- The paper introduces a dual-capability bottleneck in searchless chess Transformers, showing that performance is limited by the weaker of implicit tracking or move selection.
- An Elo-weighted training scheme is proposed to balance data diversity and move quality, avoiding the pitfalls of filtering out low-rated games.
- Empirical evidence highlights that model scaling combined with intermediate gradient weighting yields human-level play and state-of-the-art move prediction.
Introduction
The paper addresses the central challenge of designing searchless, human-like chess engines trained solely on move sequences without explicit board representations. The core insight is that such models must simultaneously master two orthogonal capabilities: implicit state tracking ("tracking" T) and high-quality move selection ("decision quality" Q). The work introduces and formalizes a dual-capability bottleneck, P≤min(T,Q), showing that downstream performance is constrained by whichever capability is weakest. Empirical results demonstrate that the conventional approach of filtering out low-rated games to improve decision quality is predictably suboptimal, as it catastrophically impairs position tracking, particularly in non-canonical positions, middlegames, and endgames.
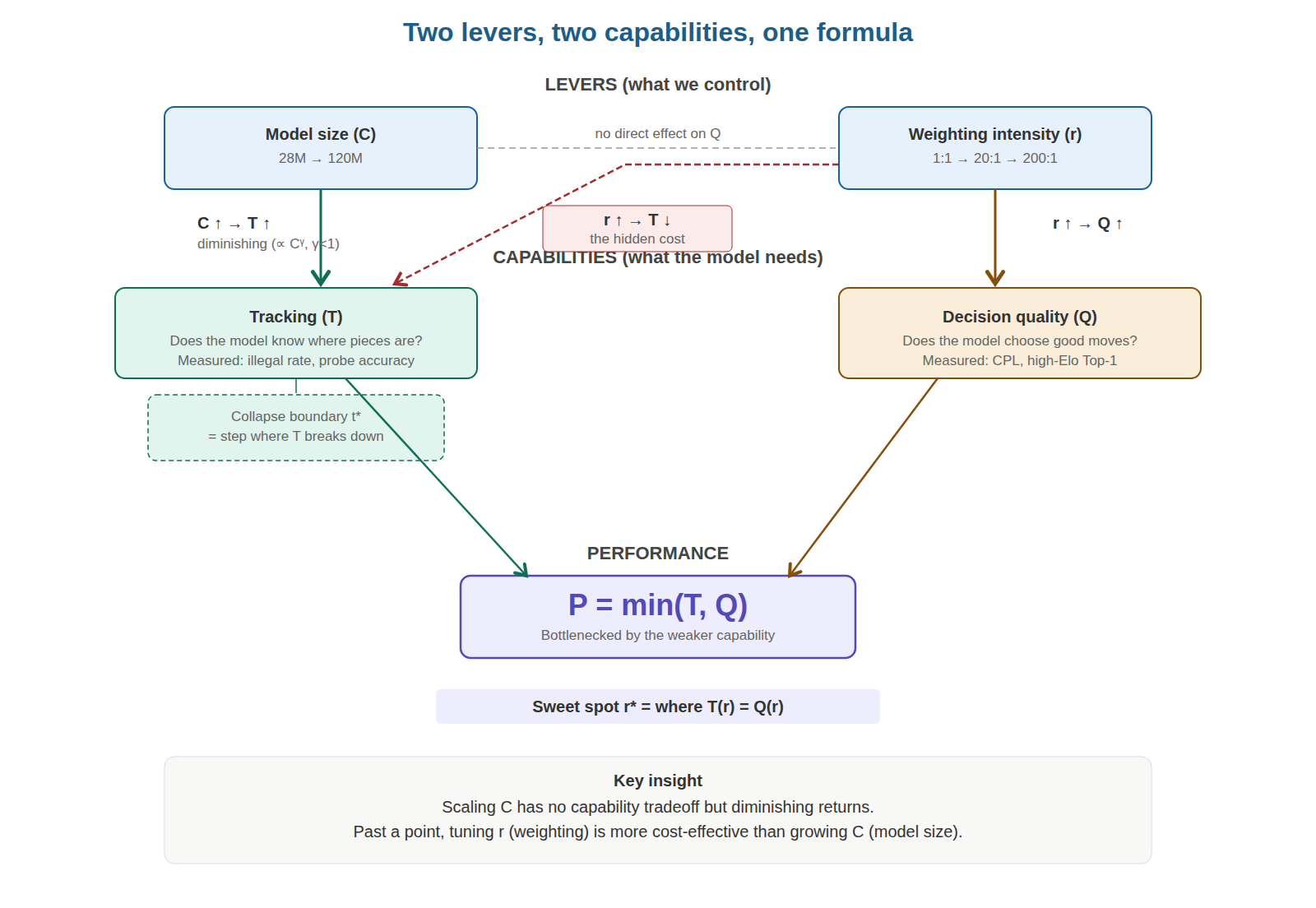
Figure 1: Core variable relationships. Two controllable levers (model capacity and data weighting) feed two capabilities (tracking T and decision quality Q), governed by the bottleneck P≤min(T,Q).
Methodology and Model Framework
Architecture and Training Protocol
A standard decoder-only Transformer architecture is utilized, with model sizes of 28M and 120M parameters, trained on sequences of UCI-formatted moves. The model receives no explicit board state or chess-specific features; all representation of position must be inferred auto-regressively from the action sequence. Training data covers the complete Lichess Elo spectrum in Bullet and Blitz formats, augmented by puzzle datasets for additional diversity.
Data Weighting and the Bottleneck Paradigm
Contradictory pressures arise in training: low-rated games introduce high positional diversity (essential for robust tracking), while high-rated games drive improved decision quality. The paper demonstrates that hard filtering of low-rated data sharply degrades tracking (double illegal-move rates, collapsed accuracy in complex phases), providing both behavioral and mechanistic evidence from internal linear probes.
To resolve this, an Elo-weighting scheme is proposed, modulating gradient contributions by player rating without removing positions that foster tracking diversity. The authors empirically demonstrate that only a specific intermediate weighting intensity ("the sweet spot") effectively balances these competing requirements; both under- and over-weighting degrade effective performance.

Figure 2: Experimental causal chain. Each step's failure diagnosis motivates the next intervention, from baseline through filtering failure, model scaling, Elo weighting, and the discovery of the weighting sweet spot.
Empirical Analysis and Ablation
Data Filtering Paradox and Internal Probe Evidence
Filtering for high-quality (high-Elo) data produces only minor improvements in opening accuracy but catastrophic declines in tracking-dependent phases. Internal linear probes measuring 64-square board state accuracy across network layers confirm this: probe accuracy degradation is specifically localized to non-standard, middlegame, and endgame positions when low-level diversity is removed.
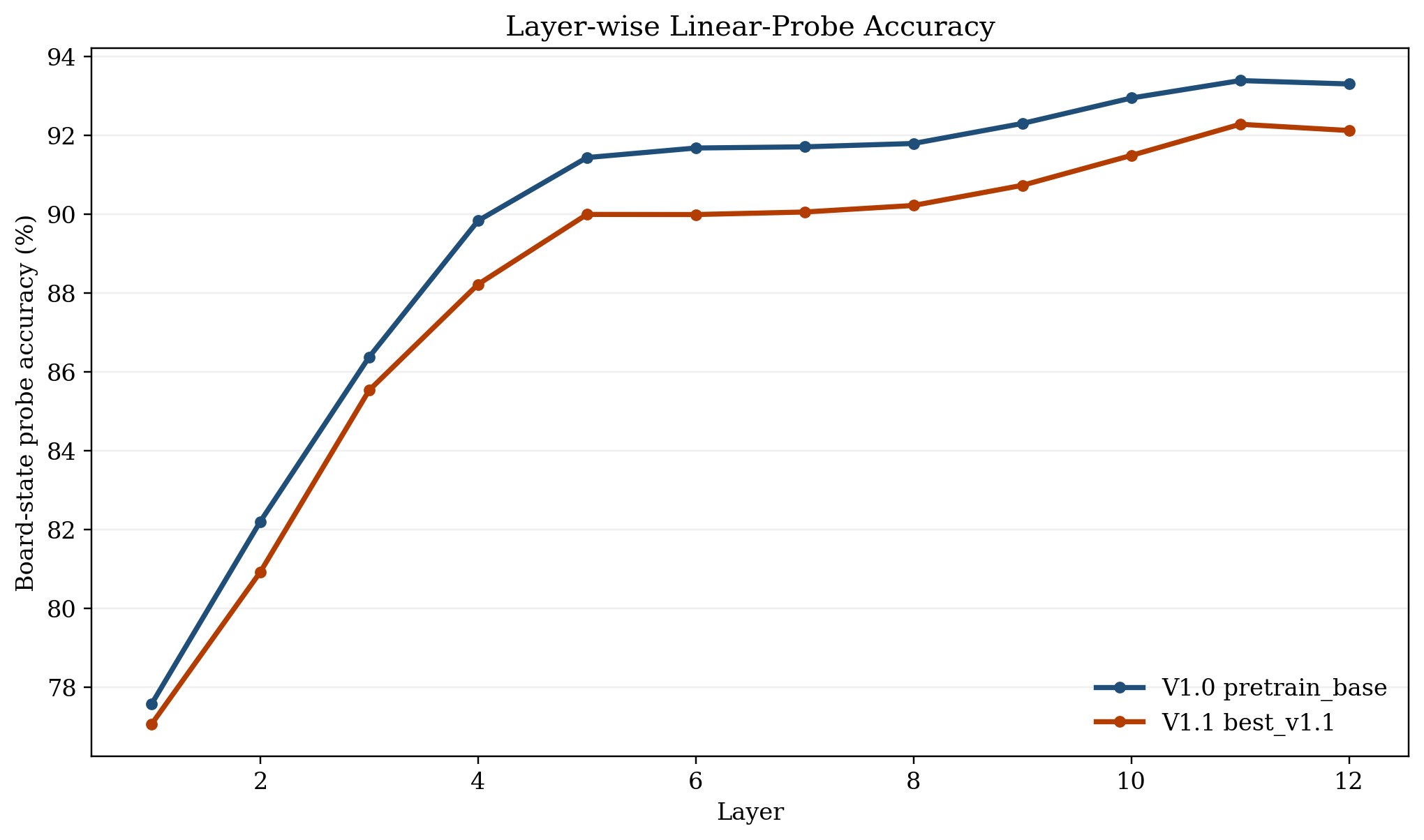
Figure 3: Layer-wise board-state probe accuracy. The all-Elo base model (V1.0) maintains higher square accuracy throughout the network, with both models peaking in the final layer.
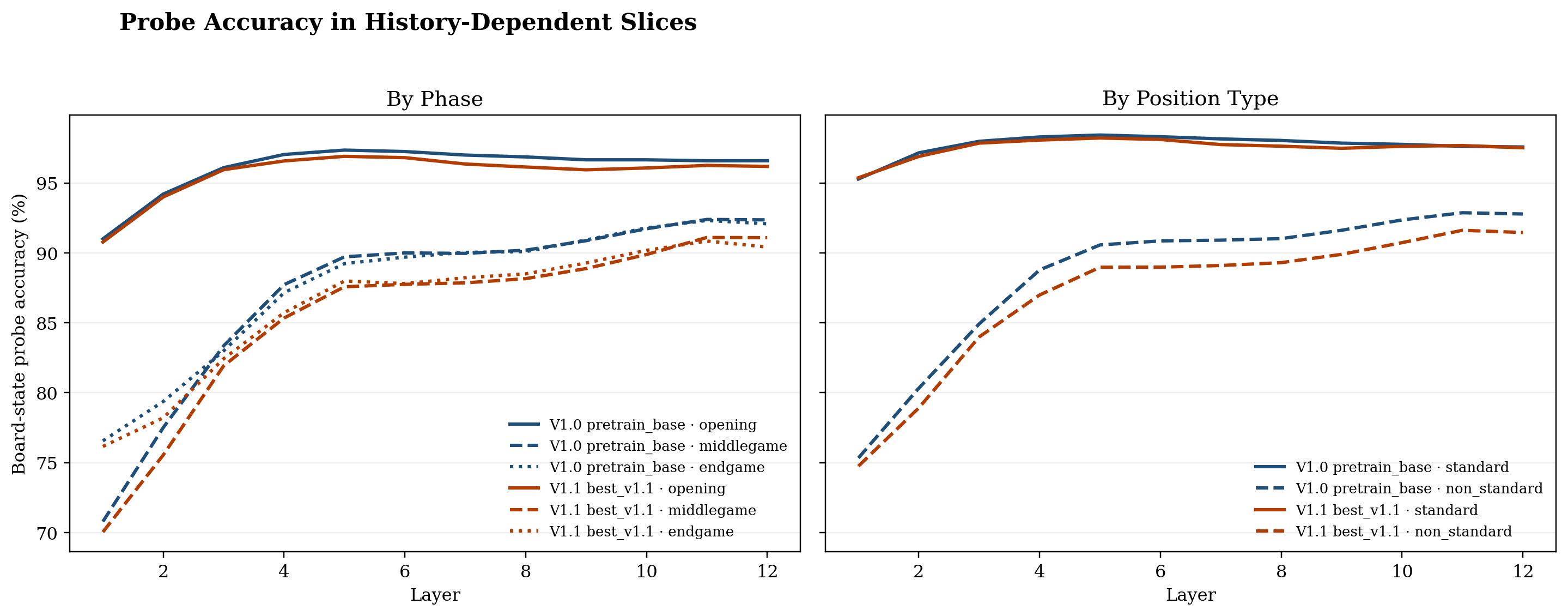
Figure 4: Probe accuracy by evaluation slice. The gap between V1.0 and V1.1 is smallest on standard and opening positions, and largest on non-standard, middlegame, and endgame slices---precisely where low-Elo games contribute the most diverse positions.
Weighting Sweet Spot and Factorial Design
A full 2×2 factorial ablation across model size and weighting scheme empirically isolates the effects of model scaling (which primarily benefits tracking) and gradient weighting (which primarily augments decision quality). Strong head-to-head performance gains are achieved only by combining both interventions, and the intermediate but not extreme weighting regime maximizes practical Elo.
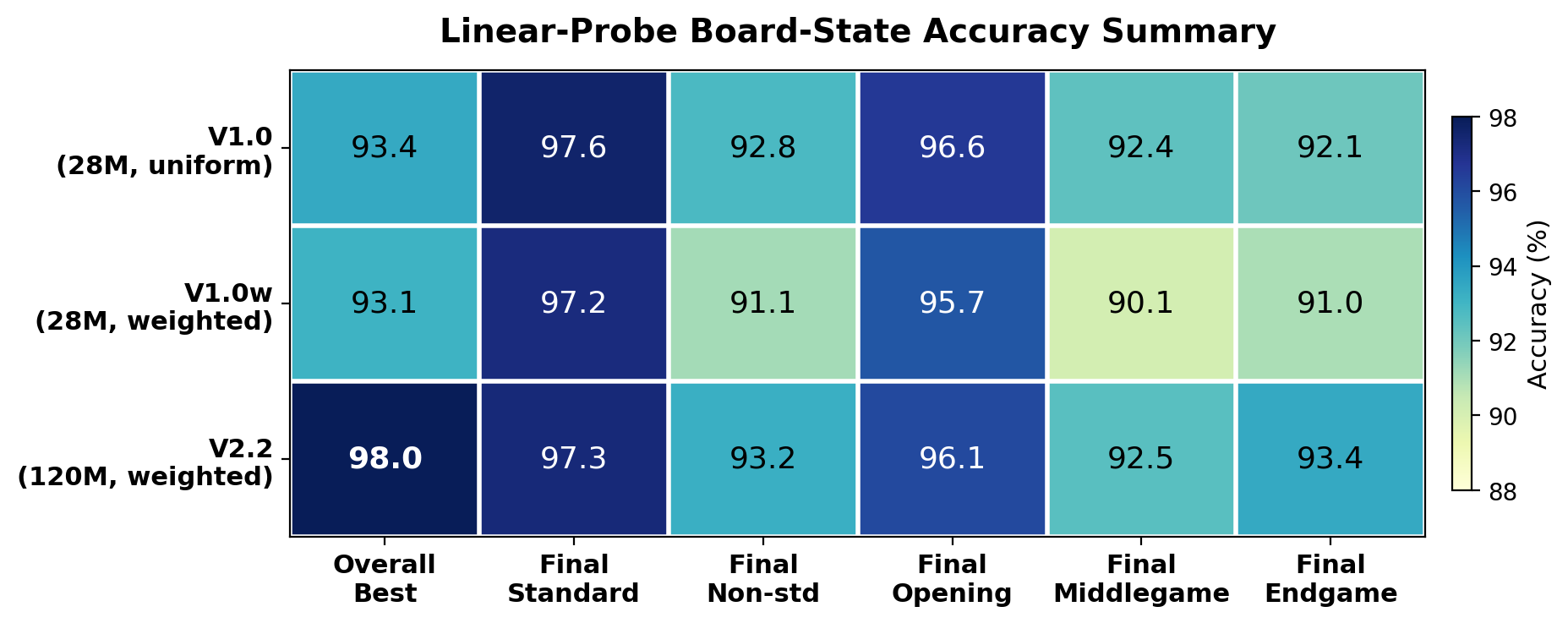
Figure 5: Linear-probe board-state accuracy for three models (V1.0, V1.0w, V2.2) under unified evaluation. Scaling from 28M to 120M produces a large tracking improvement (93.4% to 98.0%), while weighting at fixed 28M scale does not improve---and slightly reduces---probe accuracy.
Degeneration Points: Late-Game Fragility
The model consistently manifests local "degeneration points" during games, where move quality drops dramatically, reflected in sharp cliffs of catastrophic blunder probability and mean centipawn loss when game states enter underrepresented or off-distribution configurations. A simple coverage-decay theoretical model explains the exponential explosion of state space support as games deepen.
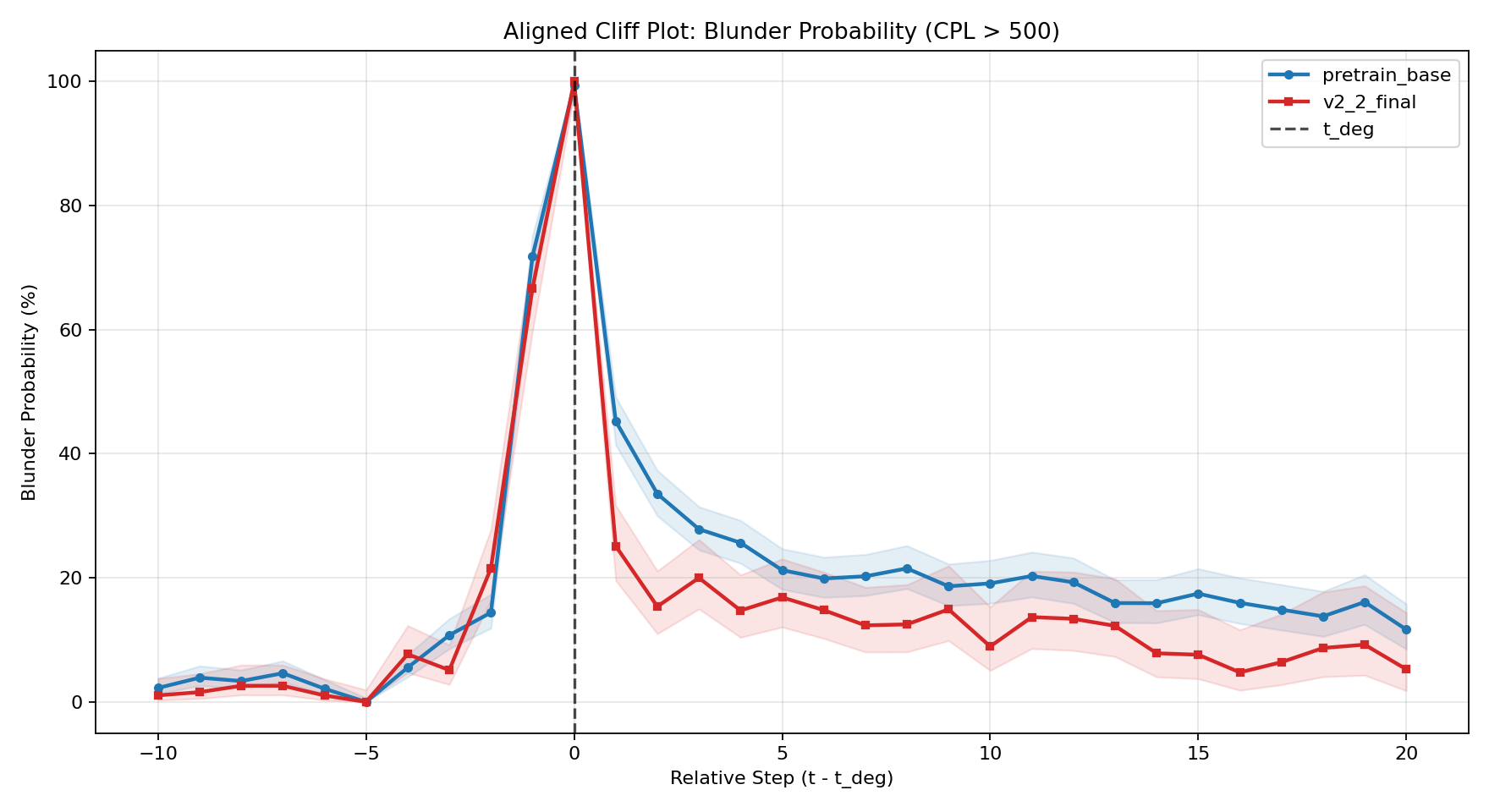
Figure 6: Aligned cliff plot of catastrophic blunder probability (CPL~>~500) around tdeg.
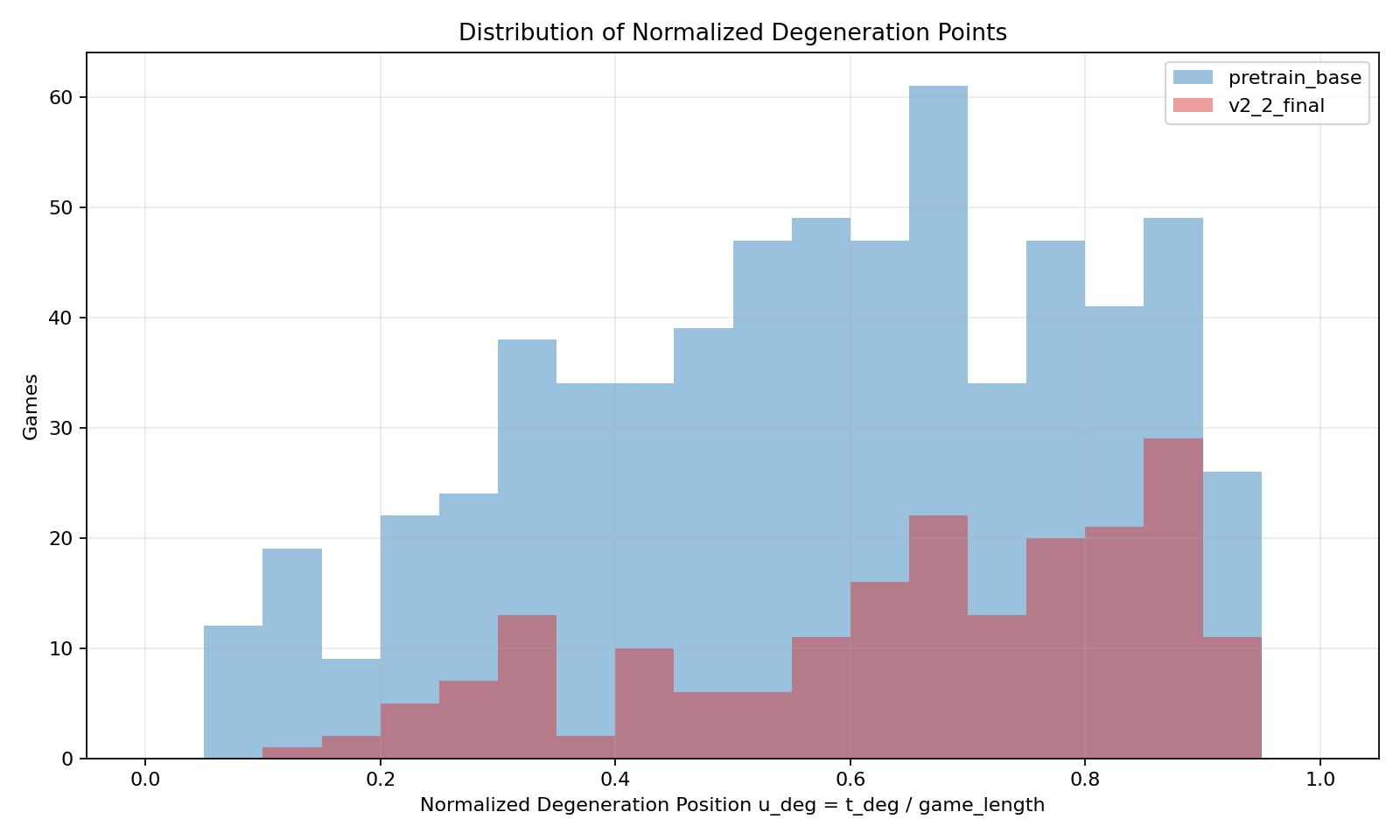
Figure 7: Distribution of normalized degeneration positions udeg. Degeneration occurs predominantly in later stages, and the final model shifts the distribution rightward.
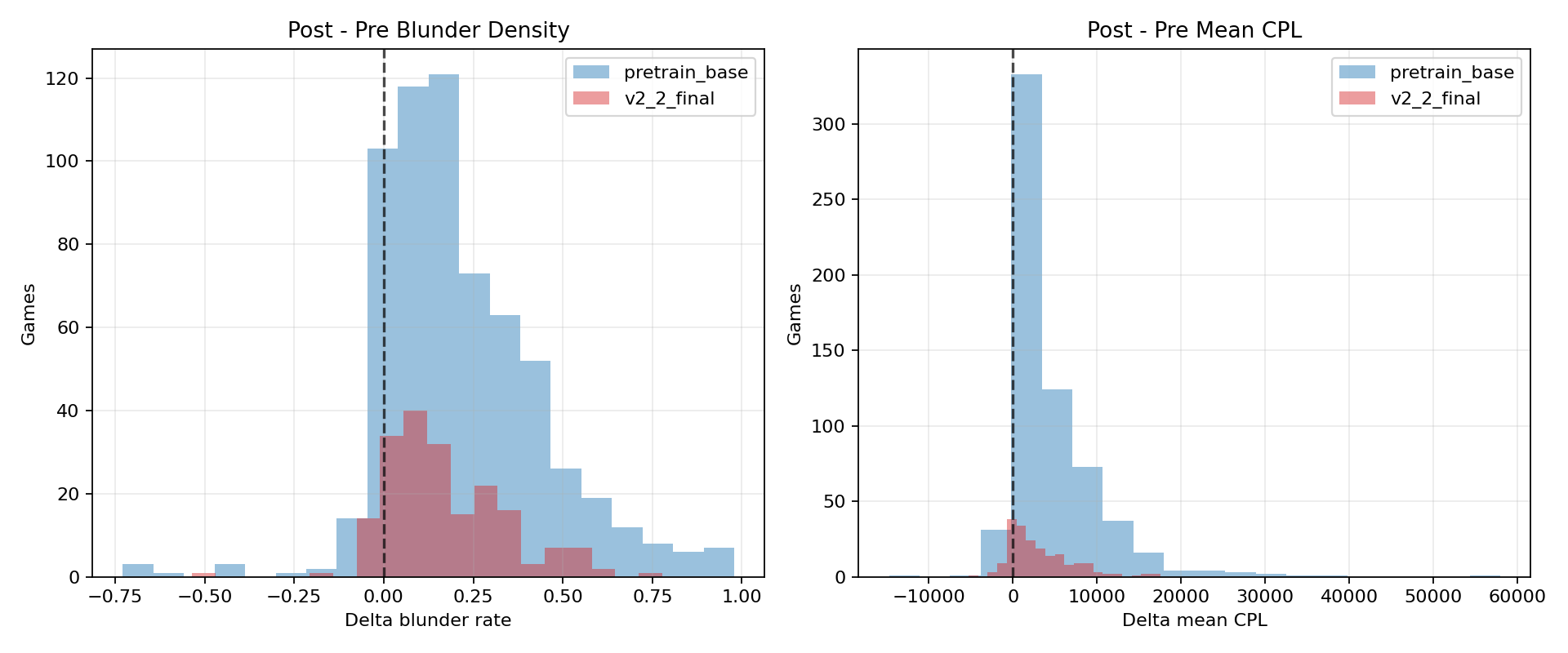
Figure 8: Within-game error changes after the degeneration point. Left: change in blunder density. Right: change in mean CPL. For most games, both increase after tdeg.
Human-Likeness Evaluation
Static Move Prediction
Under native-input (sequence-based) evaluation, the final model achieves 55.2% Top-1 accuracy in human move prediction—outperforming Maia-2 (FEN-based), which plateau at 50%. The gain is especially pronounced in openings and positions where move sequence history is highly informative, confirming substantial advantages to the autoregressive, sequence-based paradigm.
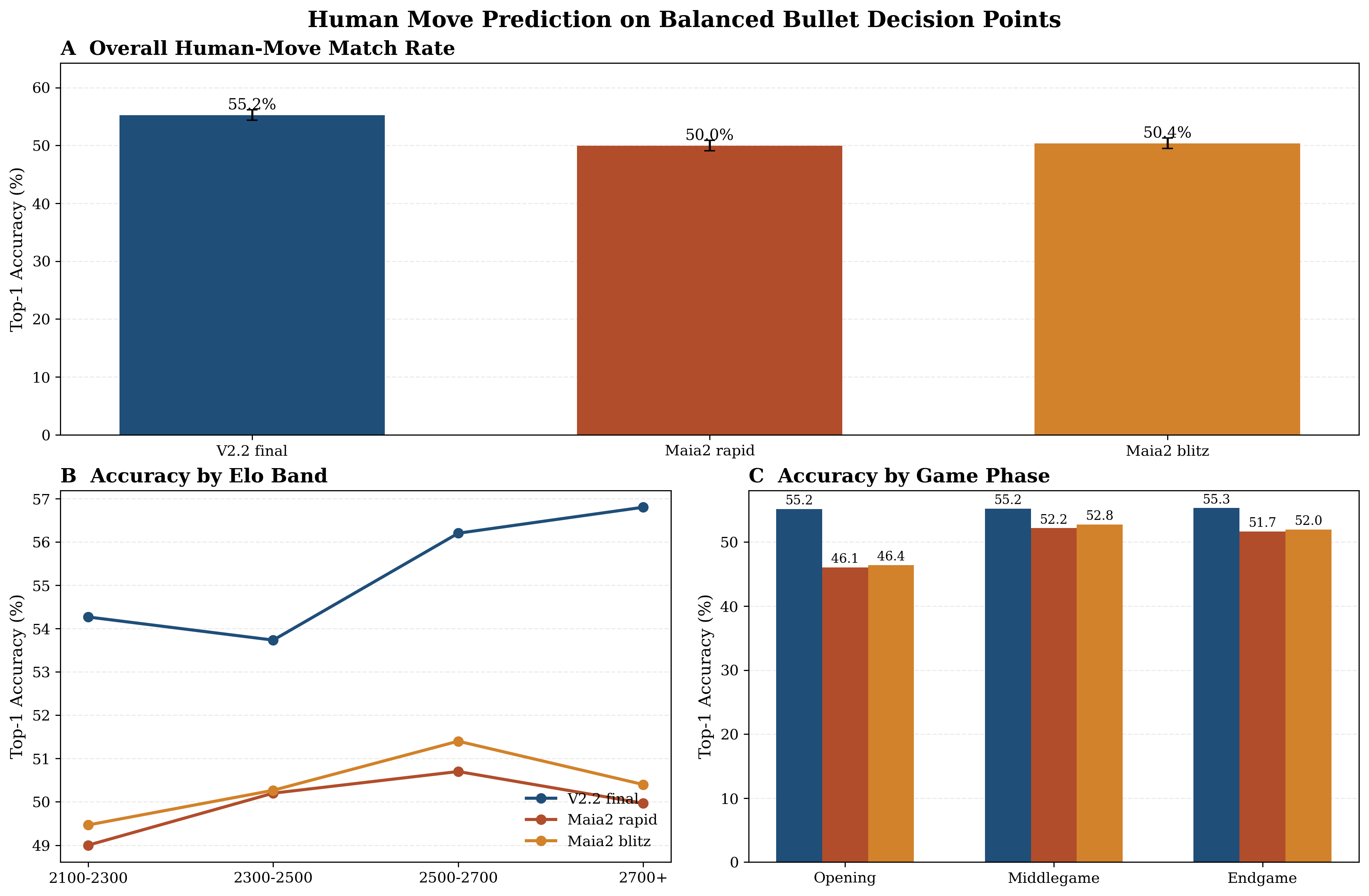
Figure 9: Human move prediction comparison. Panel A: overall Top-1 accuracy. Panel B: accuracy by Elo band. Panel C: accuracy by game phase. V2.2 outperforms both Maia-2 variants across all slices.
Error Overlap and Human-Like Failure
Blunder-alignment analysis shows the model's propensity to fail on positions where humans blunder is higher than Maia-2, particularly at more severe blunder thresholds, indicating closer alignment not only in what moves are played but also in what mistakes are made.
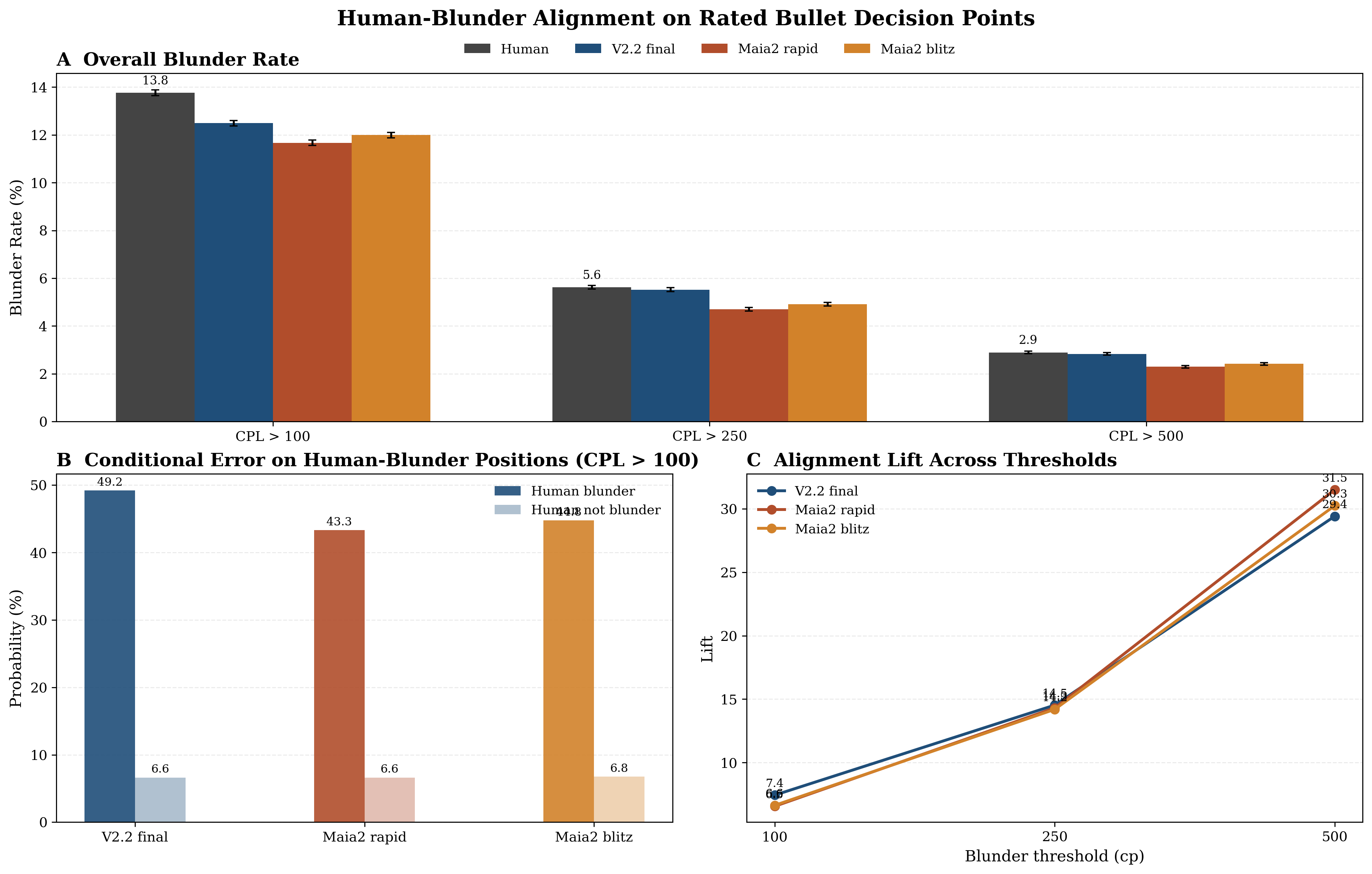
Figure 10: Human-blunder alignment. Panel A: overall blunder rates at three thresholds. Panel B: conditional blunder probability on human-blunder vs. human-non-blunder positions. Panel C: alignment lift increases with threshold severity, and V2.2 consistently leads.
Trajectory-Dependent Decisions
A controlled experiment on repetition/draw decisions using move history demonstrates the model's explicit use of sequential context, directly contrasting with position-only models. Altering history while holding position fixed materially changes model behavior, validating true trajectory-sensitive reasoning.
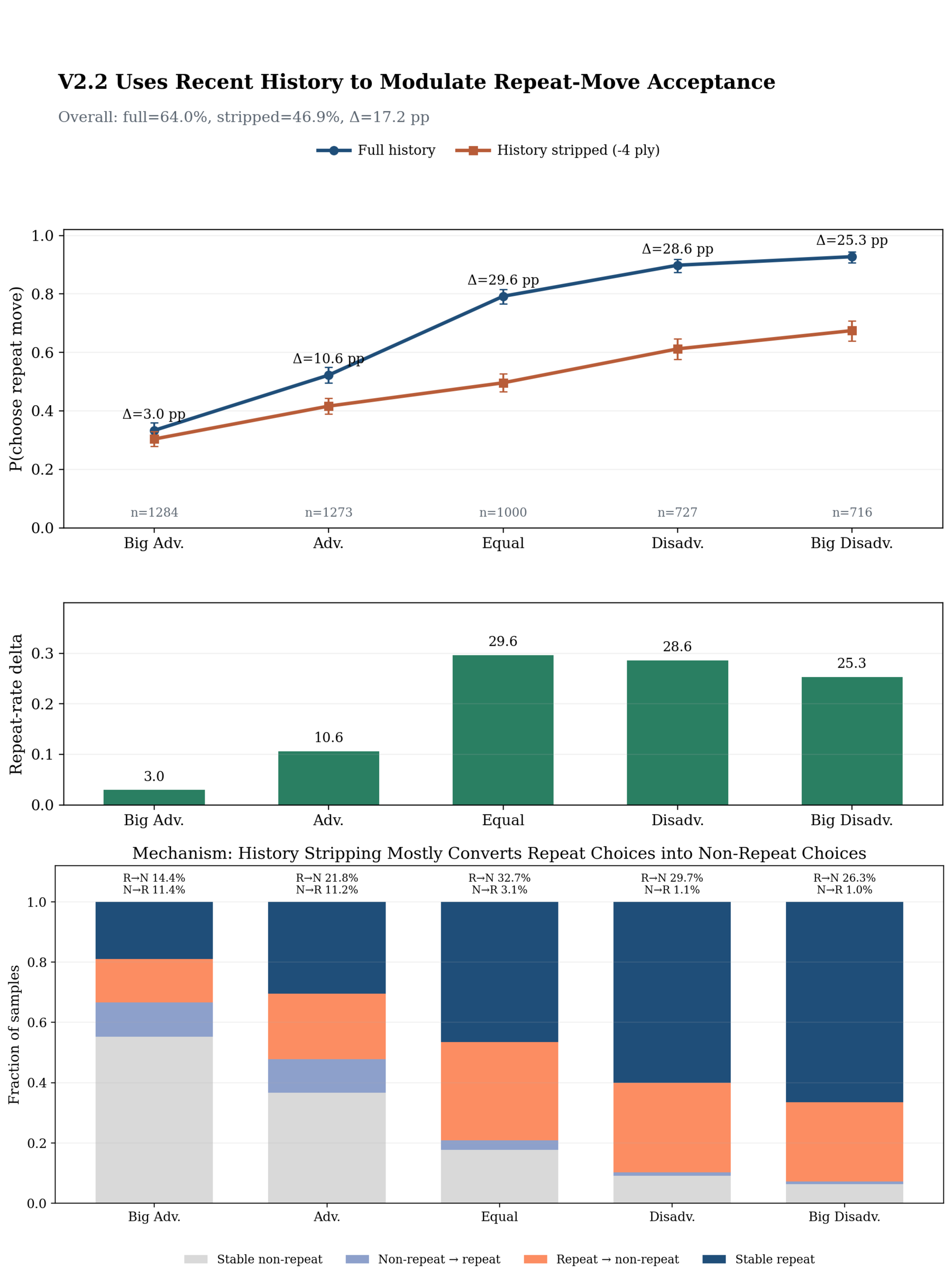
Figure 11: Repetition behavior and history-control test. Panel A: repetition preference across evaluation buckets under full-history and history-stripped inputs. Panel B: fraction of decisions that flip when history is removed.
Real-World Deployment
In online play, the model attained a Lichess bullet Elo of 2570 without triggering anti-cheating measures, consistent with human-like timing and move-selection patterns.
Implications and Future Directions
This work provides formal and empirical evidence that in searchless, sequence-trained RL systems for stateful environments, performance is bounded by the weaker of tracking and decision capacities. Aggressive data curation for quality is, under this bottleneck, actively harmful unless positional diversity for implicit tracking is preserved. This result generalizes to any game or domain where latent state estimation is necessary and state-space coverage is adversarially or anti-correlated with task-optimal data.
Soft data modulation—such as Elo-based gradient weighting—allows balancing these competing constraints, and model capacity determines the feasible sweet spot. The findings call into question the sufficiency of aggregate validation metrics, advocating instead for evaluation protocols that directly interrogate bottlenecked capabilities. Further, the analysis of intra-game degeneration and compounding error dynamics may inform architecture and data augmentation protocols for greater late-phase robustness.
Applicability extends beyond chess, with direct experimental predictions for sequence models in other perfect and imperfect information games (e.g., Othello, Shogi, Poker) when move-only or event-sequence-only data is available.
Conclusion
The study establishes that training high-level, human-aligned, searchless chess Transformers from move sequences necessarily confronts a dual bottleneck in tracking and decision quality, with naïve data filtering harming practical strength by undermining state reconstruction. Elo-weighted loss delivers a soft-resolution of this paradox, with empirical evidence confirming a real and sharply localized sweet spot. The resultant models achieve human-level online play, state-of-the-art native-input move prediction, and manifest unique trajectory-sensitive behaviors unachievable by position-only paradigms. These findings have strong implications for the design and training of autoregressive agents in any sequential decision environment with hidden state and quality-diversity tradeoffs.