- The paper presents a novel random circuit generator that controls width, depth, and density to mimic real benchmark distributions.
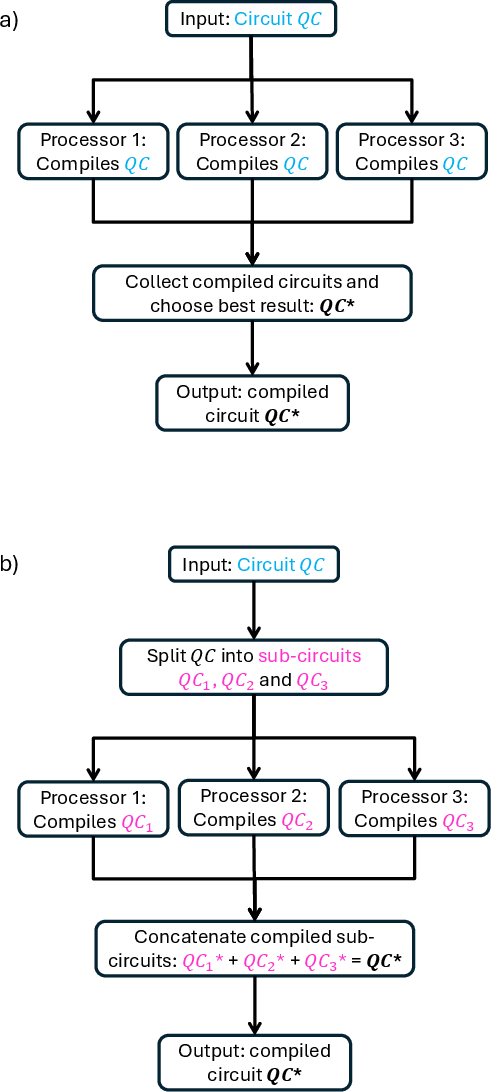
- It introduces a parallel compilation approach by decomposing circuits into temporally ordered sub-circuits with minimal SWAP overhead.
- Experimental results demonstrate up to 19.8× speedup and negligible overhead, confirming the method's scalability across different compilers.
Efficient Parallel Compilation and Profiling of Quantum Circuits at Large Scales
Motivation and Problem Statement
Quantum circuit compilation has become an acute bottleneck for practical quantum computation. As circuit sizes grow—both in qubit width and gate depth—the time required for compilation often exceeds simulation and even hardware execution, especially for circuits containing >100 qubits or >100,000 gates. Scaling to millions of qubits and gates, as projected for future quantum hardware, is infeasible under current compiler designs. The lack of sufficiently large circuit benchmarks and random circuit generators that can model realistic density characteristics further impedes empirical studies of compilation performance.
Existing benchmark suites (e.g., QASMBench, MQTBench, Red Queen) offer limited variety and scale; only a small subset feature deep and wide circuits simultaneously. Moreover, density, a key determinant of compilation cost, is rarely matched by random generators which typically saturate circuits to 100% density—a scenario unrepresentative of hand-crafted algorithmic circuits. There is thus a critical need for scalable circuit generators and robust parallelisation strategies applicable across compilers and routing algorithms.
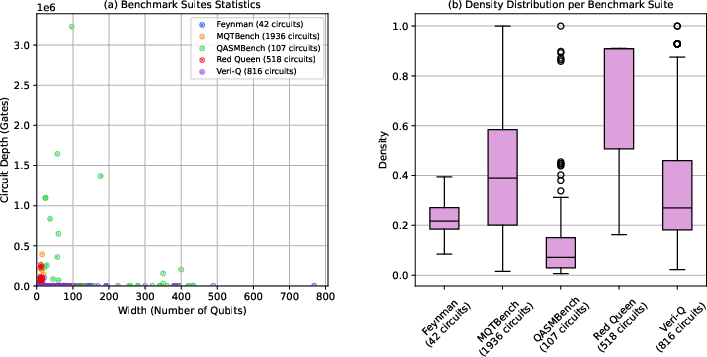
Figure 1: a) Scatter chart illustrating the depth and width statistics for 5 benchmark suites with gate density. b) Box plot illustrating the density distribution of the 5 benchmark suites.
Random Circuit Generation with Controlled Density
The paper introduces a random circuit generator capable of controlling width, depth, and density parameters. Density (d), defined as d=depth×widthnq1+2nq2, is regulated post-generation via probabilistic gate removal, ensuring generated circuits mimic the density distributions observed in benchmark libraries (typically <60%). The generator thus enables systematic production of circuits up to 200 qubits and with >16 million gates—substantially exceeding prior empirical limits and facilitating comprehensive compiler profiling.
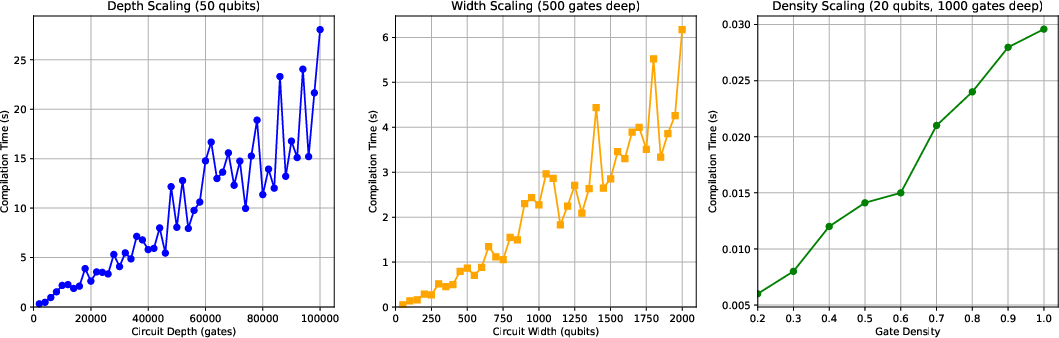
Figure 2: Compilation times for quantum circuits of varying depth, width, and gate density.
Parallelisation Approach and Algorithmic Design
Compilation is dominated by qubit routing, an NP-Complete problem exacerbated by nearest-neighbor constraints in realistic hardware layouts (e.g., IBM Melbourne, linear or grid topologies). The proposed parallelisation methodology operates by decomposing a circuit into temporally ordered sub-circuits, each compiled independently in parallel, followed by the insertion of permutation circuits to realign qubit mappings before re-concatenation.
Key attributes:
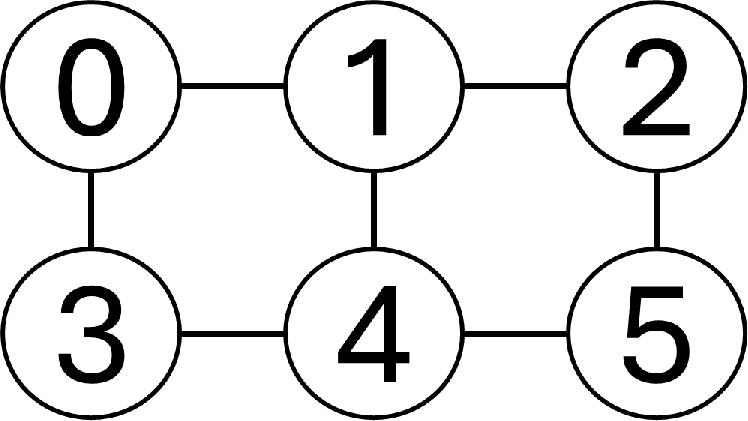
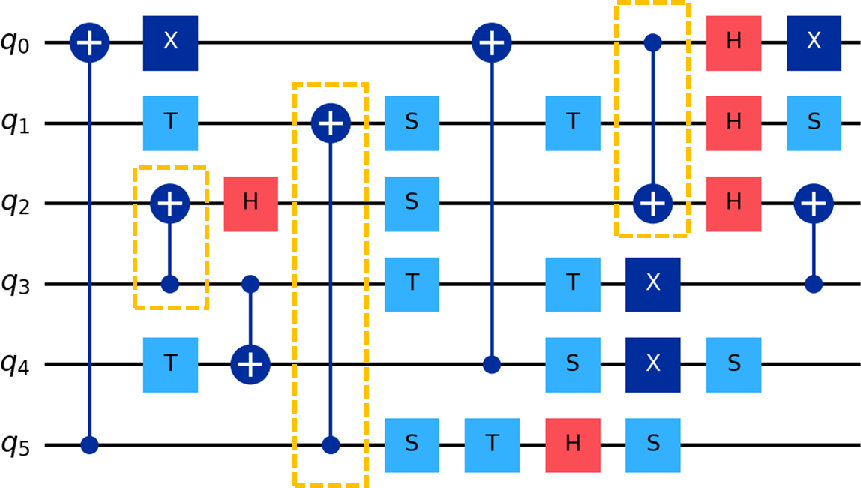
Figure 4: Example six-qubit circuit showing 2-qubit gates incompatible with processor topology (orange outline).
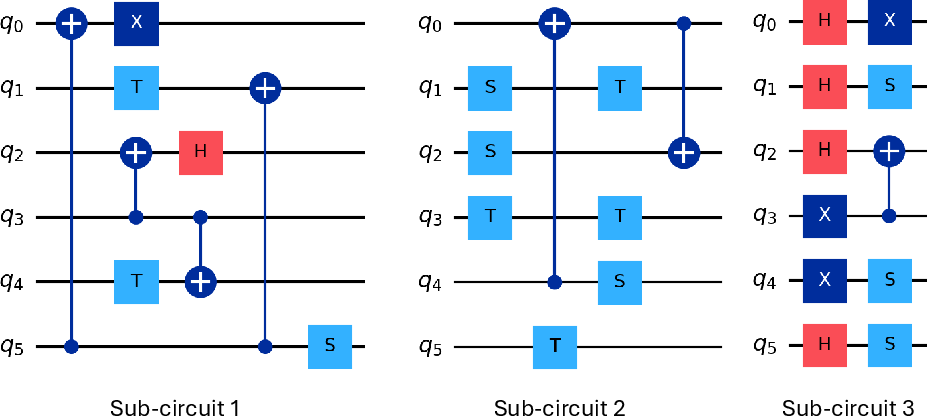
Figure 5: Sub-circuit decomposition of the example circuit, each with trivial initial qubit orderings.
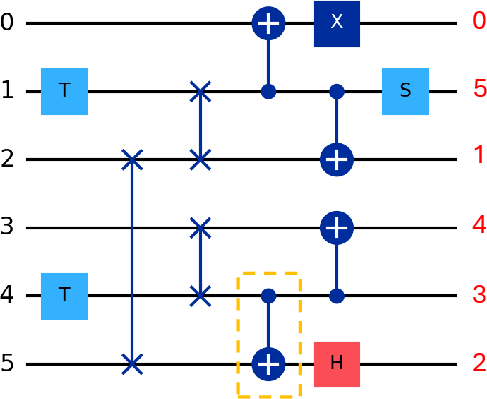
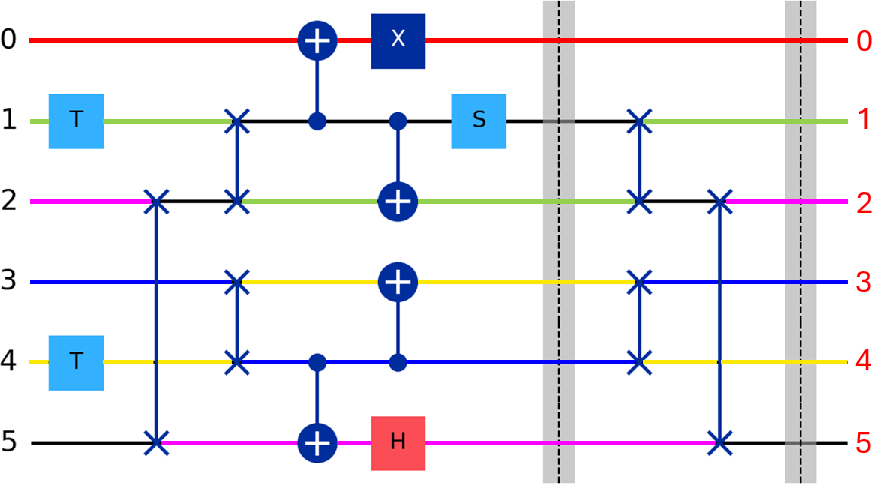
Figure 6: Compiled sub-circuit with SWAP insertion to enable NNA compliance; CNOT gates highlighted.
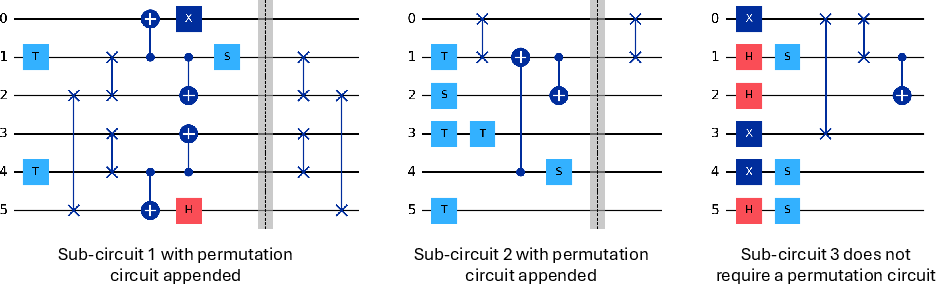
Figure 7: Compiled sub-circuits with permutation circuits appended (SWAP gates). Barriers mark permutation circuit boundaries.
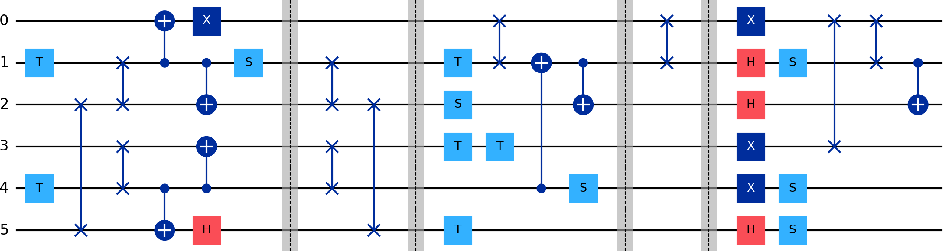
Figure 8: Final concatenated compiled circuit, including SWAP gates and permutation segments.
Experimental Evaluation
Qiskit (SabreSwap, BasicSwap) Results
- Compiled 400 circuits spanning 20–200 qubits, 10k–100k gates, densities of 20–100%.
- Peak speedup for SabreSwap reached 12.95 on 16 cores for high-density, deep circuits; BasicSwap peaked at 15.56.
- Gate, SWAP, and depth overheads remain minimal: typically <1% (e.g., 0.2% gate overhead, 0.25% SWAP, 0.85% depth for SabreSwap).
- For low-density circuits and benchmarks, peak speedup is reduced, reflecting limited parallelism scope.
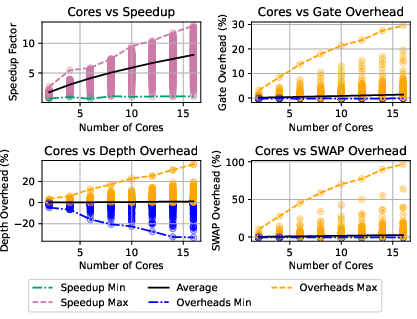
Figure 9: Speedup and overhead variation with number of processors for random circuits using SabreSwap.
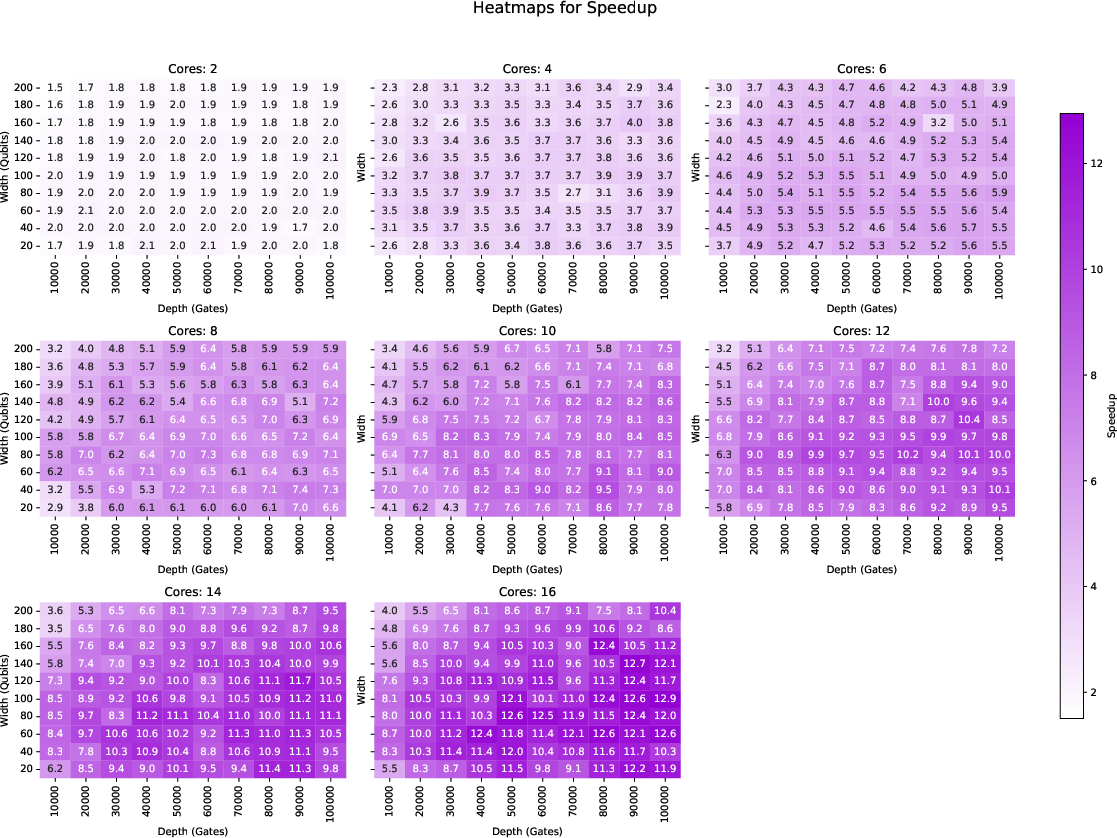
Figure 10: Speedup heat maps for 100% density random circuits using SabreSwap.
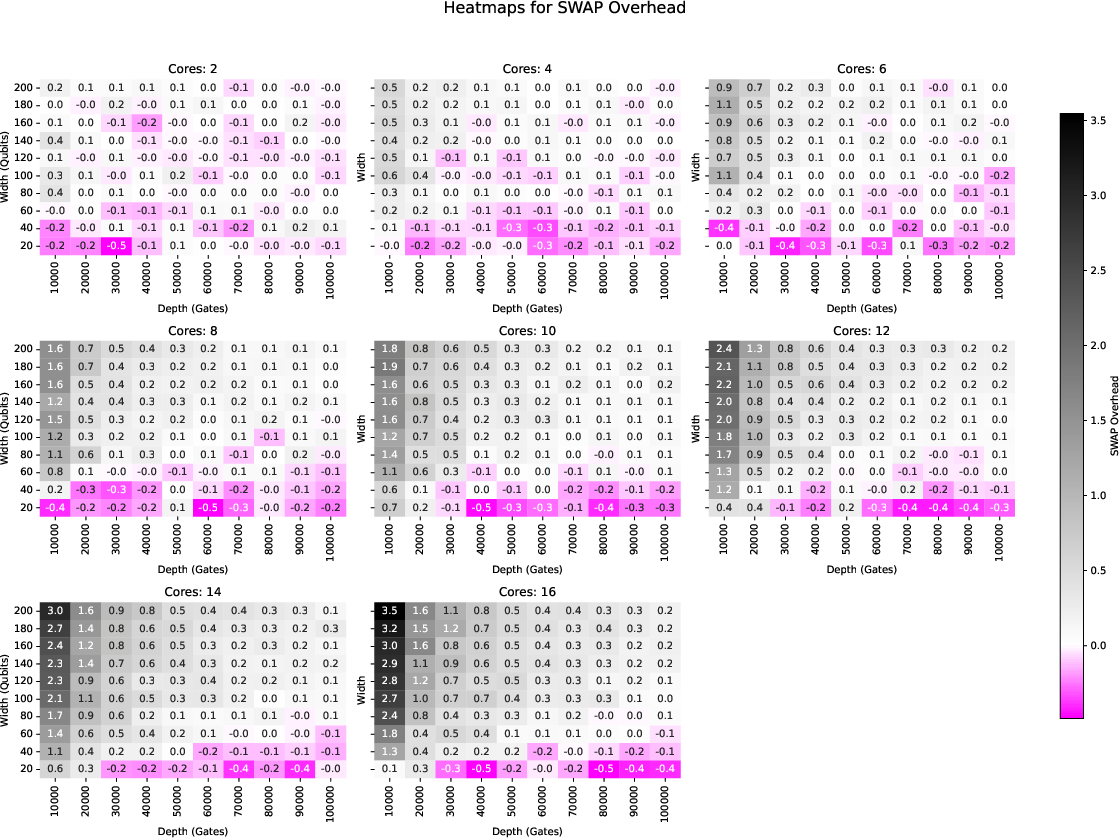
Figure 11: SWAP overhead heat maps for 100% density random circuits using SabreSwap.
Compiler and Routing Algorithm Effects
- PyTKET routing (RoutingPass) achieves peak speedup of 19.8 for dense, deep circuits; overheads remain negligible (<0.25%).
- Speedup is strongly correlated with circuit depth and density; width correlation is weaker due to depth reduction post-decomposition.
- Cross-compiler results are consistent; parallelisation is robust to compiler improvements and topology variations (grid and linear).
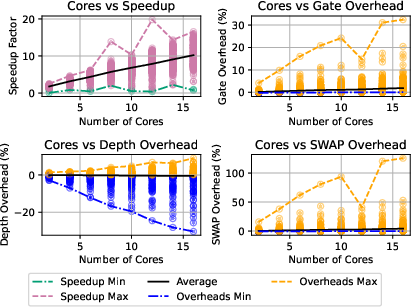
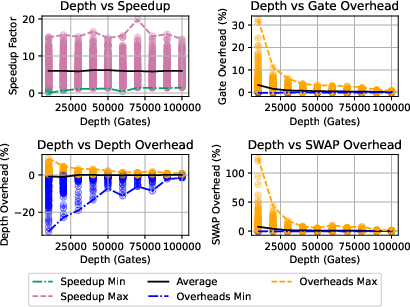
Figure 12: Speedup and overhead cost variation with processors for random circuits compiled using PyTKET.
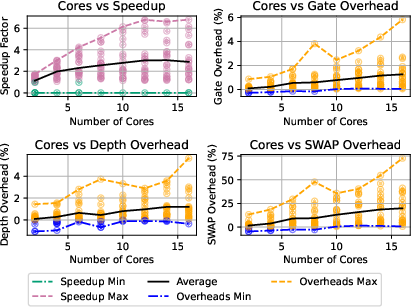
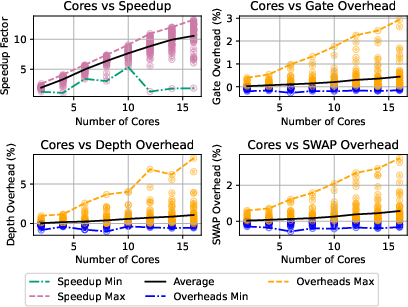
Figure 13: Speedup and overhead cost variation with processors for benchmark circuits compiled using PyTKET.
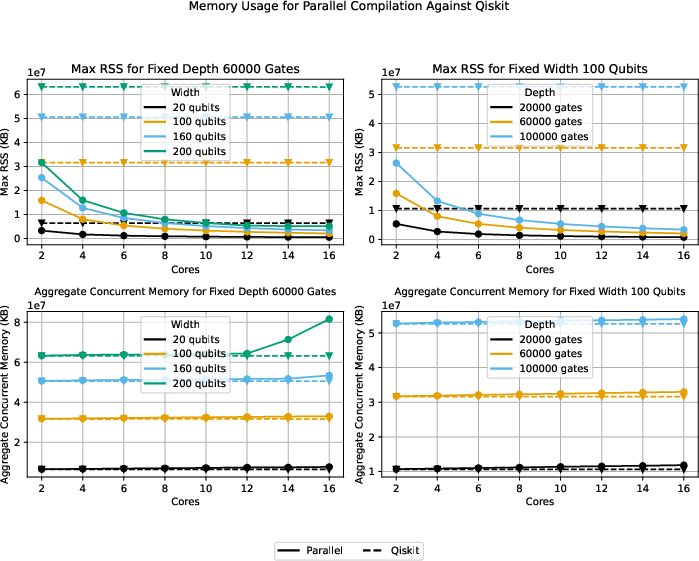
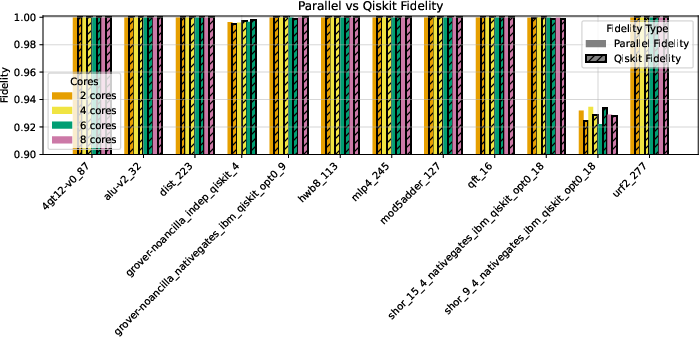
Additional Analysis: Memory, Fidelity, and Practical Constraints
Implications and Future Directions
The presented methodology addresses two practical limitations in quantum compilation at scale: empirical benchmarking (via controlled random circuit generation) and accelerated compilation (via effective parallelisation). The demonstrated speedups, negligible overheads, and compiler-agnostic applicability have direct implications for hybrid quantum-classical workflows, near-term NISQ execution pipelines, and large-scale circuit simulation.
Theoretical implications span scalable quantum software engineering, distributed circuit design, and optimal resource allocation models. Immediate future directions include:
- Auto-calibration of parallel sub-circuit quantity based on circuit physical attributes.
- Load balancing refinement using multi-qubit gate statistics.
- Integration with distributed quantum computing frameworks and topology-aware optimisers.
Emerging quantum hardware with multi-core architectures and large memory pools will benefit substantially from these techniques. The generator's extensibility to mimic algorithmic circuit structure (e.g., Shor, Grover) is a promising avenue for more realistic profiling.
Conclusion
This work systematically resolves both the benchmarking and compilation bottleneck for large-scale quantum circuits. The generator enables unprecedented empirical circuit profiling. The parallel compilation approach achieves significant acceleration across compilers and routing algorithms with minimal overhead, up to 19.8× speedup for real-world circuit scales. Memory and fidelity analyses indicate robust practical applicability. Future research should focus on optimal load balancing, deeper integration with quantum distributed computing, and enhancing random circuit generators to more precisely emulate structured algorithm outputs.
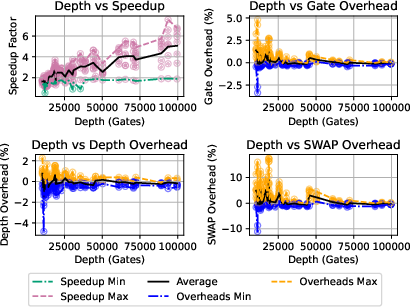
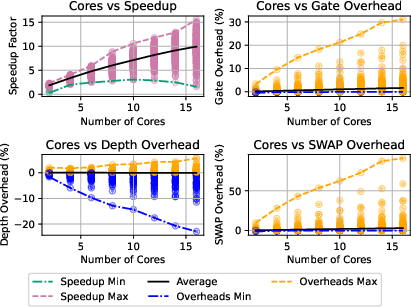
Figure 16: Speedup and overhead cost variation with benchmark circuit depth using SabreSwap.
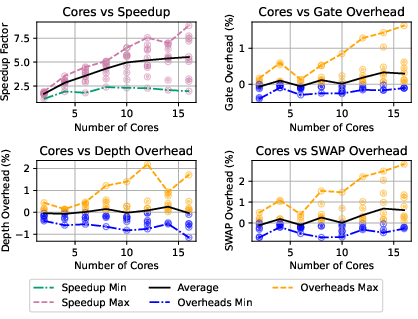
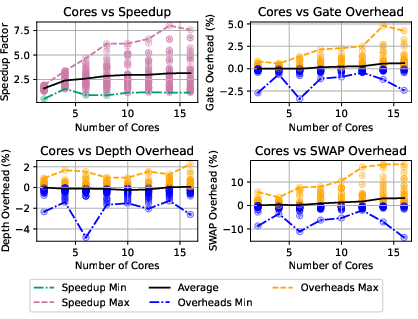
Figure 17: Speedup and overheads for 20-qubit randomly-generated circuits at 20% density.