- The paper introduces a framework showing that intra-signal spectral gaps in the parameter update matrix underlie phase transitions like grokking and circuit formation in neural networks.
- It employs three axioms and coupled ODEs to decompose signal hierarchies, quantify gap dynamics, and assess stability across different training regimes.
- Empirical results confirm that spectral gap ratios correlate with validation loss shifts, supporting architecture-independent predictions for feature learning.
The Spectral Edge Thesis: A Mathematical Framework for Intra-Signal Phase Transitions in Neural Network Training
Introduction and Motivation
"The Spectral Edge Thesis: A Mathematical Framework for Intra-Signal Phase Transitions in Neural Network Training" (2603.28964) presents a cohesive theory linking phase transitions during neural network training—including grokking and circuit formation—to the intra-signal spectral gap structure of the parameter update Gram matrix. The framework is architecture-agnostic and derives its main results from first principles, employing three axioms that govern the trajectories of parameter updates in extreme aspect ratio regimes (p≫W). It explicitly argues that classical BBP (Benaych–Georges–Peché) noise frameworks are vacuous in typical modern neural network settings, establishing that every observable eigenvalue is signal; the operative structure is therefore a gap within the signal, not between signal and noise.
Mathematical Foundations
The thesis constructs a spectral flow theory for neural network training based on three axioms:
- Hierarchical Signal Decomposition: The trajectory matrix admits a decomposition into dominant signal, subdominant signal, and negligible noise, with the noise operator norm far below the smallest signal singular value.
- Spectral Gap Structure: The signal singular values possess a maximal consecutive gap at position k∗, marking the separation between dominant and subdominant modes.
- Slow Variation: Signal directions and strengths are approximately constant within each rolling window, enabling perturbative analysis.
In this regime, the Gram matrix G=XX⊤ of rolling-window parameter updates (X∈RW×p, p∼108, W∼10) contains only signal eigenvalues, confirmed empirically by σW/dcrit∼20–$300$ across multiple model families. The classical noise threshold is never approached.
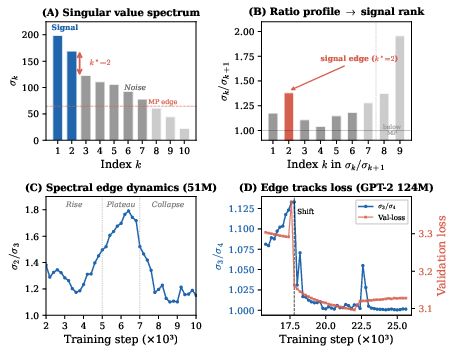
Figure 1: The spectral edge framework. (A) Singular value spectrum for TinyStories~51M exhibits a sharp intra-signal gap at k∗=2. (B) Ratio profile σk/σk+1, the maximal point defining signal rank. (C) Gap ratio over training follows a three-phase pattern: rise, plateau, collapse. (D) Gap ratio tracks validation loss for GPT-2~124M, phase transitions coincide with loss plateaus.
Signal Hierarchy and Gap Dynamics
The spectral gap emerges from the Hessian eigenvalue hierarchy, with phase transitions tied to level crossings of signal strengths. The thesis gives a formal definition for spectral gap position:
k∗0
where k∗1 are the ordered singular values of the trajectory matrix. This gap separates the dominant backbone modes from subdominant, coherent but weaker directions. Importantly, empirical results show k∗2 across model families, optimizer-dependent (e.g., Muon drives k∗3, AdamW k∗4).
Phase transitions—grokking, circuit emergence, capability gain—are marked by the collapse or opening of the spectral gap. Subspace stability is controlled by the Davis–Kahan k∗5 theorem, which depends only on the gap size, not whether it separates signal from noise or intra-signal modes.
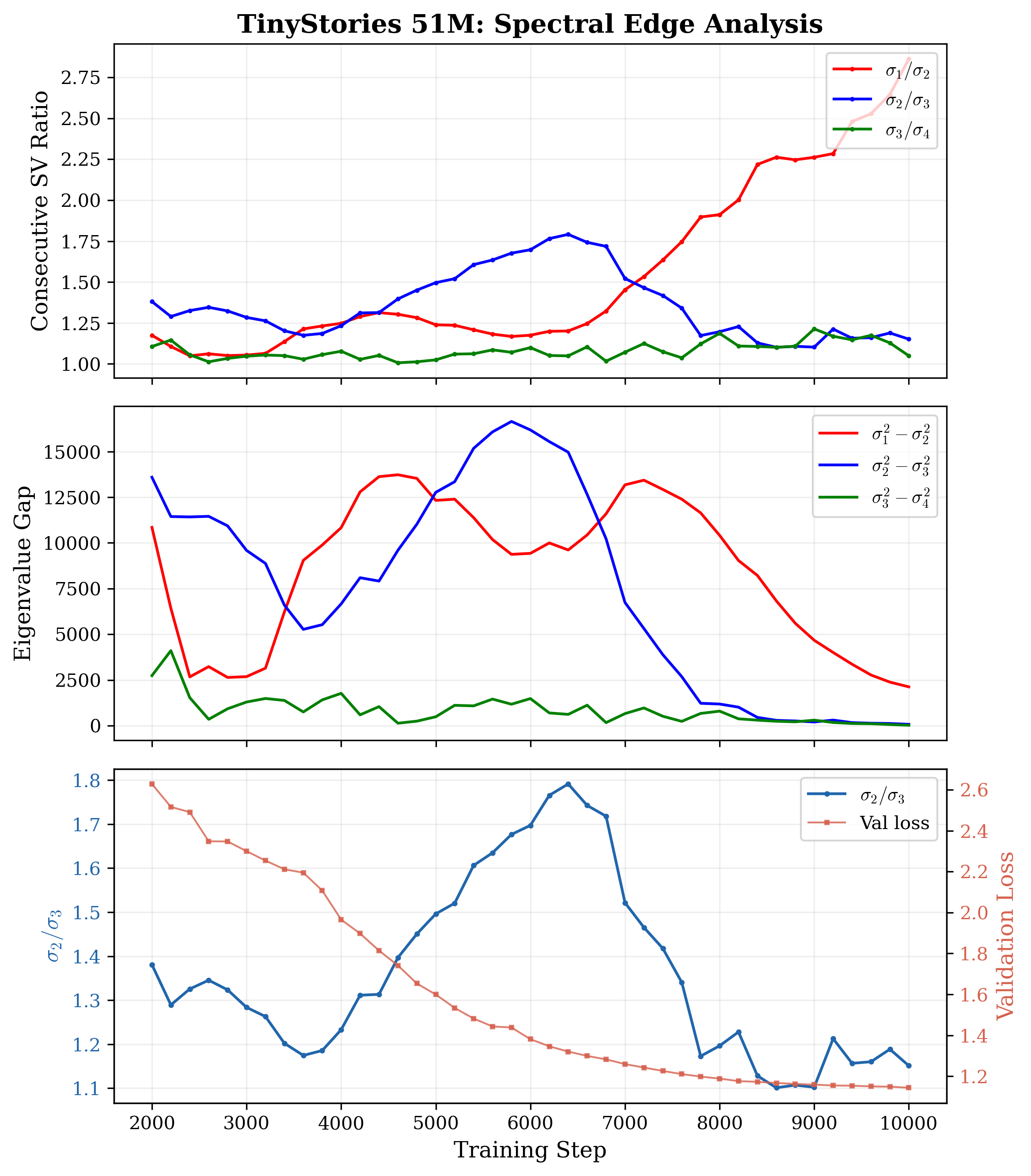
Figure 2: Spectral edge analysis for TinyStories~51M illustrating consecutive singular value ratios, gap phases, and correspondence with validation loss.
Dynamical Flow Equations
A suite of coupled ODEs governs the evolution of signal strengths k∗6, gap position k∗7, and gap size k∗8. The core equation:
k∗9
where G=XX⊤0 is the Rayleigh quotient of the Hessian (curvature), G=XX⊤1 mode coupling (conservative), and G=XX⊤2 the injection from nonlinearity (anharmonic correction; measurable directly from trajectory statistics). Circuit stability follows from the adiabatic parameter G=XX⊤3; stability only prevails when G=XX⊤4.
Gap flow dynamics are determined by curvature asymmetry, damping from weight decay, and gradient projection imbalances. Level repulsion during eigenvalue crossings ensures phase transitions are avoided crossings, with subspace mixing sharply localized at the gap boundary.
Empirical Verification
The thesis validates its predictions across a battery of experiments—TinyStories 51M, GPT-2 124M, Dyck-1/SCAN grokking, modular arithmetic grokking, multi-task setups. Key empirical results:
- BBP Threshold is Vacuous: All observed eigenvalues exceed noise threshold by at least an order of magnitude.
- Maximal Ratio for G=XX⊤5: Gap position defined as maximal consecutive ratio explains observed training phenomena.
- Gap–Loss Correlation: Spectral gap ratio is tightly correlated with validation loss plateaus and transitions.
- Stability Hierarchy: G=XX⊤6 (stability coefficient) exhibits exact predicted hierarchy: dominant modes nearly stable, gap mode marginally stable, subdominant modes unstable.
- Grokking as Gap Opening: Generalizing directions are subdominant signals until the gap opens; grokking occurs precisely at gap opening (24/24 with weight decay, 0/24 without).
- Causal Intervention: Removing signal directions degrades learning by the amount predicted by spectral loss decomposition, validated with G=XX⊤7 at sufficient window size.
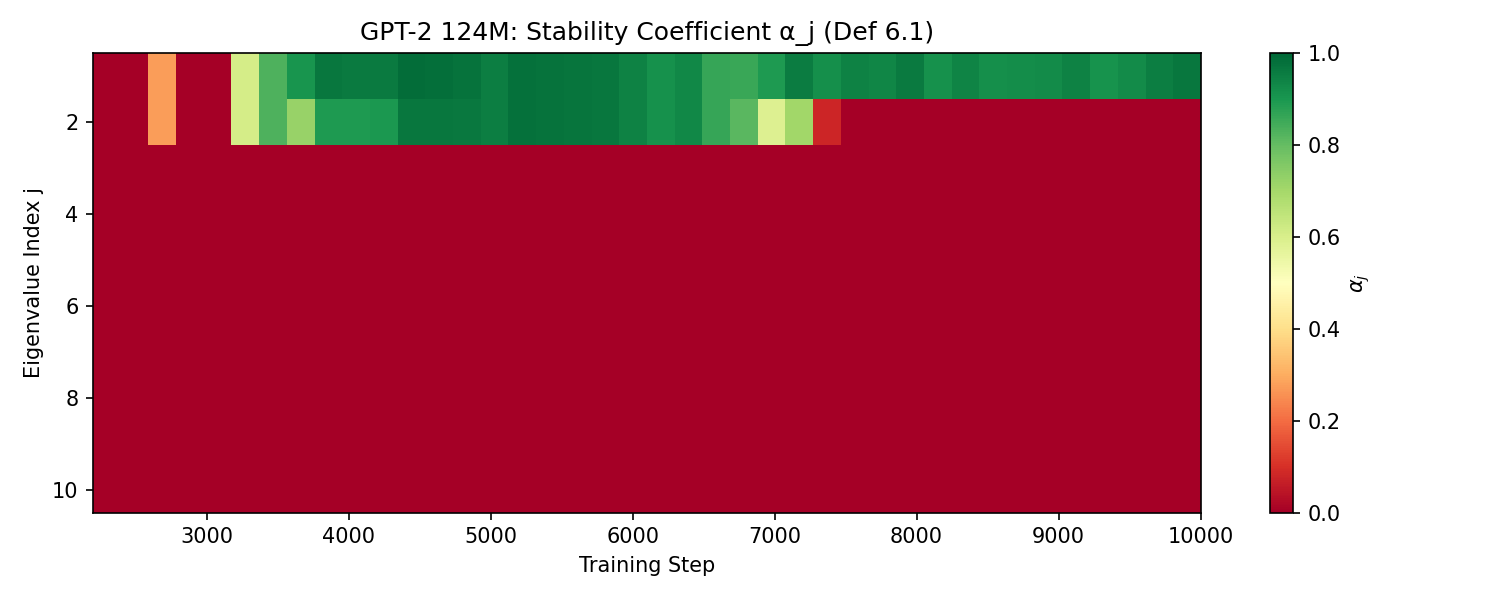
Figure 3: Stability coefficient hierarchy for GPT-2~124M. Dominant modes maintain stability through training while gap modes fluctuate.
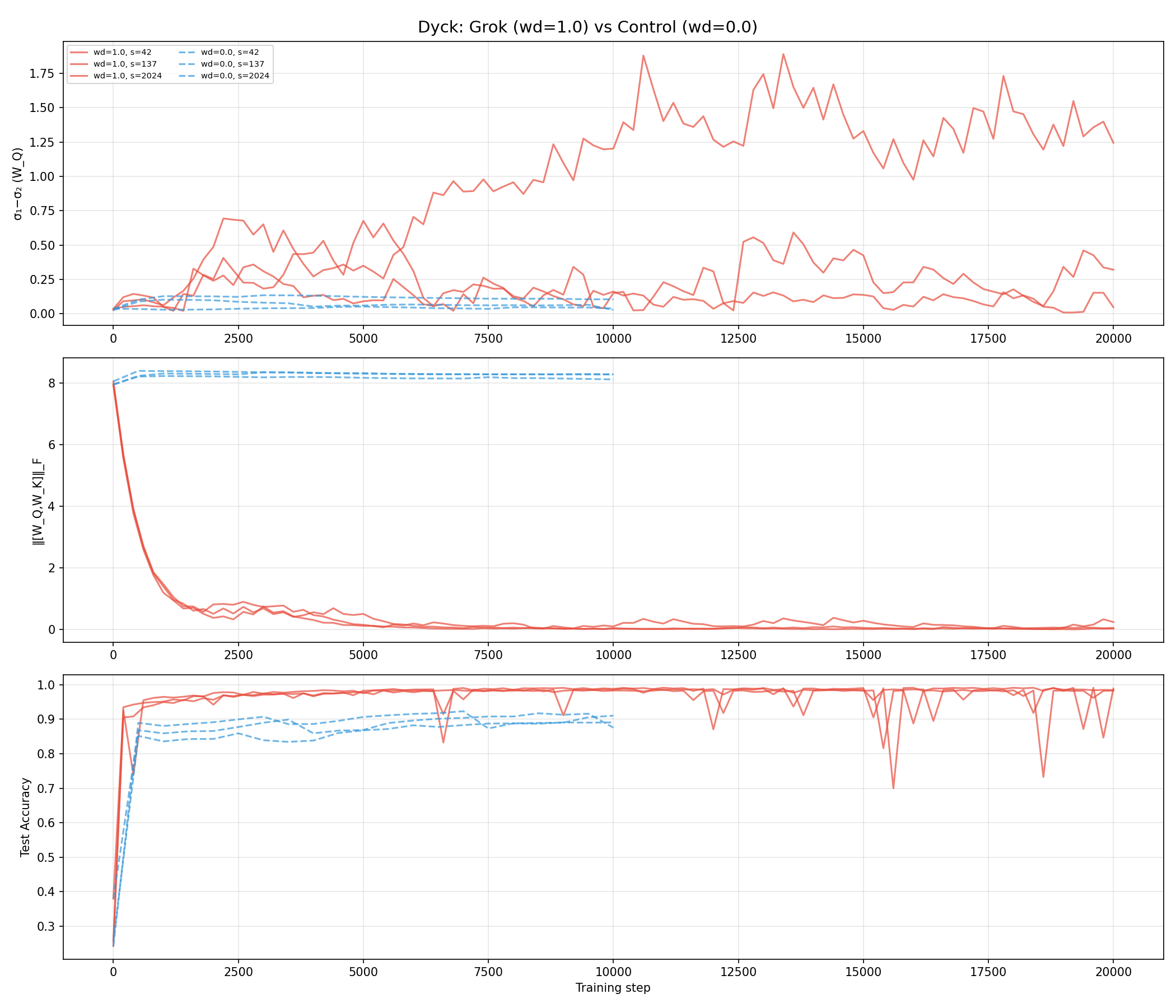
Figure 4: Grokking in Dyck-1 as a spectral edge event. Weight decay opens the gap and enables grokking; controls remain flat and fail to grok.
Theoretical and Practical Implications
The spectral edge thesis unifies diverse phenomena in neural network training:
- Architecture Independence: The signal flow dynamics are geometric, dependent only on NTK eigenvalues, kernel evolution, and gradient statistics; architectural details enter solely via spectral parameters.
- Circuit Formation and Survival: Circuit persistency maps to gap protection—circuits die when the gap closes, are protected by large gaps (deep in the hierarchy), and can be destroyed by weight decay if curvature falls below threshold.
- Scaling Laws: Power-law scaling emerges from spectral tail integrals, consistent with empirical scaling in modern LLMs.
- Foundation for Interpretability: Subspace stability theory gives formal underpinning to circuit analysis, lottery ticket hypothesis, and holographic encoding.
- Optimizer Effects: Signal hierarchy is optimizer-dependent. Optimizers with stronger preconditioning (e.g., Muon) collapse signal rank, modifying gap structure without loss in final capability—suggesting deeper invariance in path-dependent learning.
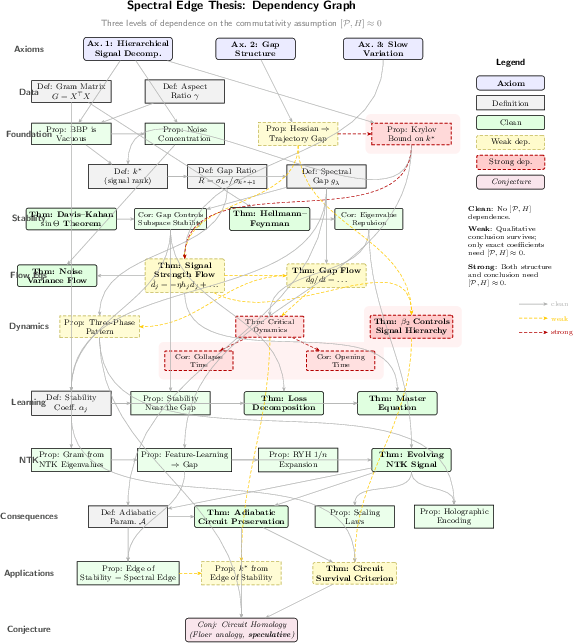
Figure 5: Dependency graph of the spectral edge framework, showing logical separation between diagnostic, learning-theoretic, flow, and optimizer-dependent elements.
Connections to Prior Frameworks
The thesis aligns with, and extends, multiple foundational theories:
- Edge of Stability: Quantitative agreement via spectral activation threshold, explaining empirically small G=XX⊤8.
- Tensor Programs / NTK: Signal formation maps to outlier NTK eigenvalues in feature-learning regimes; kernel regime produces degenerate Gram matrices with no intra-signal gap.
- Roberts–Yaida–Hanin Criticality: Initial NTK spectrum and kernel evolution rate provide starting point for gap dynamics.
- Lottery Ticket Hypothesis: Signal gap ensures pruning fidelity, circuit survival, and explains “winning ticket” phenomenon as spectral filtering.
- Geometric Flow Analogy: The NTK evolution constitutes a geometric flow, with spectral gap corresponding to singularity formation and circuit event dynamics.
Open Problems and Future Directions
The thesis outlines open problems for precise null distributions, scaling of G=XX⊤9, multi-layer phase transitions, prediction of grokking, causal interventions, circuit stability under continual learning, quantitative edge-of-stability predictions, and calculation of higher-order coupling tensors in transformers. Comparative optimizer experiments suggest a Floer-theoretic invariance in circuit formation versus optimizer paths.
Conclusion
The spectral edge thesis delivers a mathematically rigorous, empirically validated framework for interpreting phase transitions—grokking, circuit formation, and feature learning—in terms of intra-signal spectral gap dynamics in neural network training. The theory advances the state of understanding by revealing the primacy of local subspace structure and spectral gap as order parameters, unifying disparate empirical phenomena and prior theoretical constructs under a cohesive scheme. The framework opens principled avenues for both mechanistic interpretability and optimization strategies, and its implications for continual learning, scaling, and architecture-independent generalization promise high impact for future AI research.