- The paper introduces HyperKKL, a framework that applies hypernetwork-based input conditioning to yield input-dependent neural KKL observers for improved state estimation in non-autonomous nonlinear systems.
- The framework comprises two strategies, HyperKKL_obs and HyperKKL_dyn, which adjust latent dynamics and encoder-decoder weights respectively, achieving up to 86% SMAPE reduction over static baselines.
- The study provides theoretical error bounds and practical guidelines, highlighting a trade-off between dynamic expressiveness and optimization complexity for robust observer design.
Overview and Motivation
The paper investigates the synthesis of Kazantzis-Kravaris/Luenberger (KKL) observers for nonlinear non-autonomous systems, specifically those whose dynamics are influenced by exogenous inputs. Traditional neural KKL observer architectures are restricted to autonomous regimes, relying on static transformation maps that do not adequately generalize to input-driven systems. This architectural limitation results in persistent phase drift and degraded estimation accuracy when applied to controlled systems. Theoretical extensions in prior work suggest that time-varying transformation maps are necessary to accommodate non-autonomous settings, but systematic learning-based implementations for such observers have been lacking.
To bridge this gap, the authors propose the HyperKKL framework, leveraging hypernetwork-based input conditioning for neural KKL observers. Two complementary strategies are introduced: (i) HyperKKL\textsubscript{obs}, which applies input-dependent corrections to latent observer dynamics while retaining static encoder-decoder maps; and (ii) HyperKKL\textsubscript{dyn}, which uses a hypernetwork to generate input-conditioned encoder and decoder weights for fully dynamic transformation maps. The framework achieves significant improvements in state estimation error, especially across diverse input regimes, and provides explicit theoretical bounds relating approximation and architectural properties to estimation performance.
HyperKKL Framework: Architectural Innovations
HyperKKL is structured in two phases: autonomous pretraining and input-conditioned adaptation.
- Phase 1—Autonomous Pretraining: Encoder and decoder networks are separately trained on data from the unforced (autonomous) system. The encoder approximates a transformation map T into a stable latent space, and the decoder approximates the left inverse T∗.
- Phase 2—Input Conditioning:
Both strategies are trained using a dataset comprising diverse initial conditions and input signals, enabling generalization across multiple regimes.
Theoretical Guarantees: Estimation Error Bounds
The authors derive a worst-case bound for the state estimation error of the learned KKL observer. The error is shown to depend on: (1) the uniform approximation error of the learned encoder and decoder; (2) the residual violation of the governing PDE for the transformation map; and (3) the Lipschitz constant of the decoder inversion. Explicitly, for compact domains and continuously differentiable networks, the asymptotic estimator error is bounded by:
t→∞limsup∥ξ(t)∥≤ϵdec+ℓdec(ϵpdeλκ+ϵenc)
where ϵpde is the maximal PDE residual, ℓdec is the decoder's Lipschitz constant, ϵenc, ϵdec are encoder and decoder approximation errors, and κ, T∗0 arise from the Hurwitz observer matrix. The architectural difference between HyperKKL\textsubscript{obs} and HyperKKL\textsubscript{dyn} manifests in their control over T∗1 and T∗2, explaining the observed empirical trade-offs.
Empirical Validation: Robust Accuracy Gains
The framework is tested on four benchmark nonlinear systems (Duffing, Van der Pol, Rössler, FitzHugh-Nagumo) under various input regimes (zero, constant, sinusoidal, square wave). Both observer variants are compared to baselines: the static autonomous observer and a curriculum learning strategy. Strong numerical results include:
- SMAPE reduction: HyperKKL\textsubscript{obs} achieves up to 86% reduction in symmetric mean absolute percentage error (SMAPE) compared to the autonomous baseline under certain input regimes.
- Consistency: Both HyperKKL variants reduce SMAPE under non-zero input in nearly all cases, with HyperKKL\textsubscript{obs} outperforming HyperKKL\textsubscript{dyn} in 13 of 16 system/input combinations.
- Generalization: The curriculum learning baseline, which relies only on diverse data, exhibits degraded performance, confirming that architectural input conditioning—not richer data alone—is necessary for robust observer design.
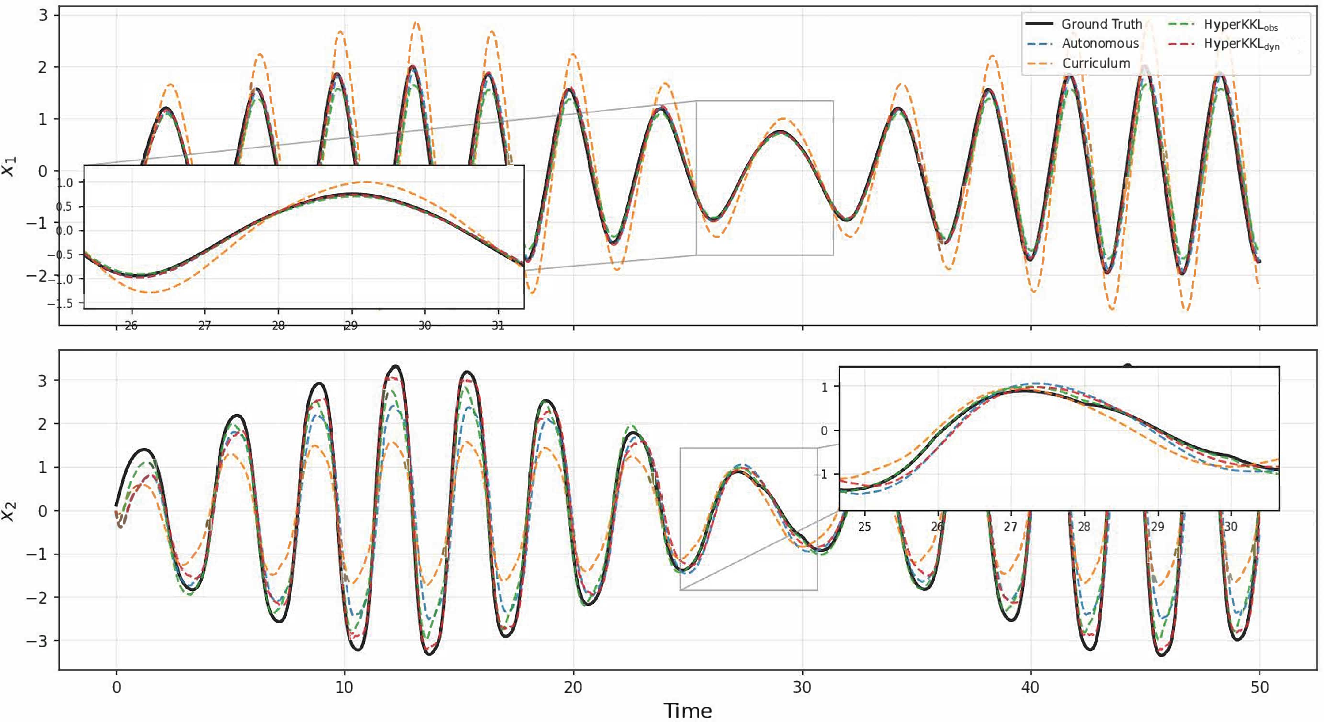
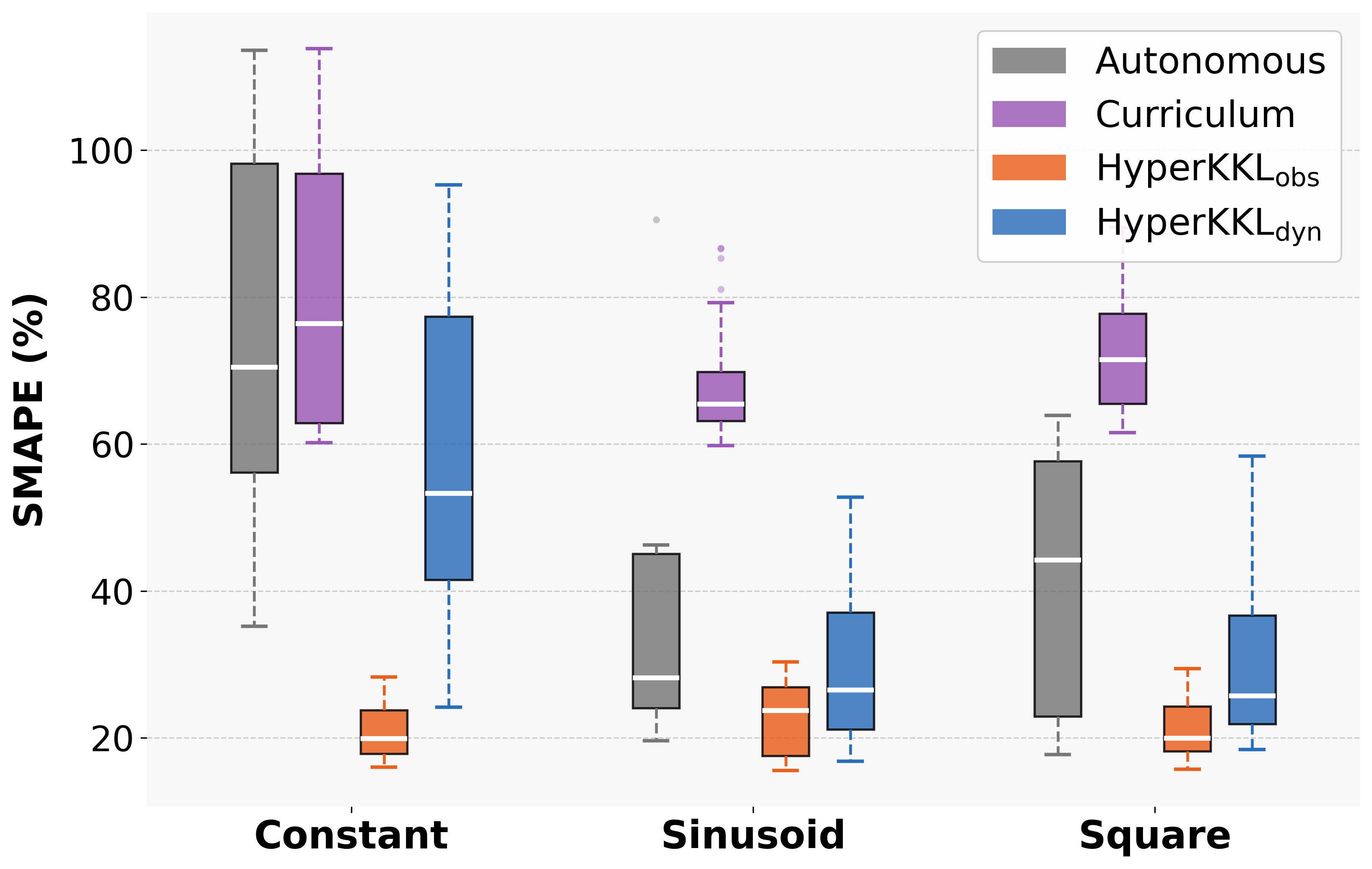
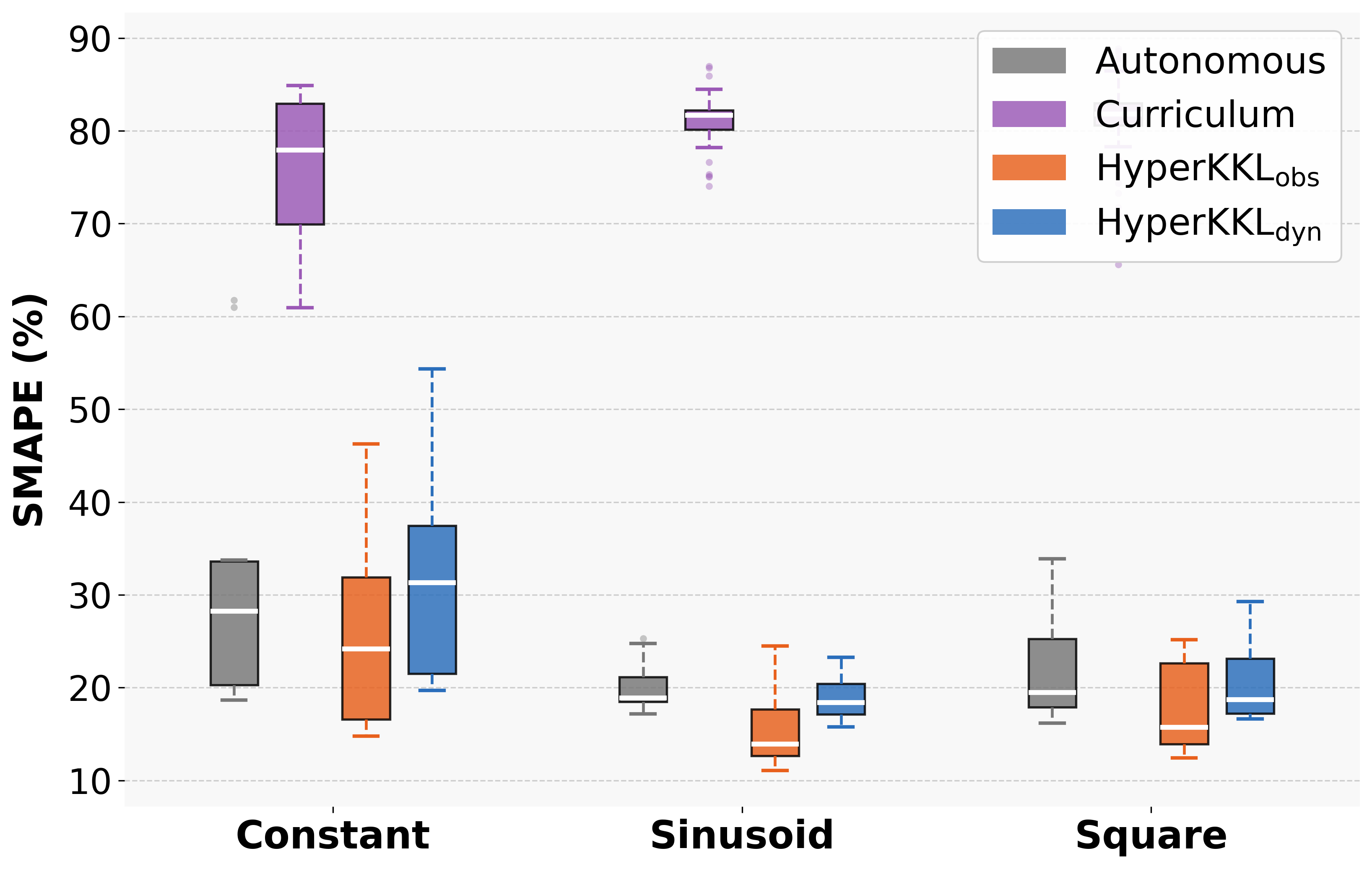
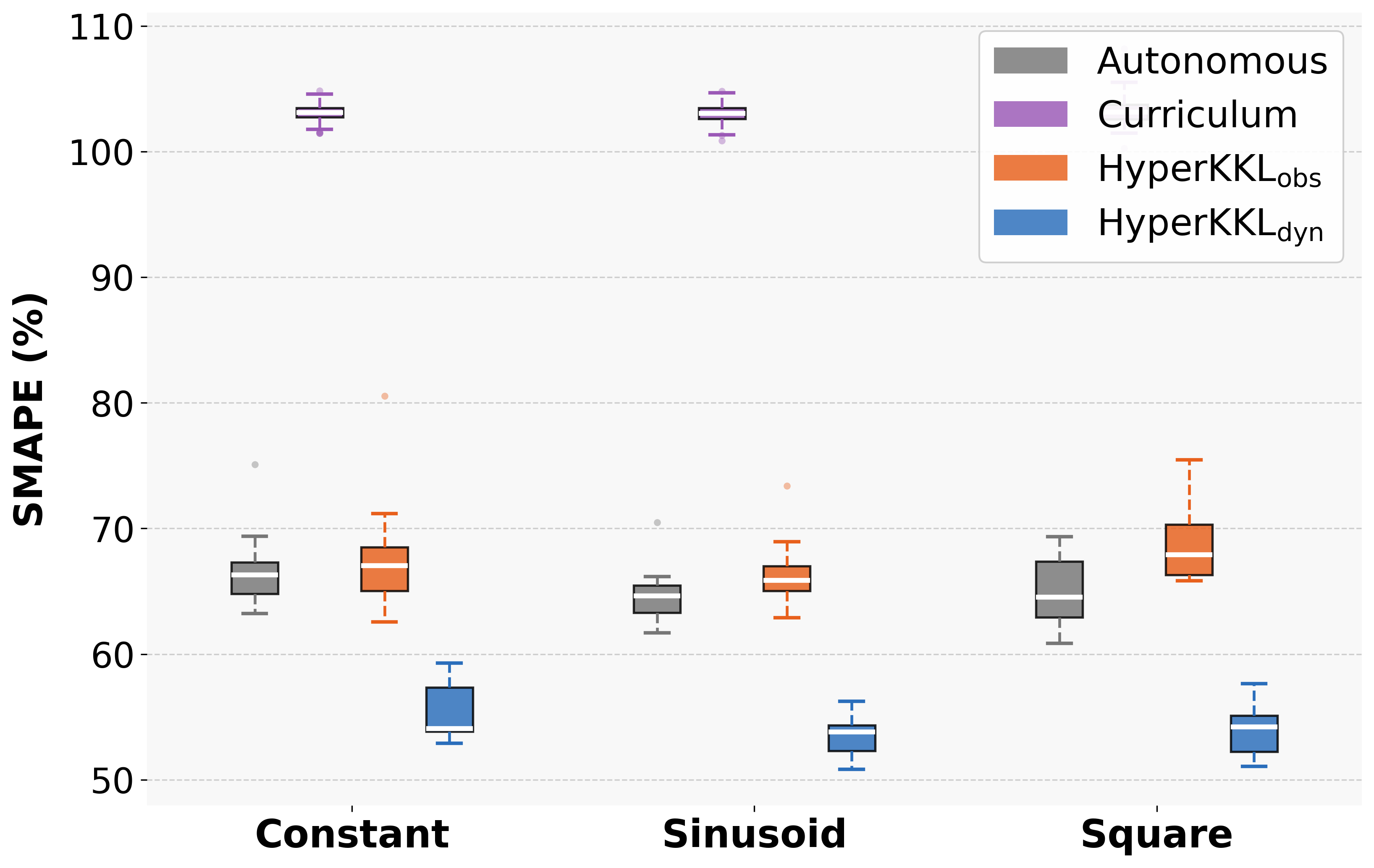
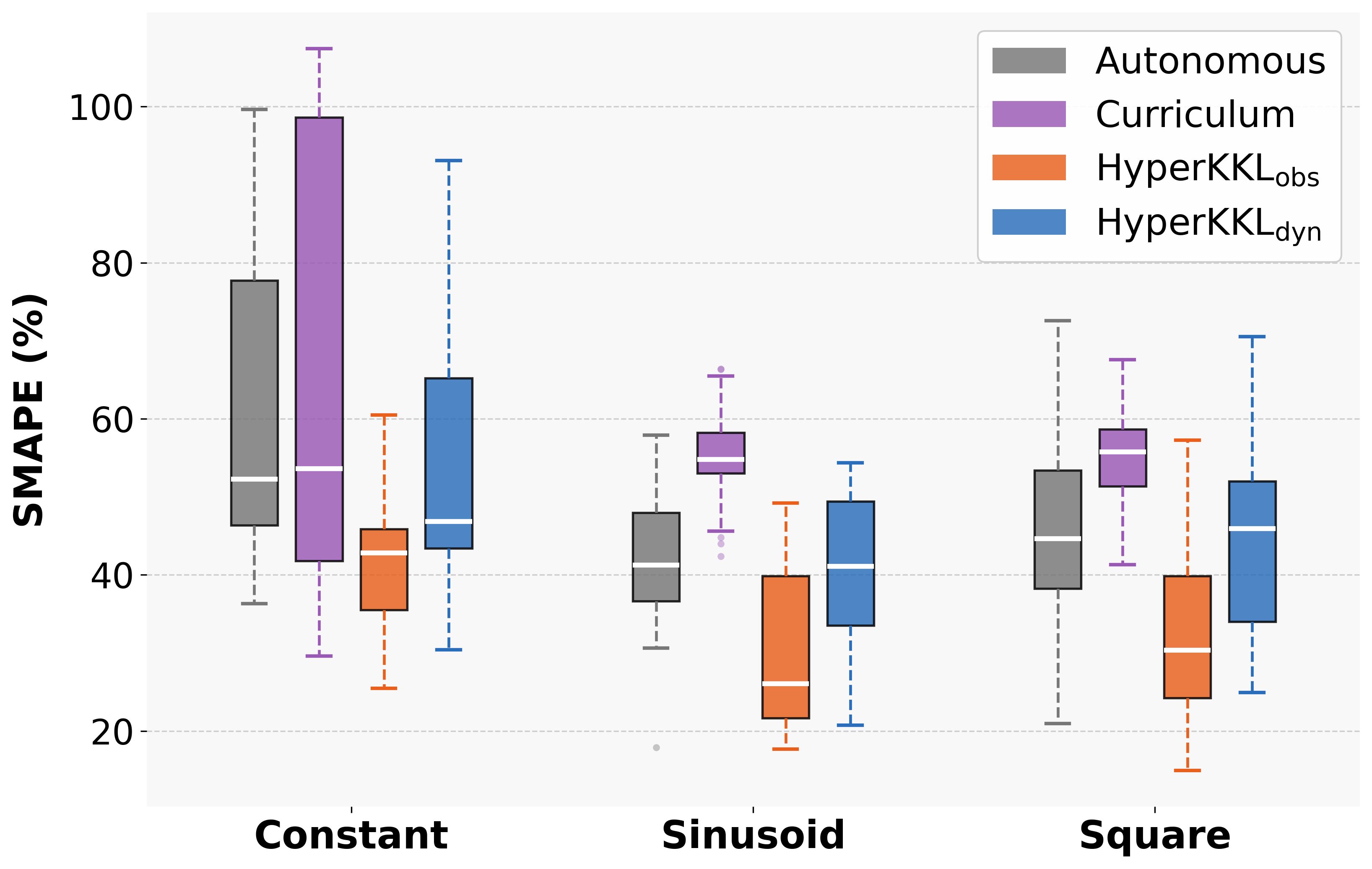
Figure 2: State estimation of the Duffing oscillator under square wave input, demonstrating that HyperKKL\textsubscript{obs} accurately tracks the ground truth and avoids phase drift.
Practical and Theoretical Implications
The findings have several direct implications:
- Input conditioning is essential: Static transformation maps are insufficient for non-autonomous nonlinear systems; architectural integration of input signals into observer dynamics or mapping is required to ensure bounded error and correct embedding.
- Hypernetworks as adaptation mechanisms: Hypernetwork-based conditioning enables interpolation in the space of transformation maps, supporting robust generalization across input regimes without retraining for each realization.
- Optimization/expressiveness trade-off: Dynamic conditioning (HyperKKL\textsubscript{dyn}) is theoretically more expressive, but practical optimization difficulties mean latent injection (HyperKKL\textsubscript{obs}) often offers better accuracy.
- Future directions: The analysis motivates spectral normalization to control the Lipschitz constant, hybrid approaches focusing on decoder conditioning, and disturbance-aware extensions.
Conclusion
HyperKKL establishes a systematic hypernetwork-based approach to learning input-conditioned neural KKL observers for non-autonomous nonlinear systems. Both latent injection and dynamic transformation conditioning methods yield substantial reductions in estimation error compared to autonomous observers, explicitly addressing the architectural gap at the intersection of system identification and neural observer design. Theoretical analysis clarifies the underlying trade-offs and guides future model and optimization improvements, with broad implications for robust nonlinear state estimation and adaptive observer synthesis in complex, input-driven environments.