- The paper introduces a parameter-free writer adaptation framework that leverages multimodal in-context learning to tackle inter-writer variability in HTR.
- It employs a compact CNN-Transformer network with a Context-Aware Tokenizer to condition predictions on contextual handwriting data, achieving state-of-the-art error rates.
- The method enables scalable, inference-time adaptation without gradient updates, reducing computational overhead and making deployment practical in low-resource scenarios.
Few-shot Writer Adaptation via Multimodal In-Context Learning
Introduction
Handwritten Text Recognition (HTR) remains challenged by high inter-writer variability, particularly for writers with idiosyncratic styles underrepresented in training corpora. Existing writer adaptation techniques—ranging from data augmentation to supervised fine-tuning and test-time adaptation—often require parameter-intensive inference procedures, such as gradient-based optimization with Masked Autoencoder (MAE) objectives. "Few-shot Writer Adaptation via Multimodal In-Context Learning" (2603.29450) addresses this challenge by developing a fully parameter-free adaptation framework, using only a few support examples per writer as multimodal context for adaptation at inference time.
Writer Adaptation in HTR: Background and Limitations
Prior strategies for adaptive HTR generally fall into three categories:
- Training-Time Generalization: Augmentation and synthetic data generation techniques, such as font-based rendering and generative models, expand the style distribution but face domain gaps and diminishing returns as the number of unique styles grows.
- Offline Fine-Tuning: Fine-tuning on labeled samples from a target writer improves performance but risks overfitting and entails potentially prohibitive annotation/compute costs.
- Inference-Time Adaptation: Gradient-based adaptation via MAE or explicit style representation methods allows quick per-writer specialization, but these approaches impose significant memory/compute overhead and require meticulous hyperparameter tuning, particularly in balancing recognition and reconstruction losses.
The limitations of MAE-based adaptation are especially pronounced: the disconnect between the reconstruction objective and true character disambiguation, as well as complex interdependencies between various adaptation hyperparameters, undermine robustness and interpretability.
Multimodal In-Context Learning for Writer Adaptation
The proposed framework draws from recent advances in Multimodal In-Context Learning (MICL), where large vision-LLMs (VLMs) are prompted with multimodal input-output pairs and adapt to new tasks by leveraging in-context examples, without any parameter updates during inference. This model bridges the gap between robust visual grounding and context-sensitive adaptation by using a compact (8M parameter) CNN-Transformer network tailored for context-driven inference in HTR.
Upon receiving a query line from a target writer, the model is provided with up to nine context lines (along with their transcriptions) from the same writer. The architecture's salient components are:
- Context-Aware Tokenizer (CAT): Generates a context-dependent encoding by assigning relative position tokens to unique characters within the context.
- CNN Visual Encoder: Processes composite context and query images, retaining spatial fidelity via 2D sinusoidal positional encoding.
- Transformer Decoder: Attends over both the visual sequence and the encoded context tokens, autoregressively outputting token sequences for the query.
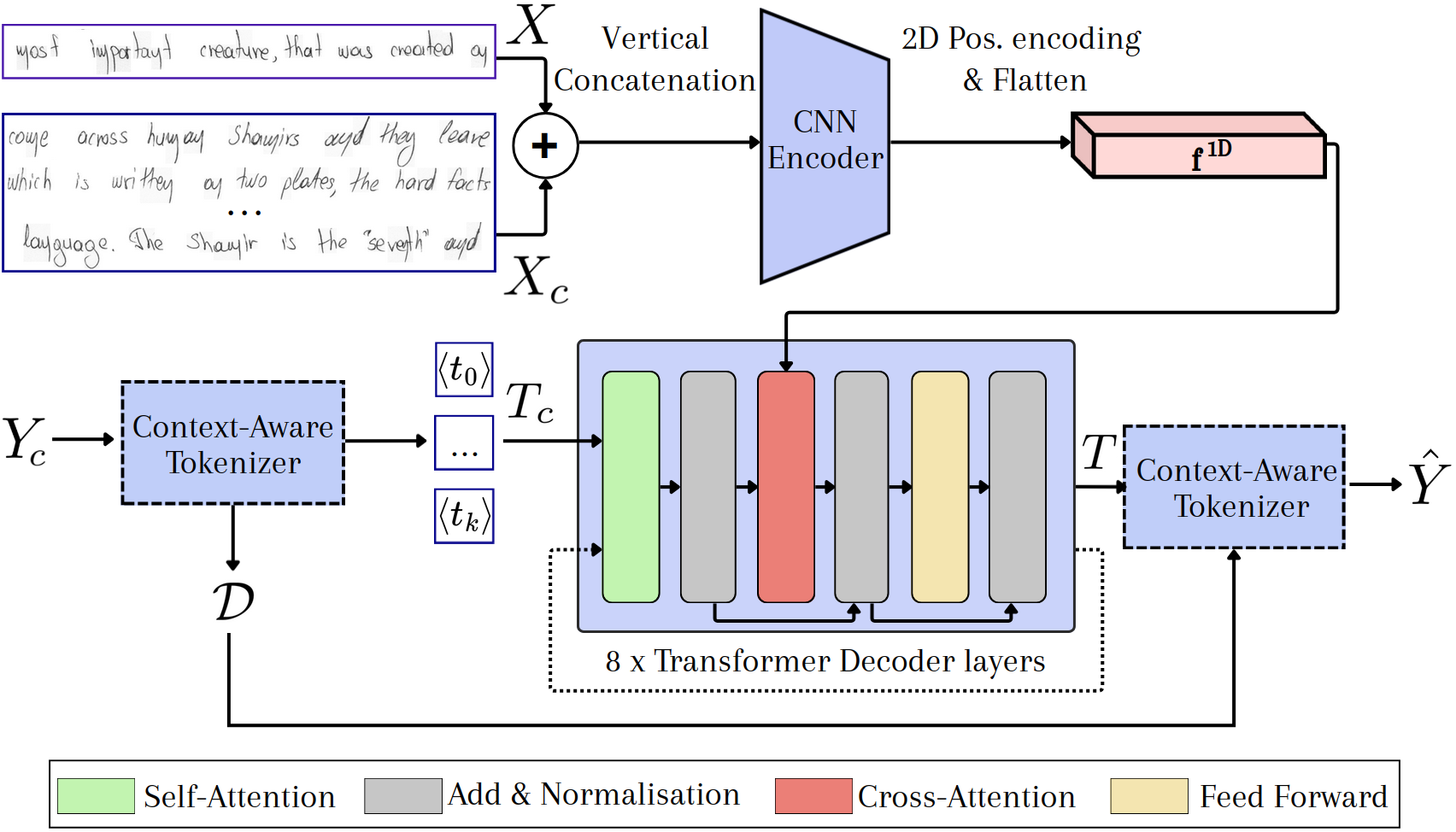
Figure 1: A schematic of the context-driven architecture, comprising the Context-Aware Tokenizer, CNN visual encoder, and Transformer decoder.
By conditioning prediction on the context, the model resolves character ambiguities endemic to atypical handwriting, without explicit parameter adjustments.
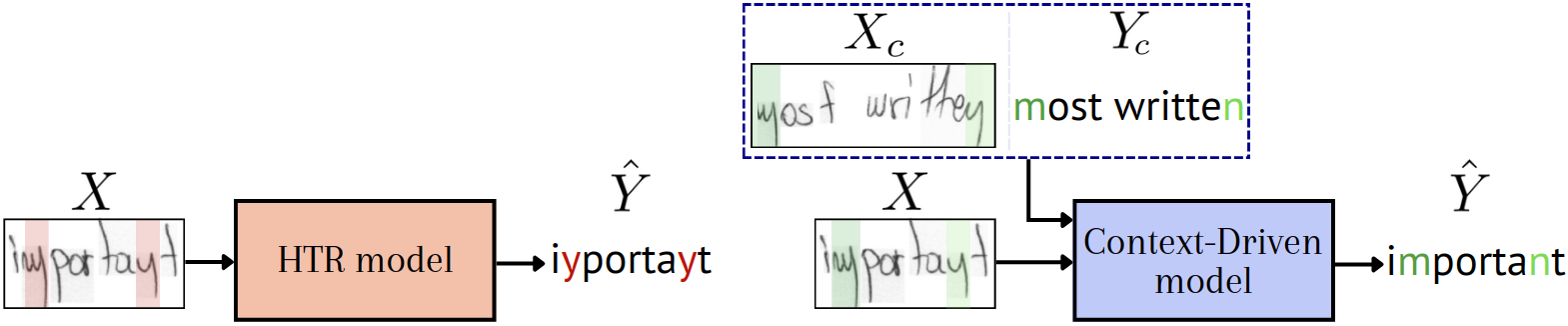
Figure 2: In-context support lines enable the model to internalize and disambiguate writer-specific shape patterns, significantly reducing recognition errors.
Training Protocol and Regularization
A progressive curriculum is used both for visual complexity and context length. Initial training phases use printed synthetic fonts to bootstrap pattern association, gradually ramping up the ratio of real handwritten data. Context length is similarly increased over time, facilitating adaptation to long-range context dependencies.
To simulate real-world conditions and bolster resilience, noise is injected during teacher forcing (via token corruption and group-level replacements), forcing the model to robustly leverage context, even under partial or noisy supervision.
Complementarity and Fusion with Standard OCR
While context-driven adaptation excels for writers whose styles are idiosyncratic or sparsely covered in the training set, traditional OCR models remain strong for styles well-captured by pretraining. The paper demonstrates the complementary nature of both strategies. Confidence-based late fusion—where aligned predictions from both models are scored and selectively adopted—yields superior error rates, as confirmed by thorough ablation.
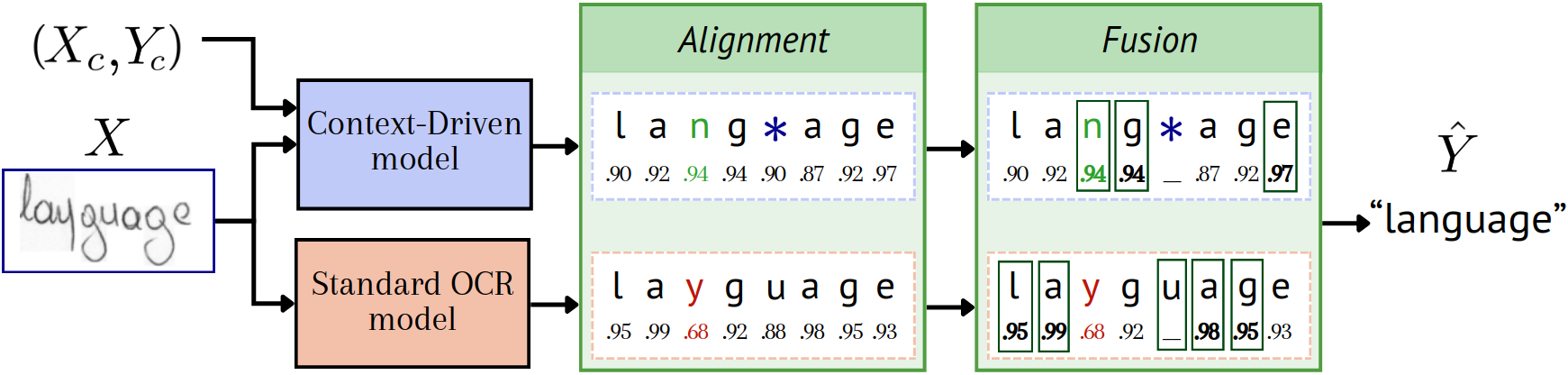
Figure 3: Confidence-based fusion aligns and merges predictions from context-driven and standard OCR models at the character level using dynamic programming.
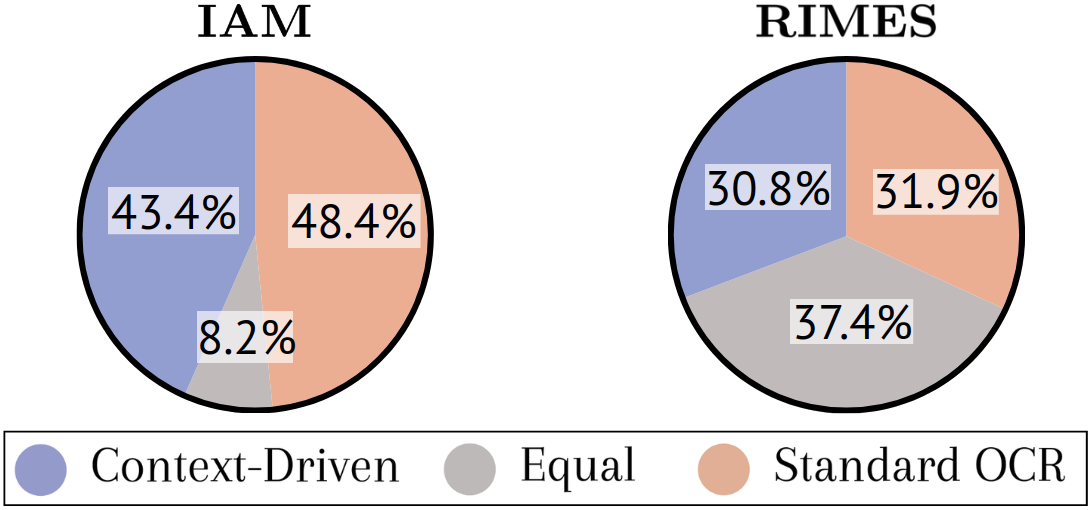
Figure 4: Percentage of writers benefiting most from context-driven, standard OCR, or equal performance, with the fusion approach revealing substantial complementarity.

Figure 5: Qualitative examples on challenging samples, showing context-driven adaptation correcting misclassifications from baseline OCR.
Empirical Results
The approach is rigorously evaluated on IAM and RIMES, two demanding, writer-annotated benchmarks. Results yield the following notable claims:
- State-of-the-art character error rates among parameter-free adaptation methods: 3.92% on IAM and 2.34% on RIMES.
- Consistent improvement with increasing context size: Even two context lines noticeably reduce error, and nine lines provide near-exhaustive query character coverage and maximal performance gains.
- Complementary strengths: On a substantial subset of writers, fusion of models outperforms either alone (see Figure 4).
Compared with parameterized adaptation methods (e.g., MAE or meta-learning approaches), the method matches or exceeds performance for parameter-free adaptation, and approaches the best reported results for MAE-based writer adaptation, without the additional computational burden.
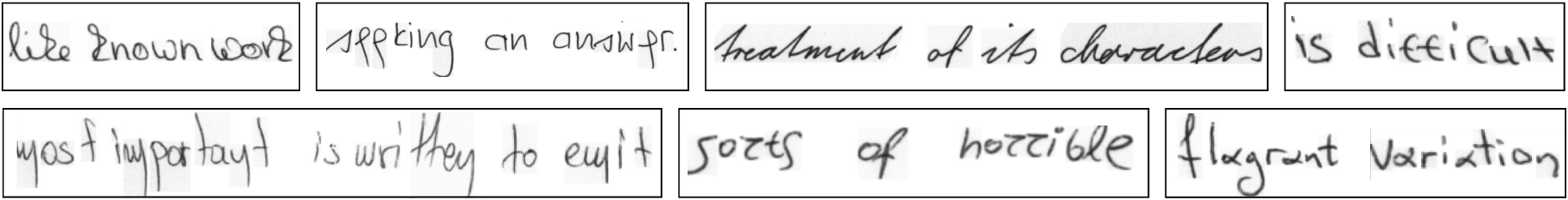
Figure 6: Illustration of the high inter-writer variation present in the dataset, motivating the necessity of robust adaptation.
Theoretical and Practical Implications
This context-driven approach offers three major theoretical advances:
- Explicit adaptation mechanism: Adaptation is grounded in direct visual-token alignment from context, eschewing latent style embeddings or self-supervised reconstruction.
- Parameter-agnostic adaptation: No gradient computation, optimizer state, or retraining is needed at inference, making the system modular and lightweight.
- Flexibility and scalability: The model operates effectively with as few as two context lines and demonstrates strong scaling with additional context, making it viable in realistic, low-data scenarios.
Practically, this paradigm considerably lowers barriers for deploying robust writer adaptation in production systems. Acquiring a handful of annotated lines per writer is far more feasible than massive retraining/fine-tuning cycles, or online model updating, especially when compute/memory budgets are constrained.
Limitations and Future Directions
The necessity for labeled context transcriptions at inference remains a constraint, though the labeling burden is vastly lower than in classic adaptation scenarios. Future directions include:
- Self-supervised or weakly supervised context selection: Leveraging unlabeled examples via semi-supervised learning or self-training for context construction.
- Dynamic context sampling or weighting: Optimizing context choice for maximal disambiguation, perhaps by automatically selecting lines with the highest coverage or shape diversity.
- Hybridization with LLMs: While the late fusion is visual-evidence centric and deliberately omits linguistic priors, further gains may be possible by incorporating LM-derived constraints in the fusion protocol.
Conclusion
This work establishes a compact, interpretable, and robust pipeline for few-shot writer adaptation in HTR via multimodal in-context learning, eliminating the need for test-time updates. The empirical and theoretical analyses confirm that strong writer adaptation is attainable with a simple, parameter-free, and highly scalable mechanism conditioned on multimodal context. This paradigm is positioned to influence future developments in practical, low-resource, and adaptive HTR systems in both research and industry.