MMFace-DiT: A Dual-Stream Diffusion Transformer for High-Fidelity Multimodal Face Generation
Abstract: Recent multimodal face generation models address the spatial control limitations of text-to-image diffusion models by augmenting text-based conditioning with spatial priors such as segmentation masks, sketches, or edge maps. This multimodal fusion enables controllable synthesis aligned with both high-level semantic intent and low-level structural layout. However, most existing approaches typically extend pre-trained text-to-image pipelines by appending auxiliary control modules or stitching together separate uni-modal networks. These ad hoc designs inherit architectural constraints, duplicate parameters, and often fail under conflicting modalities or mismatched latent spaces, limiting their ability to perform synergistic fusion across semantic and spatial domains. We introduce MMFace-DiT, a unified dual-stream diffusion transformer engineered for synergistic multimodal face synthesis. Its core novelty lies in a dual-stream transformer block that processes spatial (mask/sketch) and semantic (text) tokens in parallel, deeply fusing them through a shared Rotary Position-Embedded (RoPE) Attention mechanism. This design prevents modal dominance and ensures strong adherence to both text and structural priors to achieve unprecedented spatial-semantic consistency for controllable face generation. Furthermore, a novel Modality Embedder enables a single cohesive model to dynamically adapt to varying spatial conditions without retraining. MMFace-DiT achieves a 40% improvement in visual fidelity and prompt alignment over six state-of-the-art multimodal face generation models, establishing a flexible new paradigm for end-to-end controllable generative modeling. The code and dataset are available on our project page: https://vcbsl.github.io/MMFace-DiT/








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
MMFace-DiT: A simple guide for teens
What is this paper about?
This paper introduces MMFace-DiT, an AI model that can create very realistic faces by combining different kinds of inputs at the same time—like a text description (“a smiling woman with short curly brown hair”) and a spatial guide such as a mask (a colored outline of face parts) or a sketch (a line drawing). Think of it as a smart art assistant that can both “read” a description and “trace” a layout, then paint a lifelike portrait that follows both.
What questions are the researchers trying to answer?
In everyday words, they asked:
- How can we make AI draw faces that both look real and follow the shape or layout we want (from a mask or sketch) while also matching a written description?
- Can we avoid the common problem where one input (like a strong sketch) overpowers the other (like a subtle text detail)?
- Is it possible to build one single model that understands different spatial inputs (masks or sketches) without retraining it every time?
- Can we improve training data so the AI better understands detailed text descriptions of faces?
How does their method work? (Explained with simple ideas)
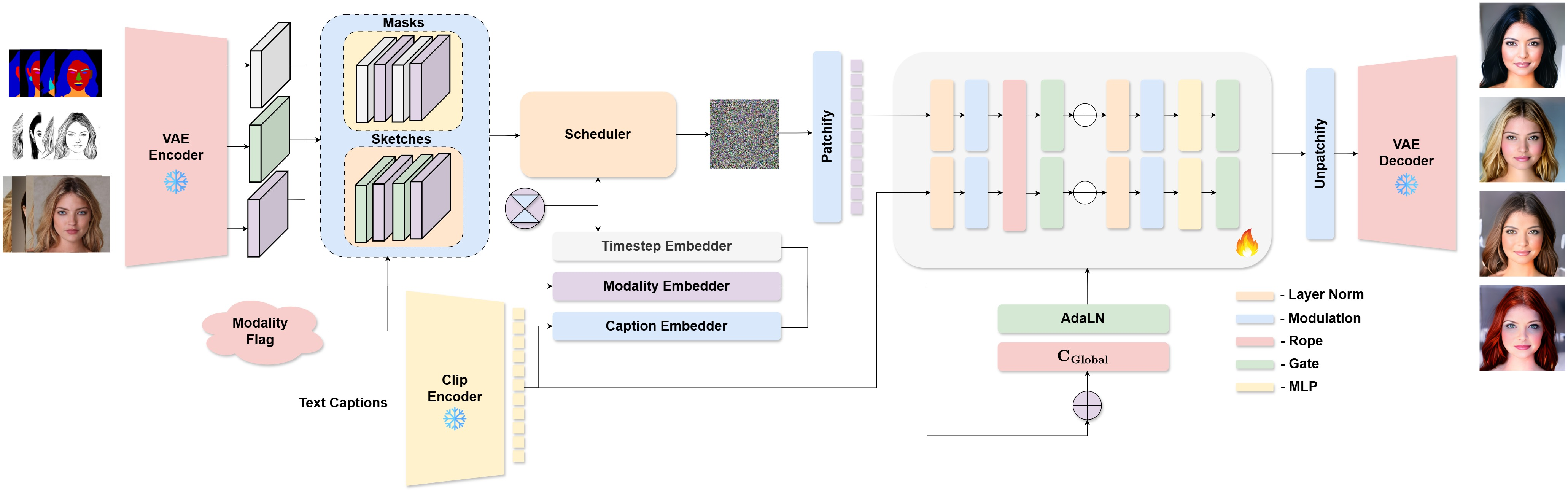
You can imagine their system like a two-lane highway for information, where both lanes constantly talk to each other:
- Two lanes of information
- One lane carries “spatial” guidance (the layout or shape: masks or sketches).
- The other lane carries “semantic” guidance (the meaning from text prompts).
- Constant conversation between lanes
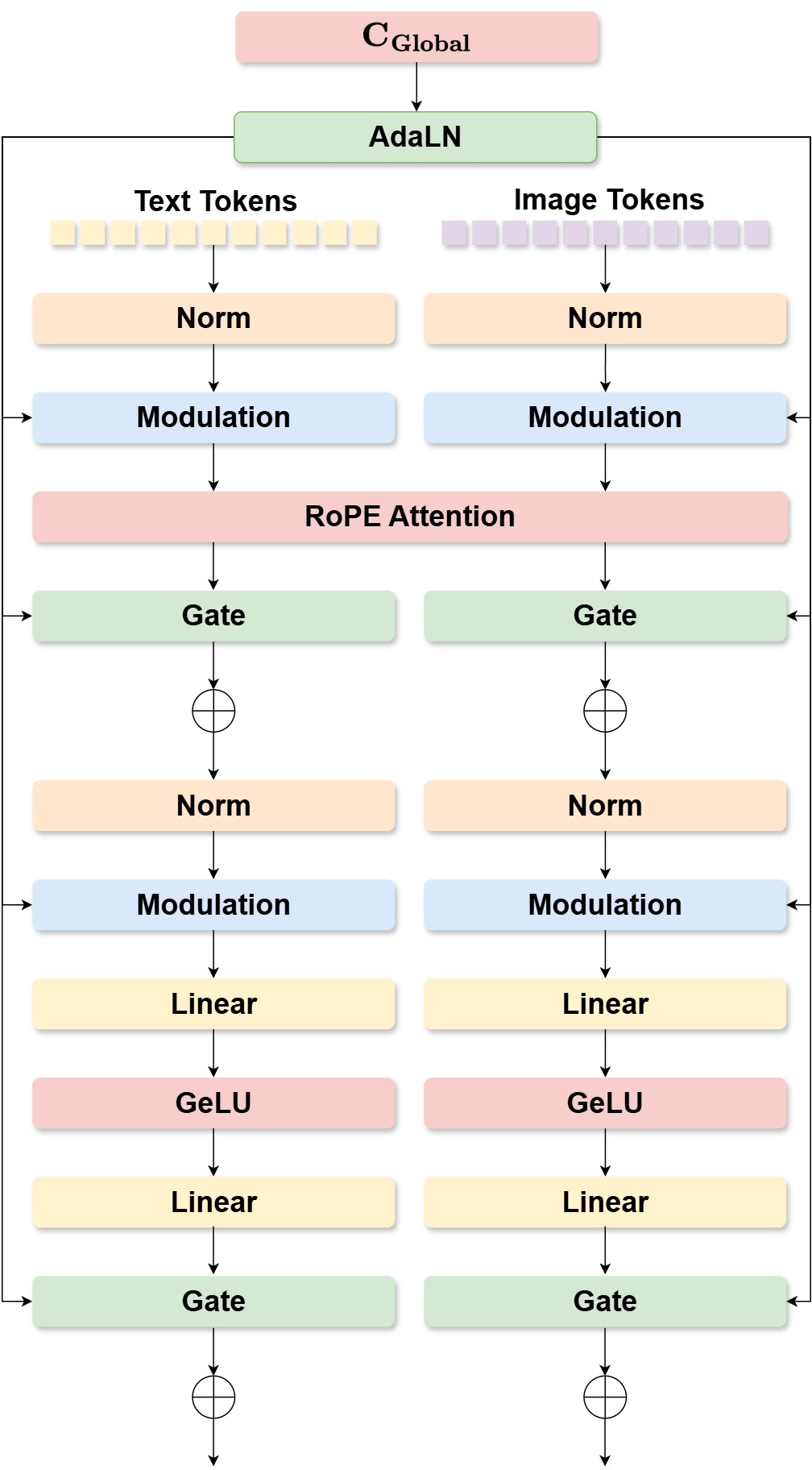
- Inside the model, these two lanes meet and “talk” at every step so the final image respects both the shape and the description. This is done with a shared attention mechanism, which you can think of as the model looking at every part of the sketch and every word in the sentence at the same time, and deciding how they relate.
- Knows where things are
- The attention system uses something called RoPE (Rotary Position Embeddings). In simple terms, it helps the model remember positions—like which patch of the image is top-left or bottom-right, and which word came first—so shapes and words line up correctly in the final picture.
- A smart mode switch
- A tiny “Modality Embedder” acts like a setting switch that tells the model whether the spatial input is a mask or a sketch, so one model can handle both without retraining.
- Balancing act
- The model has “gates” that act like volume knobs. If the sketch is very detailed, it won’t drown out the text. If the text has important details, they won’t get lost behind the mask.
- Works in a compressed space
- The images are handled in a compressed form (like a zip file) called a “latent space” using a VAE. This lets the model work faster while still producing high-quality results.
- Trained with “denoising”
- The model learns to turn noisy, blurry images into clear ones step by step. This “diffusion” process is like slowly sharpening a foggy picture until it looks real.
- They tried two training styles:
- DDPM (predict the noise)
- Flow Matching (predict the “direction” from noise to a clean image), which can be faster and more stable.
To make the text guidance stronger and more detailed, they also built a better training dataset by using a vision-LLM to create rich captions for face images and then cleaned those captions with rules and another LLM.
What did they find, and why does it matter?
They tested MMFace-DiT against several popular methods and found:
- More realistic faces: Their images looked more natural and detailed.
- Better alignment with the text: If the prompt says “blue eyes, gold earrings, high bun,” the model actually adds those, in the right places.
- Better spatial faithfulness: The result respects the mask or sketch layout closely, so the face shape and features follow the guide.
- Works across different inputs: The same model can switch between mask-guided and sketch-guided modes without retraining, thanks to the “modality” switch.
- Strong scores across many measures: On common benchmarks (like FID for realism and CLIP score for text-match), they report big improvements—up to about 40% better in realism and prompt matching compared to other methods. Their “flow matching” version often performed best.
Why this matters:
- Artists and designers can control both the shape and the style with simple inputs.
- It reduces common failures where the picture follows the shape but ignores the description, or vice versa.
- It makes controlled image generation more reliable and flexible.
What’s the bigger impact?
- One model, many controls: This simplifies real-world tools that let you guide image generation with both text and drawings.
- Better training data: Their captioning pipeline shows how to build richer, cleaner descriptions, which could help other research areas too.
- Practical and efficient: They trained a large model on just two GPUs using careful tricks, suggesting similar systems can be built without massive computing power.
- A step toward safer, more accurate control: By keeping text and spatial inputs in balance, the model is less likely to ignore important instructions and more likely to give users the result they intended.
In short, MMFace-DiT is a new way to get AI to “color inside the lines” of a sketch or mask while fully following a written description—producing photorealistic faces that match both what you draw and what you say.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of gaps and open questions that remain unresolved and could guide future research:
- Generalization beyond faces: Does the dual-stream architecture transfer to non-face domains (e.g., whole-body, indoor scenes) without re-design, and what adaptations are necessary for broader applicability?
- Demographic fairness and bias: How does performance vary across age, gender presentation, skin tone, and other demographic attributes in CelebA-HQ/FFHQ? Establish bias audits with stratified metrics and controlled test sets.
- Identity preservation and drift: Quantify identity consistency in generated faces (e.g., using face recognition embeddings) and measure drift under different prompts and spatial conditions.
- Robustness to conflicting conditions: Systematically evaluate cases with deliberately conflicting text and spatial inputs (e.g., “long hair” + short-hair mask) and characterize failure modes and resolution strategies.
- Out-of-distribution robustness: Assess resilience to extreme poses, occlusions (glasses, masks), low-quality or noisy sketches/masks, rare accessories, and atypical facial structures.
- Human evaluation: Conduct controlled user studies (A/B tests, pairwise preference) to validate perceptual improvements and semantic alignment beyond FID/CLIP/LLM metrics.
- Metric reliability: Validate the correlation of CLIP Score and LLMScore with human judgments in face synthesis, and develop task-specific metrics for fine-grained attributes (e.g., hair color, accessories).
- Inference efficiency: Report and compare wall-clock latency, throughput, and memory footprint under DDPM vs. RFM across resolutions and step schedules; assess real-time feasibility.
- Resolution scaling: Evaluate synthesis at higher resolutions (>512×512), including stability, artifacts, and compute cost; study scaling laws for quality vs. resolution.
- Editing and inversion: Explore real-image editing via robust inversion (e.g., face-specific encoders), and quantify controllability vs. identity retention in edit workflows.
- Explicit controllability knobs: Provide and evaluate user-adjustable controls for modality weighting (e.g., gating α, text vs. spatial dominance) and negative prompts to suppress attributes.
- Modality coverage: Test the Modality Embedder with additional spatial modalities (e.g., landmarks, 3D morphable model parameters, depth, pose maps) and combinations (mask + sketch simultaneously).
- Modality Embedder design: Investigate richer modality representations (beyond a discrete flag), such as learned continuous embeddings, multi-label conditioning, or mixture-of-experts routing.
- Fusion mechanism ablations: Compare shared RoPE attention against alternative fusion designs (cross-attention, co-attention, token mixers, FiLM-style conditioning) and quantify trade-offs.
- Positional encoding choices: Study the impact of different positional encodings (e.g., 2D sinusoidal, learned PE, disentangled axial encodings) vs. RoPE variants on spatial–semantic alignment.
- Dataset annotation quality: Provide quantitative validation of VLM-generated captions (human ratings, factual accuracy, hallucination rates), inter-annotator agreement, and error analysis.
- Caption pipeline reproducibility: Assess sensitivity to the choice and version of VLMs (InternVL3, Qwen3), release detailed prompts and filtering rules, and evaluate legal/licensing constraints for dataset redistribution.
- Segmentation/sketch label noise: Quantify errors from SegFormer/U2Net-derived masks/sketches and their downstream impact; explore training with noisy labels and robust loss formulations.
- VAE dependence: Analyze how latent dimensionality and reconstruction biases of different VAEs affect color fidelity, texture realism, and training stability; explore end-to-end VAE fine-tuning vs. frozen VAEs.
- Joint training with encoders: Evaluate benefits/risks of fine-tuning CLIP (text encoder) within the dual-stream architecture for improved alignment; investigate multilingual caption support.
- Data scale and diversity: Test scaling beyond ~100K images and 1M captions; quantify quality gains vs. compute with larger, more diverse face corpora and synthetic captions.
- Safety and misuse: Study deepfake risks, propose watermarking/detection baselines, and report detectability by state-of-the-art synthesis detectors; address consent and ethical considerations explicitly.
- Benchmark standardization: Develop and release standardized multimodal face control benchmarks with curated conflicting cases, fine-grained attribute checklists, and demographic splits for reproducible comparisons.
- Failure case analysis: Document and categorize typical failure modes (artifacts, semantic misses, color shifts, texture oversmoothing) under various conditions to guide targeted improvements.
Practical Applications
Immediate Applications
The following applications can be deployed with the methods and resources described in the paper, using the released code and dataset.
- Controlled face ideation from sketches or masks for creative production
- Sectors: media & entertainment, advertising, gaming
- Tools/workflows: design plugins for Photoshop/Blender/Figma; “sketch + prompt → photorealistic face” generators; batch variant generation for art direction
- Assumptions/dependencies: availability of designer-provided masks/sketches; adherence to content guidelines; licensing of VAEs (e.g., Flux) and CLIP encoders; manage deepfake risk via moderation and watermarking
- Avatar and NPC face generation with precise constraints
- Sectors: gaming, social platforms, virtual events
- Tools/workflows: Unity/Unreal pipeline that accepts silhouettes or facial region masks plus text prompts to auto-generate characters; character-creation wizards
- Assumptions/dependencies: runtime inference latency acceptable or use offline precomputation; profile moderation; consistency constraints for sequels may require seed control
- AR effects and cosmetics concepting
- Sectors: AR/VR, beauty & cosmetics, creative agencies
- Tools/workflows: rapid prototyping of filters/makeup/hair styles from designer sketches + textual descriptions; export masks and textures for downstream engines
- Assumptions/dependencies: mask templates for common regions (hair, lips, eyes); robust color fidelity depends on VAE choice (Flux recommended by the paper)
- Hair and accessories ideation for e-commerce merchandising
- Sectors: retail, fashion, beauty
- Tools/workflows: generate photorealistic product shots showing hair color/style changes or accessories placement guided by masks and prompts
- Assumptions/dependencies: not personalized to a specific customer without an identity-safe pipeline; needs usage policies to avoid misleading images
- Privacy-friendly synthetic faces for UI mockups and A/B testing
- Sectors: software/product design, marketing
- Tools/workflows: replace real portraits in design comps with controlled, synthetic faces; maintain demographic diversity by prompting attributes
- Assumptions/dependencies: ensure synthetic identity unlinkability; document synthetic use to avoid deception; handle bias through prompt coverage
- Data augmentation for non-biometric face tasks
- Sectors: academia, CV/ML teams
- Tools/workflows: generate diverse images and corresponding masks for training face parsing, accessories detection, or makeup segmentation
- Assumptions/dependencies: validate domain gap; avoid using for face recognition biometrics without ethics review; maintain labels derived from known masks
- Benchmarking and teaching multimodal fusion
- Sectors: academia, standards bodies
- Tools/workflows: use the released VLM-augmented captions and code to benchmark multimodal alignment, study modality dominance, test fusion strategies (shared RoPE, gating)
- Assumptions/dependencies: compute availability (inference is feasible on a single high-memory GPU); compliance with dataset licenses (FFHQ/CelebA-HQ)
- Low-resource training recipe adoption for startups/SMEs
- Sectors: software/AI startups, applied research labs
- Tools/workflows: replicate progressive training (256→512), bfloat16, 8-bit AdamW, checkpointing; extend with domain-specific captions
- Assumptions/dependencies: access to 1–2 prosumer GPUs; matching software stack and precomputed latents
- Region-aware generative plugins for design suites
- Sectors: creative software
- Tools/workflows: “select region → prompt → generate” feature using segmentation masks; controlled hair, skin, or background edits
- Assumptions/dependencies: plugin SDK support; UI for modality selection (mask vs sketch); integrate safety filters
- Rapid casting visualization and character briefs
- Sectors: film/TV previsualization, advertising shoots
- Tools/workflows: translate creative briefs into photorealistic faces with explicit attributes (e.g., hairstyle, age cues) respecting layout constraints
- Assumptions/dependencies: disclosure of synthetic imagery; mitigation of resemblance to real persons; content approval processes
- Accessibility for non-expert creators
- Sectors: education, creator economy
- Tools/workflows: simple sketch + natural language interface to generate portraits; classroom labs on multimodal AI
- Assumptions/dependencies: prompt quality matters (CLIP token limit ~77); add guardrails to prevent harmful content
- Content moderation and safety research testbed
- Sectors: trust & safety, policy
- Tools/workflows: systematically introduce conflicting prompts and masks to study failure modes; measure semantic-spatial consistency and apply rule-based filters
- Assumptions/dependencies: dedicated evaluation metrics (CLIP score, LLMScore); human review for sensitive cases
Long-Term Applications
These opportunities need further research, scaling, or engineering (e.g., video consistency, real-time performance, expanded modalities).
- Real-time, consistent digital humans for telepresence and VTubing
- Sectors: streaming, enterprise communications
- Tools/workflows: live “structure + prompt” face synthesis that respects user-provided shape constraints; adaptive stylization
- Assumptions/dependencies: model distillation/acceleration; temporal consistency and lip-sync; privacy/consent and watermarks
- Video-level multimodal editing and VFX
- Sectors: film/VFX, advertising
- Tools/workflows: extend dual-stream DiT to spatiotemporal generators; track masks across frames while applying text-guided changes
- Assumptions/dependencies: video diffusion training, motion-aware RoPE, dataset scale-up; shot-level consistency validation
- Personalized virtual try-on for hair/makeup on user images
- Sectors: beauty tech, retail
- Tools/workflows: user face parsing → region-aware synthesis per prompt; explore multiple looks while preserving identity
- Assumptions/dependencies: identity-preserving control (currently a generative identity model); fairness across skin tones and hair textures; regulatory compliance for biometric use
- Privacy-preserving dataset release with synthetic surrogates
- Sectors: public sector, research, smart cities
- Tools/workflows: replace faces in images/videos with synthetic, layout-consistent surrogates preserving scene semantics
- Assumptions/dependencies: formal unlinkability/irreversibility metrics; policy and legal frameworks; robust detectors for provenance
- Forensic sketch-to-face assistance with safeguards
- Sectors: public safety, forensics
- Tools/workflows: generate candidate faces from composite sketches and text descriptions for investigative leads
- Assumptions/dependencies: strict protocols to mitigate confirmation bias; audit trails, explainability, and prohibitions on evidentiary use unless validated; oversight boards
- Clinical visualization for craniofacial planning and prosthetics
- Sectors: healthcare, medical devices
- Tools/workflows: pre/post-operative outcome exploration guided by anatomical masks and clinician notes
- Assumptions/dependencies: medical datasets, domain-specific evaluation, regulatory approval (FDA/CE); ethical review and patient consent
- Security R&D for anti-spoofing and adversarial robustness
- Sectors: cybersecurity, fintech
- Tools/workflows: synthesize diverse, controlled facial variations and accessories to harden PAD (presentation attack detection)
- Assumptions/dependencies: careful governance to avoid misuse; simulate realistic distributions; never for bypassing security
- Cross-domain generalization of dual-stream fusion
- Sectors: architecture/design, robotics, geospatial
- Tools/workflows: apply “structure + semantics” paradigm to floorplan+text→interior images; map masks+task text→synthetic environments
- Assumptions/dependencies: domain-specific VAEs/encoders and datasets; retraining the modality embedder for new conditions
- Agentic creative assistants combining LLMs and MMFace-DiT
- Sectors: creative tooling, marketing
- Tools/workflows: agents that turn briefs into masked layouts and prompts, iterate with feedback, and produce consistent face assets
- Assumptions/dependencies: integration with LLM planning, asset management pipelines; safety filters and usage tracking
- End-to-end watermarking and provenance by default
- Sectors: policy, platforms, media
- Tools/workflows: embed C2PA/cryptographic watermarks during generation; provide APIs for verification and content labeling
- Assumptions/dependencies: industry standards adoption; robust, hard-to-remove watermarks; user education
- Bias auditing and fairness probes for downstream systems
- Sectors: policy, compliance, academia
- Tools/workflows: controlled generation of demographic/attribute combinations via text prompts and masks to probe model or system biases
- Assumptions/dependencies: comprehensive prompt taxonomies; independent evaluation protocols; transparent reporting
- Marketplace for controllable face assets and templates
- Sectors: creator economy, stock media
- Tools/workflows: curated packs of sketch/mask templates and prompt presets for reproducible looks (e.g., hairstyles, accessories)
- Assumptions/dependencies: licensing frameworks; content moderation; provenance metadata
- Higher-resolution, identity-consistent portrait pipelines
- Sectors: photography, digital art
- Tools/workflows: super-resolved outputs (≥1024²) with per-subject identity anchors; consistent series for campaigns
- Assumptions/dependencies: scaling the DiT and VAE; identity conditioning mechanisms (e.g., reference encoders); compute budgets
Cross-cutting assumptions and dependencies
- Scope and modality: current model is trained for faces with masks/sketches at up to 512²; new domains/modalities (e.g., depth, pose, landmarks) and higher resolutions require retraining or fine-tuning.
- Pretrained components: relies on CLIP text encoders and VAEs (Flux or others); licenses and compatibility must be confirmed for commercial use.
- Data and bias: FFHQ/CelebA-HQ and VLM-generated captions carry demographic and aesthetic biases; applications must include bias audits and mitigation.
- Safety and compliance: consider watermarking, provenance (e.g., C2PA), content moderation, and clear labeling of synthetic media to address policy, legal, and ethical concerns.
- Compute and latency: real-time or video applications will need model distillation, caching, and acceleration beyond the presented training/inference setup.
Glossary
- Adaptive Layer Normalization (AdaLN): A conditioned layer-normalization that modulates activations using external signals for fine-grained control. "modulated by a global conditioning vector ($C_{\text{global}$) via AdaLN."
- bfloat16 precision: A 16-bit floating-point format that preserves a wide exponent range for faster, memory-efficient training. "including bfloat16 precision, 8-bit AdamW, full gradient checkpointing, and precomputed VAE latents."
- CLIP Distance: A text–image misalignment metric derived from CLIP embeddings; lower is better. "we quantify text-image alignment using CLIP Score and Distance"
- CLIP encoder: A pretrained text encoder that maps prompts to embeddings aligned with visual features. "a text prompt is encoded into text tokens by a CLIP encoder"
- CLIP Score: A text–image alignment metric based on cosine similarity in CLIP space; higher is better. "we quantify text-image alignment using CLIP Score and Distance"
- Compositional frameworks: Methods that combine multiple pretrained models at inference rather than training a unified model. "inference-time compositional frameworks~\cite{nair2023unite, huang2023collaborative} attempt to combine uni-modal generators"
- ControlNet: A conditioning adapter that adds trainable branches to frozen diffusion backbones for spatial control. "ControlNet~\cite{zhang2023adding} introduces spatial control by attaching trainable auxiliary modules to large, pre-trained T2I diffusion models."
- Denoising Diffusion Probabilistic Models (DDPM): Generative models that iteratively remove noise from data through a learned reverse diffusion process. "predicts either the noise (DDPM) or the velocity (RFM)."
- Diffusion Transformer (DiT): A transformer-based backbone for diffusion models offering scalable image generation. "However, the introduction of DiT~\cite{DiT2023} marked a pivotal moment"
- Dual-stream design: An architecture with separate but fused pathways for different modalities (e.g., image and text). "its dual-stream design treats these conditions as co-equals"
- Entangled latent spaces: Representations where factors of variation are not disentangled, making targeted edits difficult. "suffer from entangled latent spaces, hindering the representation of fine-grained attributes"
- Flow-matching objectives: Training objectives that learn continuous velocity fields between noise and data for generative modeling. "Ours (F), trained using flow-matching objectives."
- Fréchet Inception Distance (FID): A distributional metric of image realism comparing features of generated and real images; lower is better. "Image realism is measured by Fréchet Inception Distance (FID)"
- Gated Residual Connections (Gate): Residual connections modulated by learned scalars to control information flow between components. "Gated Residual Connections (Gate) for dynamically balancing information flow"
- GeLU activation: A smooth nonlinear activation function often used in transformer MLPs. "with a GeLU activation~\cite{hendrycks2016gaussian} between the two linear layers."
- Gradient checkpointing: A memory-saving technique that recomputes intermediate activations during backpropagation. "including bfloat16 precision, 8-bit AdamW, full gradient checkpointing, and precomputed VAE latents."
- Latent Diffusion Models (LDMs): Diffusion models operating in a compressed latent space for efficiency. "more efficient Latent Diffusion Models (LDMs)"
- Latent space: A compressed representation space (e.g., from a VAE) where diffusion operates. "Our model operates in a VAE's latent space."
- Learned Perceptual Image Patch Similarity (LPIPS): A perceptual distance metric using deep features; lower is better. "Learned Perceptual Image Patch Similarity (LPIPS)"
- mean Intersection-over-Union (mIoU): A segmentation metric measuring overlap between predicted and ground-truth masks. "mean Intersection-over-Union (mIoU)."
- Min-SNR weighting: A DDPM training reweighting strategy that balances contributions from different noise levels. "we adopt the Min-SNR weighting strategy~\cite{hang2023efficient}"
- Modality Embedder: An embedding module that encodes the active spatial modality (e.g., mask or sketch) for dynamic conditioning. "a novel Modality Embedder enables a single cohesive model to dynamically adapt to varying spatial conditions"
- Modal dominance: A failure mode where one modality overpowers another during fusion. "shared RoPE attention prevents modal dominance"
- Multi-head attention: An attention mechanism with multiple parallel heads to capture diverse dependencies. "The central fusion mechanism is a single, shared multi-head attention operation."
- Patch embedding: A projection of image (or latent) patches into token embeddings for transformer processing. "A patch embedding layer projects this combined tensor into a sequence of flattened image tokens"
- Pixel Accuracy (ACC): A segmentation accuracy metric measuring the fraction of correctly classified pixels. "For masks, we evaluate structural integrity with Pixel Accuracy (ACC) and mean Intersection-over-Union (mIoU)."
- Rectified Flow Matching (RFM): A flow-based generative training paradigm that learns a straightened velocity field between noise and data. "we also adopt the widely popular Rectified Flow Matching paradigm"
- Rotary Position Embeddings (RoPE): A position-encoding scheme applying rotations to queries/keys for relative positional modeling. "We apply Rotary Position Embeddings (RoPE) to the combined query and key tensors."
- SegFormer (face-parsing): A transformer-based segmentation model used here to produce facial semantic masks. "semantic masks using a pre-trained Segformer face-parsing model"
- Sinusoidal timestep embedder: A periodic embedding mapping diffusion timesteps to vectors for conditioning. "Here, $E_{\text{time}$ is a sinusoidal timestep embedder"
- Structural Similarity Index Measure (SSIM): A multi-scale perceptual similarity metric for image quality; higher is better. "multi-scale Structural Similarity Index Measure (SSIM)"
- StyleGAN latent manipulation: Editing images by operating in StyleGAN’s latent space to control attributes. "rely on StyleGAN latent manipulation, which suffers from entangled representations"
- U-Net: A convolutional encoder–decoder architecture previously standard for diffusion denoisers. "the U-Net architecture was the de facto standard for the denoising network."
- U2Net: A deep network for salient object detection used here to extract sketches. "sketches via the U2Net model~\cite{qin2020u2}."
- Unpatchifying: Reassembling tokens back into image patches before decoding. "The final image is produced by unpatchifying the output tokens"
- Variance schedules: Noise schedules in diffusion training/inference controlling variance over timesteps. "This formulation eliminates the need for variance schedules"
- Variational Autoencoder (VAE): A generative encoder–decoder that maps images to and from a latent space. "Our model operates in a VAE's latent space."
- Velocity field: A vector field indicating direction and speed from noise to data in flow-based generative models. "which treats diffusion as learning a velocity field between noise () and data ()."
- Visual LLM (VLM): A multimodal model jointly processing images and text for tasks like captioning. "InternVL3~\cite{zhu2025internvl3} Visual LLM (VLM)."
Collections
Sign up for free to add this paper to one or more collections.