- The paper introduces ReLog, a framework that iteratively refines logging statements using runtime feedback to optimize defect localization and repair by LLMs.
- It leverages a closed-loop architecture combining static analysis, compilation repair, and LLM evaluation to generate dynamic, evidence-rich logs.
- Experimental results show significant improvements in F1 scores and repair rates across direct and indirect debugging settings compared to traditional static methods.
Iterative, Runtime-Aware Logging Statement Generation for LLM-Based Debugging: An In-Depth Analysis of ReLog
Introduction and Motivation
Logging statements are central to debugging, program comprehension, and maintenance. Traditional automated techniques for logging generation have predominantly utilized static code analysis and evaluated outputs based on their syntactic similarity to human-authored logs. However, this paradigm fails to leverage the iterative and feedback-driven refinement process commonly adopted by human developers and is misaligned with current workflows where LLMs are both the generators and consumers of logging artifacts during automated debugging and repair tasks. Furthermore, strict adherence to human-written logs as ground truth restricts downstream effectiveness, especially considering these logs may themselves be diagnostically suboptimal.
The work presented in "Logging Like Humans for LLMs: Rethinking Logging via Execution and Runtime Feedback" (2603.29122) introduces ReLog, a runtime-feedback-driven iterative logging generation framework. ReLog reconceptualizes automated logging: logs are not static one-shot artifacts but are iteratively tuned via execution feedback to maximize utility for downstream tasks—primarily defect localization and repair—carried out by LLM-based agents.
Empirical Motivation for Iterative Logging Refinement
A motivating study across ten large Apache projects establishes that a nontrivial proportion (20–40%) of logging statements are modified one or more times after their initial introduction. This empirical evidence corroborates that logging is a process subject to ongoing refinement rather than a static, one-shot act. Developers routinely adjust logs to improve their semantic informativeness, granularity, and severity in response to runtime dynamics and emergent debugging needs.
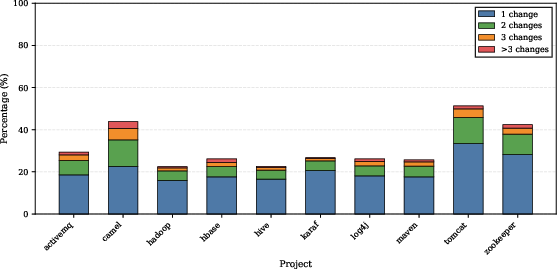
Figure 1: Distribution of revision frequencies for logging statements, highlighting the prevalence of iterative, post-insertion modification.
Furthermore, case analyses reveal logs being adapted from high-precision nanosecond trace points to more interpretable millisecond-level diagnostics, along with severity demotion after evaluation of their operational utility in-situ.
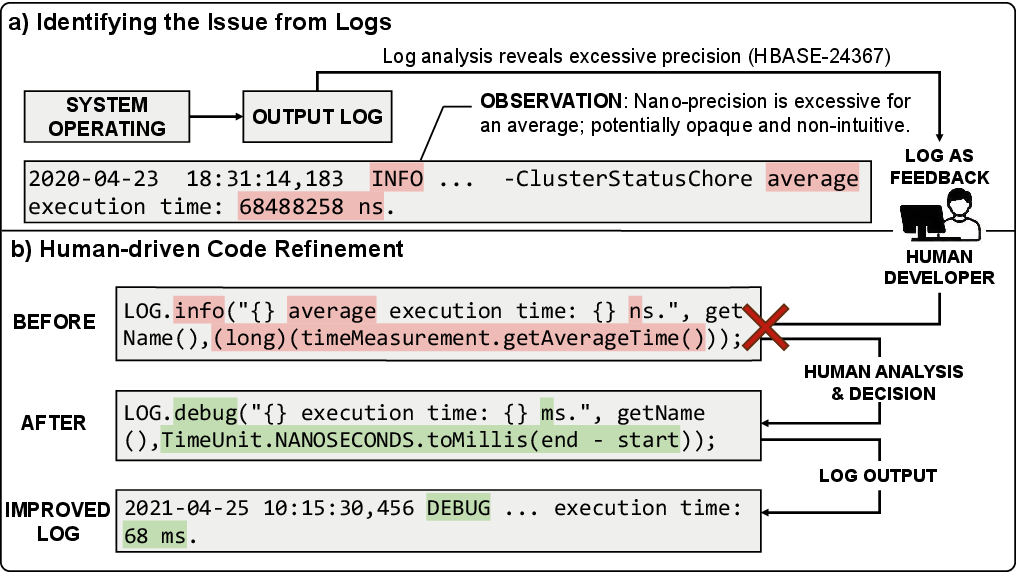
Figure 2: Example of real-world log refinement: initial nanosecond-level timing log is revised to millisecond-level and a reduced severity level after runtime analysis.
ReLog Framework: Architecture and Workflow
ReLog operationalizes iterative log refinement through continuous runtime feedback in a closed-loop architecture, fundamentally diverging from previous static approaches.
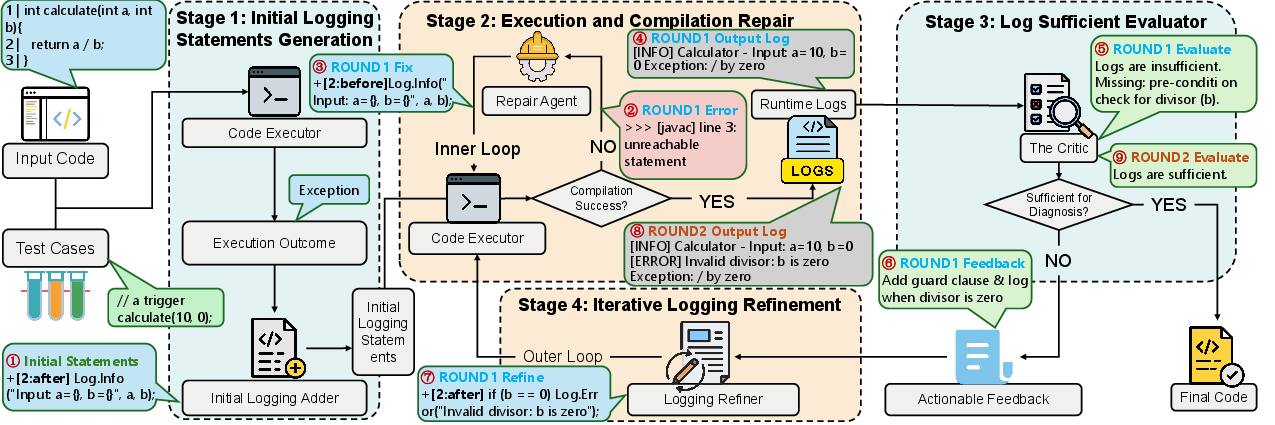
Figure 3: End-to-end architecture of ReLog's iterative runtime feedback loop for logging statement generation and refinement.
The framework comprises four core stages:
- Initial Logging Statement Generation: Combines static code signals with runtime execution results (such as exceptions, return value anomalies, or timeouts) to generate localized candidate logs.
- Compilation Repair: Integrates compiler output to fix syntactic and semantic errors introduced during logging statement insertion, maintaining compilation and execution integrity.
- Log Sufficiency Evaluation: Employs an LLM-based critic guided by traceability, state observability, and causal linkage rubrics to assess whether runtime logs provide sufficient evidence for downstream defect localization and repair.
- Iterative Refinement: If logs are deemed insufficient, the framework refines the logging statements based on feedback, then cycles through additional rounds of compilation and execution, systematically closing evidence gaps.
ReLog terminates upon achieving log sufficiency or exhausting configurable iteration limits.
Experimental Setup
Two evaluation datasets are composed from Defects4J, targeting distinct real-world debugging settings:
- Direct Debugging: Both faulty source code and generated runtime logs are accessible to the LLM-based agent. Tasks include both defect localization and program repair.
- Indirect Debugging: Only runtime logs and dynamic caller context are available, simulating scenarios where source code access is restricted (e.g., in production systems). Only localization is evaluated.
A suite of strong baselines—ranging from deep neural models (LANCE, LANCE2, FastLog) to in-context LLM-driven and static context-aware generators (UniLog, GoStatic)—is used for comparison. Downstream utility is measured by F1 score for defect localization and the absolute count of successfully repaired defects.
Results and Analysis
Downstream Debugging Effectiveness
ReLog substantially improves both F1 and repair rates relative to baselines in both direct and indirect settings. In direct debugging, ReLog attains an F1 of 0.520 and successfully repairs 97 of 311 defects—a marked improvement (+16.33% in F1) over the strongest baseline. In the indirect setting, ReLog’s F1 of 0.408 similarly outpaces competing methods by a clear margin.
Moreover, ReLog robustly eliminates the large rates of compilation failures endemic to static and deep learning-based methods due to its compilation repair loop. Deep learning baselines typically fail to generate more than one logging statement per method owing to task framing limitations, resulting in poor runtime trace coverage. In contrast, ReLog produces concise yet sufficiently dense trace evidence (5.52 logs/method in direct, 6.21 per-caller in indirect), balancing informativeness against verbosity.
Model Generality
Evaluation across multiple LLMs (DeepSeek-V3, Qwen3-Coder-30B, GLM-4.7, GPT-5-mini) demonstrates that ReLog's iterative refinement mechanism is architecture-agnostic: all models achieve comparable localization and repair scores. F1 ranges narrowly from 0.518 (Qwen3) to 0.559 (GPT-5-mini), and repair counts remain consistent. This finding substantiates that it is the runtime-aware generation paradigm—rather than specific model choice—that amplifies debugging outcomes.
Component Ablation
Ablation of core components (compilation repair or iterative refinement) leads to pronounced F1 and repair degradation. Disabling compilation fix-up increases failures and reduces recall, while removal of iterative refinement reverts ReLog’s behavior to mere static generation, halving its effectiveness (F1 drops from 0.520 to 0.388, repairs from 97 to 81 in direct debugging). This empirically establishes that both components synergistically underpin ReLog’s utility.
Case Study
A targeted defect study highlights that static and deep learning loggers can either (a) entirely fail due to compilation errors, or (b) generate logs that cover only entry/exit points or final anomalous values, hence insufficient for precise root cause localization. In contrast, ReLog, via successive refinement rounds, uses runtime signal analysis to suggest the addition of critical variable states and conditional branch evidence, ultimately enabling correct fault identification by the downstream LLM agent.
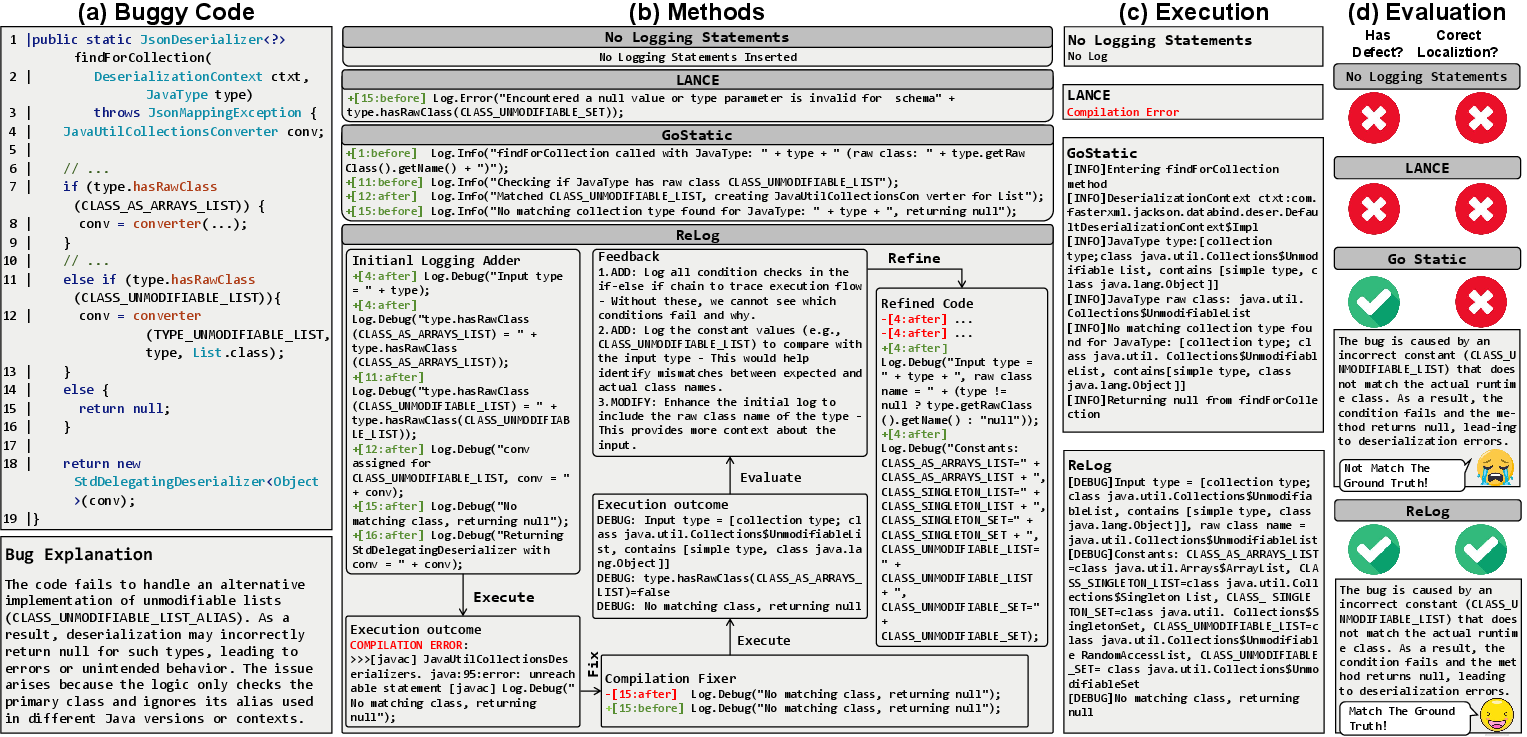
Figure 4: Case study contrasting ReLog's evidence-chaining with static and DL-based logging, showing improved localization performance due to runtime-driven refinement.
Theoretical and Practical Implications
This work demonstrates a clear paradigm shift: logging statement generation must be construed as an execution-aware, iterative process. ReLog bridges the gap between static code analysis–based logging generation and the empirical realities of runtime-driven diagnostic needs, especially in LLM-driven workflows. The findings concretely advocate for evaluating automated log generation by practical downstream impact (defect localization/repair) as opposed to proxy text-similarity metrics.
Practically, ReLog's model-agnostic design and robust executable patching loop establish a blueprint readily extensible to other tasks involving log-based anomaly detection, automated performance analysis, or runtime-aware regression testing. The dynamic, feedback-driven approach also aligns with recent trends in retrieval-augmented and execution-aware LLM frameworks.
Conclusion
ReLog fundamentally redefines the logging statement generation problem, positioning it as a runtime-guided, downstream-utility maximization task. Through iterative, feedback-driven refinement and robust error-repair mechanisms, ReLog delivers logging artifacts that materially improve LLM-based debugging and repair. Experimental results confirm the superiority of this methodology across task settings and LLM architectures. The framework lays the groundwork for further research into execution-aware, automated instrumentation strategies optimized for a diverse suite of program analysis workflows.
Future Directions
Possible future extensions include: (a) integration with continuous integration systems for on-the-fly logging augmentation, (b) adaptation to latency-sensitive or constrained environments via cost-aware runtime signal selection, and (c) expansion of critique rubrics and critic module learning for multi-task generalization.
Reference: "Logging Like Humans for LLMs: Rethinking Logging via Execution and Runtime Feedback" (2603.29122).