- The paper introduces a hierarchical, sparse discrete flow matching framework that reduces computational overhead while enhancing generative fidelity.
- It employs a novel D-Min coarsening objective and level-wise conditional generation to efficiently produce high-quality graphs.
- Empirical results on molecular, synthetic, and social benchmarks demonstrate significant improvements in speed, sample diversity, and scalability.
Hierarchical Discrete Flow Matching for Graph Generation
Introduction and Motivation
Graph generation frameworks have advanced significantly with diffusion-based and flow-matching approaches, particularly for molecular design, program analysis, and modeling complex relational data. However, these models are constrained by computational bottlenecks: quadratic scaling in node pairs and high numbers of function evaluations (NFE) during generation due to dense modeling and iterative denoising. The paper "Hierarchical Discrete Flow Matching for Graph Generation" (2604.00236) directly addresses these inefficiencies by introducing a hierarchical, sparse, and discrete-generation framework that reduces both computational and memory overhead without sacrificing – and indeed, improving – generative fidelity and sample quality.
Hierarchical Framework and Graph Sparsification
Hierarchical Coarse-Graining
The authors propose a multi-level generative process where the graph is progressively coarsened, then expanded and refined in a top-down manner. Nodes are clustered using a dedicated coarsening algorithm parameterized by a GNN, with assignment matrices defining the partitioning. While previous coarsening strategies, such as edge/neighborhood contraction or community-detection-based clustering (e.g., DiffPool, MinCut), either lack permutation invariance or tend to yield dense coarse graphs, the proposed method explicitly minimizes the density of the expanded graphs. This is central for computational savings.
Spanning Supergraph Density Minimization
A differentiating contribution is the D-Min (Density-Minimizing) clustering objective: the cluster assignment matrix is learned to minimize the density of the induced spanning supergraph after coarse-grain expansion. This process guarantees that downstream refinement (e.g., denoising) operates in sparse graphical domains, with the expanded graphs forming sparse spanning supergraphs over the support graphs of the input data.
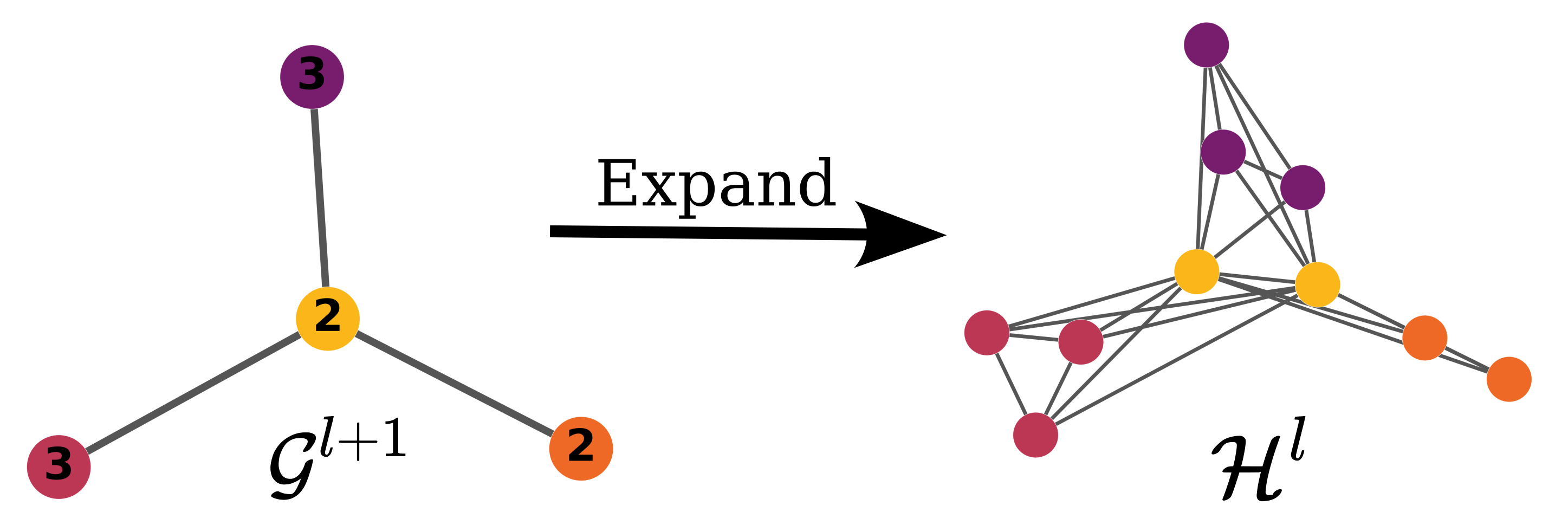
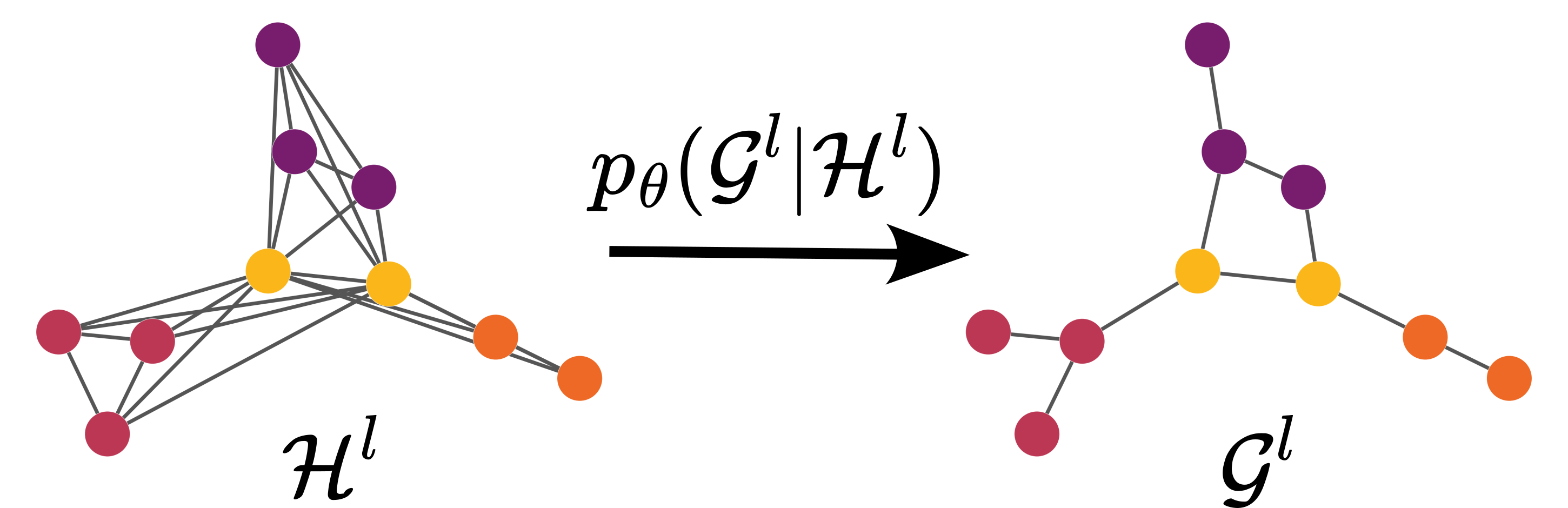
Figure 1: (Top) Deterministic expansion: parents spawn cliques and bicliques; (Bottom) Learned graph refinement prunes extraneous edges.
Discrete Flow Matching: Level-wise Conditional Generation
Discrete Flow Matching (DFM) Generalization
The method leverages the discrete flow matching (DFM) framework, focusing on the variant of [discrete_flow_matching_gat], which is conceptually straightforward and computationally efficient. DFM interpolates between a source distribution (node/edge marginals) and the data distribution along a parameterized time path, with denoising parameterized by a permutation-equivariant sparse GNN. The probability flows are constructed such that updates for each edge/node are independent, but the velocity functions are contextually global, preserving structural dependencies.
Hierarchical Conditional Generation
At each hierarchy level ℓ, the model learns pθ(Gℓ∣Hℓ), where Hℓ is the sparse spanning supergraph determined by the D-Min clustering at the upper level. This structurally constrains the transitions, enabling efficient and high-fidelity inference with a drastically reduced NFE and compute.
By leveraging these sparse conditional supports, unconditional and various conditional generation modes are enabled:
- Canonical generation: Standard top-down expansion and refinement from noise
- Refinement on fixed support: Conditional generation on a real or prescribed spanning supergraph, relevant for graph completion and structure-conditioned synthesis
- Spectral conditioning: Fixing the supergraph induces spectral constraints on generated graphs, enabling specified global structure.
Empirical Results
Synthetic, Molecular, and Large-Scale Real-World Benchmarks
The approach is validated on a diverse suite of graph generation benchmarks:
- Molecular generation (QM9H, ZINC250k): On both atom-annotated and large-molecule datasets, HDFM attains lower Frechet ChemNet Distance (FCD) and NSPDK compared to state-of-the-art (see Tables in paper), with significant acceleration in generation time. Hierarchical DFM allows low-NFE operation without performance drop.
- Synthetic graphs (SBM20k): Introduction of a large-scale Stochastic Block Model dataset demonstrates that HDFM outperforms earlier denoising models in MMD metrics (degree, clustering, spectral) by substantial margins while also providing orders-of-magnitude speedup in sampling.
- Social networks (Ego, Reddit12k): Experiments on large-scale social graphs (up to 1.5K nodes) show that the method achieves high-fidelity generation on both structure and attribute metrics, while baseline methods break down due to quadratic complexity or require excessive NFE for comparably poor performance.
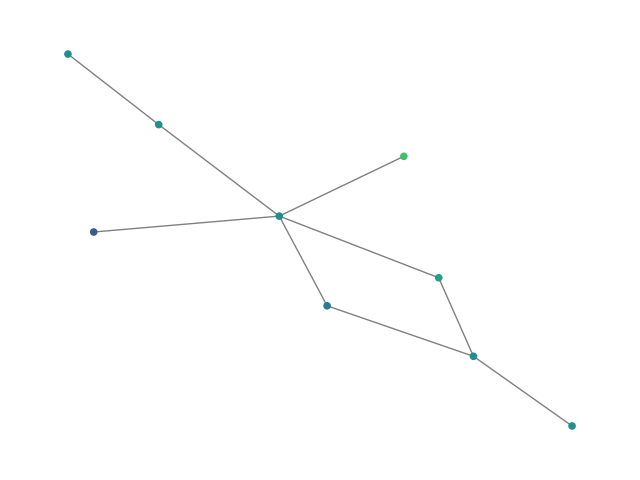
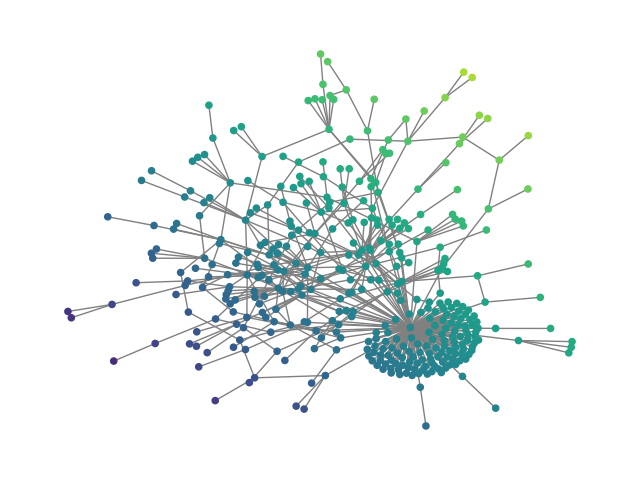
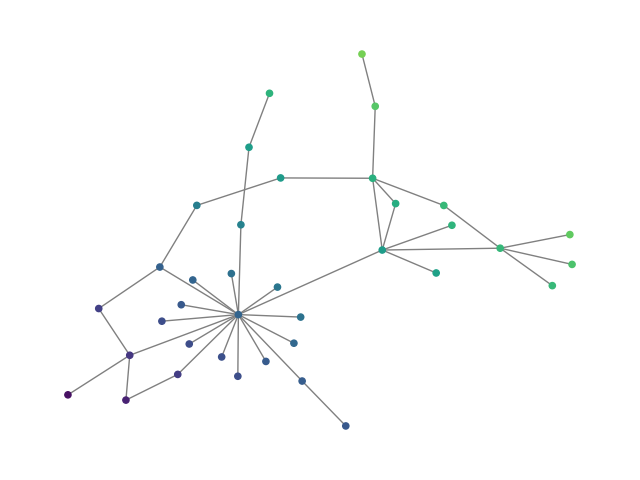
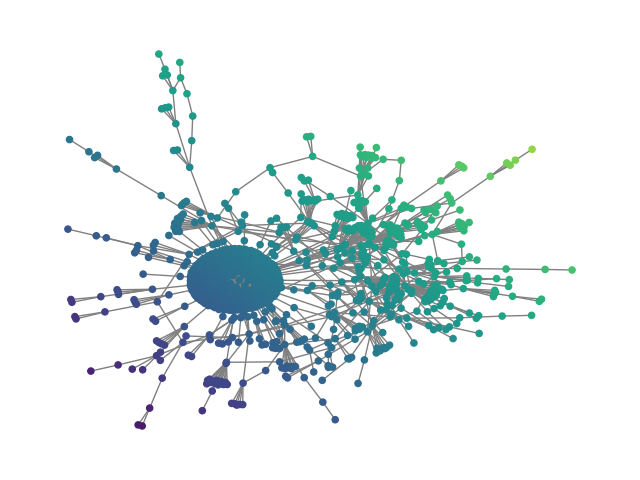
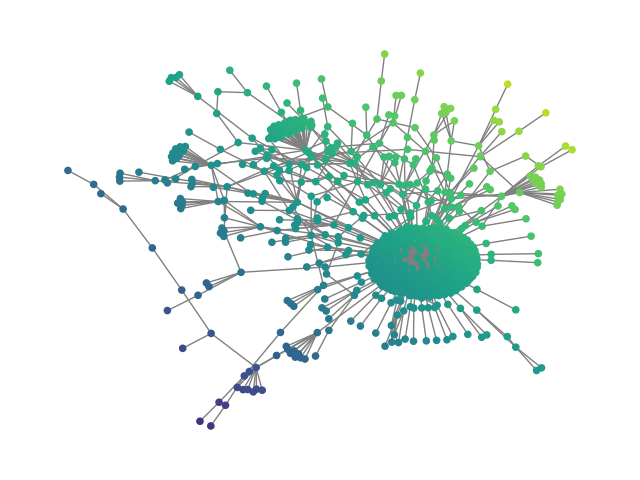


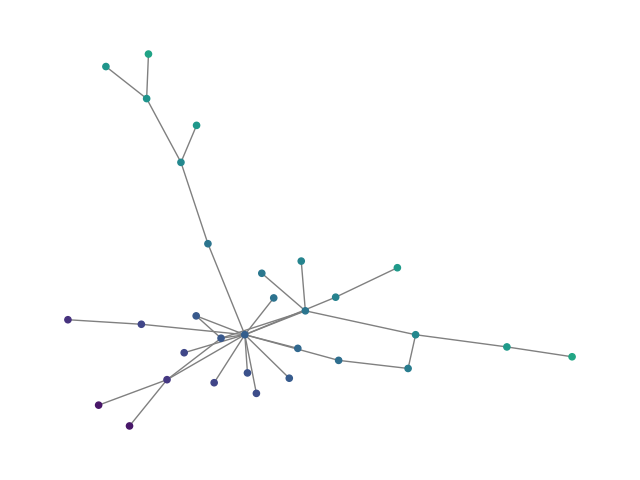

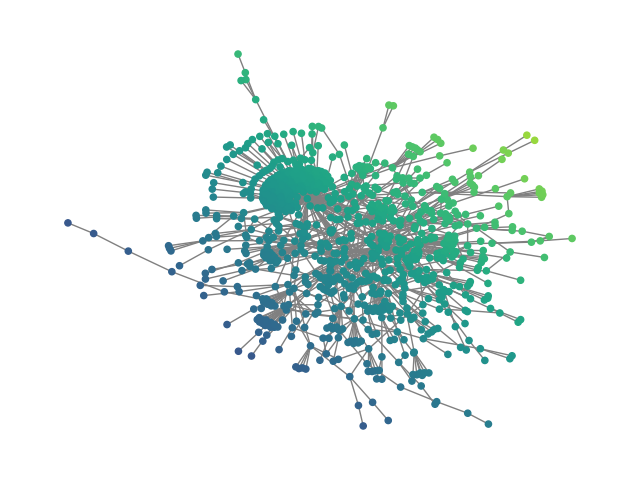
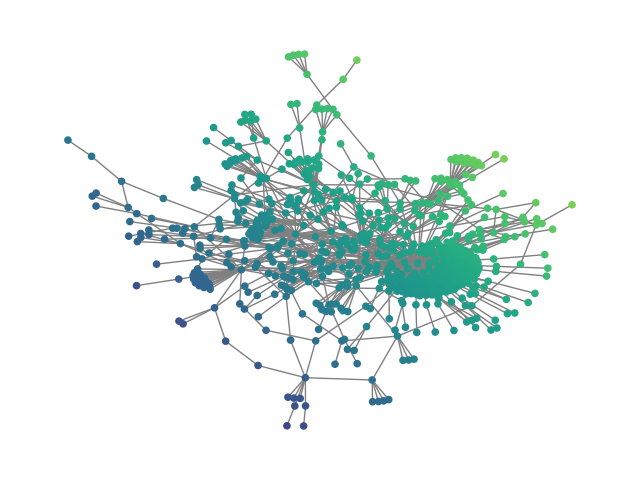
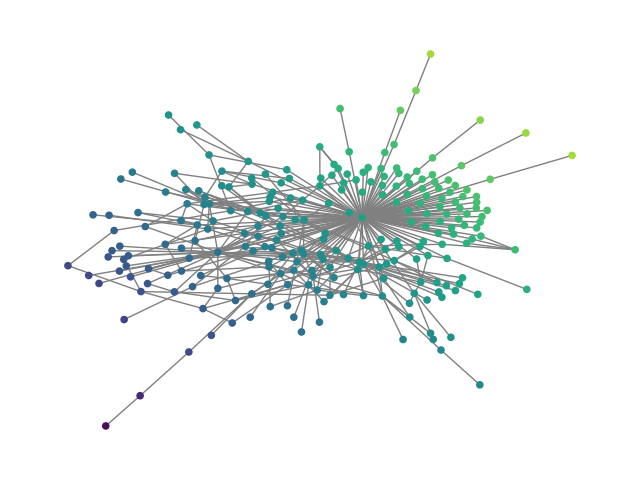
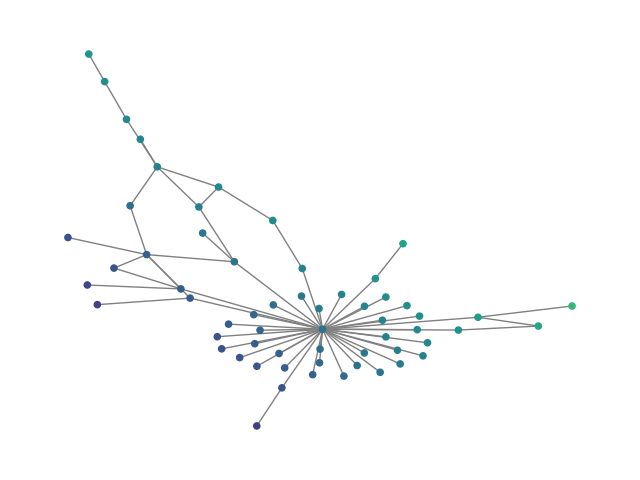
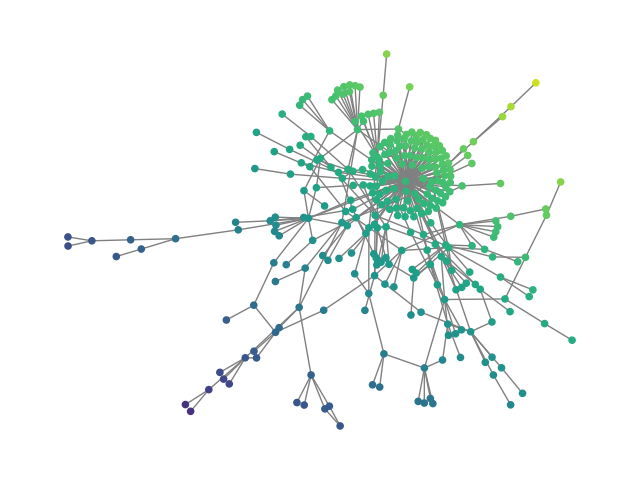
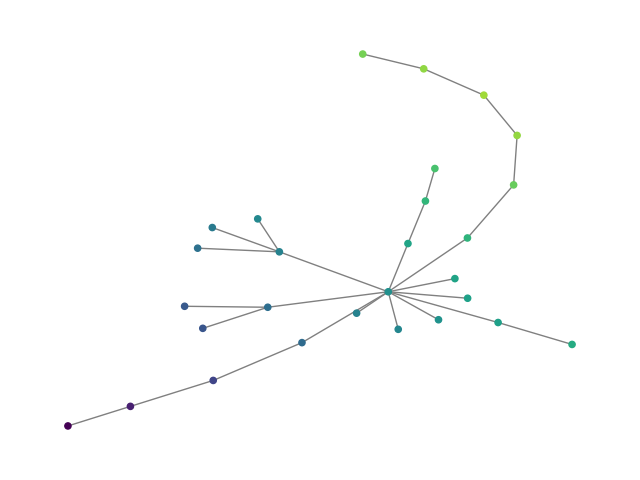


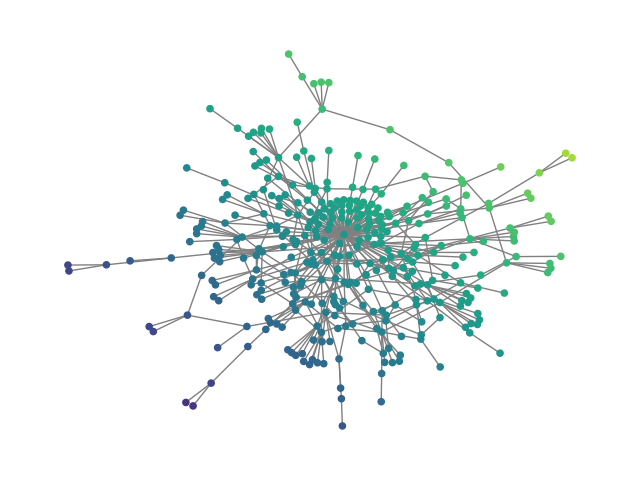



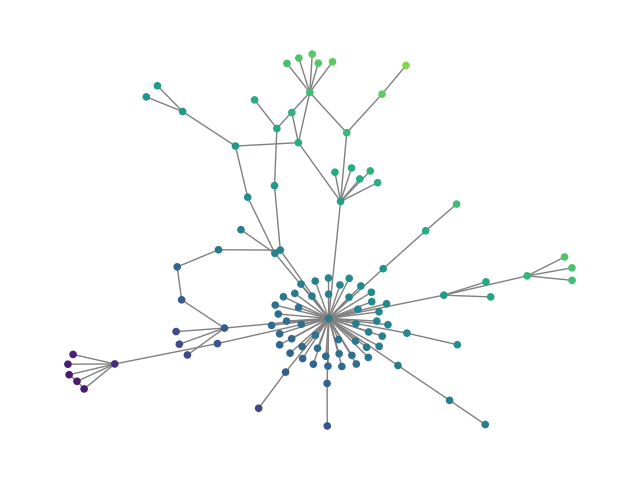
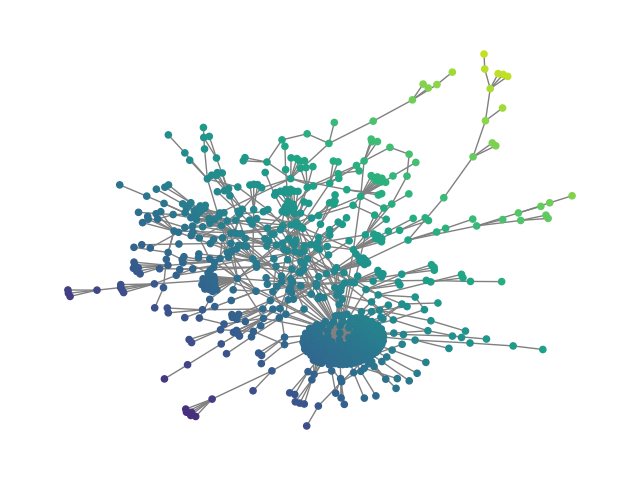

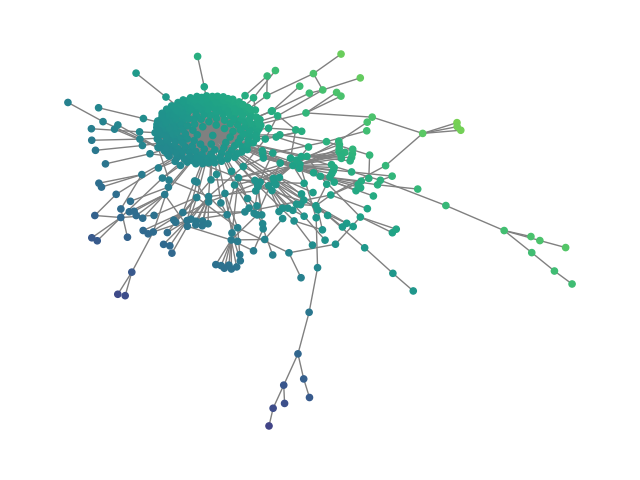

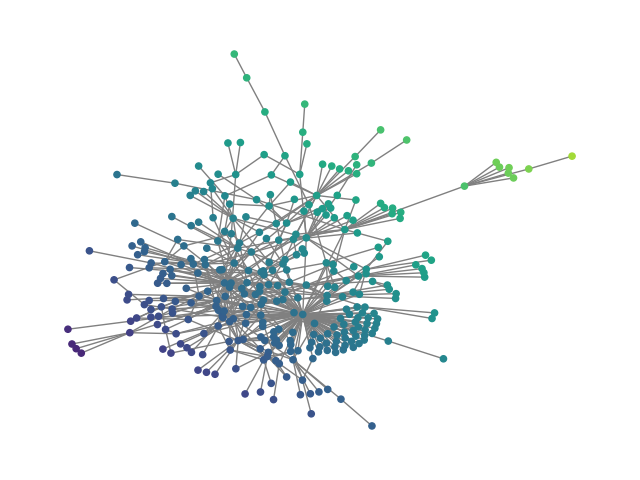

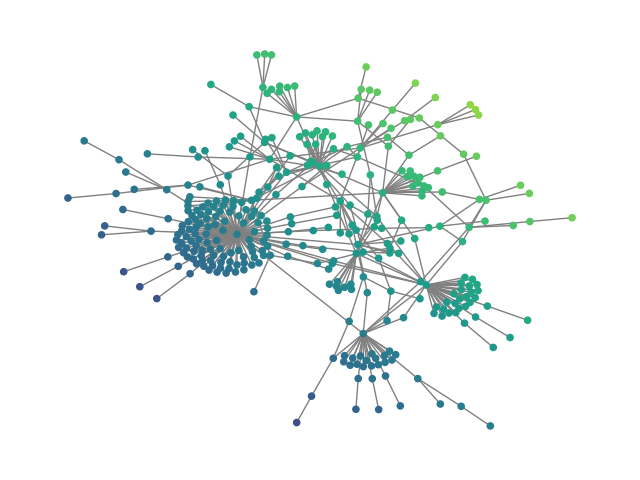
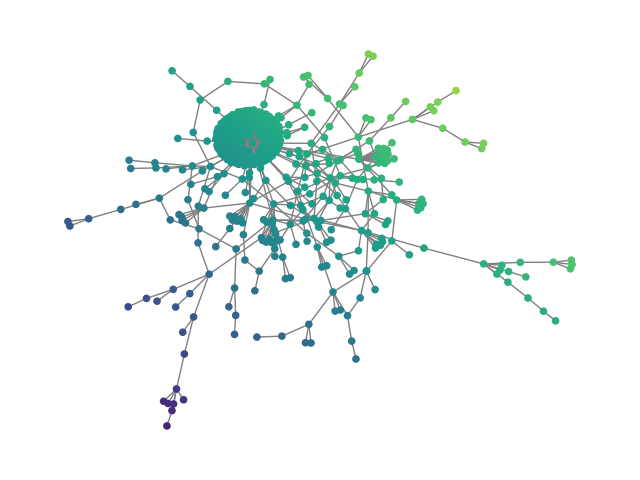
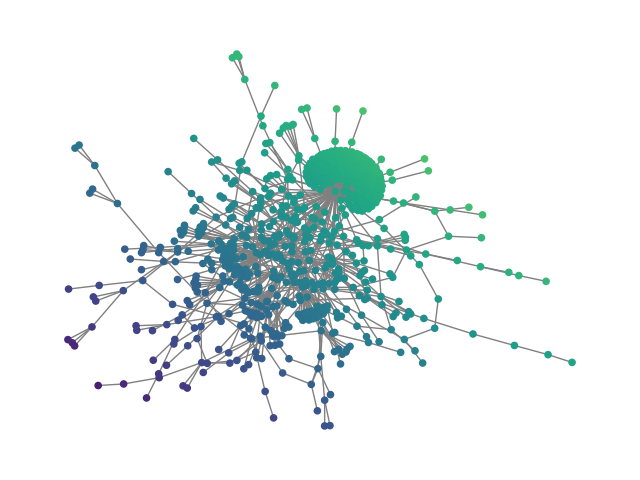


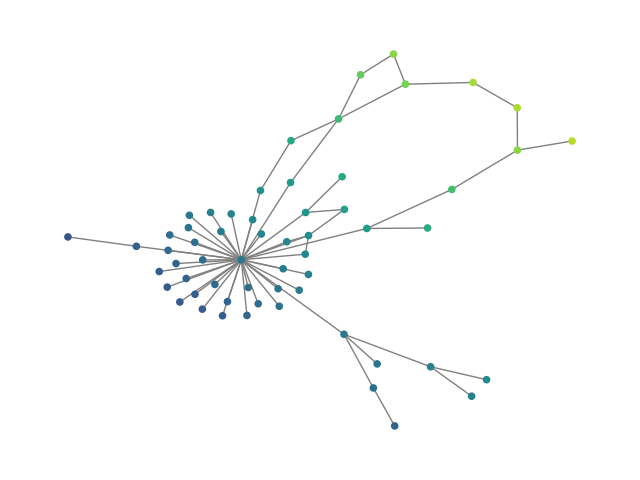

Figure 2: SBM20k: Visual comparison – generated vs dataset graphs, demonstrating structural fidelity with efficient hierarchical generation.
Figure 3: ego: Visual comparison between generated and real social graphs.
Figure 4: reddit: Generated vs reference graphs from large Reddit social network dataset.
Quantitative Analysis
- D-Min effectiveness: The method yields spanning supergraph densities several-fold lower than competing clustering schemes, directly enabling efficiency.
- Hierarchical advantage: On larger graphs (e.g., ZINC250k, SBM20k, Reddit12k), hierarchical DFM provides both better sample quality (lower FCD/NSPDK/MMD) and drastically reduced runtimes.
- Conditioned generation: Conditioning on real or fixed supports allows structure-aware and spectral-regularized synthesis, with generated graphs far closer (by an order of magnitude in spectral distance) to reference structures than randomly sampled test set graphs.
Theoretical and Practical Implications
The hierarchical discrete framework establishes a general paradigm where conditioning on intermediate, sparse, permutation-equivariant supports enables tractable and expressive graph generation. Critically, it obviates the need for dense all-pairs computation, unlocking scalability to nontrivial graph domains relevant in molecular generation, community network synthesis, and potentially program synthesis.
The D-Min coarsening objective also repositions graph pooling and clustering as not merely a regularizer or feature extractor, but as a central lever controlling both tractability and expressivity of generative models.
From a practical standpoint, the findings suggest that with careful architectural design and loss formulation, discrete denoising models can achieve sample quality and diversity competitive with or exceeding dense baselines with orders of magnitude fewer function evaluations and memory usage.
Future Directions
Open directions include:
- Integrating more expressive invariant/equivariant GNNs at each stage for further gains in structure awareness.
- Extending the hierarchical flow-matching framework to other discrete structures beyond graphs (e.g., hypergraphs, program ASTs).
- Incorporating guidance [classifier_free_guidance, discrete_guidance_nisonoff] or structural constraints in hierarchical conditional generation (useful for property-guided molecular or material design).
- Unifying hierarchical generation with continuous-state models for 3D structural data or multimodal synthesis.
Conclusion
Hierarchical Discrete Flow Matching for Graph Generation (2604.00236) introduces a principled framework that links hierarchical clustering–expansion machinery, sparse permutation-equivariant modeling, and discrete flow-matching generative processes. This results in a scalable and expressive approach, yielding strong empirical performance and setting a new standard for large-scale, conditional, and high-fidelity graph generation. The architectural insights and coarsening strategy have significant implications for the design of the next generation of graph generative models.