- The paper introduces a multi-agent, human-in-the-loop system that generates high-quality interactive documents with explicit planning and style control.
- The paper leverages the SRTC formalism to define interaction specifications, achieving up to 1.00 normalized content richness and 0.92 interaction quality.
- The paper establishes ViviBench for rigorous evaluation, demonstrating superior efficiency and usability compared to baseline multi-agent frameworks.
Generating Interactive Documents through Human-Agent Collaboration with ViviDoc
Introduction
ViviDoc proposes a multi-agent, human-in-the-loop system for the controlled generation of interactive documents, a domain characterized by challenging synthesis of dynamic, explorable content requiring both domain expertise and technical proficiency. Prior efforts leveraging LLM-based agents for content creation have not addressed the inherent uncontrollability and opacity when directly targeting interactive documents. ViviDoc is formulated to expose intermediate planning representations, enable stylistic and interaction customization, and establish rigorous evaluation via the construction of the ViviBench benchmark. By integrating algorithmic and user-centric control in document generation, ViviDoc addresses existing authoring bottlenecks and systematically raises the floor for accessible high-quality interactive content creation (2603.27991).
Pipeline Architecture and Human Control
ViviDoc's architecture consists of four modular agents: Planner, Styler, Executor, and Evaluator, structured around a formal Document Specification (DocSpec) that acts as the operational contract among pipeline stages. The pipeline supports three loci of user intervention for articulated authoring:
- Document Specification (DocSpec): The Planner decomposes a topic into ordered knowledge units, each comprising a summary, an instructional text description, and an explicit SRTC-formatted Interaction Specification. The SRTC (State, Render, Transition, Constraint) schema, inspired by visualization theory, ensures that interaction design is fully disambiguated before code synthesis.
- Style Palette: The Styler analyzes the DocSpec to generate mutually orthogonal style dimensions for content and interaction, exposing both LLM-suggested options and a free-form instruction channel.
- Chat-based Editing: Post-generation refinement is supported through conversational editing, enabling granular corrections to either the intermediate spec or the rendered document.
The pipeline enforces correctness and functional output through the Evaluator, isolating generation errors and enforcing alignment between authorial intent and rendered artifacts.
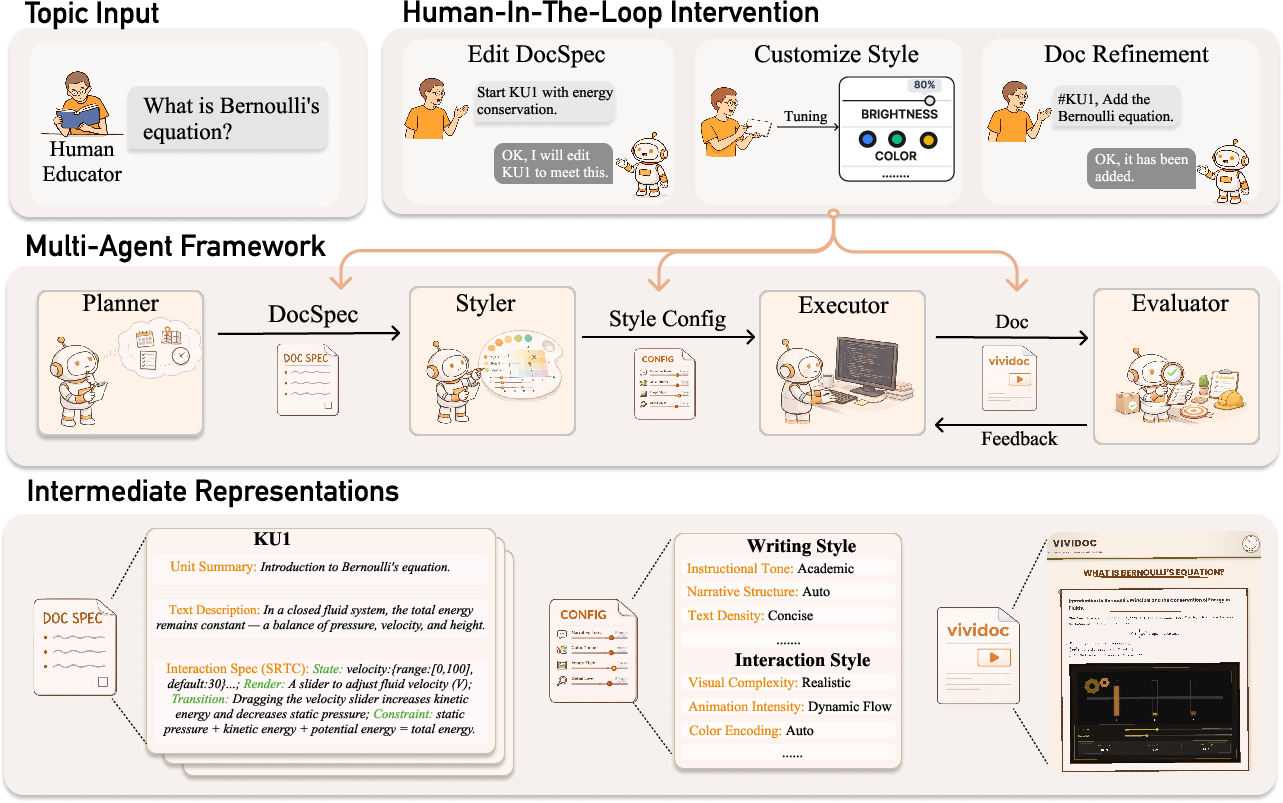
Figure 1: The ViviDoc pipeline supports multi-agent collaboration, with structured human control points at DocSpec, style, and document refinement.
Expressive Coverage of Interactive Types
ViviDoc demonstrates the ability to programmatically produce documents spanning all canonical forms of interaction identified in real-world educational content. The system's taxonomy, validated through the analysis of 482 interaction instances from curated documents, includes Parameter Exploration, Direct Manipulation, State Switching, Freeform Construction, Temporal Control, Inspection, Spatial Navigation, and Scroll-driven Narrative.
The SRTC Interaction Specification is sufficiently expressive to formalize each interaction archetype, as evidenced by synthesized documents including (but not limited to):
To provide a rigorous empirical basis for evaluation, the authors construct ViviBench—a topic set reverse-engineered from 101 high-value interactive documents across 11 subject domains. The interaction taxonomy is derived from the annotation of 482 unique elements, ensuring benchmark coverage of the full design space observed in the wild.
Document evaluation adopts a dual-process protocol:
- Layer 1: Automated, rule-based assessment of interaction functionality (instrumented browser automation for element probing) and efficiency (HTML output length per wall-time).
- Layer 2: LLM-as-Judge metrics for content richness and interaction quality, incorporating both deterministic (functionality) and LLM-judged (design) signals. This approach is retrospectively validated by strong human-LLM judgment alignment (Pearson r>0.84).
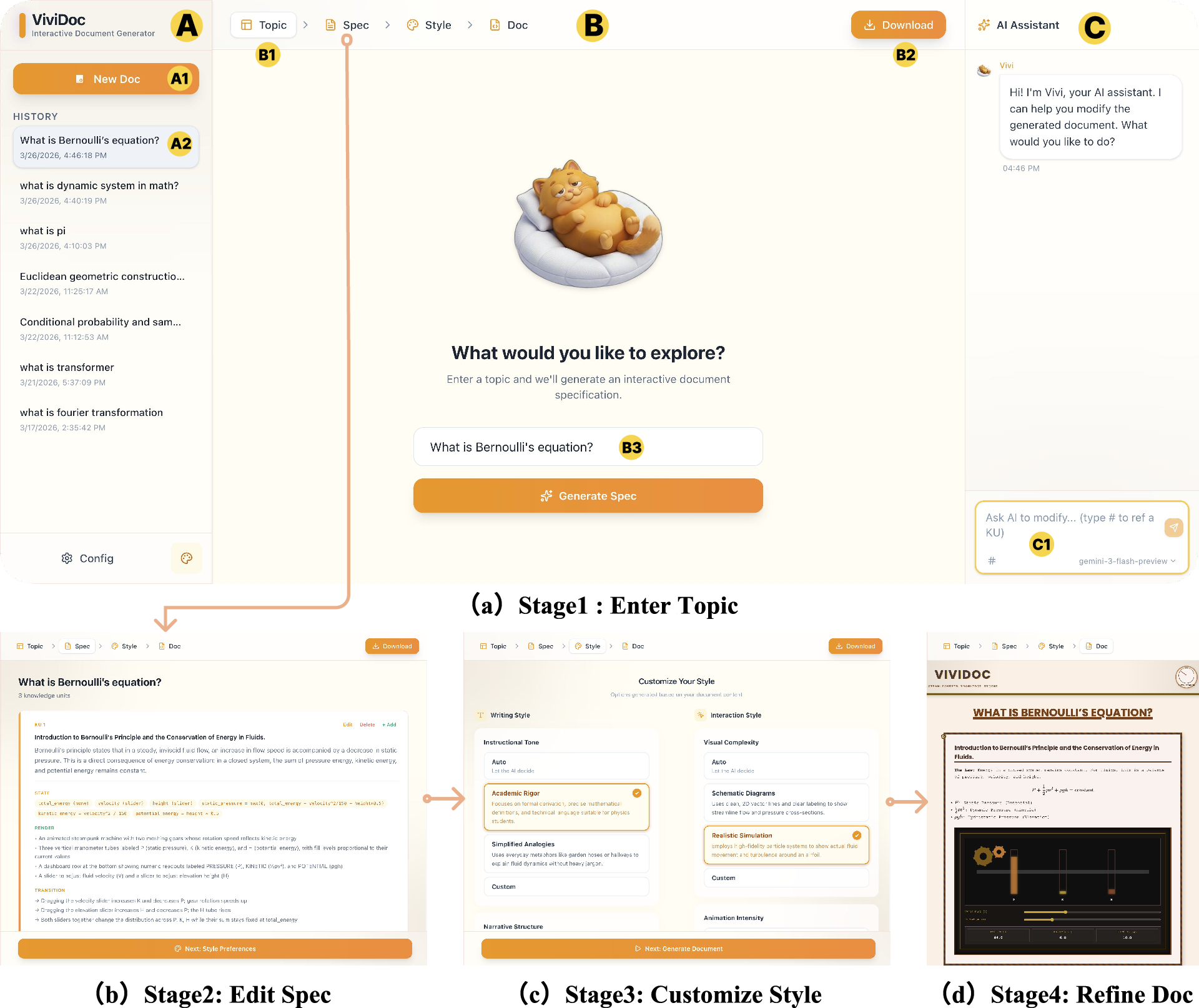
Figure 3: ViviDoc's user interface, providing structured navigation, spec editing, stylistic customization, and integrated chat-based document refinement.
(Figure 4)
Figure 4: Comparative automated evaluation demonstrates ViviDoc's dominance across content and interaction quality, robustness across LLM backbones, and higher efficiency relative to AutoGen, MetaGPT, and CAMEL.
Empirical Results
Across comprehensive quantitative and qualitative ablation studies, key claims are substantiated as follows:
- Content Richness and Interaction Quality: ViviDoc consistently surpasses baseline multi-agent systems (AutoGen, CAMEL, MetaGPT) in both normalized content and interaction scores (CR up to 1.00, IQ up to 0.92; baselines CR < 0.53, IQ < 0.64). Notably, general-purpose agent frameworks exhibit dysfunctional interaction synthesis, frequently yielding near-zero interaction functionality.
- Efficiency: ViviDoc achieves substantially improved throughput (e.g., 505 chars/s on Gemini Flash vs. 153 chars/s for AutoGen).
- DocSpec Contribution: Isolating the structured planner (DocSpec) yields up to 41% IQ improvement versus end-to-end naive agents, with modest trade-offs in throughput.
- User Study: Human participants (n=12) report perfect usability (5.0/5), high controllability (DocSpec and chat-editing >4.5), and are consistently satisfied with both text quality and visualization (output satisfaction >4.58).
Implications and Future Directions
ViviDoc formalizes an extensible design pattern for controlled interactive content generation, bridging the disjunction between black-box LLM performance and transparent incremental authoring. The structured intermediate representations and their multi-layered evaluation protocol mitigate hallucination and non-determinism endemic to LLM-based code generation.
Practically, ViviDoc lowers the technical barrier for high-quality educational and scientific communication, democratizing access to interactive explorable explanations. Theoretically, the results suggest that LLM-based pipelines benefit from explicit intent serialization and intermediate constraint layers, a strategy extensible to other code-driven creative domains (e.g., infographic generation, scientific visualization).
Key open research directions include integration of retrieval-augmented generation for domain specialization, inline preview support during style selection, and the extension of the SRTC formalism to accommodate higher cognitive interaction forms and adaptive content.
Conclusion
ViviDoc establishes a robust, controllable framework for interactive document generation through structured multi-agent collaboration and human-guided authoring. Comprehensive benchmark and user studies demonstrate superior content and interaction quality, efficient document synthesis, and strong user acceptance. This work paves the way for further advancements in human-agent collaborative design systems, with particular implications for educational technology, explainable AI, and science communication (2603.27991).
