- The paper introduces an MXFP8 pre-training recipe that quantizes key tensors using the E4M3 format, ensuring BF16-level accuracy.
- It details a novel rounding method for converting FP32 to MXFP8 that enhances training stability by minimizing quantization noise and preventing numerical issues.
- Empirical results on 8B-parameter models trained on 15T tokens confirm negligible accuracy loss and highlight substantial throughput improvements.
Recipes for Pre-training LLMs with MXFP8
The paper "Recipes for Pre-training LLMs with MXFP8" explores various methodologies for efficient LLM pre-training using NVIDIA's MXFP8 data format, which offers the dual benefits of reduced precision and enhanced hardware efficiency on specific NVIDIA GPUs. This study is significant in its application of the MXFP8-E4M3 format, which presents a robust solution to the challenge of maintaining model accuracy while optimizing computational resource utilization.
Introduction to MXFP8 and Blackwell GPUs
The introduction of MX formats represents a pivotal advancement in the computational efficiency of LLM pre-training. With the emergence of NVIDIA Blackwell GPUs supporting 8-bit MXFP8, the paper underscores two principal conditions necessary for effective pre-training without loss of accuracy: the utilization of MXFP8-E4M3 data type for all key tensors and the implementation of a bespoke rounding method. This enables the quantization of more tensors compared to predecessors, thereby maximizing processing efficiency.
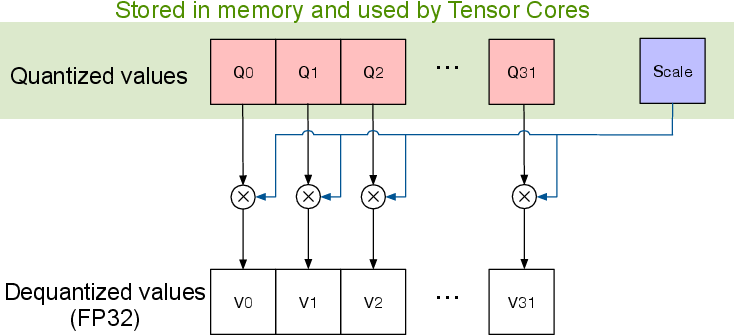
Figure 1: A single MXFP block (in green box) and interpretation of MXFP format.
MXFP8 formats combine narrow floating-point types with finer-grained scaling factors, which tackles precision challenges and achieves dynamic range and efficiency. This innovation focuses on transforming high precision FP32 values into MX-formatted representations, leveraging shared per-block scaling to encode the max representable value in the MXFP format.
Pre-training with MXFP8
Training Results and Evaluation
Through extensive experiments, the paper demonstrates that MXFP8 matches the accuracy of BF16 training regimes. Specifically, a detailed examination is carried out using models involving up to 8 billion parameters trained across 15 trillion tokens, showing negligible accuracy degradation.
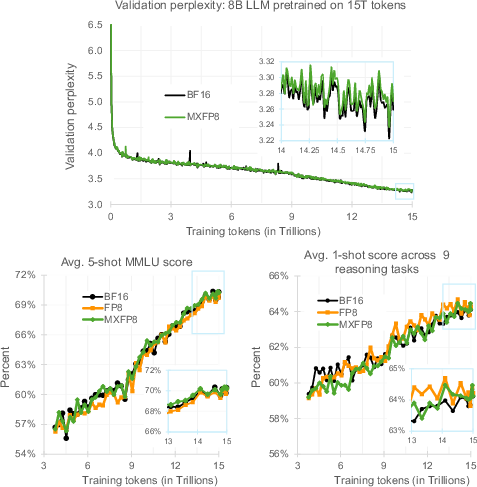
Figure 2: Pre-training a 8B LLM on 15T tokens. Top: Training behavior of BF16 vs MXFP8. Bottom: Comparing BF16, FP8, and MXFP8's downstream task scores on MMLU and a set of 9 reasoning tasks.
Validation perplexity and downstream task scores for MXFP8 match those of BF16, supported by empirical evidence from ablation studies and evaluation on key benchmarks like MMLU. This alignment affirms MXFP8's validity for large-scale LLM training, with throughput benefits noted due to hardware acceleration.
MXFP8 Training Recipe
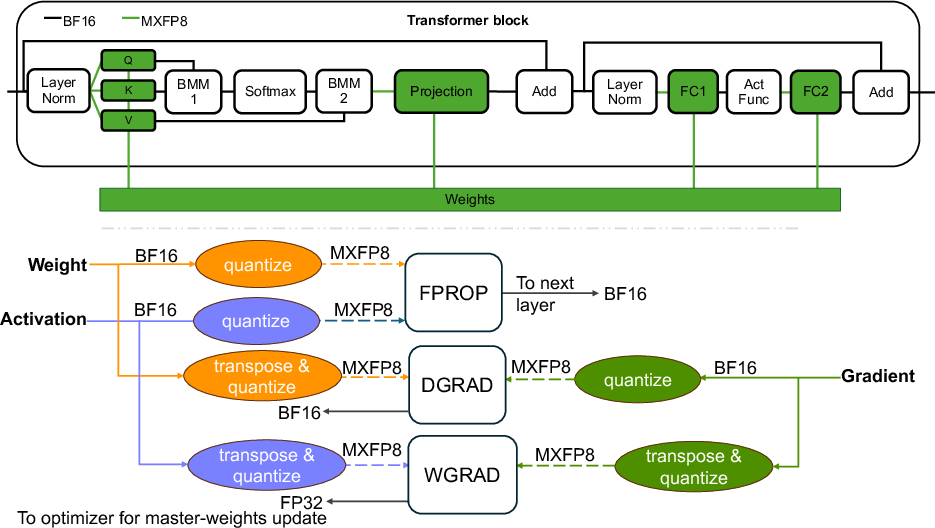
Figure 3: Top: Transformer layers quantized to MXFP8 inside a single transformer block. Bottom: Training workflow for a single layer during forward-pass (FPROP), error-gradient pass (DGRAD) and weight-gradient pass (WGRAD).
The training recipe for MXFP8 involves targeted quantization of key tensors (activations, weights, gradients) to MXFP8 across all transformer layers. The novel quantization approach highlights the formulae and selection criteria for FP8 encoding, particularly advocating the E4M3 format for its precision across various tensor types. Figure 3 illustrates the detailed architecture and workflow for quantizing tensors, ensuring high efficiency in operations carried out in MXFP8. Additionally, this format facilitates minimizing computational overhead by aligning quantized operations to transformative processes in hardware, distinguishing it from previous approaches which necessitated selective precision maintenance in certain layers.
Conversion Methodology
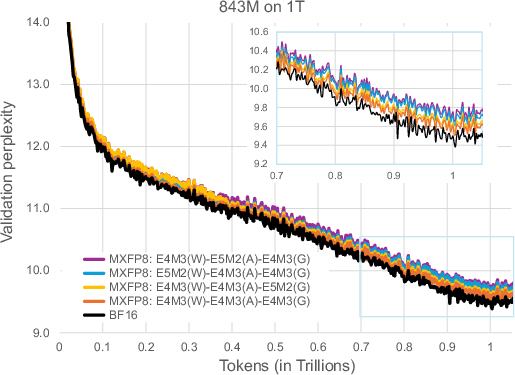
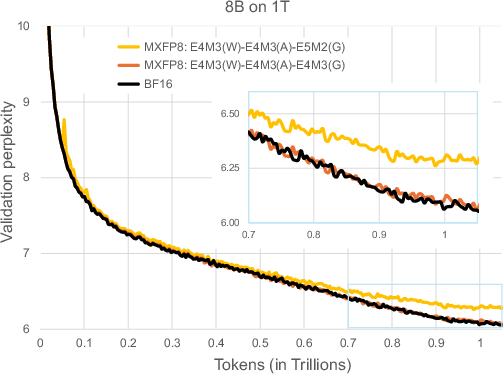
Figure 4: Validation perplexity curves for 843M parameter model trained on 1T tokens.
To effectively convert FP32 to MXFP8, a unique rounding algorithm is introduced that modifies the typical scale factor determination by rounding up to ensure numerical stability and eliminating potential overflow or underflow issues common with other methodologies. This rounding choice is shown to enhance training stability and reduce quantization noise, resulting in improved perplexity metrics in comparison to previous methods.
MXFP8 distinguishes itself from other low-precision paradigms by its hardware-supported scalability and efficient tensor representation. Existing methods focus more on post-training quantization adjustments, whereas MXFP8 integrates these considerations at the pre-training phase, systemically addressing hardware compatibility and accelerating LLM pre-training throughput significantly.
Conclusions
The study conclusively shows MXFP8 as an effective alternative to BF16 for LLM pre-training, with optimized performance metrics and hardware synergy on NVIDIA platforms. Moving forward, there is potential for exploration into post-training phases and broader applications of MX formats, introducing advancements in reinforcement learning policy optimization and fine-tuning practices.
The paper sets a precedence for adopting fine-granularity scaling factors within hardware-integrated data formats, proposing significant implications for the evolution of efficient deep learning model training practices.

