- The paper's primary contribution is an RL-based lookahead selection method that improves lap times and generalization by dynamically adapting to track geometry.
- The approach integrates PPO with Pure Pursuit using a five-dimensional observation space, reward shaping, and hyperparameter tuning for robust sim-to-real transfer.
- Experimental results demonstrate significant performance gains over fixed and hand-crafted adaptive controllers in both simulated and real-world racing environments.
Reinforcement Learning-Augmented Dynamic Lookahead Pure Pursuit for Autonomous Racing
Introduction
The paper "Dynamic Lookahead Distance via Reinforcement Learning-Based Pure Pursuit for Autonomous Racing" (2603.28625) presents a hybrid scheme integrating deep reinforcement learning—specifically, PPO—with the classical Pure Pursuit (PP) path tracking controller, for dynamic online adaptation of the lookahead distance in autonomous racing. Unlike prior rule- or model-based adaptive lookahead methods, the approach formulates the lookahead selection as a one-dimensional continuous control task, with the policy trained in simulation and transferred zero-shot to hardware. The paper’s primary contribution is the demonstration that an RL-based lookahead selection mechanism yields increased lap speed, improved generalization to unseen tracks, and robust sim-to-real transfer, while maintaining interpretability and low computational cost.
Methodology
The system architecture combines precomputed minimum-curvature raceline generation and LiDAR-based Monte Carlo Localization with a PPO-trained policy that dynamically selects the lookahead distance Ld for Pure Pursuit. The observation space for the agent is five-dimensional, incorporating vehicle speed and multi-horizon raceline curvature features. The policy outputs a smoothed, bounded lookahead distance at each control cycle.
Training uses Stable-Baselines3 PPO in the F1TENTH Gym simulator with careful reward shaping, KL-penalty and learning-rate decay for stability, and Optuna-driven hyperparameter tuning. The policy is evaluated on both known and unseen racetracks (Austin for training, Montreal and Yas Marina for zero-shot evaluation), and on a physical 1:10-scale RoboRacer platform.

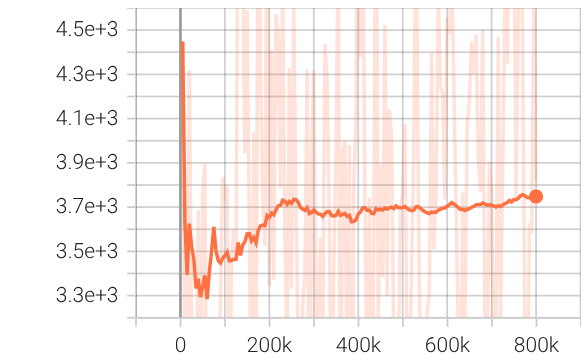
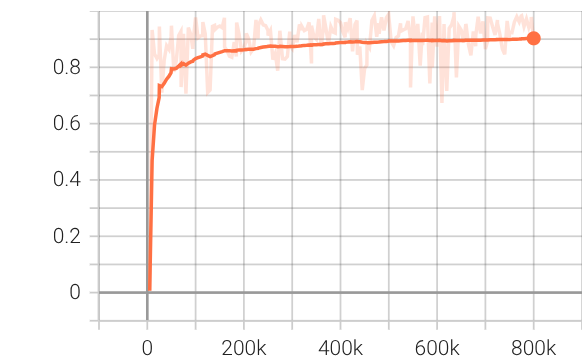
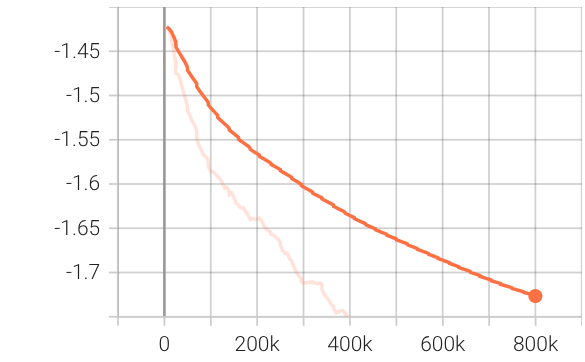
Figure 1: PPO training diagnostics show increasing reward, episode length, critic explained variance, and a controlled decrease of policy entropy, confirming effective convergence.
The policy’s action space controls only the PP lookahead parameter; thus, the geometric and model-based system properties of the baseline controller are retained. All low-level actuation and system integration are handled in ROS2, ensuring modularity and hardware compatibility.
Experimental Results
Quantitative evaluation compares three controllers: fixed-lookahead PP, a hand-crafted speed-dependent adaptive PP, and the RL-augmented Dynamic-L controller. The primary metrics are lap time, repeatability (ten consecutive laps without intervention), and maximum tolerated speed-profile scaling.
Strong numerical results include:
- On Montreal (unseen during training), Dynamic-L achieves 33.16 s/lap under +13% speed scaling, while adaptive PP reaches 34.15 s/lap (+10%), and fixed-L PP requires a reduced speed profile to remain stable (41.36 s/lap).
- On Yas Marina, Dynamic-L achieves 46.05 s/lap (+15% speed), outperforming adaptive PP (46.79 s/lap, +14%) and fixed-L PP (52.81 s/lap at the default speed, unable to tolerate any increase).
- On the physical platform, Dynamic-L successfully completes 10/10 laps (μ=11.13 s, σ=0.26 s) at the reference profile, while fixed-L PP fails to complete repeated laps.
These results establish the claim that learned dynamic adaptation robustly generalizes to new domains and track geometries, tolerating significantly more aggressive speed profiles than either fixed or hand-tuned adaptive baselines, without per-map retuning.
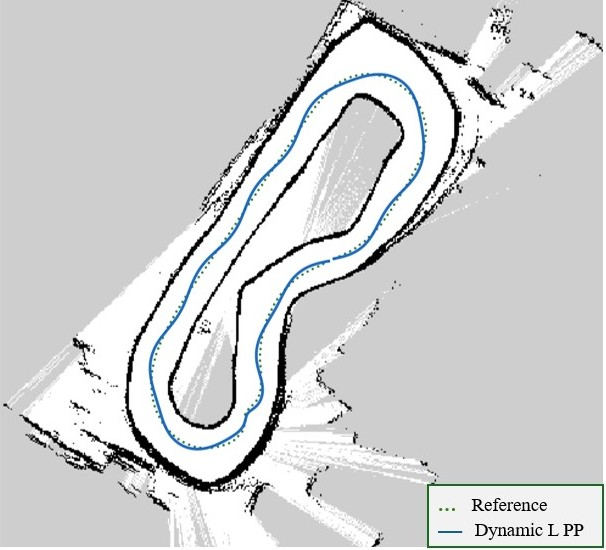
Figure 2: Overlay of a real-car trajectory shows the learned controller closely tracking the reference raceline over repeated laps.
The RL agent produces context-dependent lookahead scheduling: reducing Ld in tight curves (for agile directional changes) and increasing it along straights (for stability and reduced oscillation).
Practical and Theoretical Implications
On the practical side, the method dramatically reduces the tuning burden per new track or vehicle, supporting modular deployment in typical autonomy stacks. Since only a single interpretable parameter (lookahead) is exposed to learning, the system is transparent, debuggable, and integrates smoothly with existing safety and certification pipelines. Sim-to-real transfer is achieved without domain-specific finetuning, demonstrating that the RL-based adaptation is robust against modeling gaps.
Theoretically, the study highlights the efficacy of combining RL with classical control “in the loop,” rather than replacing it wholesale, thereby blending the sample efficiency, stability, and generalization capabilities of geometric control with the adaptability and context-sensitivity of policy learning. The main result—policy improvement without architectural loss of interpretability—addresses a common criticism of end-to-end RL in robotics.
Training curves (Figure 1) show stable value learning and convergence, with reward and explained variance improving throughout PPO training. Hardware trajectory overlays (Figure 2) demonstrate real-world tracking performance and repeated lap completion.
Discussion and Prospects
The work underlines the advantage of framing RL tasks as interpretable parameter adaptation, rather than black-box action prediction. Building upon the present pipeline, future research should evaluate broader class of adaptive controllers, extend state features, and further analyze the contribution of smoothing, state representation, and reward terms. Application to large-scale vehicles, more complex environments (multi-agent, dynamic obstacles), and integration with full-stack path planning are logical next steps.
From the community perspective, the methodology offers a template for synergistic RL-classical controller design, relevant for safety-critical systems and resource-constrained deployment targets.
Conclusion
The integration of PPO-based RL for online lookahead tuning in Pure Pursuit enables high-speed, robust, interpretable autonomous racing, outperforming both fixed and hand-crafted adaptive baselines on simulated and real-world domains (2603.28625). The learned controller adapts effectively to track geometry and speed, minimizes the need for manual retuning, and supports generalization and sim-to-real transfer—a result with direct implications for scalable deployment of adaptive control in practical robotics.

