- The paper introduces a three-step pipeline—relative ratio estimation, truncation, and recovery—to reliably estimate unbounded density ratios in covariate shift scenarios.
- It proposes a bounded surrogate via relative density ratio estimation that stabilizes importance weighting and mitigates high variance in heavy-tailed contexts.
- Theoretical analysis provides non-asymptotic, high-probability convergence rates for kernel regression, clarifying the sample complexity needed for effective adaptation.
Unbounded Density Ratio Estimation for Covariate Shift: Theory and Algorithms
Introduction
The paper "Unbounded Density Ratio Estimation and Its Application to Covariate Shift Adaptation" (2603.29725) tackles a critical problem in transfer learning: handling unbounded density ratios in covariate shift scenarios. Covariate shift occurs when the input distributions for training (source) and test (target) domains differ, but the output conditional on input remains the same. The standard approach to covariate shift, importance weighting, requires estimation of the density ratio θ(x)=dQ/dP, where P and Q denote the source and target input distributions, respectively. Most existing theoretical results and algorithms rely on the (often violated) assumption that θ is bounded, undermining their applicability to high-dimensional and heavy-tailed settings encountered in practice.
This paper designs a robust procedure for unbounded density ratio estimation and provides a complete finite-sample, non-asymptotic convergence analysis of both the density ratio estimation and its application to weighted regression under covariate shift.
Suppose we observe labeled training data (xi,yi) i.i.d. from the source distribution PX×Y and wish to estimate the regression function for the target distribution QX×Y, under covariate shift: PY∣X=QY∣X, PX=QX. The target risk is
E(x,y)∼Q[(y−f(x))2].
In the presence of covariate shift, the minimization of the empirical risk estimator under P0 becomes biased. The standard correction employs importance weighting:
P1
Crucially, when P2 is unbounded (e.g., with log-concave or heavy-tailed targets), both the theoretical risk and its estimation become challenging.
Theoretical Challenges in Unbounded Density Ratio Estimation
Most prior work either (i) assumes P3 is uniformly bounded or (ii) restricts to truncated or known forms, both unrealistic for modern applications. The key technical issue is that when P4 is unbounded, importance weights exhibit high variance, and the standard machinery for learning in reproducing kernel Hilbert spaces (RKHS) fails since bounded functional classes cannot express unbounded densities directly.
To overcome this, the paper introduces a surrogate: the relative density ratio P5, which is always bounded. This is defined with respect to a mixture distribution P6 by
P7
P8 is always in P9, and Q0 can be recovered via a nonlinear transformation of Q1.
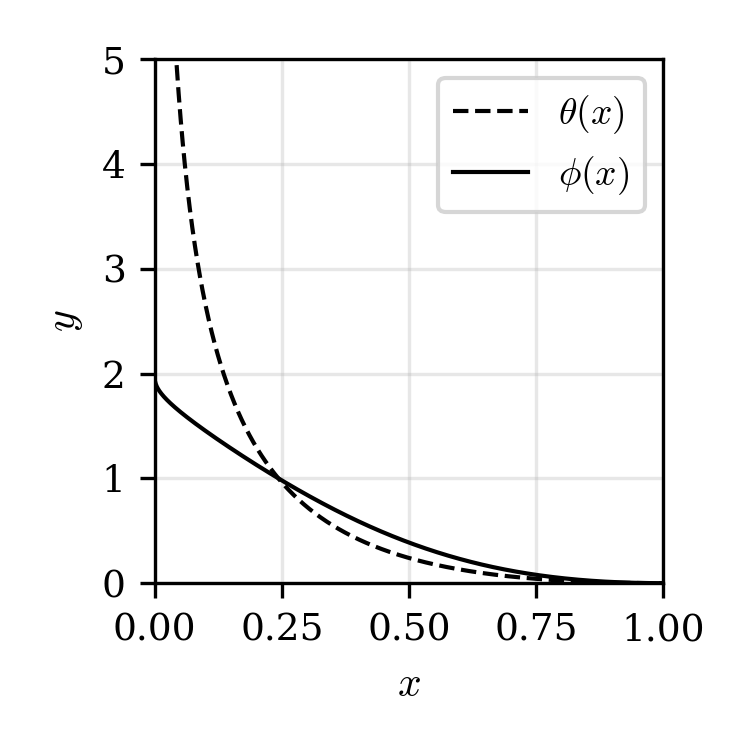
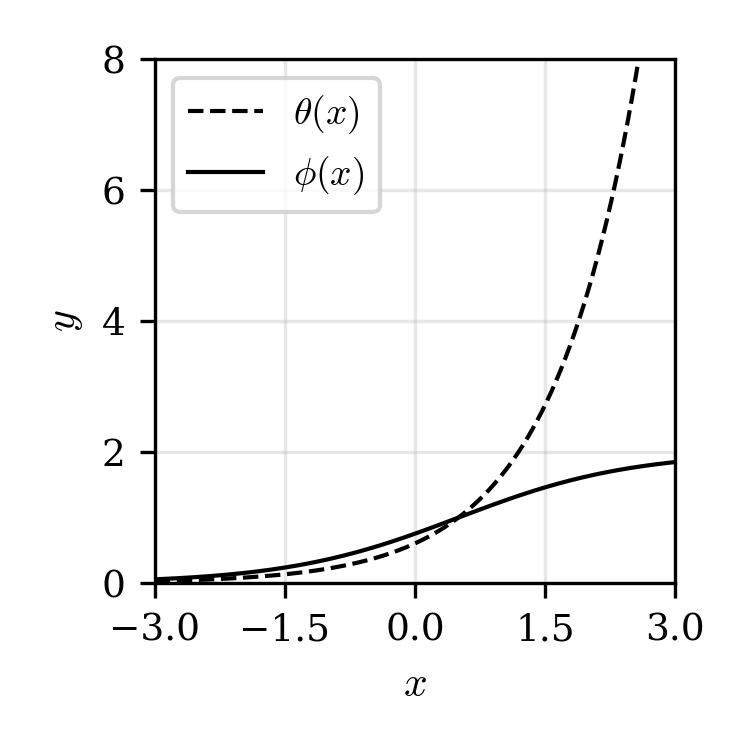
Figure 1: The standard density ratio Q2 (unbounded) and the relative density ratio Q3 (bounded) for illustrative pairs of Q4, Q5.
Proposed Three-Step Estimation Procedure
The paper proposes a robust three-step estimator for Q6:
- Relative Ratio Estimation: Use empirical kernel mean matching to estimate the bounded relative ratio Q7 in RKHS.
- Truncation: Apply lower and upper truncation to the estimate, ensuring Q8 remains in a feasible interval.
- Recovery Step: Transform the truncated estimate back to the original scale to obtain an estimator Q9 for the unbounded density ratio.
This approach enables stable kernel methods to estimate θ0 even when the true ratio is unbounded.
Statistical Guarantees and Algorithmic Framework
Assumptions
- The density ratio θ1 possesses finite θ2-th moment with respect to θ3 (θ4).
- The regression function and relative ratio both satisfy standard source conditions (smoothness/qualification) with respect to the chosen kernel and mixture/target measure.
Main Results
- Relative Ratio Estimation: The estimator θ5 achieves optimal non-asymptotic minimax rates in θ6. The key rate for θ7 unlabeled samples is θ8 where θ9 quantifies regularity.
- Density Ratio Recovery: The error in (xi,yi)0 translates to the error in (xi,yi)1 (in an (xi,yi)2 sense), with an additional dependence on the truncation parameter (xi,yi)3 and moment (xi,yi)4 of (xi,yi)5.
- Regression under Covariate Shift: When (xi,yi)6 are (xi,yi)7 labeled samples and (xi,yi)8 unlabeled samples ((xi,yi)9), the kernel ridge regression (KRR) solution using estimated importance weights PX×Y0 enjoys non-asymptotic high-probability convergence rates in both the RKHS and PX×Y1 norms. Near-optimal rates are possible as long as PX×Y2 grows polynomially in PX×Y3.
These theorems precisely quantify how the estimation of an unbounded importance function cascades into the excess risk for target distribution regression.
Methodological and Theoretical Insights
- Implicit Debiasing: By operating in the "relative" space, the method regularizes the ill-posedness, but then must control for the bias introduced by truncation and the nonlinear recovery step.
- Sample Complexity: Achieving minimax-optimal convergence rates for the target regression function is contingent upon the unlabeled sample size scaling polynomially with the labeled sample size, highlighting the intrinsic difficulty of density ratio estimation relative to regression under covariate shift.
- Spectral Algorithm Generalization: The analysis encompasses KRR as a special case but applies broadly to general spectral regularization algorithms, allowing flexibility in practical implementation.
Comparison to Prior Work
Earlier works on density ratio estimation are typically restricted to bounded ratios or implicitly regularize by enforcing boundedness in RKHS estimators. Classifier-based and neural methods exist for unbounded ratios, but theoretical support is often limited to parametric settings or expectation-based (not concentration) guarantees. Recent algorithms which use truncation schemes either lack precise characterization of the bias or rely on increasingly complex function classes (e.g., local Hölder).
In contrast, this work's relative ratio framework and full non-asymptotic analysis show that unbounded ratios can be robustly and efficiently estimated via this translation–truncation–recovery pipeline, yielding high-probability risk bounds.
Practical and Theoretical Implications
- Practicality: The method enables kernel-based covariate shift regression even in the presence of heavy-tailed or sharply peaked PX×Y4 ratios—scenarios prevalent in NLP, genomics, climate modeling, and other domains with significant label shift.
- Theory: The optimality statements extend classical learning theory to the unbounded ratio regime and inform the design of robust adaptation strategies in underdetermined limits.
Limitations and Directions for Future Research
- Misspecification: The theoretical analysis requires that the regression function lies within the RKHS. Future work should consider the case PX×Y5 (model misspecification).
- Sharper Capacity Measures: By leveraging notions such as effective dimension or embedding index, it may be possible to obtain sharper minimax rates.
- Debiasing: Addressing the accumulative bias from regularization, truncation, and the nonlinear transformation could further improve performance and suggest new estimation strategies.
Conclusion
This paper provides a principled, statistically sound methodology for unbounded density ratio estimation, enabling effective covariate shift adaptation with rigorous non-asymptotic guarantees. The approach—via relative ratio estimation and careful transfer of error bounds—overcomes longstanding obstacles in applying importance weighting under realistic, heavy-tailed regimes. The quantified relationship between sample complexity and convergence elucidates the fundamental gap between importance weight estimation and regression, providing actionable guidance for data collection and methodological choices in transfer learning.
Reference
- "Unbounded Density Ratio Estimation and Its Application to Covariate Shift Adaptation" (2603.29725)