- The paper demonstrates that targeted, context-specific speech timing adjustments using reverse-correlation derived kernels covertly enhance intelligibility for non-native and challenged listeners.
- By applying precise rate modifications around critical vowels, the approach achieves recognition improvements of 20–30% over global slow-down methods.
- Integration into a modified TTS system reduces word error rate by over 50%, highlighting a clear dissociation between human and ASR strategies.
Covert Speech Timing Adaptation for Intelligibility Gains: Data-Driven Insights from Reverse Correlation and TTS
Introduction
This paper introduces a methodology and series of experiments to systematically determine how targeted, data-driven adaptations of speech timing can covertly improve speech intelligibility for non-native (L2) and challenged listeners. Contrary to the common practice of global speech slowing, the work demonstrates that intelligibility benefits most from precise, context-dependent rate adjustments—especially around critical vowels—rather than from uniform deceleration.
Key to this approach is the application of reverse-correlation techniques to extract optimal prosodic timing kernels, its cross-linguistic validation, followed by integration into a controllable text-to-speech (TTS) framework. This pipeline allows for causally testing the consequences of temporal manipulations on both human and machine comprehension across varied listener populations and environmental conditions.
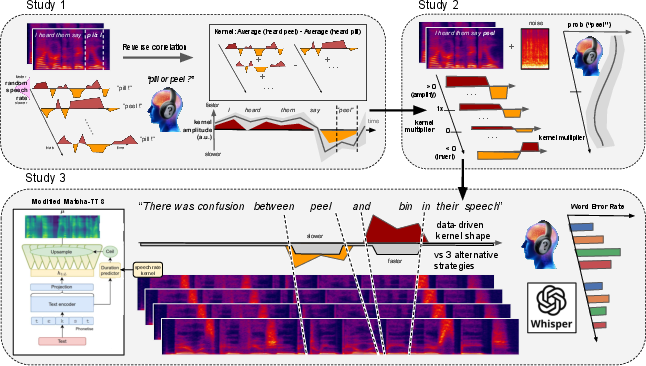
Figure 1: A data-driven algorithm to manipulate speech rate in clear speech, outlining extraction of contextual timing kernels and their integration into a generative speech synthesis system.
Temporal Structure of Rate Intake: Reverse Correlation Analysis
The first major experimental contribution is the quantification of how temporal context in the lead-up to target vowel contrasts modulates phoneme identification. Across a diverse sample of L1 and L2 listeners (French, English, Mandarin, Japanese), reverse-correlation on judgment of ambiguous speech samples revealed a robust, cross-linguistically stable "scissor-shaped" kernel. This kernel consists of two principal effects:
- Distal Contrastive Effect: Slower speech 800–300 ms before the target biases listeners toward identifying the subsequent vowel as the phonetically "faster" option.
- Proximal Congruent Effect: Slower speech immediately before (100–200 ms) the target yields perception favoring the "slower" vowel alternative.
This pattern is reliably observed across both isolated words and full sentence contexts, regardless of listeners' native language or their L2 experience. Notably, these context-timing influences are present even in L2 populations not accustomed to using duration as a primary phonemic cue.
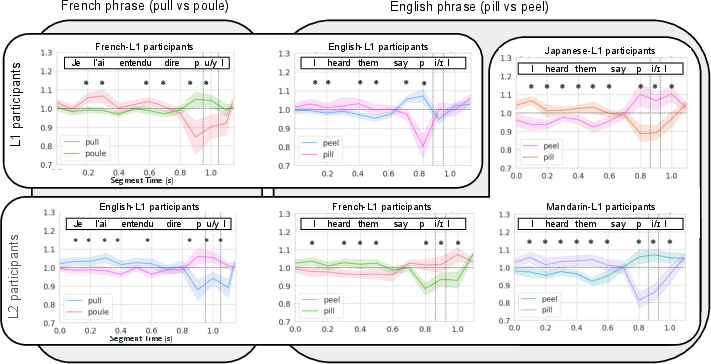
Figure 2: The temporal contour of rate information intake in leading phrasal contexts is consistent across individuals and languages.
Functional Implications: Speech-Rate Structure and Word Recognition
Having established the kernel, subsequent studies systematically applied these "scissor" manipulations to critical regions of sentences containing challenging tense-lax vowel minimal pairs. In multi-group forced-choice recognition tasks, L2 listeners (French, Mandarin, Japanese) exhibited significant, often dramatic, swings in recognition accuracy—on the order of 20–30% absolute—contingent on the application of contextually correct rate contours. The effect magnitude was sufficient to close or reverse much of the typical L1–L2 performance gap under baseline conditions.
Native (L1) English listeners, by contrast, generally did not rely on rate manipulations when spectral cues were unambiguous and noise-free; however, under challenging acoustic conditions (reverberation, noise, ambiguous synthesis), their performance was similarly contingent on contextual timing, indicating a flexible, cue-weighting system that is invoked only when primary cues become unreliable.
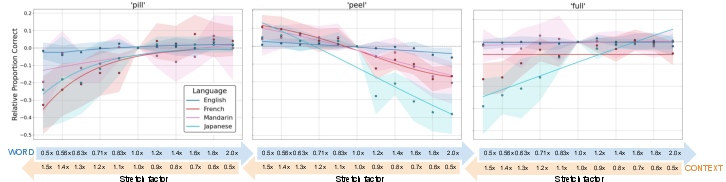
Figure 3: Speech-rate scissor structures strongly modulate word recognition in L2 English listeners but not in L1 listeners under clear conditions.
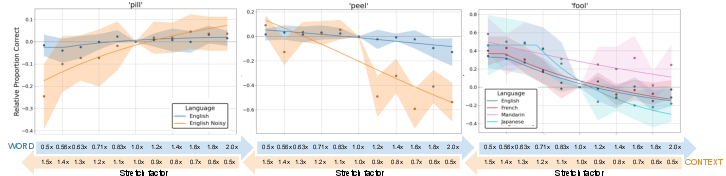
Figure 4: Native listeners utilize speech rate as an auxiliary strategy only when adverse acoustic conditions mask primary spectral cues.
Data-Driven Speech Synthesis: Integration and Causal Testing
Drawing on the computational extraction of contextual timing kernels, the methodology is implemented in a modified MatchaTTS model. The TTS system automatically parses text, identifies target minimal pairs, and applies the optimized temporal stretching solely to proximal regions of tense vowels. Compared to controls (baseline TTS, global slow-down, or naive target stretching), this targeted algorithm achieves substantial reductions in word error rate (WER)—over 50% decrease relative to baseline for difficult vowels—demonstrably outperforming human-like clear speech strategies that slow speech globally.
Interestingly, listeners remain largely unaware of these intelligibility improvements brought by targeted timing adaptation. Subjective judgments indicate a bias toward perceiving globally slowed speech as more intelligible, despite objective error rates being higher for such utterances. This disconnect highlights the covert nature of the optimized timing strategy's benefit.
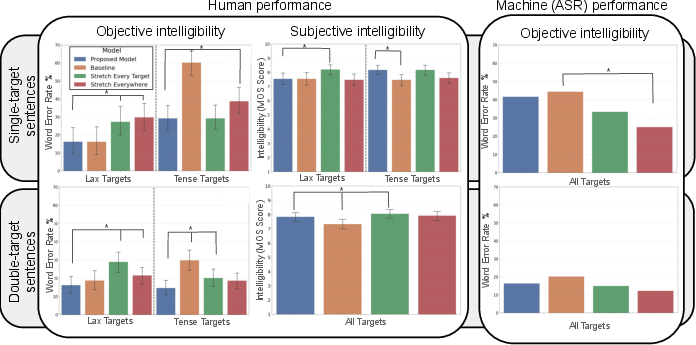
Figure 5: Targeted speech-rate manipulations enhance machine speech comprehension for L2 listeners, even though listeners do not consciously attribute benefit to such changes.
Dissociation between Human and ASR Intelligibility Gains
Evaluation with state-of-the-art automatic speech recognition (ASR) systems (Whisper) reveals divergent sensitivity to rate manipulations—global slowing improves ASR performance, while the human-optimized "scissor" model has negligible or even adverse effects on WER. This showcases a clear dissociation between strategies that maximize human and machine intelligibility, indicating that neural ASR architectures do not exploit duration cues in the same manner as human listeners.
Implications and Future Prospects
The findings concretize the causal, time-resolved influence of acoustic context on speech perception, and demonstrate that directly manipulating this structure within TTS frameworks can yield substantial, context-dependent gains in intelligibility for L2 and challenged listeners, without listeners' explicit awareness. This provides not only empirical evidence for cue integration and cue weighting theories in auditory perception but also sets forth a paradigm for "algorithmic theories" of intelligibility that are implementable in production systems.
Practically, the results advocate for deploying contextually targeted timing adaptations in speech technology aimed at accessibility for L2 speakers, environments with high noise or reverberation, or for populations with perceptual or cognitive impairments. The experimental pipeline also provides a framework for evaluating and closing performance-competence gaps between humans and ASR, guiding development of next-generation systems that incorporate human-like temporal context integration.
Further research is warranted on generalizing the approach to other phonetically challenging contrasts, broader listener populations (e.g., young, older adults, clinical), and exploring how ASR architectures might be modified or trained to leverage context timing in more human-like ways.
Conclusion
The data-driven extraction and implementation of temporal speech rate structure proves to be a powerful, covert mechanism for improving intelligibility in TTS—principally benefitting non-native and challenged listeners and outperforming traditional speaker adaptation strategies. Though listeners are subjectively unaware of the benefit, the methodology sets a new standard for adaptive, ecologically valid speech synthesis. This work also highlights fundamental differences in temporal cue exploitation between human and machine perception, and paves the way for principled, listener-adaptive speech technologies.