Drop the Hierarchy and Roles: How Self-Organizing LLM Agents Outperform Designed Structures
Abstract: How much autonomy can multi-agent LLM systems sustain -- and what enables it? We present a 25,000-task computational experiment spanning 8 models, 4--256 agents, and 8 coordination protocols ranging from externally imposed hierarchy to emergent self-organization. We observe that autonomous behavior already emerges in current LLM agents: given minimal structural scaffolding (fixed ordering), agents spontaneously invent specialized roles, voluntarily abstain from tasks outside their competence, and form shallow hierarchies -- without any pre-assigned roles or external design. A hybrid protocol (Sequential) that enables this autonomy outperforms centralized coordination by 14% (p<0.001), with a 44% quality spread between protocols (Cohen's d=1.86, p<0.0001). The degree of emergent autonomy scales with model capability: strong models self-organize effectively, while models below a capability threshold still benefit from rigid structure -- suggesting that as foundation models improve, the scope for autonomous coordination will expand. The system scales sub-linearly to 256 agents without quality degradation (p=0.61), producing 5,006 unique roles from just 8 agents. Results replicate across closed- and open-source models, with open-source achieving 95% of closed-source quality at 24x lower cost. The practical implication: give agents a mission, a protocol, and a capable model -- not a pre-assigned role.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “Drop the Hierarchy and Roles: How Self-Organizing LLM Agents Outperform Designed Structures”
What this paper is about (overview)
This paper asks a big question: When you have many AI “agents” (think smart chatbots) working together, what is the best way for them to coordinate so they solve tasks well, quickly, and cheaply? The authors tested different ways of organizing teams of AI agents and found a surprising result: giving the group a tiny bit of structure but letting each agent choose its own role works better than strict top-down control or total freedom.
What the researchers wanted to find out (key objectives)
The study focused on simple, practical questions:
- Which team setup helps groups of AI agents produce the best answers: a boss assigning roles, everyone working freely, or something in between?
- Does adding more agents always help, or can it hurt?
- Do stronger AI models (smarter agents) make self-organizing teams work better than weaker ones?
- Can teams figure out roles by themselves without humans pre-assigning them?
- Can cheaper, open-source AIs perform close to expensive, closed-source ones?
How they tested it (methods in everyday language)
The researchers ran over 25,000 tasks using different teams of AI agents (from 4 up to 256 agents) and 8 different AI models. They tried 8 ways (“protocols”) for the agents to coordinate. They measured:
- Quality (how good the answer is)
- Time (how long it took)
- Cost (how many tokens the AI used)
- Risk (e.g., mistakes or policy issues)
- Mission relevance (how useful the answer is for the goal)
To grade the answers fairly, a separate “judge” AI (not the same model doing the work) scored each result on five things: accuracy, completeness, clear structure, how actionable it is, and how well it fits the mission.
They compared four main coordination styles:
- Coordinator (centralized): One “boss” agent assigns everyone’s jobs.
- Sequential (hybrid): Agents take turns in a fixed order. Each one sees what earlier agents produced, then decides whether to help and what role to take.
- Broadcast (signals): Agents announce their intended roles, then decide after seeing others’ intentions.
- Shared (fully autonomous): Everyone decides at the same time, using a shared memory of past roles.
Think of it like this:
- Coordinator = a conductor tells each musician what to play.
- Shared = everyone starts playing at once based on past concerts.
- Broadcast = everyone says what they plan to play, then adjusts.
- Sequential = each musician plays after hearing all previous parts and chooses the instrument/part that best fills the gap.
They also tested different task difficulties, from simple (single-topic) to very hard (conflicting goals, incomplete information), and “shock” scenarios (like removing some agents mid-task) to see how resilient teams were.
What they discovered (main findings and why they matter)
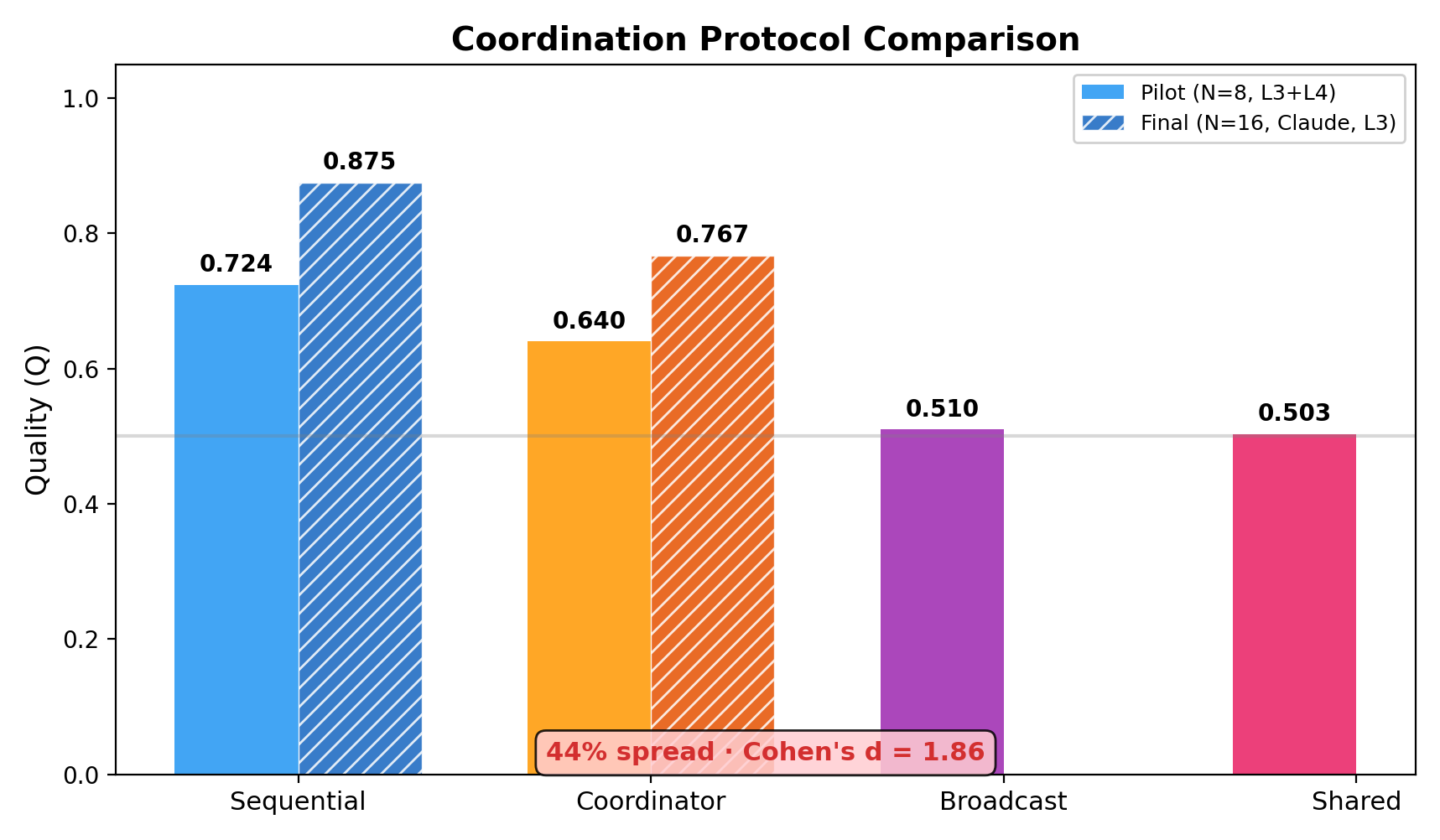
The headline finding is called the “endogeneity paradox”: neither total control nor total freedom works best. The best results came from a middle approach.
- The hybrid Sequential protocol won. With a fixed order but free role choice, it beat:
- Centralized control by about 14% (statistically very strong result).
- Fully autonomous “Shared” by about 44% (a huge difference).
- Why Sequential works: Each agent gets the most useful information—the actual outputs from the agents before them on this exact task. That’s better than:
- A boss’s single plan (limited perspective),
- Others’ intentions (which can change),
- Old history (which may not fit the new task).
- It’s like a sports draft: each pick fills the next needed role after seeing what’s already chosen.
Other important results:
- Self-organization needs a capable model and the right protocol. Strong models + the right protocol = great results. Weak models can’t self-organize well; they do better with more rigid structure.
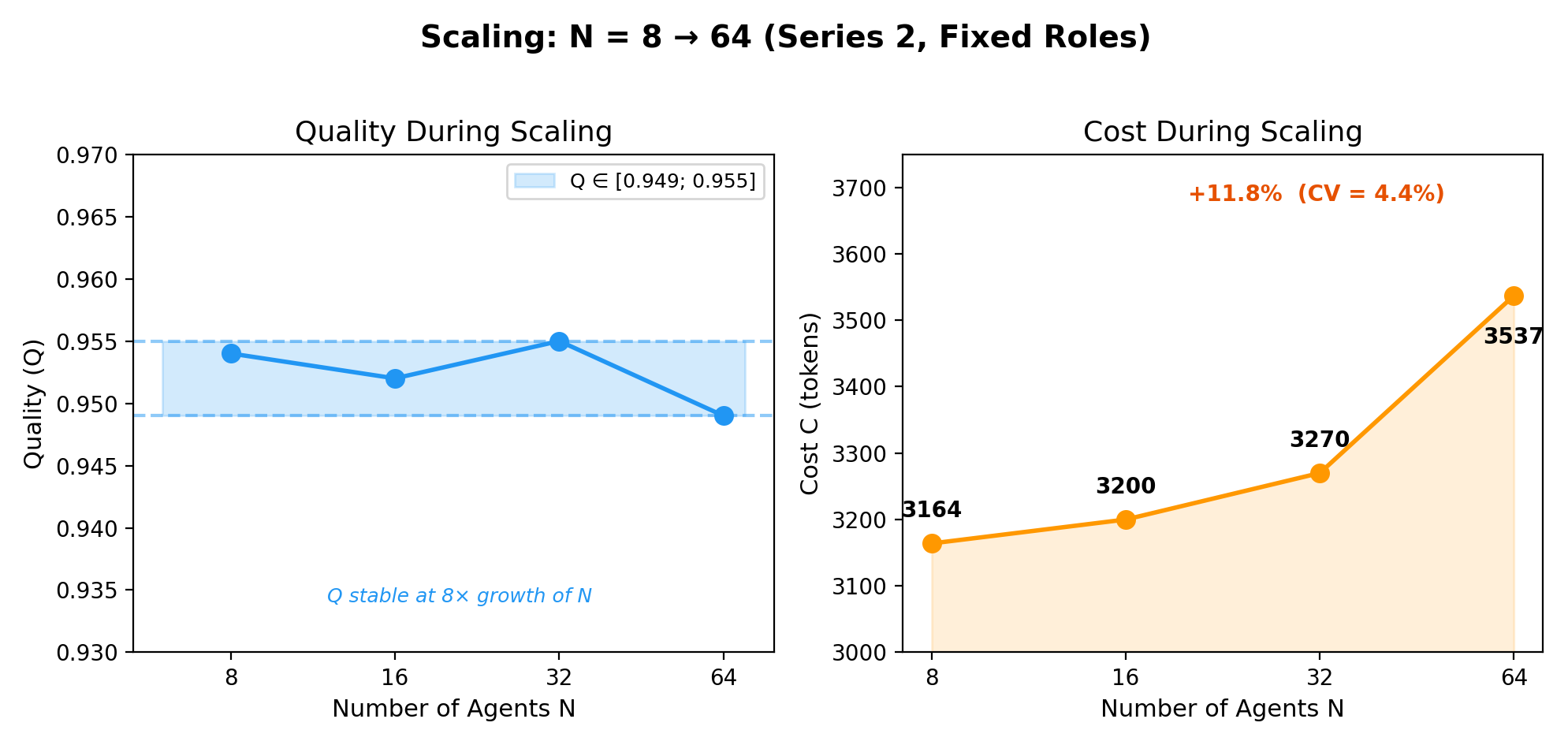
- More agents isn’t always better. Scaling from 64 to 256 agents didn’t improve quality, even though it cost more. The system stayed stable, but there were no big gains.
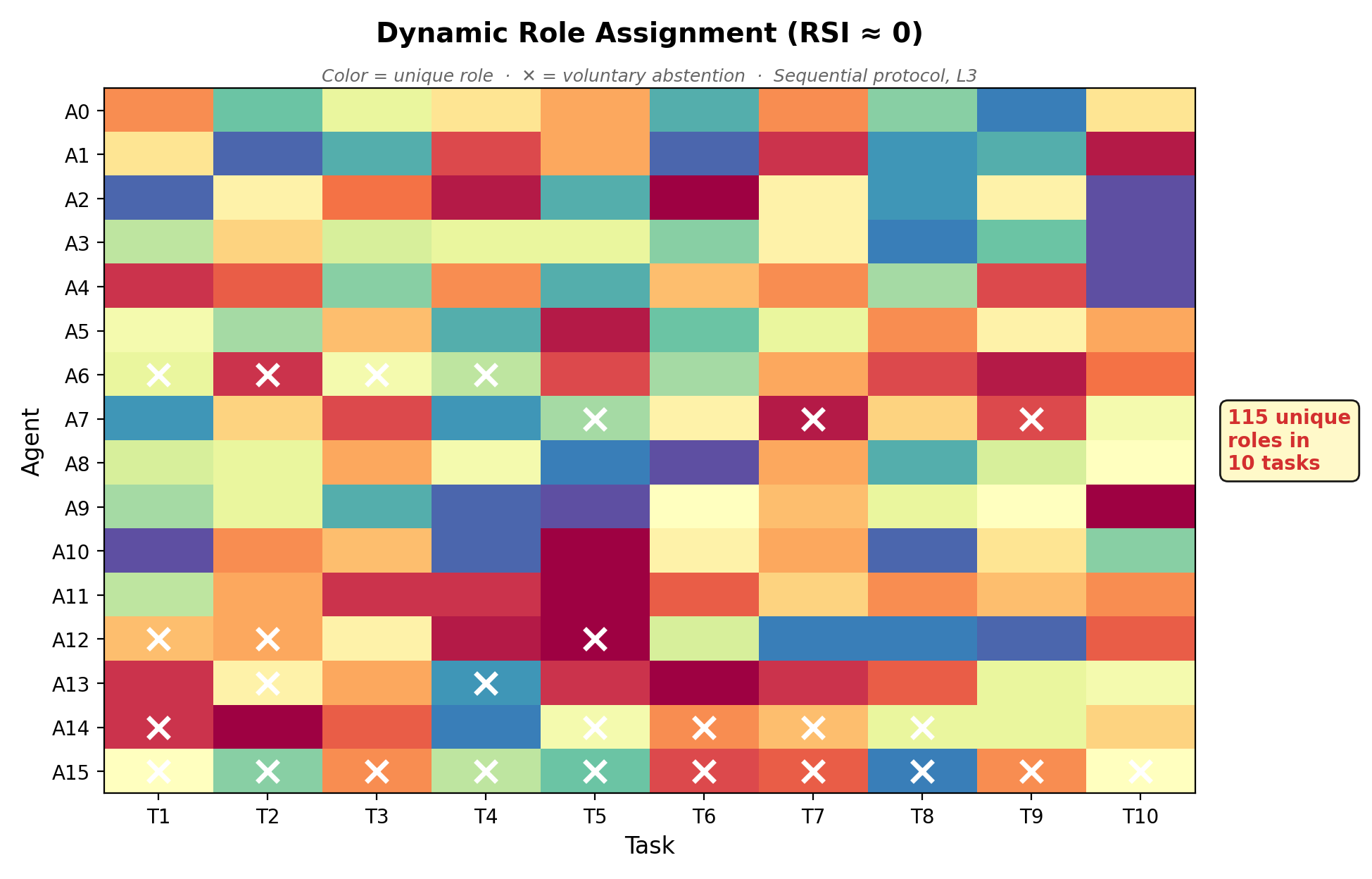
- Emergent behaviors appeared (no one hard-coded them):
- Dynamic role invention: agents created thousands of unique roles without being told.
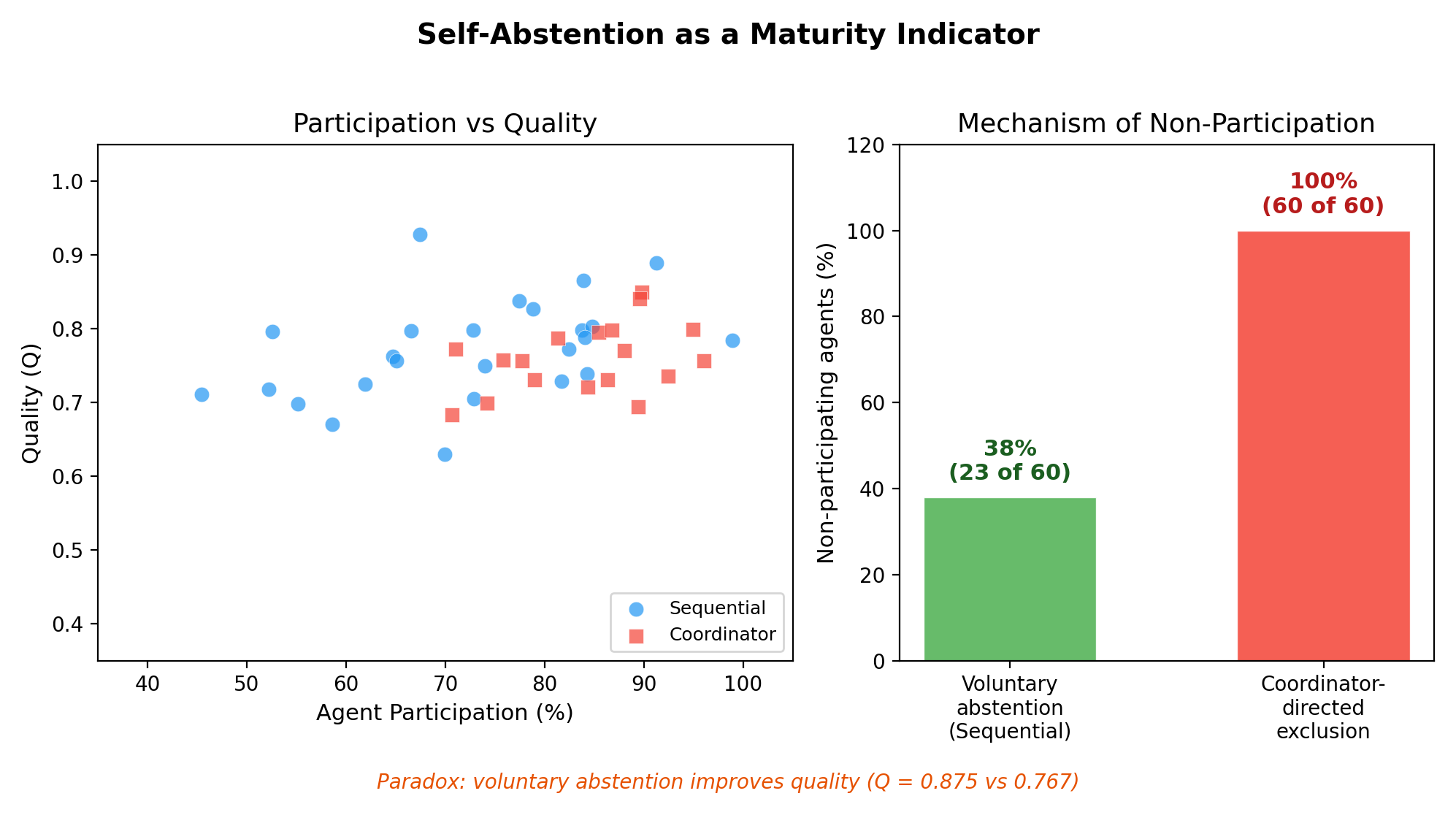
- Voluntary self-abstention: agents chose to sit out when they weren’t helpful, reducing noise and cost.
- Shallow, natural hierarchies: teams organized themselves into simple structures when tasks got harder, without being told to do so.
- Open-source models are competitive. One open-source model reached about 95% of a top closed-source model’s quality at roughly 24× lower cost. That’s a big deal for affordability.
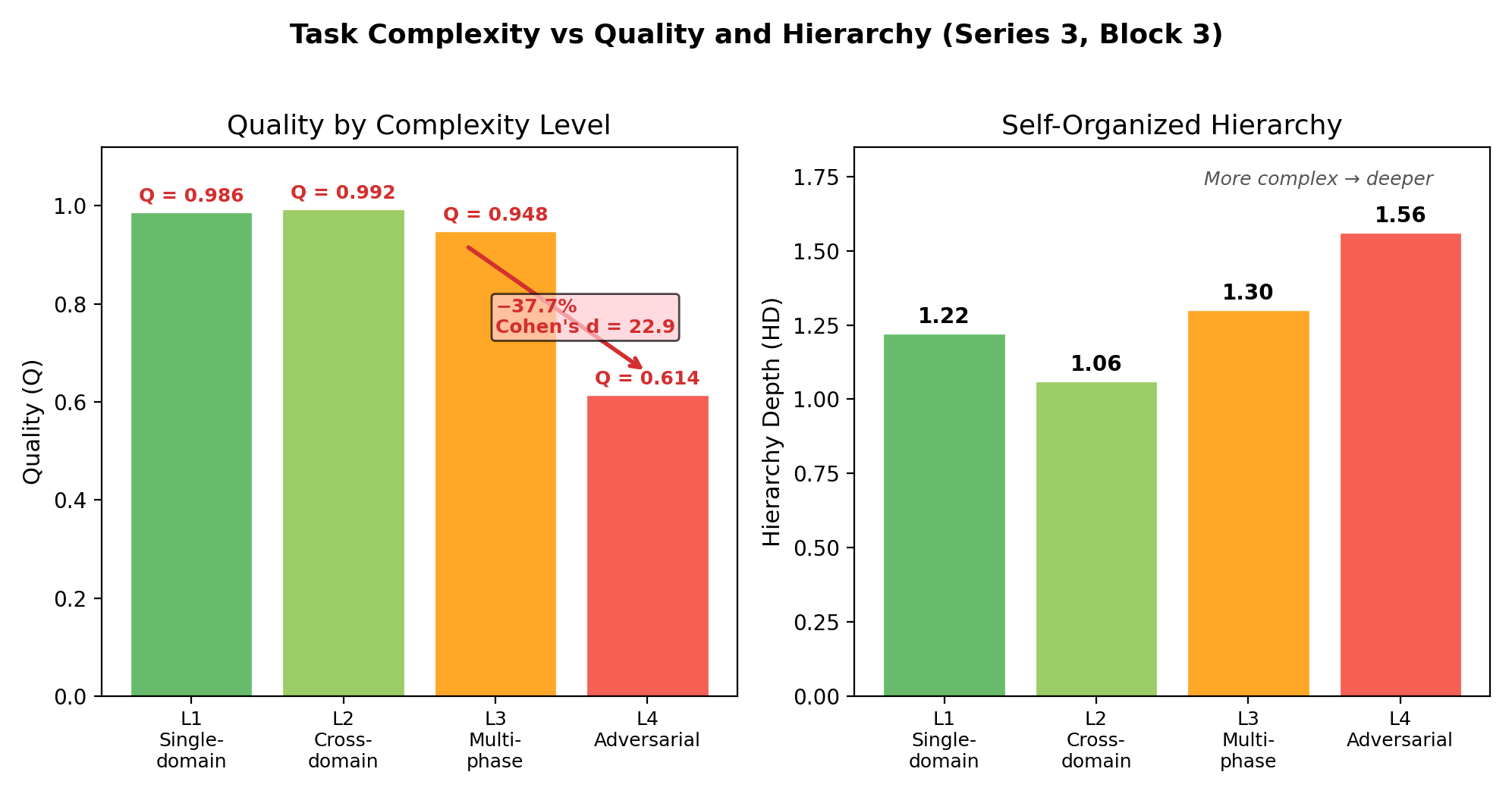
- Hard tasks remain hard. On the toughest tasks with conflicting goals, quality dropped a lot—showing where today’s systems still struggle.
Why this matters (implications and impact)
This research suggests a better way to build AI teams:
- Don’t pre-assign fixed roles like “designer,” “tester,” or “manager.” Unlike people, AI agents can switch specialties instantly. Let them pick roles based on the task at hand.
- Give a clear mission and a good protocol. The protocol (how agents coordinate) is a powerful “amplifier.” The Sequential approach—fixed order, free role choice—helps agents complement each other naturally.
- Invest in quality models and the right coordination, not just bigger teams. After a point, adding more agents doesn’t help.
- Use a simple “constitution” for AI teams:
- Humans set the mission and values (the why).
- Humans and system set standards and metrics (how to measure).
- The system runs and tunes the coordination protocol (the how).
In short: If you give AI agents a clear goal, a smart way to coordinate (like Sequential), and strong enough models, they can self-organize—deciding who should do what—often better than if you try to design all the roles and hierarchy yourself. This could make future AI workplaces more flexible, cheaper, and more effective.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
The following list enumerates concrete gaps and open questions that remain unresolved and could guide follow-on research:
- Human evaluation gap: all quality assessments use LLM judges; no human-grounded validation exists to quantify judge bias, agreement with expert raters, or sensitivity to verbosity and formatting.
- Cross-judge calibration missing: judge changed between series (GPT-4o → GPT-5.4) without a completed anchor set for cross-series normalization; how much the judge swap alone shifts absolute and relative scores is unknown.
- Synthetic-to-real transfer: findings are based on synthetic tasks; it remains untested whether the “endogeneity paradox” and protocol rankings hold on real production workflows and benchmarks.
- Reproducibility under API drift: results rely on API-hosted models whose behavior can change over time; no frozen checkpoints or replication with fixed local models have been provided to quantify drift impact.
- Protocol-confound ablation: the Sequential advantage may stem from differences in information exposure (observing concrete predecessors’ outputs) rather than “ordering” per se; no controlled ablation equalizing information content across protocols is reported.
- Ordering sensitivity: the Sequential protocol uses a fixed agent order, but the paper does not study how different orderings (randomized, competence-informed, rotating) affect quality, fairness, and participation.
- Latency bottleneck unresolved: Sequential’s O(N) latency is acknowledged but not mitigated experimentally; no empirical evaluation of batched Sequential (O(N/K)) or hybrid wave protocols is provided.
- Context growth and window limits: as N increases, later agents in Sequential may face long contexts; no analysis of truncation strategies, context overflow, or quality impact of context compression is included.
- Asynchrony and partial observability: all coordination appears synchronous; the effects of asynchronous updates, delayed signals, limited bandwidth, or lossy channels on protocol performance are untested.
- Ambiguous aggregation/termination: it is unclear how the system determines when a task is complete and how multiple agent outputs are consolidated into a final answer across protocols.
- Role uniqueness measurement validity: “5,006 unique roles” are counted by role name strings; no semantic clustering or normalization is used to distinguish true functional diversity from naming variance.
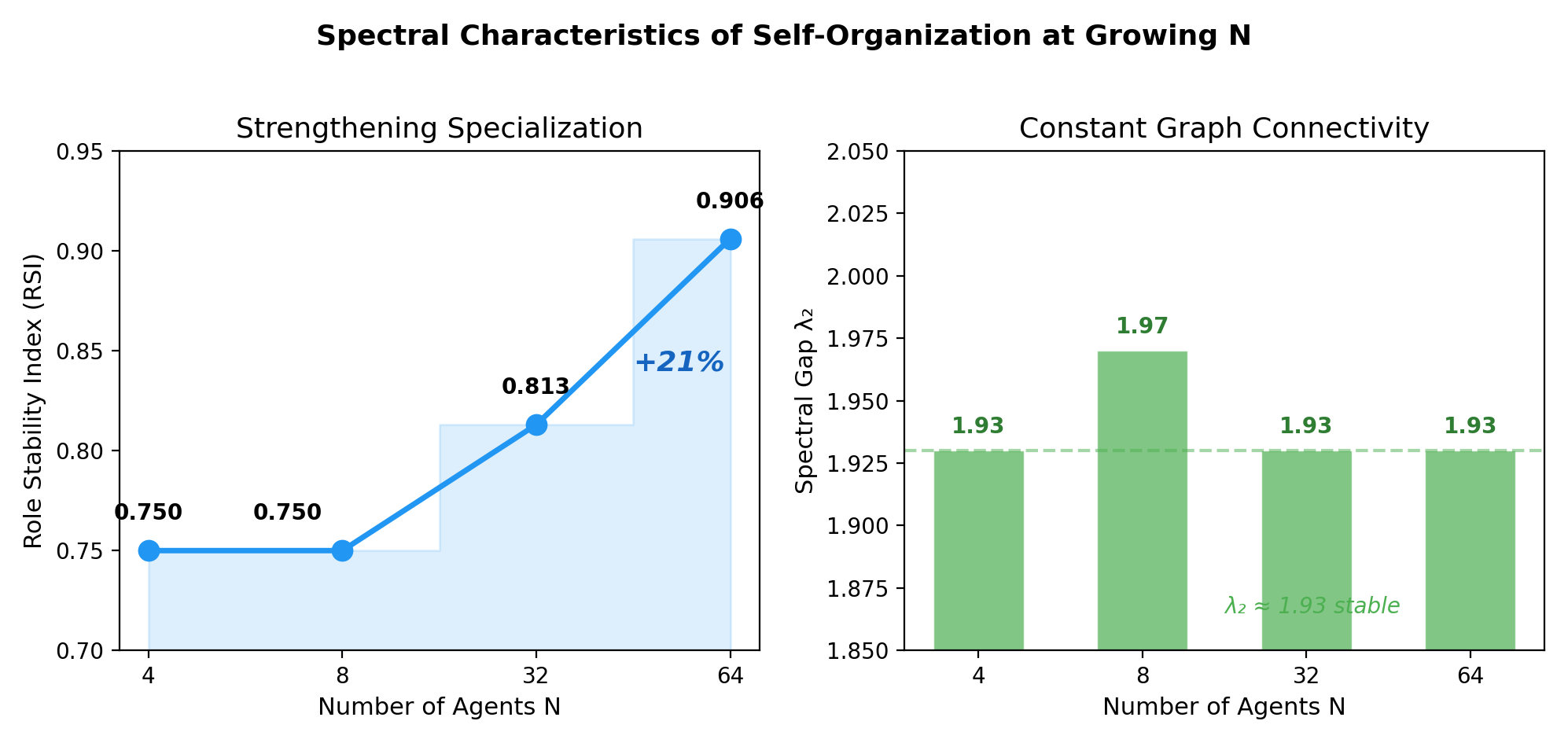
- RSI construct inconsistency: the paper reports RSI→0 in protocol-based self-organization and RSI increasing in spectral experiments; a unified, operational definition and mapping between “stability,” “specialization,” and “fluidity” is lacking.
- Hierarchy Depth (HD) definition: HD is reported (e.g., 1.22, 1.56) without a clear algorithmic definition for extracting dependency chains from text outputs; non-integer HD and its interpretation are not justified.
- Resilience Index (RI) opacity: RI is cited (e.g., 0.959) without a formal definition or computation procedure; “recovery within 1 iteration” is ambiguous across different protocols’ time steps.
- Capability threshold operationalization: the “threshold” for when autonomy helps vs hurts is qualitatively described but not quantified with diagnostics or predictive markers (e.g., abstention rate, chain-of-thought depth) across models and tasks.
- Heterogeneous multi-model teams: although “combine models” is recommended, no experiments systematically evaluate mixed-model teams, dynamic model routing, or allocation policies within the same run.
- Risk metric under-specified: R_t (compliance, errors) is included in objectives but not operationally defined or reported per protocol/model; the safety implications of self-organization remain unquantified.
- Cost accounting comparability: “24× cheaper” comparisons use API prices and token counts but do not incorporate compute/energy for self-hosted opensource models or throughput/latency trade-offs.
- Scaling on complex tasks: large-N scaling results are shown primarily on L1 tasks; the scalability of Sequential and others on L3–L4 (adversarial, multi-phase) at N≥64 remains unexplored.
- Baseline breadth: comparisons are against internal abstractions (Coordinator, Shared, Broadcast, Sequential); direct replications of established systems (e.g., ChatDev, MetaGPT, AutoGen) as baselines under identical tasks are not reported.
- Adversarial/poisoned agents: shock tests cover removals and model substitution, but robustness to actively malicious or colluding agents, misinformation cascades, and protocol exploitation is not evaluated.
- Tool-use and multimodality: experiments focus on text-only agents; how protocols perform with tool execution (code, APIs), retrieval, or vision/multimodal inputs remains unknown.
- Long-horizon organizational memory: “Shared” uses role history, but lifelong learning, catastrophic forgetting, and memory governance across extended task sequences are not characterized.
- Hyperparameter sensitivity: effects of temperature, prompt variants, and sampling seeds on outcomes and variability are not systematically analyzed; confidence intervals for key deltas are sparse.
- Multiple-comparison control: while main effects likely survive Bonferroni, a comprehensive correction for all tests and dependencies is not provided; some reported p-values lack accompanying effect sizes.
- Coordination overhead metric: “coordination overhead = 0.180” is reported without a formal definition, units, or decomposition into planning vs messaging vs computation.
- “J_judge” and Balance Index transparency: the meaning and computation of J_judge (e.g., 0.719) and the sensitivity of the Balance Index to chosen weights are not documented or stress-tested.
- Fairness and positional effects: potential first-mover or last-mover advantages in Sequential ordering (e.g., early agents shaping later context) are not measured; fairness-aware scheduling policies are untested.
- Information-theoretic grounding: the claim that Sequential’s informational advantage drives performance is not formalized; no value-of-information or causal mediation analysis is performed.
- Governance framework validation: the proposed three-ring constitution is conceptual; no implementation, metrics for compliance, or experiments verifying its effectiveness are presented.
- Task/domain coverage: generalization to domains beyond the tested synthetic set (e.g., legal drafting, medical, scientific reasoning with citations) and multilingual settings remains untested.
- Communication budget trade-offs: bandwidth and message length constraints (per-agent or global) are not varied to map protocol performance under realistic communication limits.
- Reproducibility artifacts: code, prompts, and data are promised upon acceptance; independent replication is not currently possible, and run-to-run variance across labs is unknown.
Practical Applications
Immediate Applications
Below are specific, deployable use cases that translate the paper’s findings into real-world value across sectors. Each item notes candidate tools/workflows and key feasibility assumptions.
- Software engineering (code and doc quality pipelines)
- Use case: Replace rigid, pre-assigned agent roles with a Sequential orchestrator for code review, security assessment, and documentation refinement where each agent reads and improves on the previous output.
- Tools/workflows: Add a “Sequential protocol” mode to existing agent frameworks (e.g., AutoGen-like platforms); implement “abstention-aware” prompts; introduce metrics dashboards for RSI (Role Stability Index) and Hierarchy Depth (HD).
- Assumptions/dependencies: Access to a model above the capability threshold for L3 tasks; tolerance for O(N) latency for small teams (4–16 agents); secure code/data handling.
- Security operations and incident response (SOC/IR)
- Use case: Turn-based “situation room” where detection → triage → containment → forensics are performed by agents that self-select roles and voluntarily abstain when unqualified, improving clarity and reducing duplicate work.
- Tools/workflows: SOC runbooks re-implemented as Sequential agent chains; shock tests to validate rapid recovery; “capability-threshold switch” to fall back to Coordinator when the model underperforms.
- Assumptions/dependencies: Human approval gates for high-severity actions; auditable logs; strong model for L3+ reasoning.
- Compliance, policy analysis, and regulatory briefings
- Use case: Sequentially synthesized briefs where each agent (policy analyst, risk officer, auditor persona) builds on prior outputs; abstention reduces noise; emergent shallow hierarchy improves coherence.
- Tools/workflows: Mission- and metrics-first governance (three-ring framework) with Ring 1 (mission/values) set by humans; Sequential drafting + human sign-off.
- Assumptions/dependencies: Strict privacy/compliance controls; human-in-the-loop for L4/adversarial topics; consistent prompts across runs.
- Enterprise analytics and BI reporting
- Use case: Turn-based pipeline for data extraction, validation, insight creation, and QA, with agents only contributing when confident; reduces error propagation and verbosity.
- Tools/workflows: “Sequential notebook” patterns; judge model or rules for actionability/accuracy scoring; abstention logging for audit.
- Assumptions/dependencies: Reliable data connectors; calibrated thresholds for abstention; model quality adequate for domain numeracy.
- Customer support triage and resolution
- Use case: Sequential multi-agent handling (triage → root-cause hypothesis → solution draft → QA), enabling dynamic specialization without hard-coded roles.
- Tools/workflows: Integration with ticketing (e.g., Zendesk/Jira) via agent middleware; voluntary abstention to prevent spurious replies; cost-aware model routing (open-source for L1–L2 tickets).
- Assumptions/dependencies: Latency acceptable for queue-based workflows; red-teaming to prevent policy-violating responses; model selection per task class.
- Strategic and operational planning (OKRs, roadmaps, RFP responses)
- Use case: Agents iteratively refine strategy documents, budgets, and risk registers in sequence; emergent shallow hierarchies keep plans coherent without micromanaged roles.
- Tools/workflows: “Turn-by-turn strategy” templates; Mission Relevance scoring as a gating metric; cost dashboards using Q per 1K tokens.
- Assumptions/dependencies: Senior stakeholder oversight; data provenance and version control; capable models for cross-domain synthesis (L3).
- Mixed-model cost optimization in production agent stacks
- Use case: Route simpler L1–L2 tasks to low-cost open-source models and L3–L4 tasks to stronger models, within the same Sequential pipeline, to achieve near-closed-source quality at lower cost.
- Tools/workflows: Dynamic model router using task complexity classifiers; token budget guardrails; “Q per 1K tokens” KPI.
- Assumptions/dependencies: Stable open-source deployments; licensing/compliance review; reliable task complexity detection.
- Internal AI governance rollouts (three-ring constitution)
- Use case: Adopt the paper’s mission/standards/protocols layering so humans lock “why,” while the system autonomously A/B tests “how” (protocol parameters) within guardrails.
- Tools/workflows: Ring 1 policy registry; Ring 2 audit and metrics service; Ring 3 protocol experimentation service with rollback.
- Assumptions/dependencies: Clear risk appetite; change management; executive sponsorship.
- Academic research workflows (literature reviews and meta-analyses)
- Use case: Turn-based agent teams for survey writing: retrieval → screening → synthesis → critique; role fluidity avoids premature specialization and coverage gaps.
- Tools/workflows: Sequential integration with scholarly APIs; judge model for completeness/coherence; disclosure of LLM contribution.
- Assumptions/dependencies: Human validation for key claims; reproducible prompts/logs; attention to bias in LLM-as-judge.
- Classroom and collaborative learning
- Use case: “Turn-based group writing/analysis” where students or teaching assistants coordinate with agents in a Sequential flow; teaches structured collaboration and critique.
- Tools/workflows: LMS plugins for sequential contributions; rubric-aligned judge feedback; abstention prompts to encourage recognizing limits.
- Assumptions/dependencies: Academic policies on AI usage; accessibility and fairness considerations.
- Personal productivity assistants
- Use case: Multi-tool itinerary planning, budgeting, or home projects using a turn-based pipeline (gather options → consolidate → constraints check → finalize), with abstention on low-confidence steps.
- Tools/workflows: Personal agent apps with a Sequential mode; plug-ins for travel, calendars, and finance tools.
- Assumptions/dependencies: User consent for data aggregation; latency tolerance; transparency for final decisions.
- Vendor/platform enhancements for agent orchestration
- Use case: Add first-class “Sequential protocol” and “voluntary abstention” capabilities to agent platforms; provide observability for emergent metrics (RSI, HD, resilience).
- Tools/workflows: Orchestrator middleware; batched logs and spectral statistics; auto-fallback to centralized Coordinator for weaker models.
- Assumptions/dependencies: Backward compatibility; clear SLAs for API rate limits; evaluation harness with human spot checks.
Long-Term Applications
These applications require additional research, scaling, or development (e.g., latency mitigation, human validation for high-stakes tasks, and stronger models for L4/adversarial complexity).
- Batched Sequential orchestration at scale
- Vision: Reduce O(N) latency by grouping K agents in parallel rounds while preserving the “see prior outputs” advantage.
- Tools/products: A “Batched Sequential” scheduler with tunable K; parallel wave execution (“Ripple”) for adversarial tasks.
- Assumptions/dependencies: Careful information propagation to avoid reintroducing duplication; benchmarking under real workloads.
- Autonomous AI organizations with constitutional governance
- Vision: Semi-autonomous units optimize protocols and team composition under a three-ring constitution; humans set mission and standards, agents self-organize operations.
- Tools/products: Protocol AB-testing engine; mission invariants enforcement; compliance audit trails.
- Assumptions/dependencies: Mature risk controls; organizational readiness; legal clarity on responsibility and liability.
- High-stakes decision support (healthcare, finance, critical infrastructure)
- Vision: Sequential, self-organizing “AI committees” for care pathway planning, portfolio risk reviews, or grid operations—agents add value or abstain, with human adjudication.
- Tools/products: FDA/EMA-style validation pipelines; traceable chain-of-reasoning; domain-tuned abstention thresholds.
- Assumptions/dependencies: Human oversight mandated; robust calibration to avoid over/under-abstention; validated datasets; regulatory approval.
- Multi-model, self-improving agent teams (vertical × horizontal compounding)
- Vision: Combine self-improving agents (vertical intelligence) with Sequential self-organization (horizontal intelligence) to compound gains.
- Tools/products: “Hyperagents in sequence” frameworks; automated capability assessment to set autonomy levels.
- Assumptions/dependencies: Safe self-modification protocols; catastrophic forgetting safeguards; compute governance.
- Government policy development and stakeholder negotiation (L4 tasks)
- Vision: Turn-based, multi-stakeholder drafting and critique for complex, adversarial policies with transparent trade-offs and traceable edits.
- Tools/products: Stakeholder simulation sandboxes; deliberation logs; fairness/bias auditing.
- Assumptions/dependencies: Improved L4 performance; diverse human oversight; public transparency requirements.
- Robotics and cyber-physical teams
- Vision: Extend Sequential coordination to multi-robot or sensor-fusion teams where each unit conditions on prior observations/actions to reduce conflict and redundancy.
- Tools/products: Edge-friendly sequencers; time-synced “wave” protocols; safety cages for actuation.
- Assumptions/dependencies: Real-time constraints; robust comms; mapping textual coordination into control policies.
- Decentralized autonomous organizations (DAOs) and on-chain governance
- Vision: Self-organizing agent committees propose and refine governance actions sequentially; abstention reduces governance noise/spam.
- Tools/products: On-chain protocol orchestrators; auditability and dispute resolution layers.
- Assumptions/dependencies: Legal frameworks for AI agents; sybil resistance; economic incentive alignment.
- Standards and audits for autonomous multi-agent systems
- Vision: Industry standards for protocol selection, abstention rights, and emergent metrics (RSI, HD, resilience indices) to certify quality and reliability.
- Tools/products: Compliance test suites; shock-resilience benchmarks; cross-judge calibration protocols.
- Assumptions/dependencies: Multi-stakeholder consensus; regulator buy-in; shared datasets and scoring rubrics.
- Education platforms for role-fluid collaboration
- Vision: Curricula and tools that teach students to operate in role-fluid, turn-based teams with reflective abstention and mission-first coordination.
- Tools/products: Classroom simulators with Sequential orchestration; instructor dashboards for contribution quality.
- Assumptions/dependencies: Pedagogical validation; equity/access controls; academic integrity policies.
- Enterprise “agent ops” (AIOps for agents)
- Vision: Full lifecycle management of agent organizations—capacity planning (no benefit beyond ~64 active agents), cost/quality routing, shock drills, and observability.
- Tools/products: AgentOps consoles; auto-scaling based on mission relevance; model/version management.
- Assumptions/dependencies: Clear ROI measurement; integration with enterprise IT; governance alignment.
- Evaluation science: human–LLM hybrid judging
- Vision: Replace pure LLM-as-judge with calibrated, hybrid human-in-the-loop evaluations and cross-judge alignment across series and domains.
- Tools/products: Human review panels with rubric-guided sampling; automatic drift detection for judge models.
- Assumptions/dependencies: Budget for human evaluation; standardized task banks; inter-rater reliability processes.
- Cross-sector crisis response and resilience
- Vision: Large, self-organizing, shock-resilient agent networks across agencies and utilities, coordinating sequentially for rapid recovery and adaptive planning.
- Tools/products: Inter-agency protocol bridges; resilience playbooks validated by perturbation tests.
- Assumptions/dependencies: Data-sharing agreements; secure comms; improved performance on adversarial tasks.
Notes on Feasibility and Dependencies (common across items)
- Capability threshold: Self-organization yields benefits only with sufficiently strong models (e.g., high reasoning and instruction following); otherwise centralized/structured coordination may outperform.
- Latency: Pure Sequential is O(N) in latency; acceptable for small teams and offline workflows; requires batching or wave-based variants for large, real-time systems.
- Human oversight: Necessary for high-stakes (L4/adversarial) tasks; use human gates and rigorous audits.
- Cost–quality routing: Exploit open-source models for simpler tasks to capture cost advantages; maintain high-end models for complex cases.
- Data governance: Privacy, security, and provenance controls must be embedded; comprehensive logging for auditability.
- Evaluation: Replace or augment LLM-as-judge with human evaluation for production acceptance; track Mission Relevance and Balance Index alongside quality.
Glossary
- Adaptation time: Time required for the system to recover performance after a perturbation (denoted $T_{\text{adapt}$). "Adaptation time ($T_{\text{adapt}$) improves with system size: adaptation speed as increases, suggesting that larger self-organizing systems heal faster."
- Balance Index: A composite metric that aggregates normalized quality, mission relevance, time, cost, and risk into a single score. "A Balance Index aggregates all metrics:"
- Batched Sequential: A proposed variant of the Sequential protocol that groups agents into parallel batches to reduce latency while preserving information flow. "Batched Sequential for reduced latency."
- Bonferroni correction: A statistical adjustment for multiple comparisons that tightens significance thresholds to control family-wise error. "remain significant under Bonferroni correction for the number of comparisons reported ($\alpha_{\text{corrected} = 0.05/20 = 0.0025$)."
- Broadcast (protocol): An endogenous, signal-based coordination mechanism where agents first declare role intentions in parallel, then finalize decisions. "Broadcast (signal-based, endogenous): Two rounds---agents first broadcast role intentions simultaneously, then make final decisions informed by all intentions."
- Capability threshold: A minimum model ability level required for self-organization to be beneficial; below it, rigid structures perform better. "establishing a capability threshold below which self-organization reverses and fixed structure becomes beneficial."
- Clonal (protocol): A bio-inspired coordination mechanism (details deferred) evaluated alongside other nature-derived protocols. "Four additional bio-inspired protocols (Morphogenetic, Clonal, Stigmergic, Ripple) were also tested; their detailed results will be reported in a forthcoming companion paper."
- Coefficient of variation (CV): A normalized measure of dispersion (standard deviation divided by mean), used here to summarize cost variability. "CV~"
- Cohen's d: A standardized effect size quantifying the magnitude of differences between conditions. "Cohen's ()."
- Complete topology: A network structure in which every agent is connected to every other agent. "Three shock types were tested on agents (Complete topology):"
- Coordinator (protocol): A centralized, exogenous coordination scheme with a single agent assigning roles and phases to others. "Coordinator (centralized, exogenous): Agent~0 acts as an external coordinator, analyzing the task and assigning roles and phases to all other agents, who execute in parallel."
- Directed Acyclic Graph (DAG): A directed graph with no cycles; used to represent agent routing or workflows. "retrieves optimal Directed Acyclic Graphs (DAGs) for agent routing"
- Endogeneity paradox: The non-monotonic finding that neither maximal centralization nor full autonomy is optimal; a hybrid with minimal structure performs best. "Our key finding is the endogeneity paradox: a hybrid protocol (Sequential) where agent ordering is fixed but role selection is autonomous outperforms both centralized coordination (, ) and fully autonomous protocols (, Cohen's , )."
- Endogenous coordination: Organizational structure and roles that emerge from within the agent system during execution. "We distinguish between exogenous coordination (structure imposed externally) and endogenous coordination (structure emerging from within the system)."
- Exogenous coordination: Organizational structure and roles imposed externally before or during execution. "We distinguish between exogenous coordination (structure imposed externally) and endogenous coordination (structure emerging from within the system)."
- Gini coefficient: An inequality index measuring concentration or diversity, here applied to role distribution. "Gini = 0.055"
- Hierarchy Depth (HD): The longest chain of dependencies between agents, indicating the depth of the emergent hierarchy. "We report the self-organized Hierarchy Depth (HD), measured as the longest chain of agent dependencies in each run."
- Kruskal–Wallis test: A non-parametric statistical test for comparing multiple groups without assuming normality. "The Kruskal-Wallis test yields , "
- LLM-as-a-judge: An evaluation methodology using a separate LLM to assess solutions across predefined criteria. "Quality assessment uses a multi-criteria LLM-as-a-judge methodology."
- Mean-Field Game: A modeling approach where individual agents interact with the aggregate effect of the population, used here for fixed-role coordination. "Mean-Field Game (fixed roles, population-level coordination)"
- Mission Relevance: An evaluation criterion measuring how well outputs align with the stated mission. "Mission Relevance reaches $4.00/4.00$ for both Claude and DeepSeek on Sequential L3 tasks."
- Morphogenetic (protocol): A bio-inspired coordination mechanism (details deferred) included among additional protocols. "Four additional bio-inspired protocols (Morphogenetic, Clonal, Stigmergic, Ripple) were also tested; their detailed results will be reported in a forthcoming companion paper."
- Power-law network: A topology where node degree distribution follows a power law, yielding hubs and many low-degree nodes. "across complete, chain, and power-law networks"
- Resilience Index (RI): A metric quantifying the system’s ability to maintain or quickly recover performance after shocks. "The Spectral Hierarchy model achieved the highest Resilience Index () with zero quality variance"
- Role Stability Index (RSI): A measure of how consistently agents maintain roles across tasks; near zero indicates high role fluidity. "RSI~"
- Sequential (protocol): A hybrid coordination scheme with fixed agent ordering but autonomous role selection and participation choices. "The hybrid Sequential protocol achieves the highest quality in both settings."
- Shared (protocol): A fully autonomous, parallel coordination scheme where agents make decisions simultaneously using shared memory. "Shared (fully autonomous, endogenous): Agents have access to a shared organizational memory (role history from previous tasks) and make all decisions simultaneously and independently."
- Spectral gap (λ2): The second-smallest eigenvalue of the graph Laplacian; indicates connectivity and robustness of interaction networks. "the spectral gap remains stable, indicating constant graph connectivity."
- Spectral Hierarchy: A coordination model where hierarchy emerges dynamically via spectral analysis of agent contributions. "Spectral Hierarchy (dynamically emergent hierarchy based on spectral analysis of agent contributions)"
- Sparse Graph: A topology-dependent coordination model emphasizing limited, structured connections among agents. "Sparse Graph (topology-dependent coordination across complete, chain, and power-law networks)"
- Stigmergic (protocol): A bio-inspired coordination mechanism where agents coordinate indirectly through environmental signals. "Four additional bio-inspired protocols (Morphogenetic, Clonal, Stigmergic, Ripple)"
- Sub-linear scaling: Growth in resource use or cost that increases less than proportionally with the number of agents, while maintaining quality. "The system scales sub-linearly to 256 agents ()"
- TextGrad: An evolutionary, gradient-inspired optimization technique for improving agent populations via textual feedback. "EvoAgentX uses evolutionary optimization (TextGrad) to adapt agent populations but requires gradient-based training."
- Voluntary self-abstention: An emergent behavior where agents choose not to participate if their contribution is likely to be unhelpful. "voluntary self-abstention"
- Zero-shot runtime self-organization: The ability of agents to self-organize effectively without additional training or fine-tuning at runtime. "zero-shot runtime self-organization"
Collections
Sign up for free to add this paper to one or more collections.

