- The paper presents DRKL, a modified reverse KL objective that decouples target and non-target gradients to improve calibration and output diversity.
- It demonstrates that DRKL outperforms traditional RKL and FKL objectives, yielding higher fidelity scores and enhanced diversity in distilled large language models.
- Empirical evaluations show DRKL achieves over a 2-point improvement in ROUGE-L scores along with reduced overconfidence across various instruction-following benchmarks.
Diversity-Aware Reverse Kullback-Leibler Divergence for LLM Distillation
The paper "Diversity-Aware Reverse Kullback-Leibler Divergence for LLM Distillation" (2604.00223) addresses the loss landscape and learning dynamics of knowledge distillation (KD) for LLMs, focusing specifically on the use of forward KL (FKL) versus reverse KL (RKL) divergence as a distillation objective. While RKL has empirically surpassed FKL, especially in high-vocabulary and significant teacher-student capacity mismatch regimes, the authors provide a theoretical and empirical analysis revealing structural shortcomings in RKL—namely its persistent drive for overconfident, low-diversity predictions and poor long-tail alignment.
Structural Differences Between FKL and RKL in LLM Distillation
The fundamental difference is that FKL enforces dense matching between student and teacher across the entire output space, which is infeasible for small students in the LLM regime due to heavy-tailed output distributions. Conversely, RKL focuses mainly on the dominant teacher modes, ignoring the non-target, low-probability tokens. This is demonstrated via gradient analysis: FKL provides uniform supervision, while RKL's update is suppressed for non-targets, aligning only with the portion of the distribution the student already believes is important. This mode-seeking property enables faster convergence and better alignment in limited-capacity students, as illustrated in
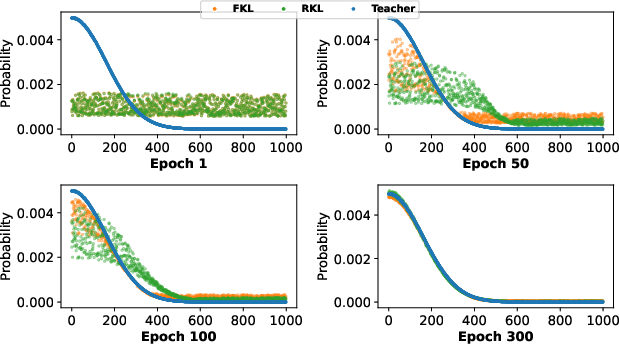
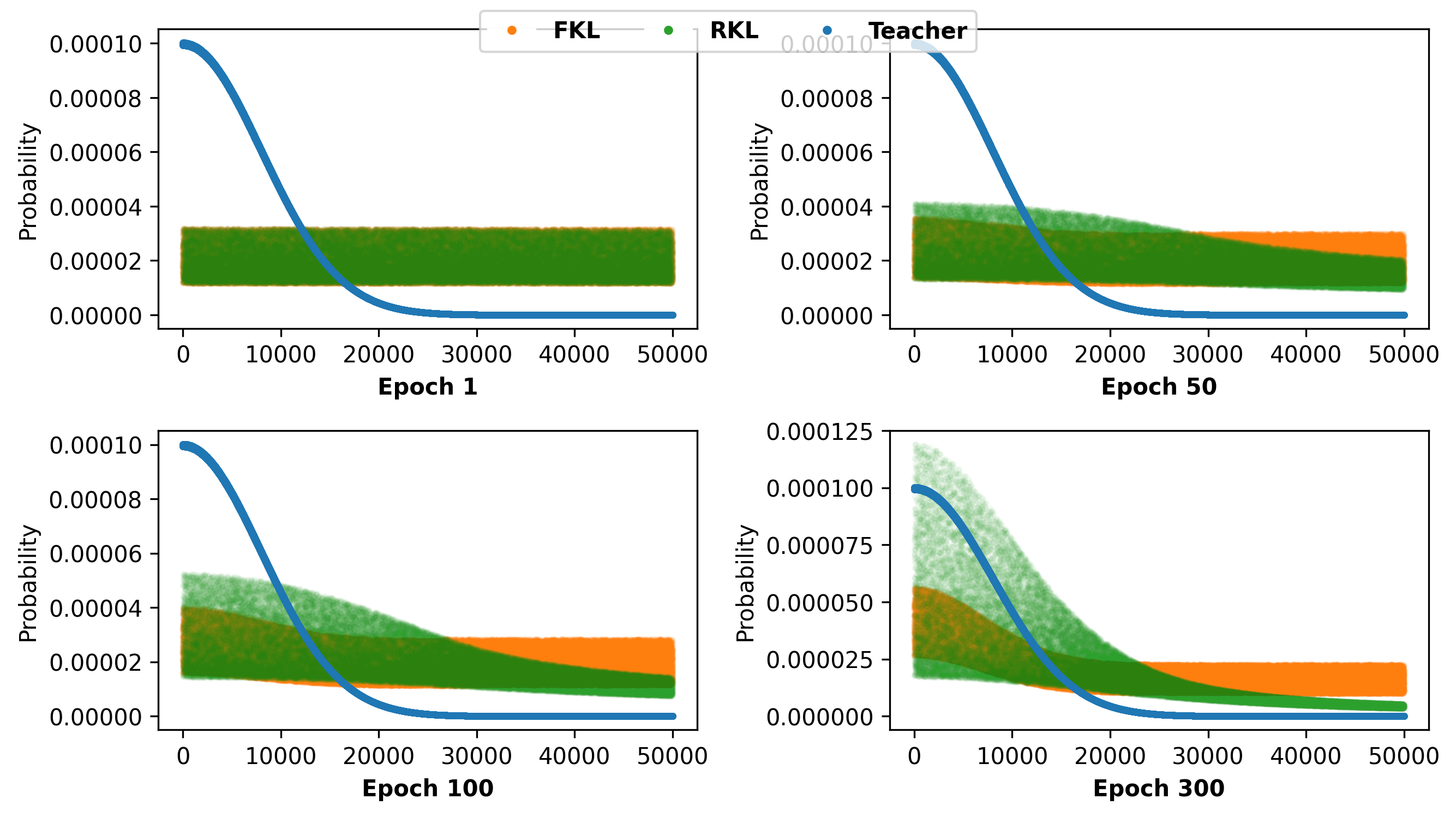
Figure 1: FKL versus RKL learning dynamics in differing output space sizes, showing faster RKL convergence in the large-vocabulary setting.
Gradient Decomposition: Target and Non-Target Effects
A novel gradient decomposition for RKL within large-vocab LLMs is presented. The decomposition reveals that non-target gradients (from low-probability classes) systematically push up the target logit, even when the student already matches the teacher on the target class. This mechanism amplifies output confidence beyond the teacher's, resulting in reduced response diversity and calibration errors. Furthermore, RKL provides only weak supervision on non-target (tail) class alignment.
Diversity-Aware RKL (DRKL): Objective and Theoretical Properties
To mitigate these issues, the authors introduce DRKL, a modified reverse KL objective. DRKL directly removes the gradient pathway from non-target losses to the target logit by reweighting the non-target term with a fixed hyperparameter γ, thereby decoupling target and non-target gradients. This enforces regularization on the "tail" (non-target) classes without allowing non-target mismatch to propagate overconfidence in the target logit. Theoretical results validate that DRKL preserves the efficient optimization structure of RKL while providing strictly better alignment and calibration.
Experimental Evaluation
Extensive experiments are conducted on LLM instruction-following tasks, spanning multiple teacher-student pairs across GPT-2 and OPT families (up to a 6.7B-to-1.3B distillation). Students are trained with DRKL and a diversity of strong baselines, including FKL, RKL, various bidirectional and symmetric KL designs, Jensen-Shannon divergence, decoupled KD variants, and recently proposed skewed/interpolated KL metrics. Evaluation employs both fidelity (ROUGE-L) and output diversity metrics (Distinct-2, Negative Self-BLEU).
Empirically, DRKL consistently outperforms all baselines across a range of benchmarks and student architectures, reporting the top scores in ROUGE-L on all main evaluation sets. In detailed ablations, the method shows consistently superior calibration, significantly reduced overconfidence, and improved diversity as measured by diversity metrics. Notably, it surpasses RKL by over 2 points on the Super-NI and UnNI benchmarks with a comparable computational budget.
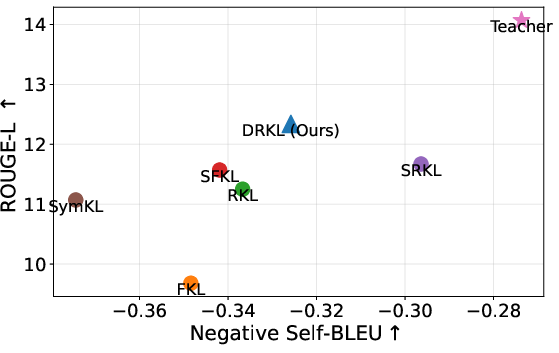
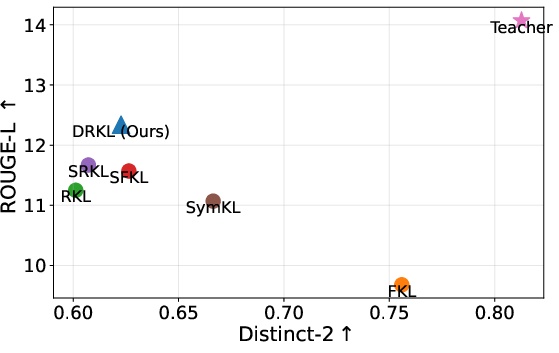
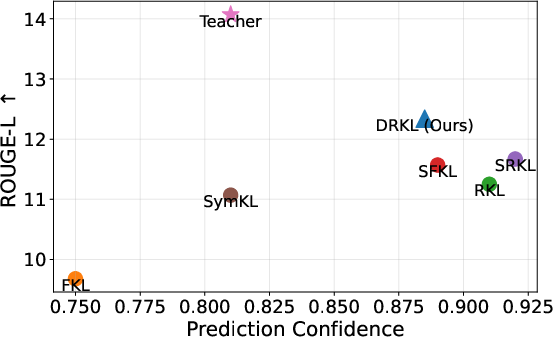
Figure 2: Trade-off between fidelity and output diversity: DRKL balances high ROUGE-L score with improved diversity compared to RKL and FKL.
These improvements are achieved without significant sensitivity to the hyperparameter γ and with minimal per-step training cost increase. Qualitative case studies on instruction-following demonstrate that DRKL-trained models produce more instruction-faithful and semantically correct responses compared to overfit or degenerate outputs commonly produced by vanilla RKL or FKL.
Practical and Theoretical Implications
The results indicate that RKL's presumed dominance in LLM distillation is only partial, and its overconfidence and diversity collapse effects are ubiquitous under realistic capacity constraints. DRKL establishes that it is possible to decouple the benefits of rapid mode alignment (due to RKL) from the drawbacks of under-regularized output tails.
From an application perspective, the improved fidelity-diversity trade-off enhances instruction-following, robustness, and the generalization characteristics of distilled LLMs. Architecturally, the simplicity of DRKL makes it composable with other RKL-based strategies, suggesting that further improvements may be obtained by integrating DRKL into broader LLM distillation toolkits and curriculum designs.
Future Directions
Subsequent work could focus on extending DRKL to online distillation, RL fine-tuning, or hybrid objectives that directly measure user-preferred behavior. There is also scope for formalizing the impact of diversity regularization on downstream tasks such as question answering, summarization, and dialog generation, as well as applying the DRKL mechanism to other structured prediction domains with large output spaces (e.g., vision, combinatorial generation).
Conclusion
This paper provides a rigorous theoretical and empirical foundation for the limitations of RKL as a distillation objective in LLMs, and presents DRKL as an effective, simple, and scalable alternative that achieves superior performance and calibration, balancing fidelity and diversity. The findings refine the understanding of loss design in LLM distillation and will inform future development of compact, robust, and diverse LLMs.