- The paper presents an ILP-based, hardware-aware framework that automatically partitions DRL tasks across the Versal ACAP domains.
- It employs dynamic mixed-precision quantization using BF16, FP16, and FP32 to maintain convergence with reward errors below 5%.
- Empirical results demonstrate up to 4.17× speedup over baseline methods, highlighting improved throughput and scalability.
AP-DRL: Synergistic Algorithm-Hardware Task Partitioning for DRL Training on Versal ACAP
Introduction
The AP-DRL framework addresses the dual challenges of efficient deep reinforcement learning (DRL) training acceleration: algorithmic diversity and quantization sensitivity. The coupling in DRL between inference and training phases places stringent demands on hardware architectures. Conventional GPU/FPGAs are either underutilized for low-computation regimes or limited by clock frequency in high-FLOP scenarios, complicating platform selection. Additionally, DRL’s wide dynamic range exacerbates reward error under conventional FP16/FP32 quantization schemes.
AP-DRL leverages the heterogeneous AMD Versal ACAP platform, with CPUs, FPGAs, and AI Engines (AIE-ML), to construct a hardware/software co-designed automatic task partitioning and quantization optimization methodology. The system performs bottleneck analysis, profiling, and Integer Linear Programming (ILP)-based layer partitioning, aligned with hardware capabilities and computational properties, to optimize DRL training on Versal ACAP. Quantization is further refined by exploiting native BF16 support on AIE-ML, FP16 on PL/DSP, and full-precision FP32 on PS. Empirical results show AP-DRL achieves up to 4.17× speedup over PL and 3.82× over AIE baselines, with reward errors consistently below 5%.
Versal ACAP Architecture and DRL Algorithm Workflow
Versal ACAP (AI Edge series) comprises three main domains: Processing System (PS, dual-core Cortex–A72), Programmable Logic (PL, FPGAs with DSP and OCM), and AI Engine-Machine Learning (AIE-ML tiles). High-throughput AXI interfaces facilitate PS–PL and PL–AIE-ML communication, allowing flexible allocation of tasks. AIE-ML incorporates native BF16 support, crucial for DRL’s dynamic range preservation.
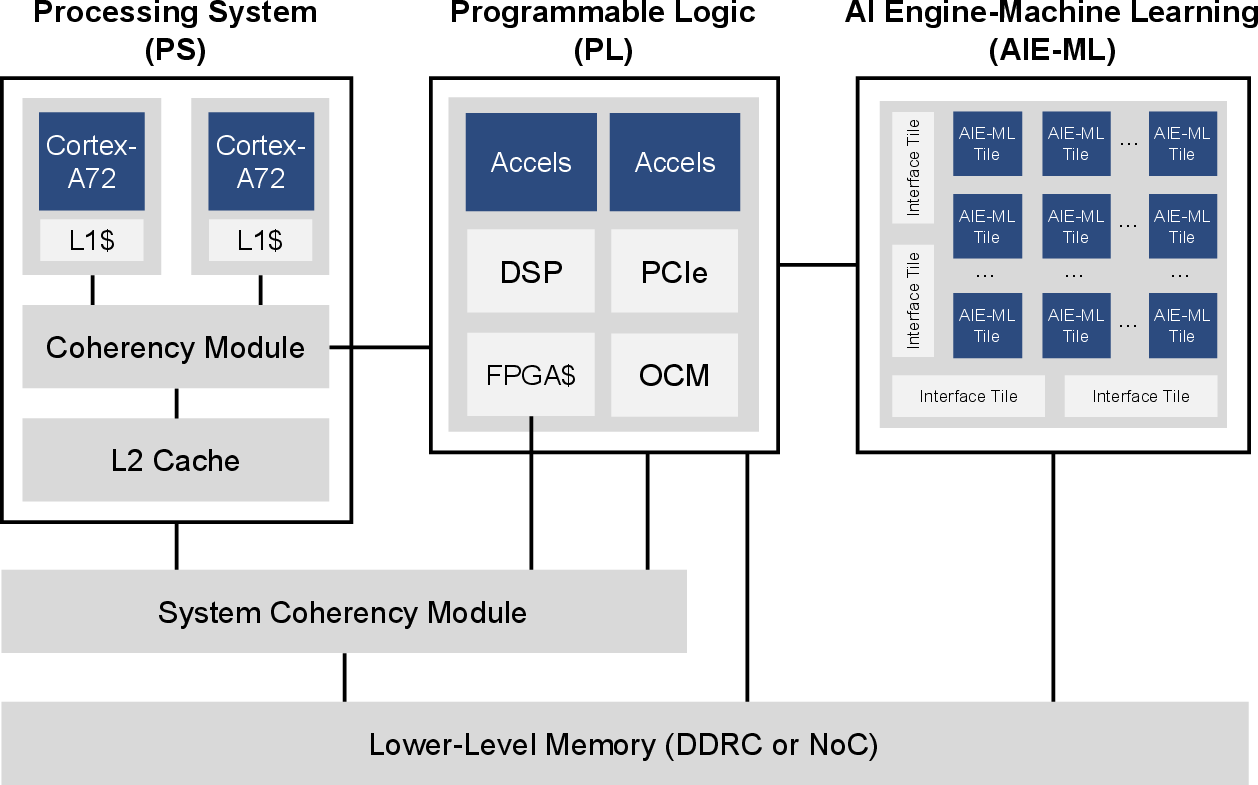
Figure 1: Versal ACAP (AI Edge series) architecture enables dynamic task allocation between PS, PL, and AIE-ML tiles, each supporting different precision formats and performance characteristics.
DRL is formulated as MDP (S,A,P,R,γ), where training tightly couples inference and environment steps with batch training dominating execution time. Acceleration requires co-optimization and fine-grained partitioning of forward/backward passes, typically represented as layers of matrix multiplications and nonlinear activations.
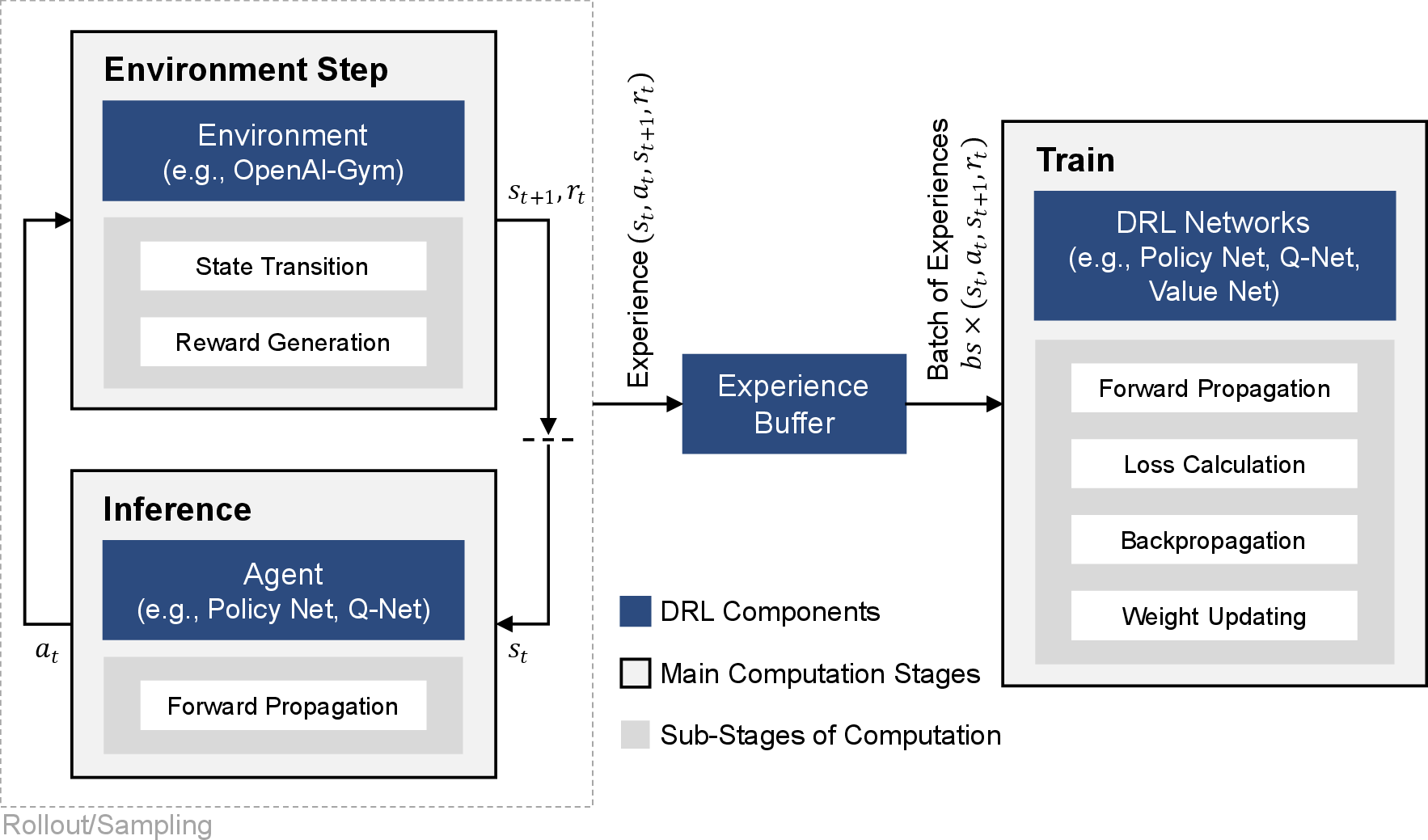
Figure 2: DRL algorithm workflow demonstrates the interleaved inference, environmental transitions, and training stages.
Extensive benchmarking across PS, PL, and AIE reveals disparities in execution under varying FLOPs:
- Low-FLOPs: PL outperforms due to lower initialization overhead.
- High-FLOPs: AIE-ML excels, driven by 1 GHz clock frequency.
- GEMM operations persist as major bottlenecks in both forward and backward passes.
Inter-component communication and initialization times vary and must be balanced against computation time to avoid performance losses. Layer-wise profiling in diverse network architectures (e.g., DQN-Breakout, DDPG-LunarCont) demonstrates substantial per-layer variation (4.10 KFLOPs to 10.61 MFLOPs), justifying partitioning at layer granularity.
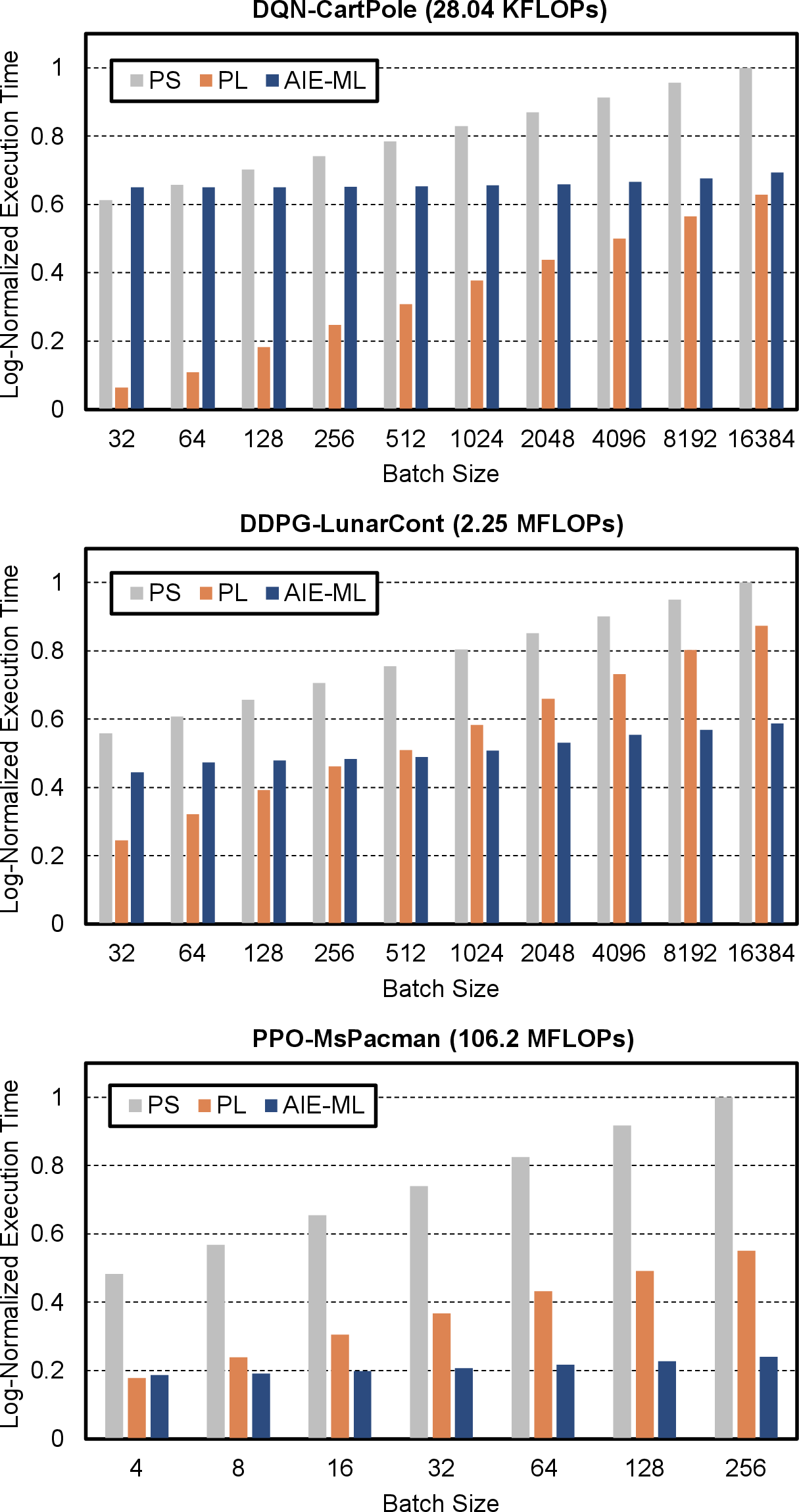
Figure 3: Log-normalized execution time of DRL training stages across PS, PL, and AIE-ML, profiled via Vitis Analyzer.
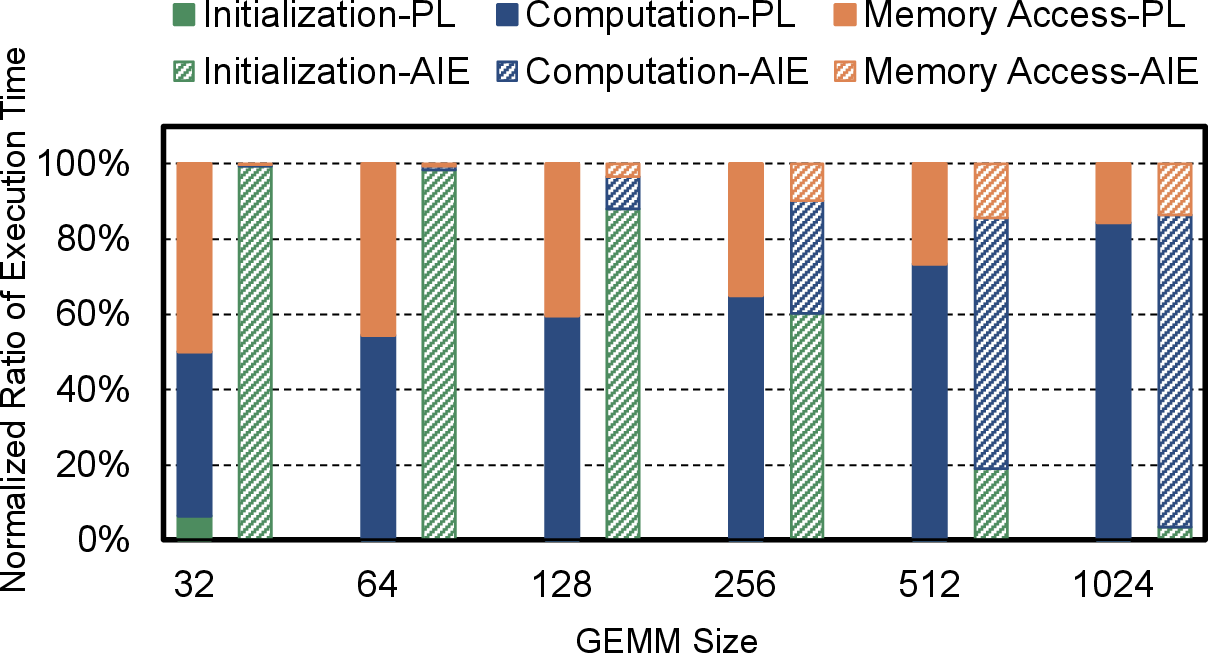
Figure 4: Execution time breakdown for GEMM operations on PL and AIE-ML, highlighting the effect of clock frequency and kernel launch overhead.
Framework Overview and Partitioning Methodology
AP-DRL consists of static (pre-deployment partitioning) and dynamic (runtime quantization) phases. C/C++ DRL specifications are lowered to LLVM IR, forming Control Data Flow Graphs (CDFGs) for ILP-based model partitioning. Layers are categorized as MM (matrix multiplication) or Non-MM nodes, profiled for resource utilization and execution latency using TAPCA and CHARM tools. ILP formulation balances parallelism, hardware resource constraints, and communication overhead, mapping layers to appropriate domains.
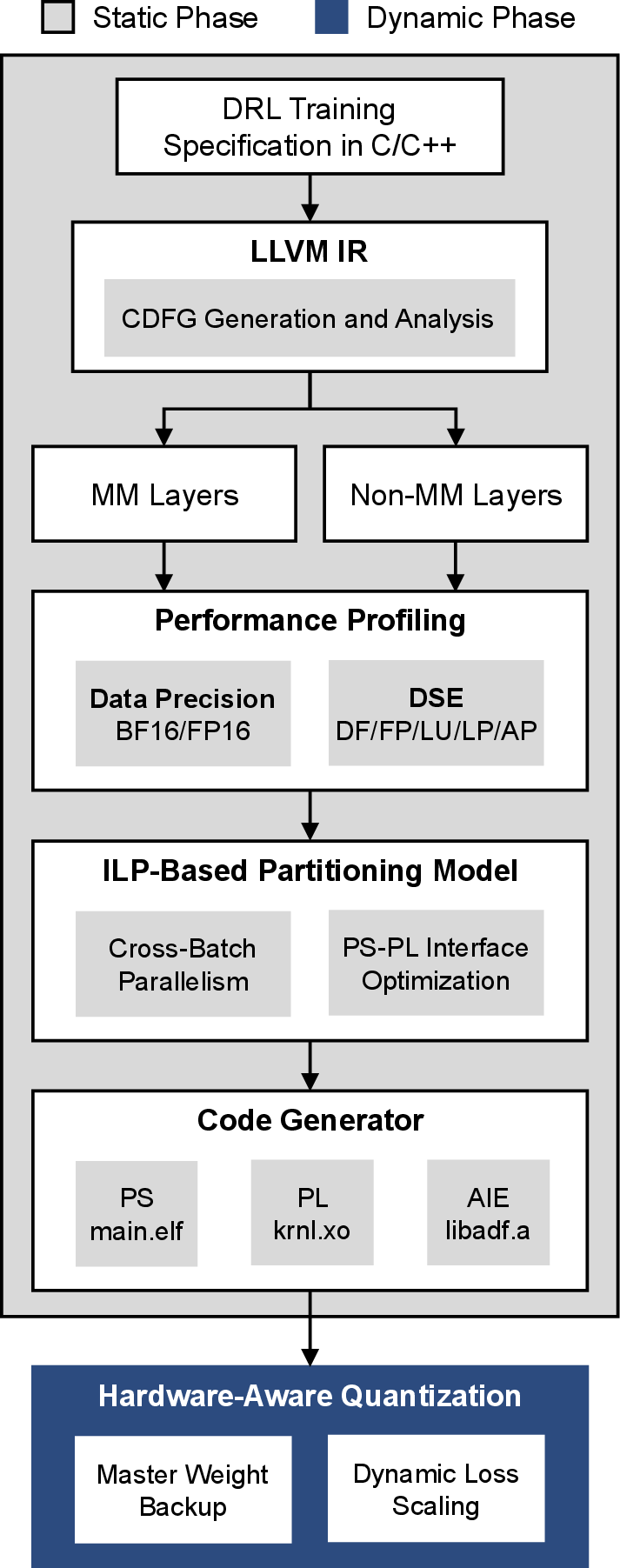
Figure 5: The AP-DRL framework organizes static and dynamic optimization phases for automatic partitioning and quantization.
Layer-wise partitioning is selected as the optimal granularity, informed by FLOP distribution and dependency analysis. TAPCA aids PL profiling, CHARM enables AIE-ML profiling, and memory interface configurations are optimized for data transfer.
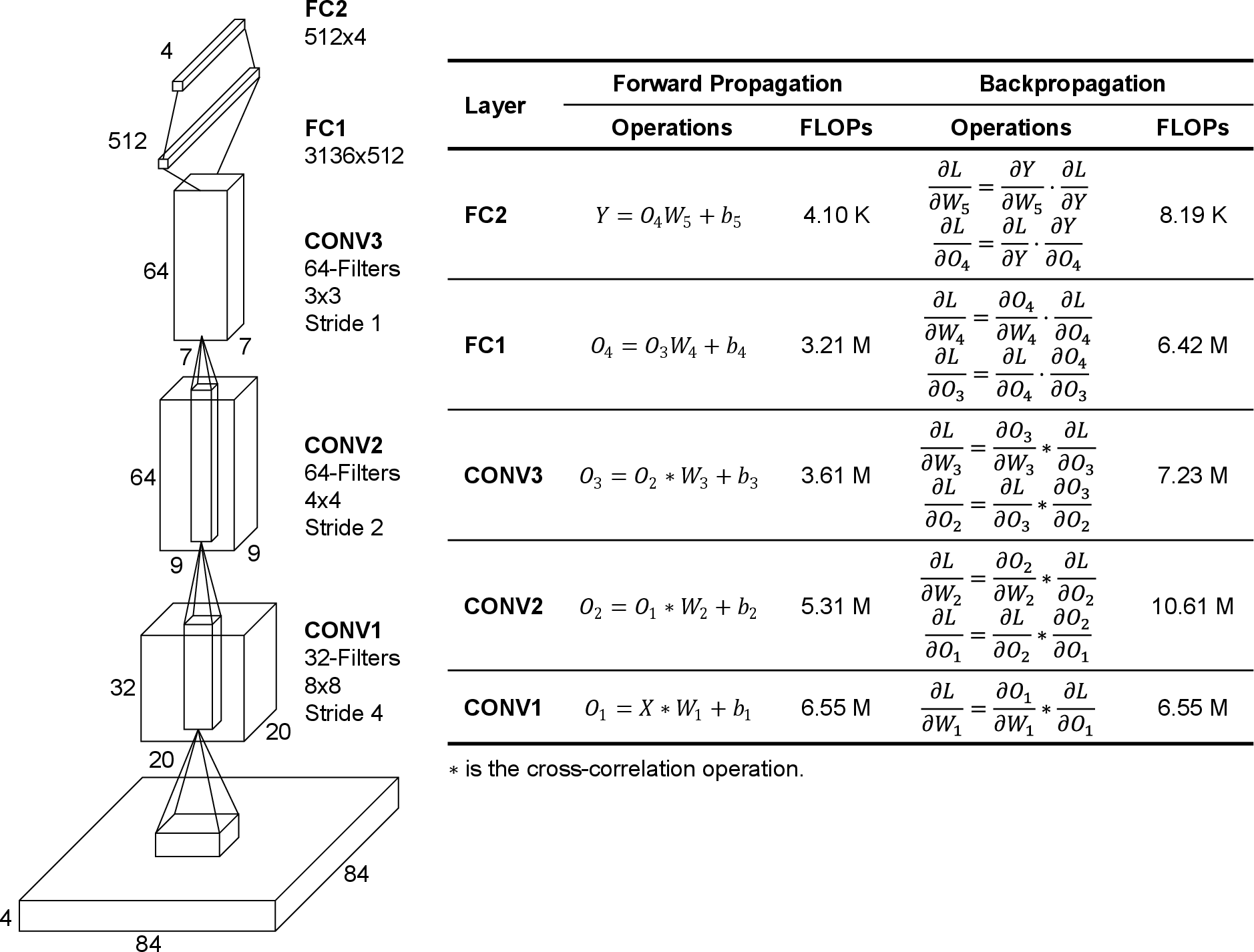
Figure 6: Detailed network architecture and FLOPs for DQN-Breakout environment forward/backward passes.
Hardware-Aware Quantization
Quantization-aware training for DRL presents unique challenges. BF16 retains FP32’s exponent range and avoids loss scaling/master weight backup overhead, addressing DRL sensitivity. FP16, with limited exponent width, requires backup and dynamic loss scaling to manage underflow/overflow.
AP-DRL implements a dynamic mixed-precision algorithm, assigning layers to domains based on profiling:
- AIE layers: BF16, no stabilization overhead.
- PL layers: FP16 + backup (BF16/FP32), dynamic loss scaling.
- PS layers: FP32.
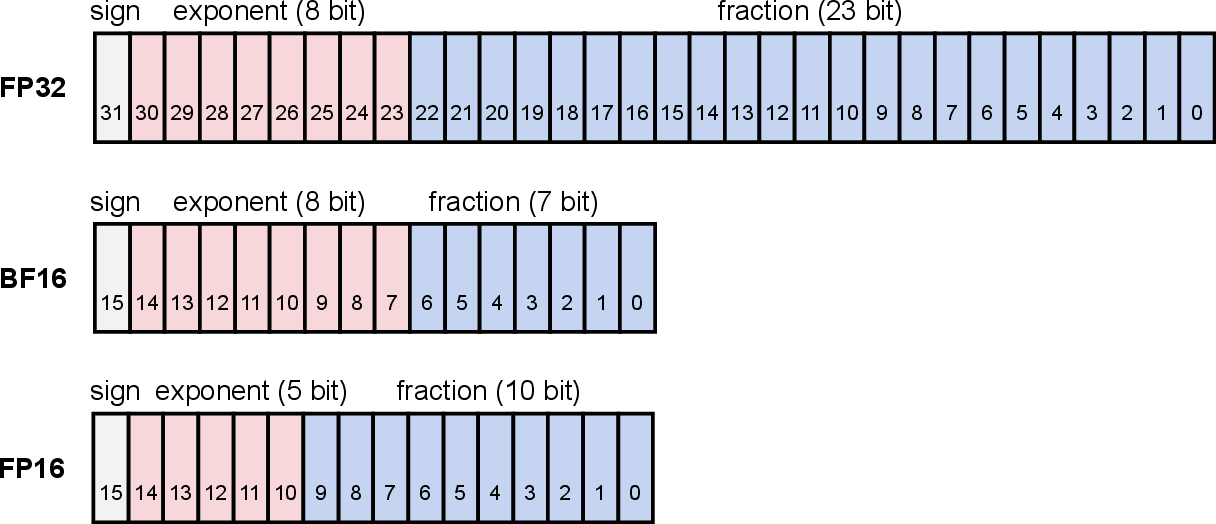
Figure 7: Binary format comparison for BF16, FP16, FP32, highlighting exponent and fraction bit distribution.
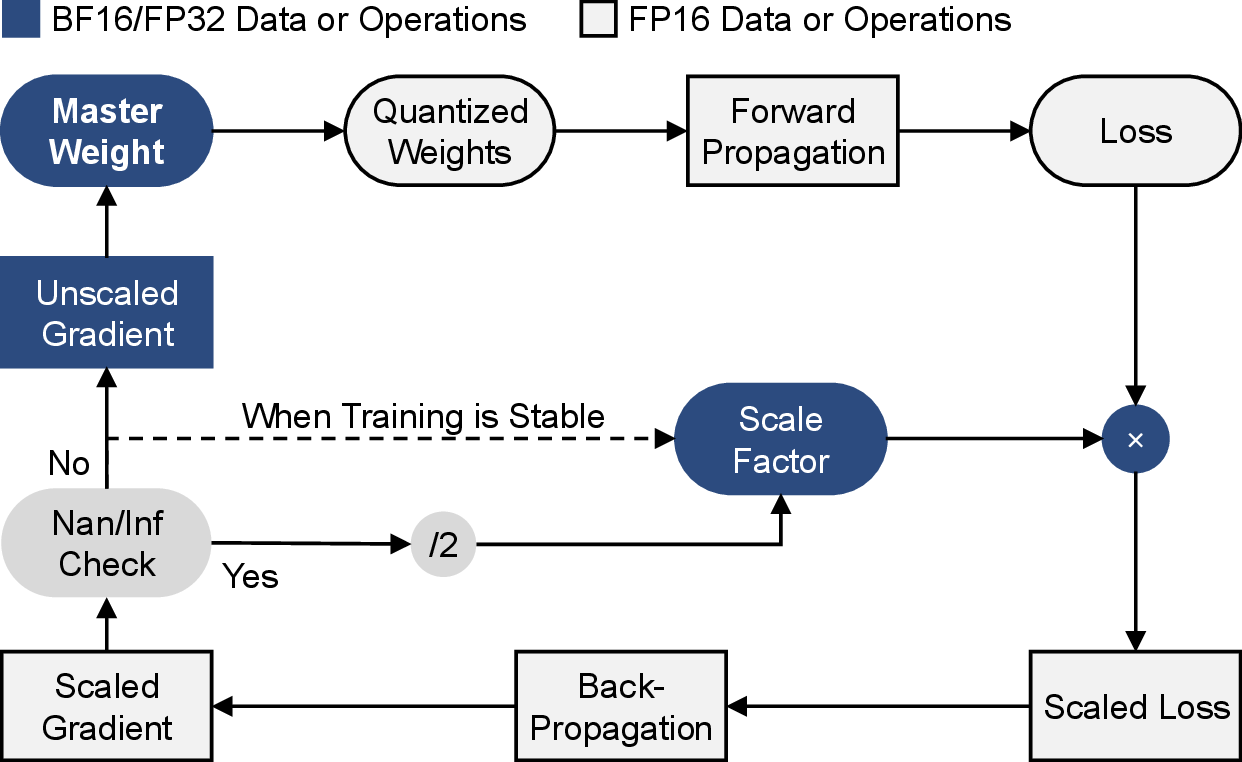
Figure 8: Mixed-precision training workflow integrating master weight backup and dynamic loss scaling.
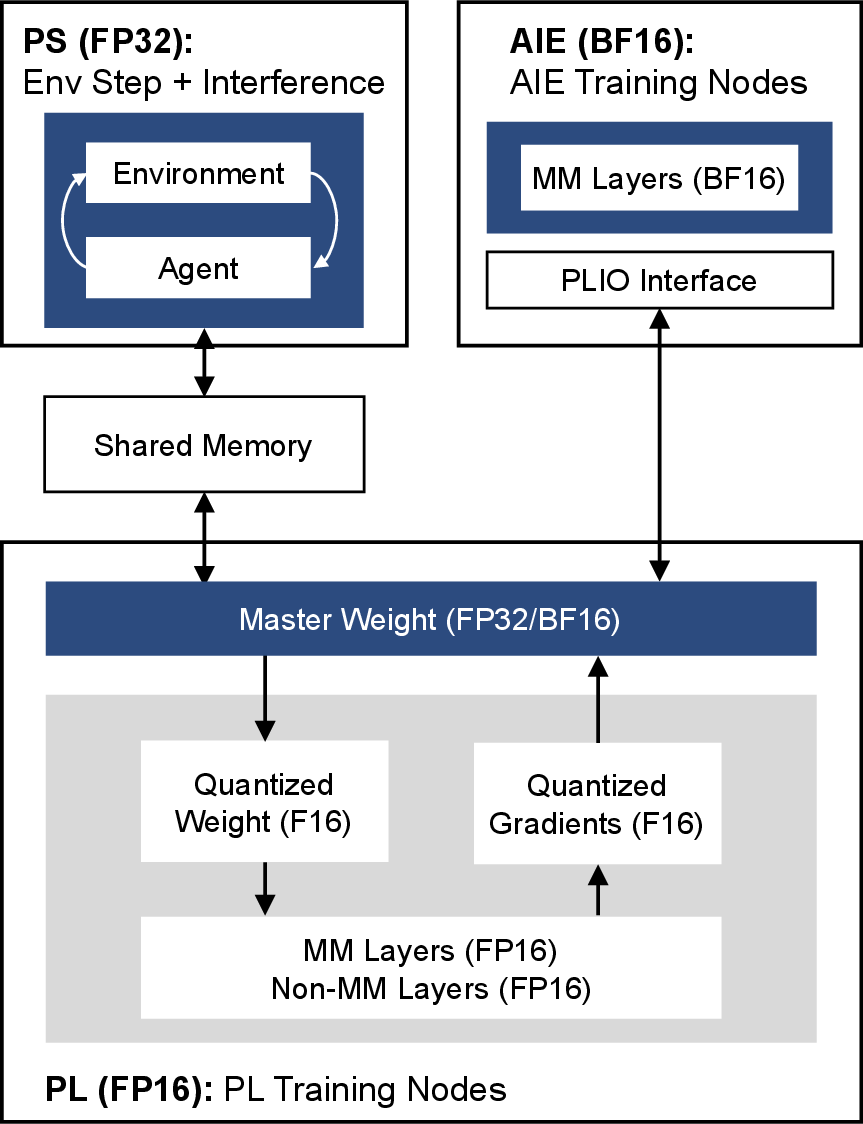
Figure 9: Hardware implementation details of the quantization algorithm on Versal ACAP.
Experimental Results
Benchmarks span Atari, OpenAI Gym, MuJoCo. Four DRL algorithms (DQN, DDPG, A2C, PPO) are evaluated across environments representing discrete and continuous action/state spaces. VEK280 hardware emulation is used.
Quantization effects: AP-DRL preserves model convergence, with reward errors up to 4.81%. Convergence rate is somewhat slower in models with pathological weight distributions, but overall stability is maintained.
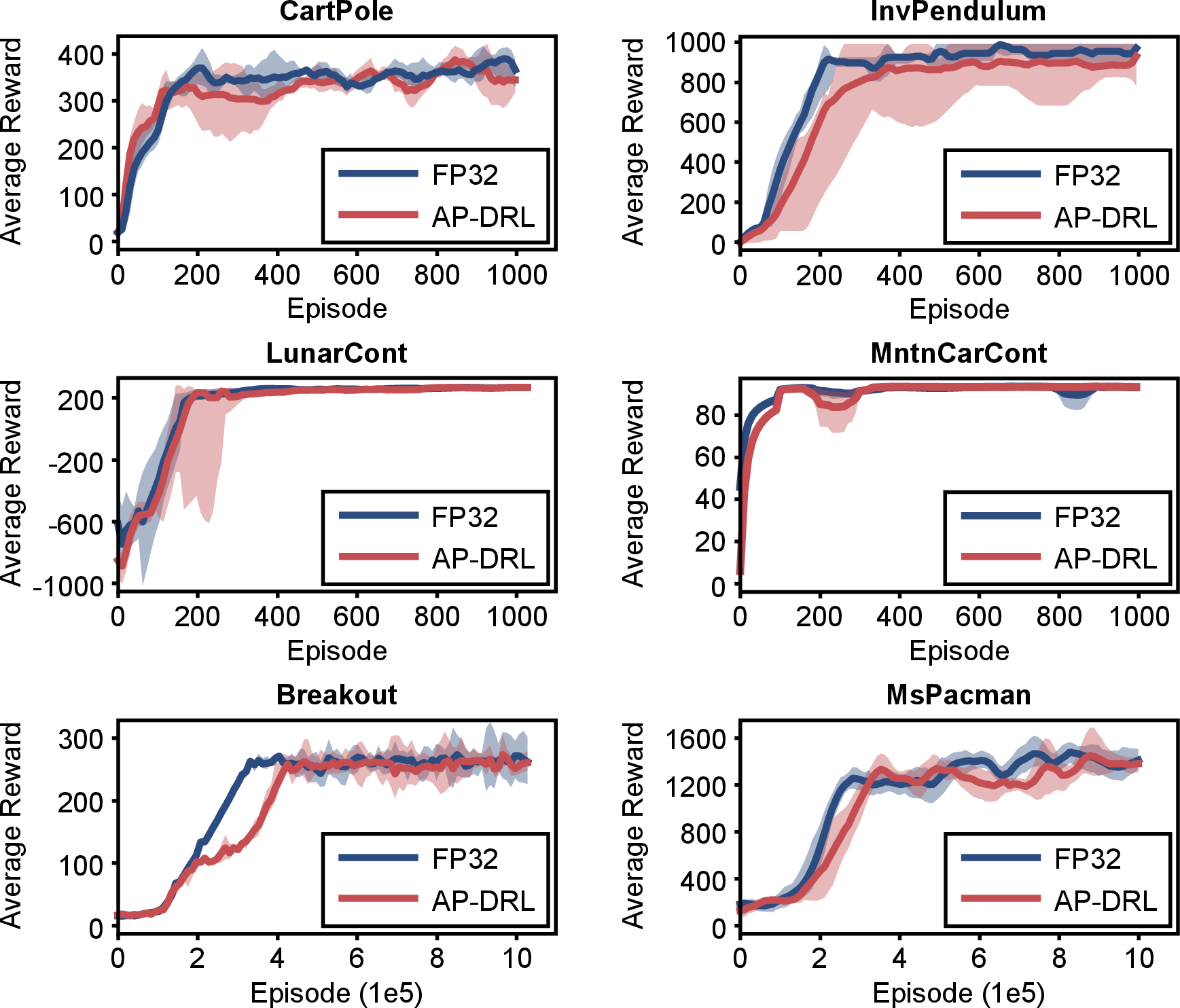
Figure 10: Convergence performance and average reward for AP-DRL quantized vs. FP32 implementations.
Training efficiency: Mixed-precision benefits scale with network size (FLOPs). Low-FLOP architectures suffer from synchronization overhead; high-FLOP architectures capitalize on BF16 hardware acceleration, yielding up to 2.98× speedup.
Partitioning acceleration: AP-DRL outperforms AIE-only and FIXAR baselines across tasks and batch sizes.
- Speedup grows with batch size and FLOPs, as more layers are allocated to AIE.
- AP-DRL avoids AIE initialization overhead in small tasks by leveraging PL.
- Consistent advantage in throughput and execution time across all task regimes.
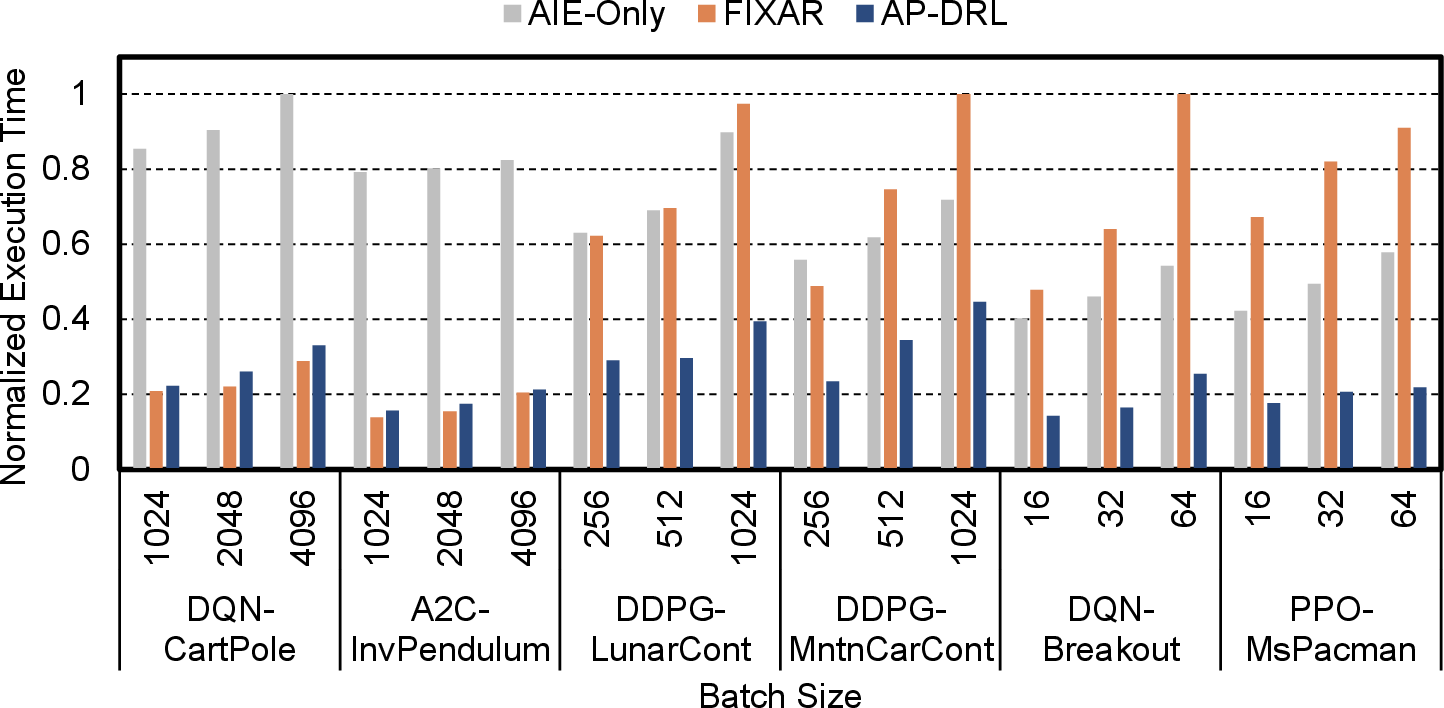
Figure 11: Normalized execution time for AIE-only, FIXAR, and AP-DRL across environments, algorithms, and batch sizes.
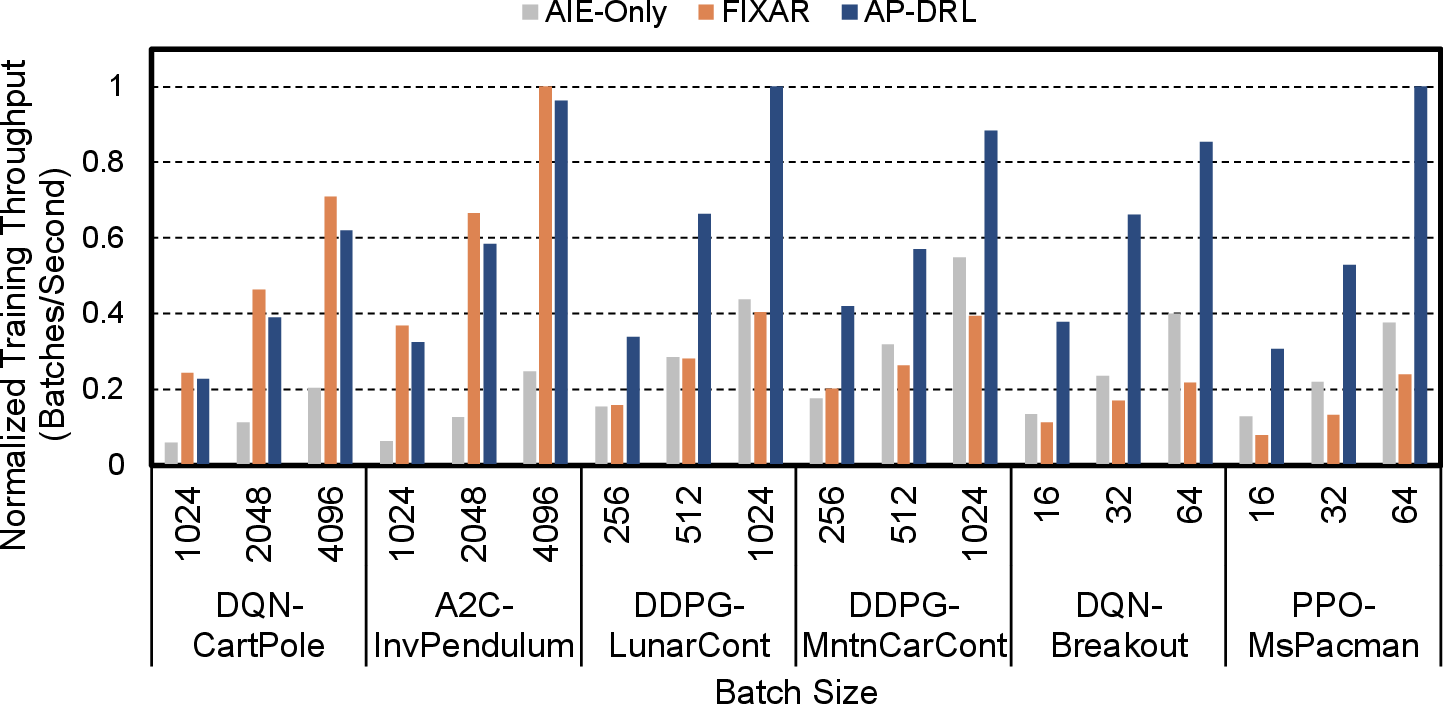
Figure 12: Training throughput comparison across approaches, batch sizes, and environments.
Partitioning evolution is demonstrated in DDPG-LunarCont case study, showing layer assignment migration to AIE with increasing batch size and FLOPs.
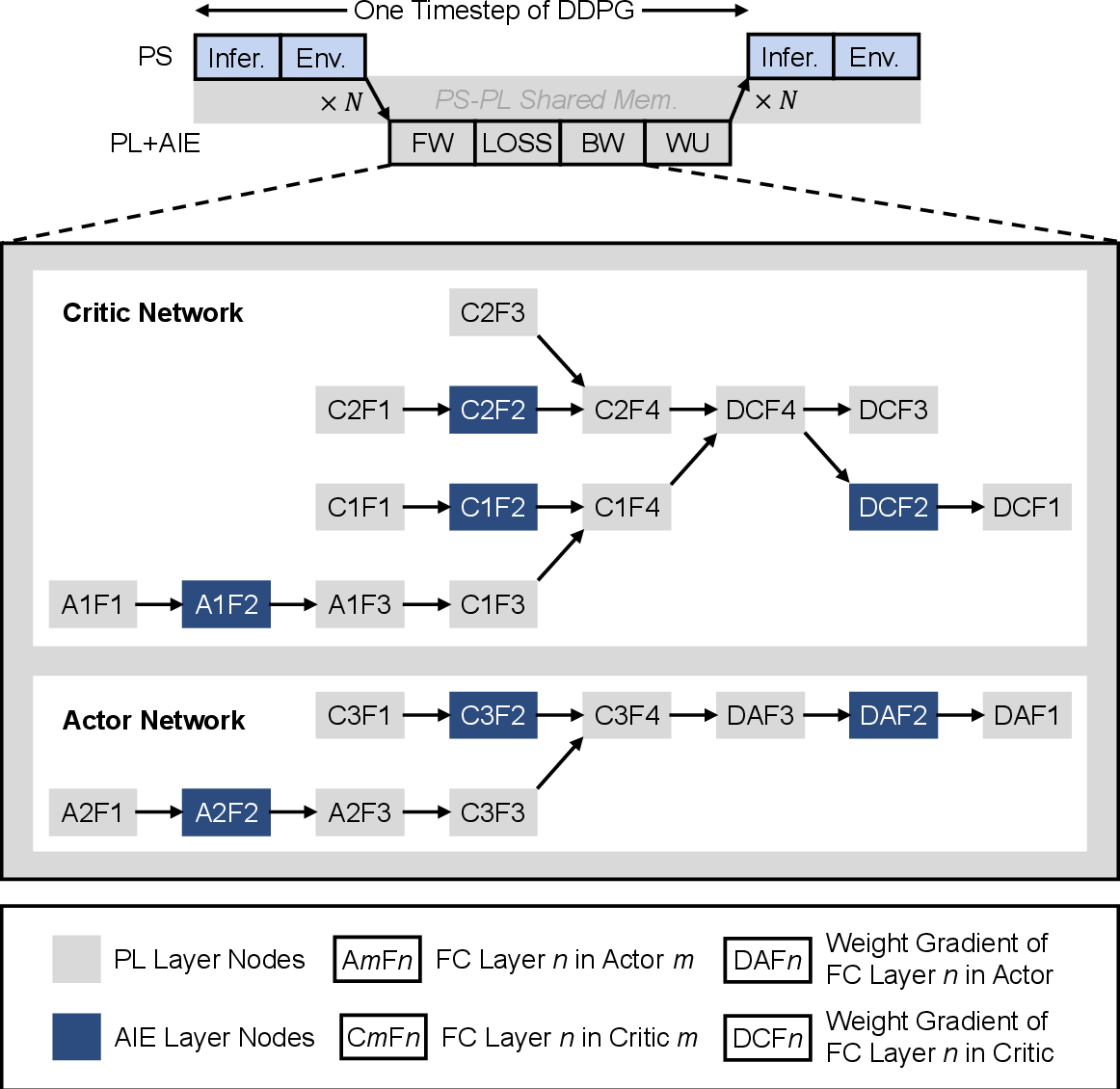
Figure 13: Layer operation sequence of DDPG-LunarCont in AP-DRL within a single timestep.
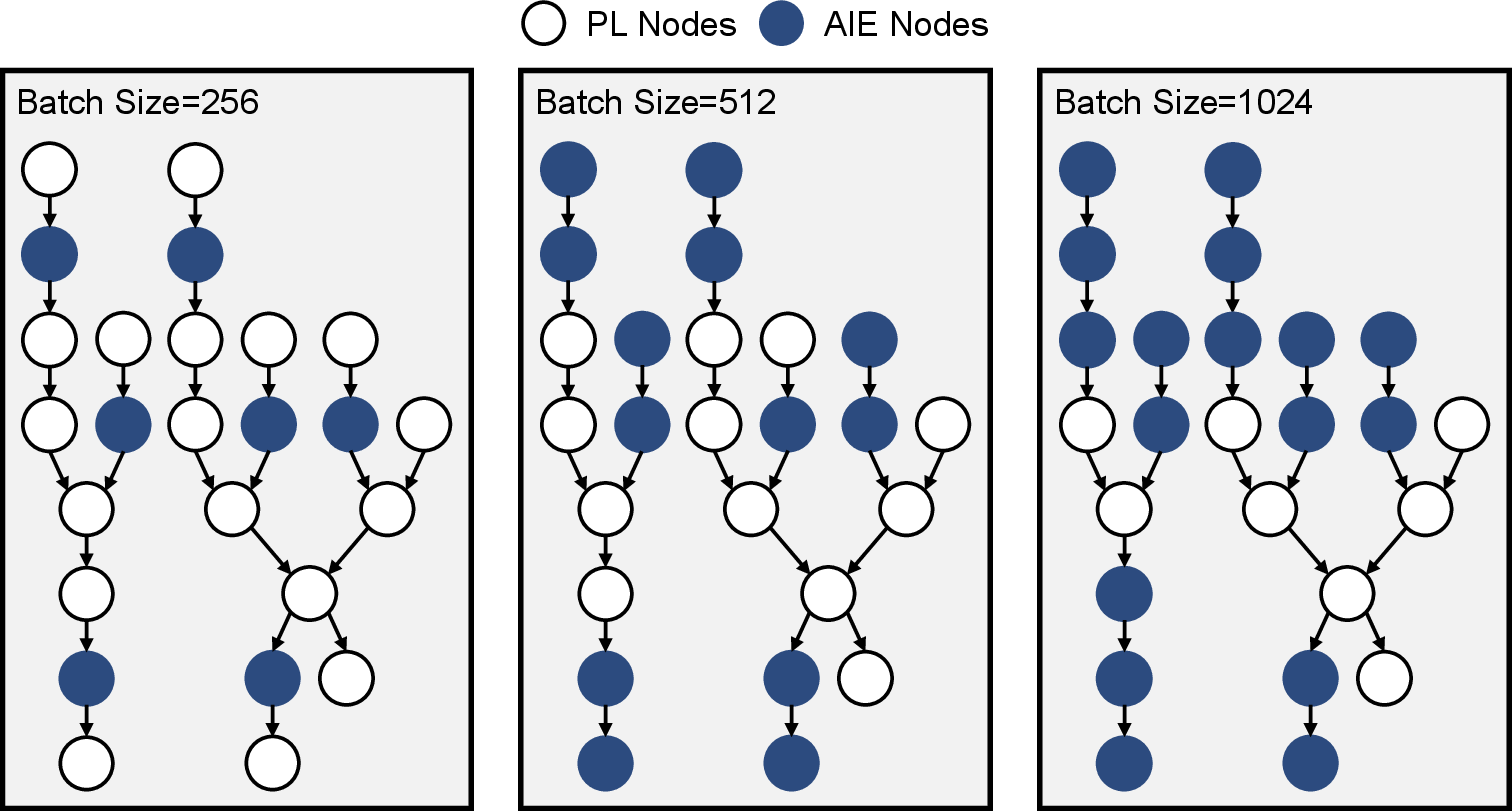
Figure 14: Partitioning results for DDPG-LunarCont across batch sizes; node-to-domain assignments reflect optimal hardware usage.
Implications and Future Directions
AP-DRL’s synergistic algorithm-hardware partitioning enables fine-grained exploitation of heterogeneous compute resources, advancing DRL training acceleration while maintaining convergence and mitigating precision-induced reward degradation. The ILP-based layer-mapping framework and BF16-centric quantization provide a formalized template for automated optimization in future adaptive training systems.
Practically, AP-DRL positions Versal ACAP as the optimal platform for a wide span of DRL workloads, automatically matching task characteristics to computational units and style. Future theoretical developments may extend partitioning strategies to inference and environment steps, further refining quantization and communication optimizations.
Conclusion
AP-DRL achieves synergistic task partitioning and quantization-aware training for DRL on Versal ACAP, systematically solving platform diversity and quantization error challenges. Its ILP-based partitioning and hardware-aware quantization produce robust convergence and substantial speedup, scaling with FLOPs and task complexity. The framework provides a formalizable pathway for DRL acceleration in heterogeneous systems and suggests promising avenues for fully automated training/inference optimization in future AI hardware.