Tucker Attention: A generalization of approximate attention mechanisms
Published 31 Mar 2026 in cs.LG and cs.AI | (2603.30033v1)
Abstract: The pursuit of reducing the memory footprint of the self-attention mechanism in multi-headed self attention (MHA) spawned a rich portfolio of methods, e.g., group-query attention (GQA) and multi-head latent attention (MLA). The methods leverage specialized low-rank factorizations across embedding dimensions or attention heads. From the point of view of classical low-rank approximation, these methods are unconventional and raise questions of which objects they really approximate and how to interpret the low-rank behavior of the resulting representations. To answer these questions, this work proposes a generalized view on the weight objects in the self-attention layer and a factorization strategy, which allows us to construct a parameter efficient scheme, called Tucker Attention. Tucker Attention requires an order of magnitude fewer parameters for comparable validation metrics, compared to GQA and MLA, as evaluated in LLM and ViT test cases. Additionally, Tucker Attention~encompasses GQA, MLA, MHA as special cases and is fully compatible with flash-attention and rotary position embeddings (RoPE). This generalization strategy yields insights of the actual ranks achieved by MHA, GQA, and MLA, and further enables simplifications for MLA.
The paper introduces Tucker Attention, which unifies various attention mechanisms by applying a tensor-based Tucker decomposition for efficient compression.
It achieves competitive performance on vision and language models with significantly fewer parameters and reduced KV cache compared to standard methods.
The method integrates with flash-attention, RoPE, and existing transformer infrastructures, enabling faster inference and lower memory usage.
Tucker Attention: A Unified and Parameter-Efficient Framework for Self-Attention
Overview
The paper "Tucker Attention: A generalization of approximate attention mechanisms" (2603.30033) presents a comprehensive tensor-based formalism for attention weights in transformer architectures. It introduces Tucker Attention, a multi-modal low-rank factorization, which subsumes prominent strategies such as Multi-Head Attention (MHA), Grouped Query Attention (GQA), Multi-Head Latent Attention (MLA), and Multi-Query Attention (MQA) as special cases. This parametrization enables direct compression along the head, query, key, value, and output modes, leading to strong empirical results: Tucker Attention achieves comparable accuracy to established methods with an order of magnitude reduction in attention parameters and KV cache requirements. The method is compatible with flash-attention, rotary position embeddings (RoPE), and standard transformer infrastructures.
Tensorial Reinterpretation of Attention
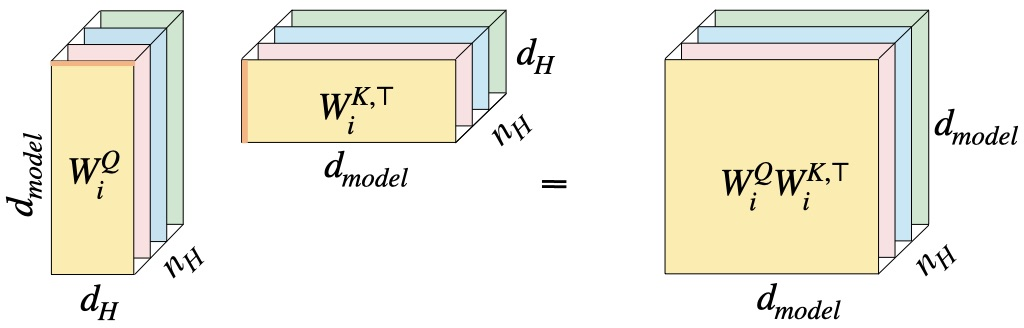
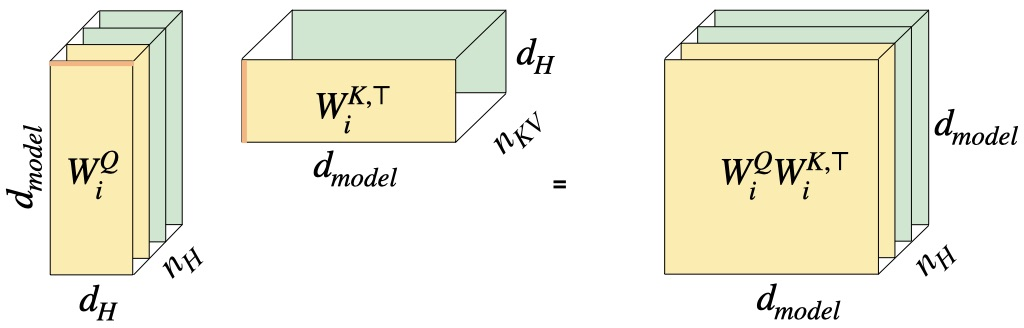
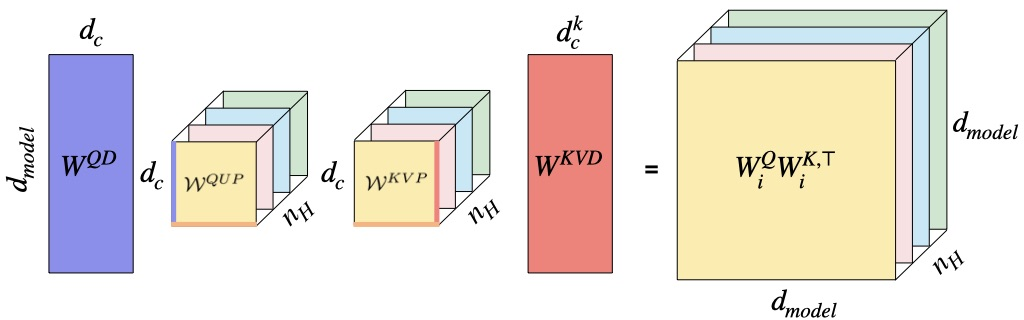
The standard MHA mechanism employs individual projection matrices for each head and modality (query, key, value, and output), resulting in redundancy and high parameter counts. By stacking the per-head key, query, value, and output matrices into higher-order tensors, the authors define the pre-softmax and post-softmax attention weights as order-3 tensors:
W (pre-softmax): Heads × Queries × Keys
W (post-softmax): Heads × Outputs × Values
This enables explicit control over the tensor ranks along each mode (especially head, query/key, and output/value), providing an interpretable view on redundancy and sharing across typical transformer layers. Crucially, MHA, GQA, MQA, and MLA all correspond to fixed, highly redundant choices of these tensor ranks.
Figure 1: Schematic depiction of various attention factorizations. Only Tucker Attention enables head-mode compression, exposing previously inaccessible parameter reduction.
Tucker Decomposition in Attention: Methodology
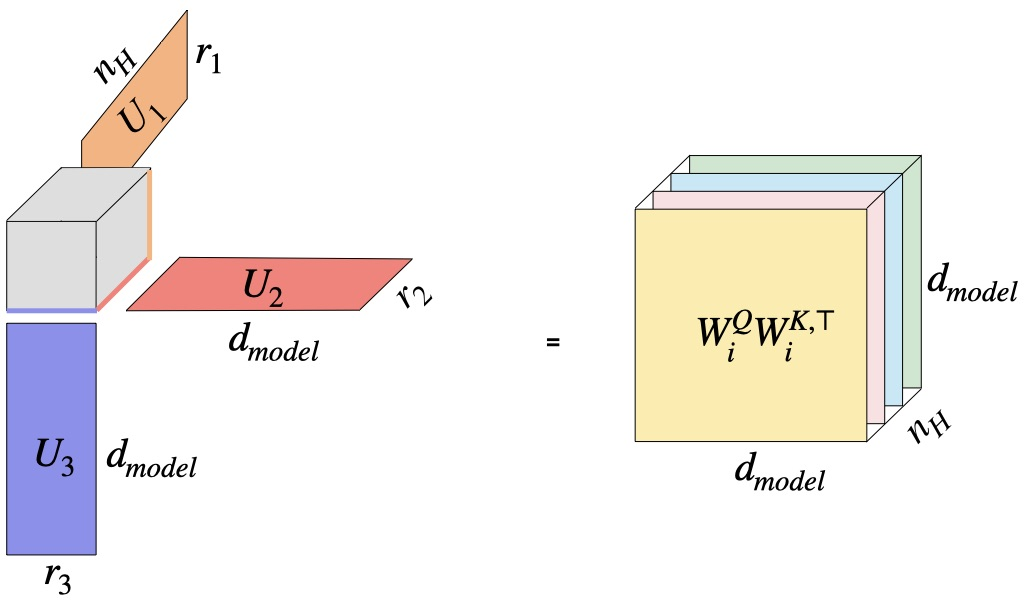
Tucker Attention leverages the Tucker decomposition, a generalization of matrix SVD to higher-order tensors. For a 3-way tensor W, the decomposition is
W=C×1U1×2U2×3U3,
where C is the core tensor and Uj are mode matrices controlling basis compression for heads, queries/outputs, and keys/values, respectively.
This formulation allows independent selection of compression ranks along each axis. Unlike GQA/MLA, which leave the head or output modes full-rank, Tucker Attention can compress these as well, yielding principled parameter reduction. The capacity to directly compress in the head mode is not accessible in prior approaches.
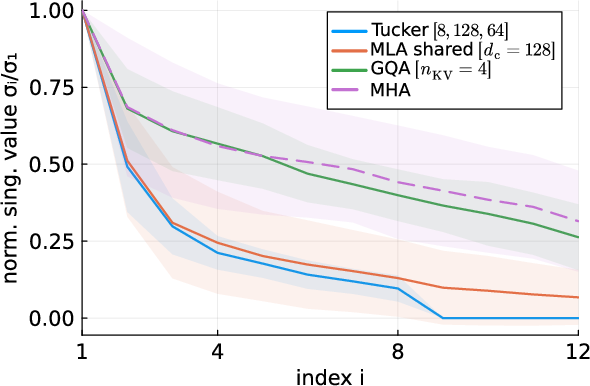
Figure 2: Normalized singular spectrum of the pre-softmax head mode $\Mat_1(\mathcal{W})$. Strong decay demonstrates empirical low-rank structure available in the head mode.
Special Cases and Interpretability
MHA, MQA, GQA, and MLA are all realized as special cases of Tucker Attention with particular choices of the ranks and the basis matrices. For instance:
MHA: Full rank in all modes; no compression.
GQA/MQA: Key and value modes compressed by grouping, head mode full.
MLA: Query/key modes compressed using low-rank projections; head/output modes left full.
Tucker: All modes can be efficiently compressed, as justified by singular spectrum analysis on trained models.
This connection clarifies how apparent gains or deficiencies in smaller methods (e.g., insufficient head-wise compression in MLA) are a consequence of their rigid design choices.
Compatibility and Practicality
KV Caching and Memory Efficiency
Tucker Attention permits efficient KV caching via shared key/value projections, akin to the lowest-memory setups in MLA and GQA, with a tunable tradeoff between cache size and accuracy via the latent rank parameter.
Rotary Position Embeddings (RoPE)
A key technical result is the latent RoPE construction: RoPE can be shifted from the head dimension (as in MHA) to the low-dimensional latent space introduced by Tucker. This preserves the relative position property critical to Transformer performance and enables simple, fused weight implementations. The method further simplifies MLA’s use of position encoding, unifying previously divergent practices.
Empirical Results
Vision Transformers
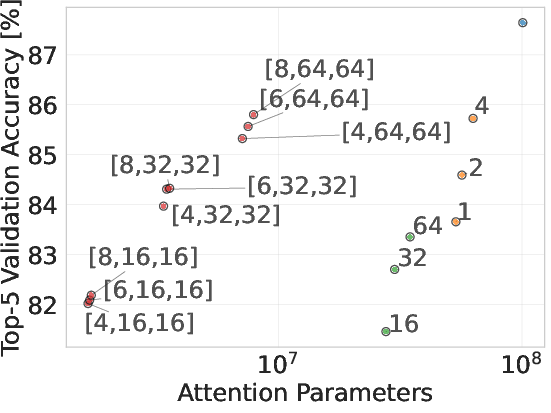
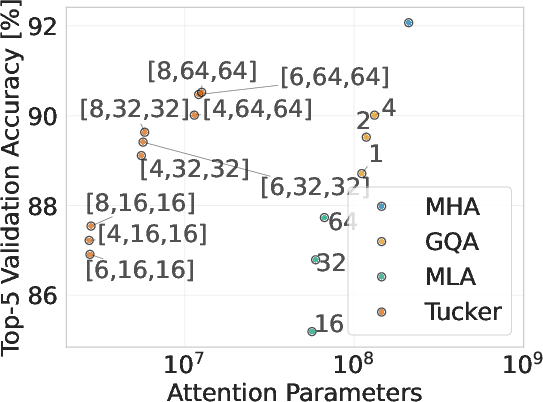
On transfer-learning tasks using Vision Transformers (ViT32l, ViT14g), Tucker Attention reaches top-5 validation accuracy on ImageNet1k on par with MHA and MLA, using nearly an order of magnitude fewer attention parameters.
Figure 3: ViT32l top-5 ImageNet1k validation accuracy for MHA, GQA, MLA, and Tucker Attention as a function of parameter count. Tucker establishes a new pareto frontier.
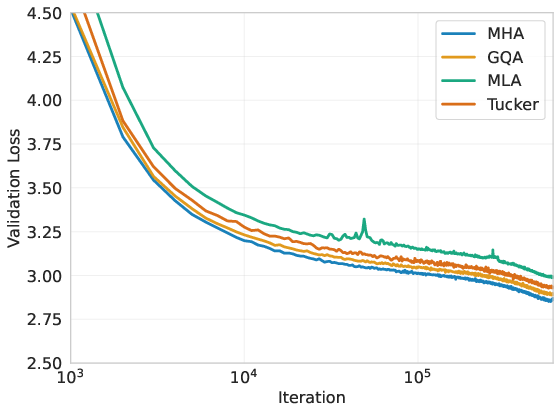
LLMs: GPT2 and LLaMA3-1B
On GPT2 and LLaMA3-1B trained from scratch, Tucker Attention matches or surpasses validation cross-entropy and perplexity scores of all baselines at a fraction of attention layer parameters and KV cache. For example, in the OpenWebText2 benchmark on LLaMA3-1B, Tucker Attention with $32$ head and $64$ latent ranks yields similar validation loss and a 8–20× reduction in parameter and cache counts compared to MHA or standard GQA.
Figure 4: Validation cross-entropy for GPT2 on OpenWebText without RoPE. Tucker Attention achieves competitive convergence with significantly fewer parameters.
Training and Inference Efficiency
Wall-clock measurements confirm that Tucker Attention reduces training iteration time and decoding latency due to lower memory pressure and more efficient cache utilization, while requiring no modifications to established flash-attention kernels.
Theoretical and Practical Implications
Theoretical: This work establishes a unifying tensor framework for accurate, memory-efficient attention. The analysis demonstrates that canonical methods are predicated on unexplored redundancies, and optimal parameter reduction is achievable by targeting all modes in the tensor structure.
Practical: Tucker Attention seamlessly integrates with major transformer optimizations (flash-attention, RoPE, KV caching) and can be deployed in existing codebases. The ability to explicitly select compression ranks along all modes facilitates targeted trade-offs between accuracy, memory, and speed, which is instrumental for large-scale pretraining and deployment of LLMs and ViTs.
Future Directions
Potential developments of this work include:
Data-driven or adaptive selection of Tucker ranks per layer, possibly dynamic during training.
Investigation of custom GPU kernels exploiting direct factorized core computation for further speed-up.
Extending the Tucker formalism to cross-attention and decoder-only settings, and its interaction with mixture-of-experts routing.
By reframing attention weights as order-3 tensors and employing Tucker decomposition, the authors provide a unified, interpretable, and highly parameter-efficient family of attention mechanisms. Tucker Attention enables compression in modes that were previously overlooked and empirically achieves comparable performance to full-rank methods with dramatic parameter savings. This approach not only clarifies the structure of attention mechanisms but also sets a new standard for efficient foundation model training and inference.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.