- The paper presents HOI-Synth, a pipeline for generating photorealistic synthetic data to improve egocentric hand-object interaction detection.
- It details the use of various domain adaptation regimes (UDA, SSDA, FSDA) to bridge the sim2real gap and boost segmentation performance.
- Empirical results indicate notable performance gains in low-label settings, highlighting synthetic data's role in efficient HOI detection.
Leveraging Synthetic Data for Egocentric Hand-Object Interaction Detection
Introduction and Motivation
Egocentric hand-object interaction (HOI) detection is essential for understanding human activities from a first-person perspective, supporting applications in robotics, behavior analysis, AR/VR, and assistive technology. Annotation of HOI in egocentric video, however, is highly labor-intensive and cost-prohibitive at scale. The paper "Leveraging Synthetic Data for Enhancing Egocentric Hand-Object Interaction Detection" (2603.29733) directly addresses the twin challenges of data scarcity and domain overfitting by systematically studying the role of synthetic data and domain adaptation for egocentric HOI segmentation and detection.
To this end, the authors introduce HOI-Synth—a synthetic data generation pipeline and benchmark—which systematically covers multiple aspects of hand-object interaction, provides matched synthetic datasets for major real HOI corpora, and addresses how best to apply synthetic data in fully-supervised, semi-supervised, and unsupervised domain adaptation regimes.
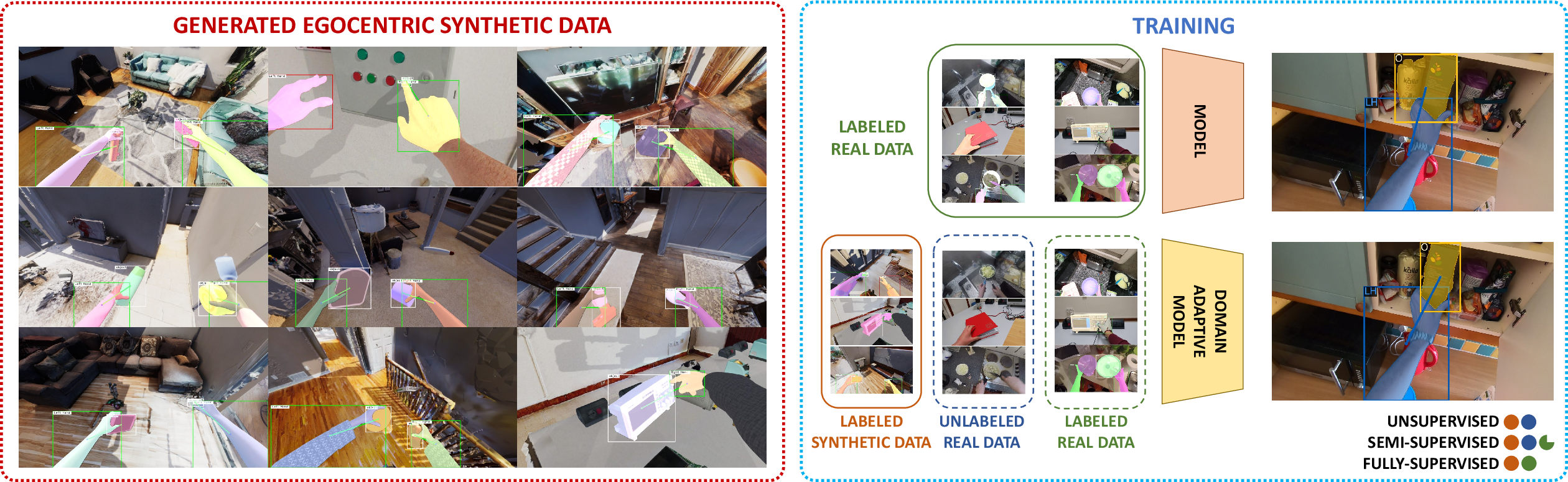
Figure 1: We explore the role of synthetic data in egocentric hand-object interaction detection by generating and automatically labeling synthetic datasets (left). We then analyze domain adaptation scenarios where models are trained using both synthetic and real unlabeled data, with varying amounts of labeled real data (right).
Synthetic Data Generation and Benchmark Construction
Pipeline Overview
The HOI-Synth pipeline is architected to generate photorealistic egocentric images with extensive annotation, including pixel-wise hand/object segmentation, contact state, and hand-object relational metadata.

Figure 2: The proposed data generation pipeline. (a) An object-grasp pair is selected from DexGraspNet and integrated with a randomly generated human model. The human-object configuration is placed in a realistic scene, and annotated egocentric data are rendered.
The pipeline samples grasp configurations from DexGraspNet, retargets them to high-quality customizable human models, and places the resultant human-object pairs in realistic environments from the HM3D dataset. Camera parameters, FOV, lighting, human pose, and distractor background objects are randomized to enhance photometric and contextual diversity. Annotations are automatically synthesized using Unity’s high-definition rendering and perception stacks.
Qualitative inspection demonstrates high geometric consistency between hands and objects, physically plausible hand constraints, and scene diversity robust to occlusion and non-trivial interactions.

Figure 3: Qualitative examples generated by our HOI-Synth Data Generation Pipeline. Per sample, the pipeline provides segmentation and relational ground truth.
Target Datasets and Alignment
For empirical evaluation, the pipeline produces synthetic splits tailored to three benchmarks: VISOR (kitchen environments), EgoHOS (diverse daily tasks), and ENIGMA-51 (industrial electronic repair). HOI-Synth supports dataset conditioning, controlling for overlap in object instance, grasp type, and scene context, supporting both in-domain and out-of-domain synthetic distributions.

Figure 4: A ENIGMA-51 image (left), a synthetic in-domain image (center), and a synthetic out-domain image (right).
Domain Adaptation and Methodology
The paper benchmarks model performance under five regimes:
- Synthetic-Only: Training with synthetic data only, directly evaluated on real data.
- Unsupervised Domain Adaptation (UDA): Labeled synthetic + unlabeled real data.
- Semi-Supervised Domain Adaptation (SSDA): Labeled synthetic + unlabeled real + limited labeled real.
- Fully Supervised Domain Adaptation (FSDA): Labeled synthetic + full labeled real.
- Real-Only: Training and evaluating on labeled real data.
The central architecture is based on the VISOR HOS PointRend network, extended with modules for hand side, contact state, and hand-object link prediction. For UDA/SSDA, Adaptive Teacher (AT) is adopted, integrating pseudo-labeling, EMA teacher-student transfer, strong/weak augmentation strategies (without spatial jittering in student branch), and a gradient reversal adversarial domain discriminator.
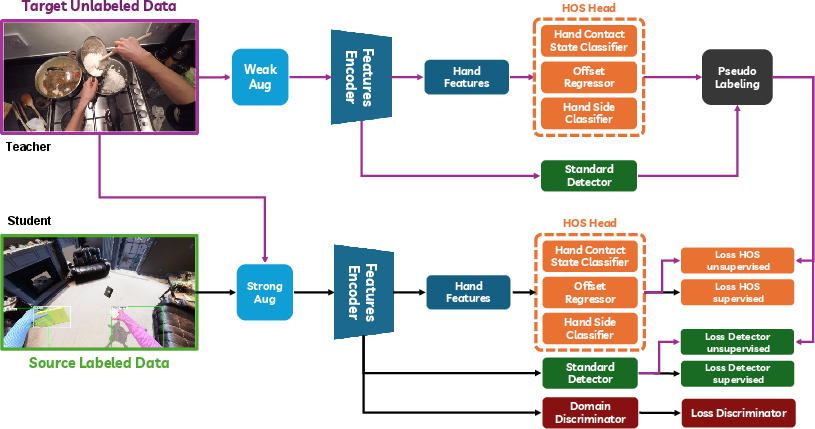
Figure 5: The architecture of the domain adaptation approach used, centered on Adaptive Teacher enhanced for HOI.
Empirical Results and Analysis
Domain Gap and Adaptation
Exclusive synthetic training yields low mask AP (e.g., 9.88% on VISOR, 7.16% on EgoHOS). This establishes a substantial sim2real gap (ΔAP≈30–40%), primarily due to synthetic domain limitations in photorealism, hand-object physics, and background diversity.
Integration of UDA techniques (labeled synthetic + unlabeled real, no manual labels) improves AP by +23.45% on VISOR, +21.0% on EgoHOS, and +21.93% on ENIGMA-51. For semi-supervised adaptation (SSDA; 10–25% labeled real), synthetic data boosts overall AP by up to +11.69% (ENIGMA-51) compared to real-only baselines, enabling performance with a small labeled set that matches or exceeds models trained on an order of magnitude more real data.
FSDA with full real labels yields smaller net gains (\textasciitilde+1–4%), indicating synthetic data's primary utility is in data-scarce regimes.
Qualitative Outcomes
SSDA-trained models outperform real-only and synthetic+real fine-tuning baselines on segmentation quality, particularly for small objects, complex scenes, and occlusions.

Figure 6: Qualitative examples on VISOR. SSDA demonstrates robustness to clutter, occlusion, and fine-structure over baselines.
Synthetic Dataset Scale and Structure
Increasing synthetic data volume up to 7.16%030k images yields monotonic improvement, with diminishing returns beyond this. Exhaustive scaling to 80k images provides negligible gains, establishing an efficiency plateau.
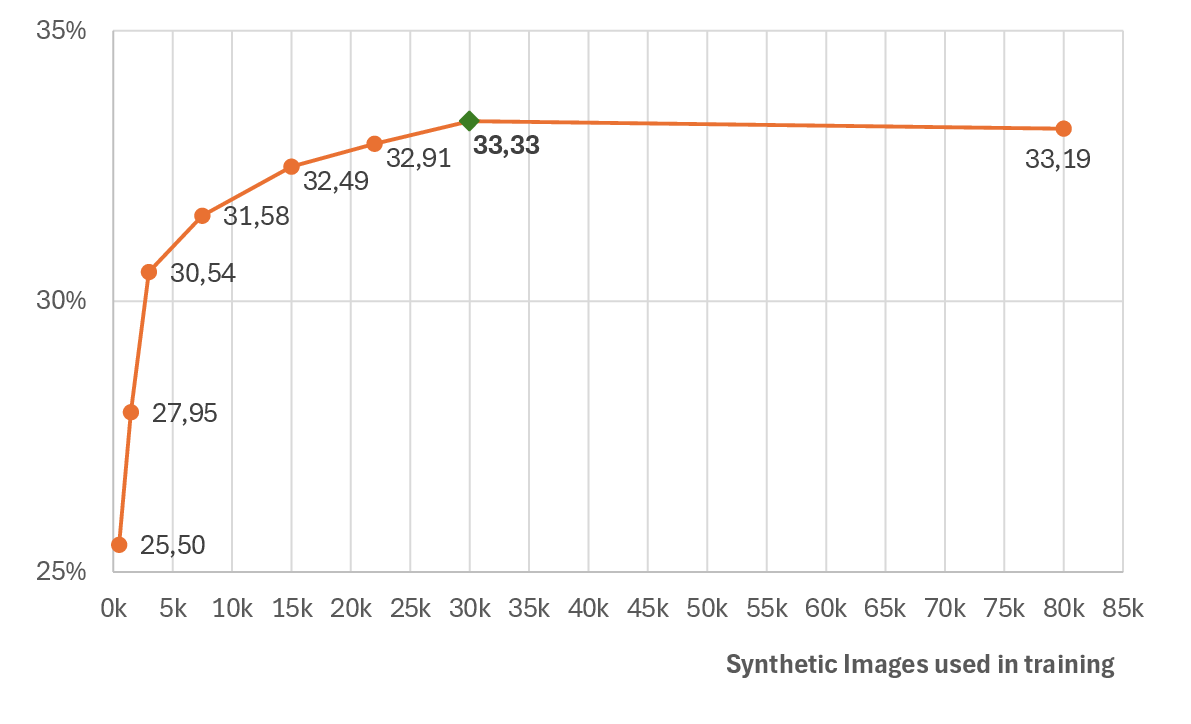
Figure 7: UDA Overall AP on VISOR validation set for different amounts of training synthetic data. The green indicator shows the best result.
Synthetic-real alignment is explored along three axes—object overlap, grasp similarity, and environment context. Alignment optimization is performed via DINOv2 and MMPose-driven clustering and matching, guiding the selection of synthetic assets closest to the real target distribution.

Figure 8: The green row shows the selected synthetic objects aligned with those in VISOR (black row). The red row contains the discarded examples, filtered out due to misalignment or poor quality.

Figure 9: The green row shows examples of selected grasps aligned with real grasps from VISOR (black row). The red row contains discarded cases due to misalignment or unrealistic grasp configurations.

Figure 10: Green rows contain some examples of selected synthetic images aligned with VISOR images (black row). The red row shows discarded examples due to misalignment or unsuitable viewpoints.
Alignment of all three modalities (object, grasp, environment) consistently improves UDA performance, with object overlap being the most significant contributor.
Generalizability and Ablative Studies
Adoption of the ConvNeXt-S backbone further improves performance over the standard ResNet101, indicating robustness across CNN architectures.
Comparison with naïve augmentation baselines—e.g., random placement of hand/object models on background photos—establishes that physically consistent simulation is crucial for transfer. Merely augmenting background data or compositing instances on random scenes leads to pronounced failure on interaction-dependent metrics.

Figure 11: Simple HOI generation approach: Object models and hands are randomly projected onto ImageNet backgrounds.
Implications and Future Directions
The study delivers several definitive takeaways for the field:
- Synthetic data, when integrated with domain adaptation frameworks, is an effective mechanism for reducing dependence on large annotated egocentric datasets in HOI detection.
- The quality, diversity, and domain alignment of synthetic data critically mediate sim2real transfer success. Precise alignment (objects, grasps, environments) is necessary in low-label (UDA) regimes but provides marginal gain once even small quantities of real labels are available.
- Optimal data regimes balance synthetic and real data such that a small proportion of real annotations (10–25%) suffices if complemented by a high-diversity synthetic set.
- Frame-based generation is adequate for the HOS task, but extending the pipeline to temporally coherent sequence generation is a relevant direction for future work.
- Beyond enhanced annotation, synthetic data augments are functional for downstream tasks (hand contact and side classification, offset prediction), not merely segmentation.
Conclusion
This work presents not merely a pipeline, but an extensive empirical account quantifying the impact of synthetic data and domain adaptation on egocentric HOI segmentation. The results are grounded in thorough quantitative and qualitative evaluation, with strong improvements documented in all adaptation regimes, especially when real labeled data is scarce, and reaffirm the necessity for physical plausibility and domain-aligned synthetic corpora in sim2real transfer for fine-grained hand-object interaction. Future research will benefit from sequence-level simulation, expanded physical modeling beyond grasping, and combinatorial scaling of synthetic domain space for more general egocentric activity understanding.

Figure 12: Qualitative examples on EgoHOS.

Figure 13: Qualitative examples on ENIGMA-51.

