- The paper presents an extrinsic-aware cross-attention mechanism that directly aligns native image patches with 3D point groups to overcome geometric distortions in calibration.
- It employs an iterative refinement process over three steps to decouple rotation and translation, significantly reducing errors on benchmarks like KITTI and nuScenes.
- The study demonstrates that harmonic positional encoding and decoupled aggregation are key to overcoming limitations of traditional projection-based methods.
Native-Domain Cross-Attention for Robust Camera–LiDAR Extrinsic Calibration
Introduction
Accurate camera–LiDAR extrinsic calibration remains a critical challenge for safety-critical perception in autonomous driving. Traditional learning-based methods often exhibit significant performance degradation when confronted with substantial initialization errors, largely attributable to their reliance on depth maps generated by projecting LiDAR points into the image plane. This operation inherently causes geometric distortion and occludes out-of-frame data, resulting in weak cross-modal feature correspondence, especially under large misalignments. The paper "Native-Domain Cross-Attention for Camera-LiDAR Extrinsic Calibration Under Large Initial Perturbations" (2603.29414) presents a targeted solution to this fundamental limitation by proposing an extrinsic-aware cross-attention framework that operates directly on native image patches and 3D point groups, circumventing the pitfalls of depth projection.
Limitations of Prior Work
Conventional end-to-end camera–LiDAR calibration pipelines construct 2D depth maps from 3D LiDAR points as the intermediate space for feature fusion. The depth map computation is intrinsically dependent on a noisy initial extrinsic guess. When this guess is erroneous—frequent in dynamic, deployed vehicles—projection includes out-of-frame point dropout and structure distortion, which severely impairs the subsequent neural feature fusion and regression stages for accurate calibration.
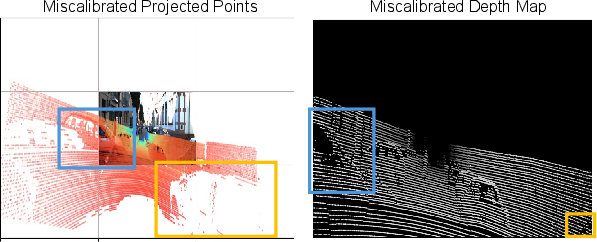
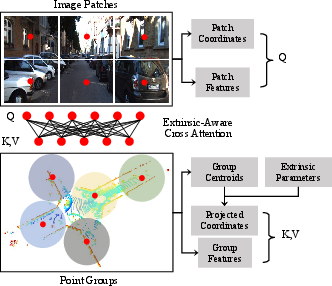
Figure 1: The extrinsic miscalibration problem—(a) Depth maps from misaligned extrinsics exhibit incomplete/distorted geometric structures; (b) The proposed framework fuses directly in native domains via extrinsic-aware cross-attention, preserving geometric integrity.
Methodology
The authors introduce a cross-modal attention mechanism explicitly conditioned on extrinsic hypotheses to align camera and LiDAR data in their native 2D and 3D domains, respectively. This approach, combined with cross-modal coordinate alignment and harmonic positional embedding, overcomes the key hurdles faced by earlier architectures and allows robust calibration even from highly perturbed initializations.
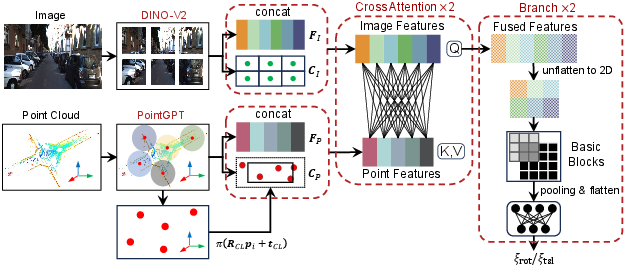
Figure 2: Network architecture—Image patches and point groups are encoded separately, followed by extrinsic-aware cross-attention and aggregation branches for decoupled rotation/translation regression.
Native-Domain Encoding and Cross-Attention
- Image Encoding: Patch-based encoding using DINOv2 ViT produces strong semantic features.
- Point Encoding: Local 3D point groups are extracted via FPS and kNN, embedded with PointNet- and transformer-based feature hierarchies.
- Extrinsic-Aware Cross-Attention: Instead of concatenating preprojected data, the module injects extrinsic parameter hypotheses, aligning native camera pixels and point groups through an image-plane-based positional embedding using learnable harmonics across multiple frequencies, reminiscent of NeRF spatial encoding.
- Coordinate Alignment: 3D points are projected (parametrically) using the calibration hypothesis but preserved outside the image extent (using a controlled margin), removing the field-of-view bottleneck.
- Bi-branch Aggregation: Rotation and translation are decoupled early and processed through independent aggregation and regression heads to avoid entanglement and encourage specialized feature selection.
Iterative Refinement
The network is unrolled for three iterative steps, taking each predicted extrinsic as the subsequent initialization, improving accuracy and convergence from severe initial perturbations.
Experimental Validation
The authors conduct rigorous quantitative and qualitative evaluation on KITTI and nuScenes, using three initialization regimes (up to 10∘ rotation and $50$ cm translation).
Notably, methods relying on precomputed depth maps (CalibNet, RGGNet, LCCNet, CalibFormer, etc.) consistently fail to recover reasonable extrinsics as initialization worsens, exhibiting low success rates (<10%) and high RMSEs, substantiating the bottleneck of 2D projection-based fusion.
Ablation and Analysis
Comprehensive ablations show:
- Replacing harmonic with simple concatenation or non-harmonic positional encoding markedly degrades all calibration metrics.
- Removing the projection margin (i.e., forcibly filtering out-of-frame points) sharply reduces translation accuracy and success, indicating cross-modal FOV expansion is a necessary ingredient for robustness.
- Decoupled aggregation for rotation/translation is essential; entangling these in feature space worsens both RMSE and success probability.
- Using strong image and point domain encoders (DINOv2, PointGPT) further improves cross-attentional fusion efficacy.
Theoretical and Practical Implications
The work establishes two foundational claims:
- Depth map fusion constitutes a geometric bottleneck in sensor calibration, especially under substantial misalignment, and cannot be rescued by deeper architectures or attention alone if the encoding space is distorted.
- Conditioning cross-modal attention on extrinsic hypotheses and positional alignment robustly enables consistent calibration regardless of initial parameter error or scene structure, making the method viable for real-world, online, and in-vehicle operations subject to perturbation and drift.
From a systems perspective, this design paradigm will likely enable practical, user-free calibration in dynamic autonomous vehicles, with direct extension to incremental or online settings and other cross-modal registration domains.
Future Directions
Potential research thrusts include integrating explicit geometric cues (edges, planes, object-level priors) into attention, expanding image-plane modeling for even broader FOV tolerance, or adapting the extrinsic-aware fusion concept to spatiotemporal or multi-sensor calibration scenarios.
Conclusion
The proposed native-domain cross-attention design decisively resolves core geometric limitations of previous camera–LiDAR calibration networks. It augments robustness and generalization in high-misalignment settings, confirmed via strong empirical performance across standard datasets. The extrinsic-aware cross-modal fusion mechanism is broadly relevant for robust multi-sensor alignment, setting a rigorous standard for future end-to-end calibration systems in autonomous sensing.
