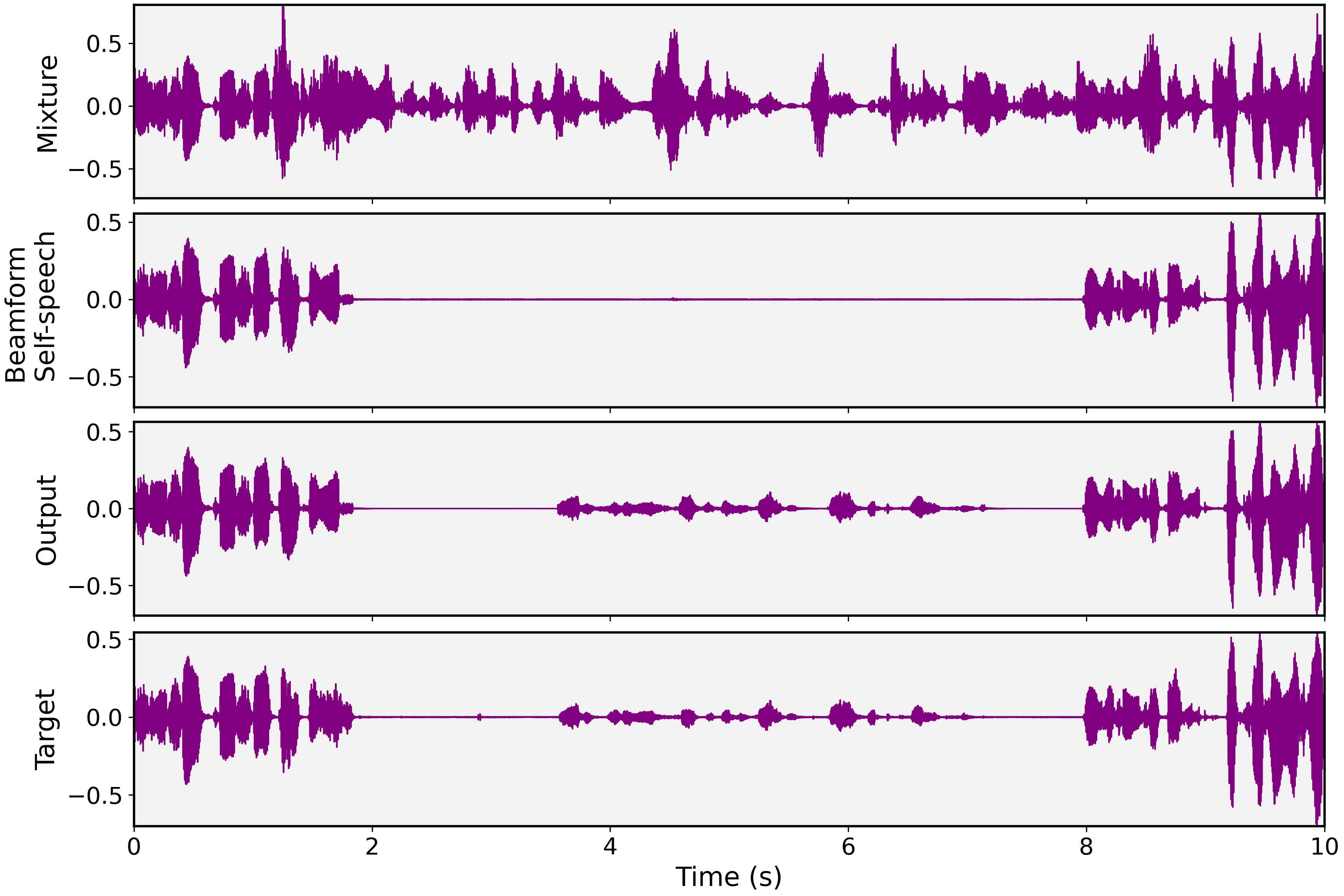
Figure 7: Example waveforms illustrate mixture, extracted self-speech, model output, and groundtruth egocentric conversation for evaluation.
Conclusion
This work establishes a new paradigm for hearing assistance in socially complex contexts, relying on proactive, context-sensitive adaptation rather than manual intervention. By leveraging turn-taking cues and self-speech anchors, the dual-model streaming architecture achieves strong separation and partner identification, even in egocentric, multi-conversation environments. The technique's generalization and efficiency make it feasible for on-device hearing augmentation and inspire future integration with multimodal, dialogue-aware AI systems.