- The paper introduces CoLMbo-DF, a modular pipeline that integrates acoustic embeddings with explicit, structured evidence for interpretable deepfake detection.
- It employs chain-of-thought supervision, achieving up to 98.7% accuracy on ASVspoof and outperforming larger generic audio models.
- The study underscores the necessity of acoustic feature grounding to enhance both detection performance and model transparency in forensic scenarios.
Audio LLM for Deepfake Detection Grounded in Acoustic Chain-of-Thought: An Expert Analysis
Problem Setting and Motivation
With the increasing realism and ubiquity of audio deepfakes generated by highly capable TTS and voice conversion systems, robust and interpretable detection of synthetic speech is a critical issue in digital forensics, voice authentication, and anti-fraud systems. Traditional detection systems have predominantly relied on hand-engineered, signal-level features, or, more recently, deep learning models leveraging high-capacity self-supervised encoders. While these approaches can yield strong classification performance, they typically offer little in the way of interpretability or structured reasoning—an essential requirement for trustworthiness in high-stakes forensic scenarios.
Chain-of-thought (CoT) prompting has seen substantial success in NLP for injective interpretability into LLMs, but its application to audio-based deepfake detection remains underexplored. Pure end-to-end neural systems typically operate as black boxes, and existing audio LLMs (ALMs), such as CoLMbo and SpeakerLM, either focus narrowly on speaker profiling or generate non-interpretable decisions in a single step.
The paper "Audio LLM for Deepfake Detection Grounded in Acoustic Chain-of-Thought" (2603.28021) addresses this gap by proposing CoLMbo-DF, a lightweight, feature-guided audio LLM that incorporates explicit, structured acoustic evidence into the LLM's input prompt, thereby facilitating transparent chain-of-thought reasoning for deepfake detection.
Model Architecture and Methodology
The core of CoLMbo-DF is a modular pipeline comprising three functional components: a pretrained audio encoder, a trainable audio-to-LLM projector, and a frozen, instruction-following LLM. Audio waveforms are first embedded by a pretrained WavLM-plus model. These frame-level representations are pooled and then mapped via a lightweight projector to LLM-compatible latent prefixes.
Crucially, in addition to implicit acoustic embeddings, interpretable acoustic features—such as pitch, formant frequencies, voice quality, and prosodic patterns—are extracted programmatically, serialized as structured text, and concatenated to the model's input prompt as explicit evidence. During training, the LLM receives projected audio embeddings alongside the structured evidence and is supervised to output a natural-language chain-of-thought supporting its final binary classification (real/fake) as well as structured speaker verification information.
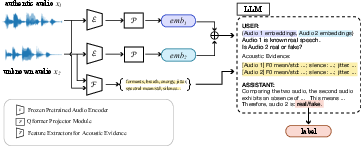
Figure 1: Overview of the CoLMbo-DF pipeline, highlighting audio encoding, feature extraction, evidence injection, and reasoning components.
This architecture explicitly decouples representation learning from downstream reasoning: the LLM is not finetuned as a black box, but rather guided to ground its decisions in interpretable acoustic correlates. Chain-of-thought annotations, generated for each instance in the new FakeReason dataset, supervise the LLM to provide transparent, context-rich justifications.
Dataset and Evidence Grounding
The FakeReason dataset is introduced to facilitate evidence-grounded learning. It combines ASVspoof 2019 data with newly synthesized utterances from modern TTS models (Fish-Speech, CosyVoice2) generated using reference and transcript pairs from VoxCeleb2. This results in labeled audio pairs, each annotated with expert-level chain-of-thought explanations produced by a powerful LLM (Qwen3-30B-A3B-Instruct), further curated via manual editing to ensure alignment with the available acoustic evidence and ground-truth labels.
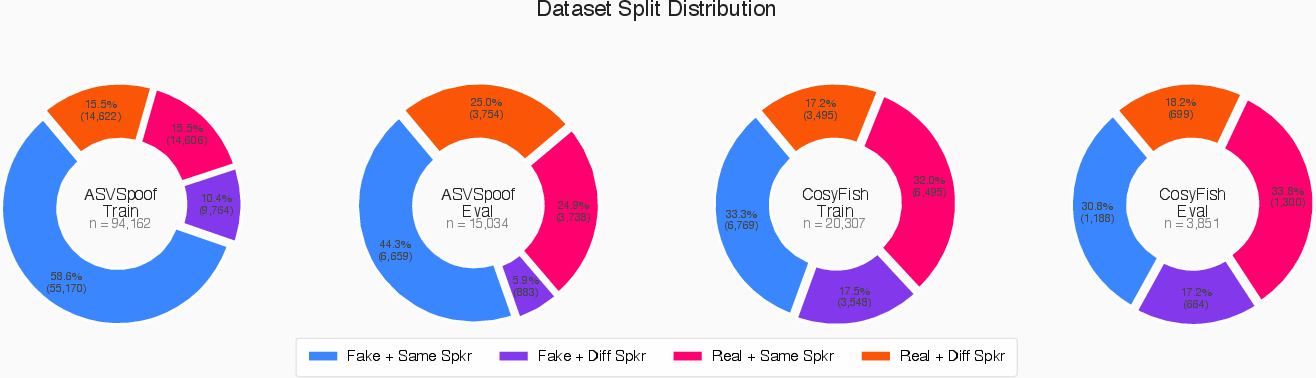
Figure 2: Dataset composition, including partitions and sample counts for ASVspoof and CosyFish subsets.
Each data point includes:
- Two audio samples (reference and candidate)
- Structured acoustic features for each sample (pitch, formants, prosody, etc.)
- A CoT-based rationale for authenticity assessment
- An explicit label for deepfake/genuine and speaker relationship
This annotation design both enriches the evidence available for supervised learning and enforces transparent, evidence-based model outputs at inference.
Experimental Evaluation and Numerical Results
CoLMbo-DF and its variants were evaluated on the ASVspoof 2019 and CosyFish test sets, benchmarking against Qwen2-Audio-Instruct (a recent pretrained ALM not exposed to deepfake detection during instruction tuning). Three supervision modes were tested: ZeroShot (label-only), CoT (full chain-of-thought), and ShortCoT (concise summary). The LLM was typically kept frozen (no parameter updates), with ablations for full-model unfreezing.
Key findings include:
- Chain-of-Thought supervision is pivotal: On ASVspoof, ShortCoT yields an accuracy of 0.987 and F1 of 0.987, compared to 0.649/0.721 in ZeroShot mode. Full CoT remains strong at 0.984/0.984.
- Explicit acoustic evidence is essential: Removal of structured acoustic evidence collapses performance to random-chance (accuracy ≈ 0.5, F1 ≈ 0).
- Compact LLMs can outperform larger generic ALMs: Despite using a much smaller LLM, CoLMbo-DF outperforms Qwen2-Audio-Instruct by a wide margin (Qwen2 accuracy as low as 0.236, F1 = 0.377).
- Cross-domain robustness: Models trained with a fraction of CosyFish data can generalize across synthesizer shifts with only modest loss in ASVspoof performance.
- Speaker verification (ASV) is harder: Even with CoT supervision, speaker relation accuracy lags behind ADD accuracy, but unfrozen LLM adaptation narrows this gap (ASV accuracy up to 0.751 with ShortCoT+Unfreeze).
These results robustly demonstrate that feature-grounded reasoning—articulated through structured CoT—yields substantial improvements in explainable deepfake detection.
Ablation and Analysis
Ablation studies reinforce the necessity of deep acoustic grounding:
- Training without explicit acoustic evidence leads to non-informative, mode-collapsed predictions, even when powerful encoders are used.
- Broader attack exposure during training improves generalization across spoofing mechanisms, but some voice conversion attacks remain challenging for cross-attack transfer.
- Adding new feature types simply requires additional evidence in the prompt and dataset annotation, not architectural changes, demonstrating the approach's extensibility.
Qualitative analyses further confirm that end-to-end systems relying only on embeddings are ill-equipped for structured, human-validated reasoning essential in practical deployment.
Implications and Future Directions
CoLMbo-DF's evidence-grounded design directly addresses interpretability demands for forensic speech analysis. Its modular architecture and capacity to integrate new, explicit feature types position it as a promising blueprint for trustworthy, auditable audio LLM-based solutions. In fraud prevention, judicial evidence, and security-sensitive AV pipelines, the ability to provide auditor-friendly rationales may ease regulatory hurdles and bolster user trust.
Theoretically, this work motivates expanded research into chain-of-thought learning for non-textual modalities, especially in adversarially challenging detection tasks where high-level semantic artifacts may be elusive. Future advancements could target:
- End-to-end differentiable CoT supervision for continuous acoustic input
- Automatic selection or generation of salient acoustic evidence
- Joint modeling of multi-modal deepfake artifacts
- More granular forensic task decomposition (e.g., TTS type, manipulation severity)
With continual evolution of synthetic speech generation, rigorous study of domain adaptation, fine-grained attack generalization, and active learning for evidence curation will also be crucial.
Conclusion
The paper introduces a modular, evidence-grounded pipeline for explainable audio deepfake detection, pairing a small LLM with explicit acoustic feature conditioning and chain-of-thought annotation. Empirical results underscore that feature-guided CoT supervision is essential for robust, transferable, and interpretable detection, with strong gains over black-box and generic ALMs. The dataset, methodology, and analysis establish new foundations for explainable AI in high-stakes, audio-based security applications, and chart a promising path for reliable, auditable audio LLM systems in the face of rapidly advancing synthesis technology.

