- The paper presents a novel TARA framework for LoRA merging that effectively preserves subspace coverage by retaining explicit rank-1 updates.
- It introduces preference-aware and direction-aware reweighting schemes to mitigate destructive interference and manage directional anisotropy.
- Empirical results on vision and language benchmarks confirm that TARA achieves superior per-task and joint performance with competitive computational efficiency.
Preference-Aligned LoRA Merging: Preserving Subspace Coverage and Addressing Directional Anisotropy
Motivation and Problem Analysis
Low-Rank Adaptation (LoRA) is extensively employed for fine-tuning over large foundation models across vision, language, and multimodal domains due to its parameter efficiency and reduced risk of overfitting. The challenge arises when integrating multiple task-specific LoRA adapters to construct models capable of general-purpose operation without costly joint multi-task training. Naive merging of LoRA modules causes loss of representational diversity (subspace coverage) and fails to account for uneven directional task sensitivity (anisotropy), undermining fidelity to multiple task objectives.
Subspace coverage measures the breadth of directions preserved in LoRA updates, essential for capturing task-relevant information with minimal collapse from destructive interference. Anisotropy describes imbalance in how individual LoRA directions affect task losses, with some directions being strongly task-critical while others exert weak influence. The authors identify these as the two principal obstacles to robust adapter merging.
Subspace Coverage in LoRA Merging
The analysis formalizes LoRA updates as collections of rank-1 outer products in the parameter space. Effective rank, computed via entropy of singular value spectra, quantitatively assesses how merging various task adapters preserves representational diversity. When adapters are naively collapsed, effective rank degrades due to destructive interference. Maintaining LoRA structure—keeping rank-1 directions explicit during merging—substantially mitigates subspace collapse as evidenced by a retained fraction (≈70%) of per-task effective rank under LoRA-aware stacking, indicating weak cross-task alignment and supporting the necessity of structural preservation.
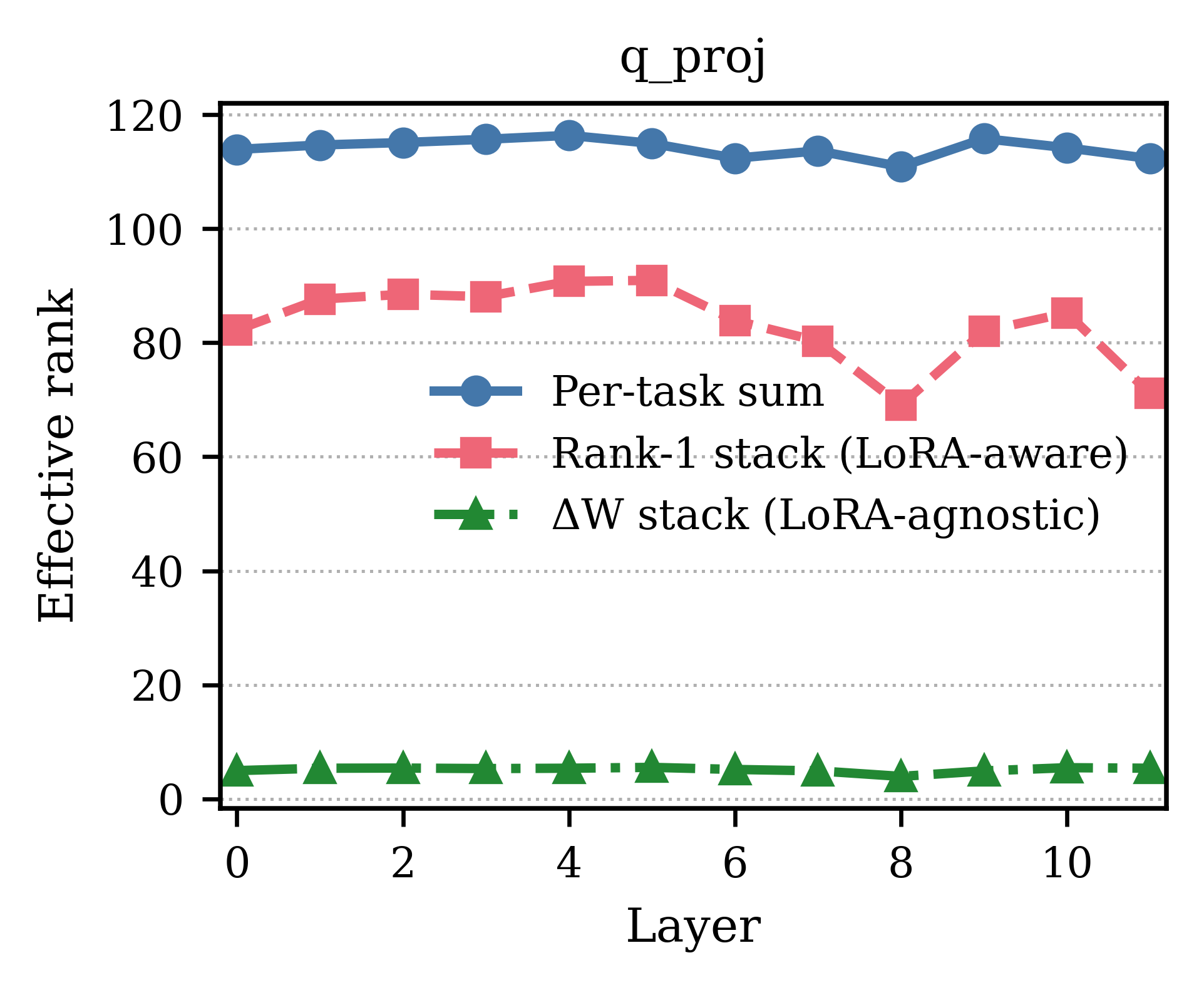
Figure 1: Effective rank across layers for an attention projection layer; the gap between LoRA-aware and LoRA-agnostic stacks reflects merge-induced collapse.
Supplementary analysis on query, key, value, and output modules corroborates that LoRA-aware merging attenuates dimensional collapse across layer types.
Directional Anisotropy and Sensitivity Misalignment
Directional anisotropy is formalized through the task-loss Jacobian restricted to the LoRA span, with condition number and singular value distribution indicating how sensitivity to parameter updates concentrates into a few critical directions. High condition numbers are prevalent across modules and layers, demonstrating strong anisotropy.
The paper introduces a misalignment index ξ(ρ1,ρ2) quantifying how loss-sensitive directions shift when task preferences change (e.g., from uniform to single-task focus):
- Large ξ values empirically confirm high misalignment, with optimal directions for different preferences diverging substantially.
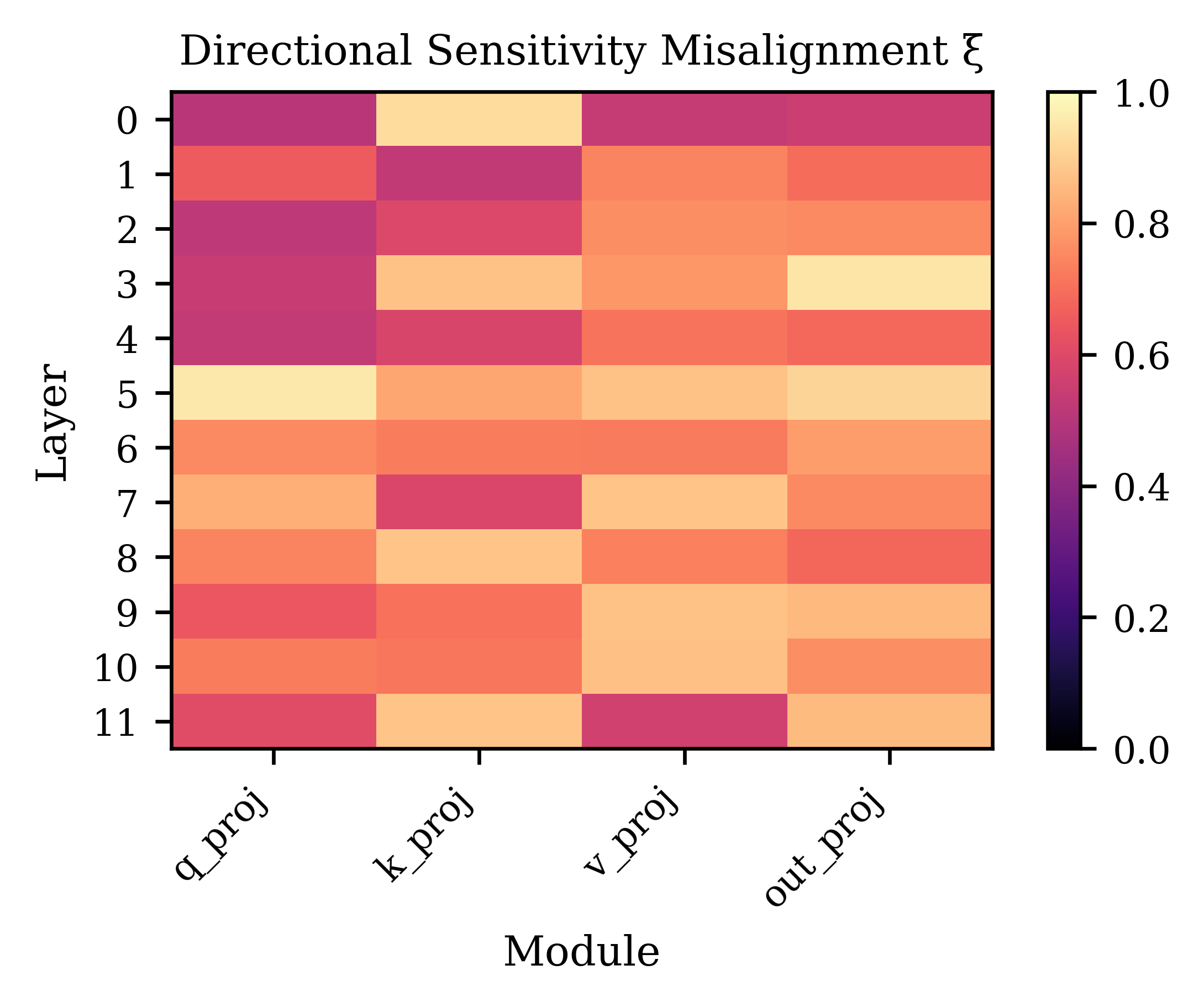
Figure 2: Directional-sensitivity misalignment ξ(ρ1,ρ2); larger ξ values signify stronger change in loss-sensitive directions upon preference switching.
This motivates merging schemes that not only preserve subspace coverage but also align direction weights with evolving task preferences.
TARA-Merging: Methodology
The Task-Rank Anisotropy Alignment (TARA) framework introduces preference-aware and direction-aware reweighting under two variants:
- Variant A: Per-rank LoRA direction selection, directly reweighting individual rank-1 directions across adapters.
- Variant B: Shared SVD basis construction; adapters are horizontally concatenated, and top singular vectors spanning the merged LoRA subspaces are extracted. Direction weights ϕik are optimized to align sensitivity profiles with user preferences, preserving broad subspace coverage and finely controlling anisotropy.
Both variants are optimized via smooth Tchebycheff scalarization, which balances task losses according to user-specified preference vectors ρ, yielding merged models along a Pareto front.
Empirical Results
Vision and Language Benchmarks
Across vision tasks (CLIP ViT-B/32 backbone, eight datasets), TARA variants outperform vanilla baselines (Task Arithmetic, TIES, DARE, AdaMerging) and LoRA-aware baselines (KnOTS, LoRA-LEGO, RobustMerge). Variant B consistently achieves the highest normalized accuracy (76.3%), demonstrating superior retention of per-task performance.
Across six NLI tasks with LLaMA-3 8B, TARA maintains leading normalized accuracy (80.3%), outperforming both vanilla and LoRA-aware baselines.
Joint-Task Evaluation
In the challenging joint-task setting where a merged model must operate over the union of all task label spaces, TARA achieves the top Hits@1, Hits@3, and Hits@5 scores. Its joint integration of task knowledge avoids accuracy collapse observed in arithmetic and pruning baselines.
Trade-Off and Robustness
TARA's preference-sensitive merging enables smooth accuracy trade-offs between tasks, outperforming isolated points produced by AdaMerging and other baselines.
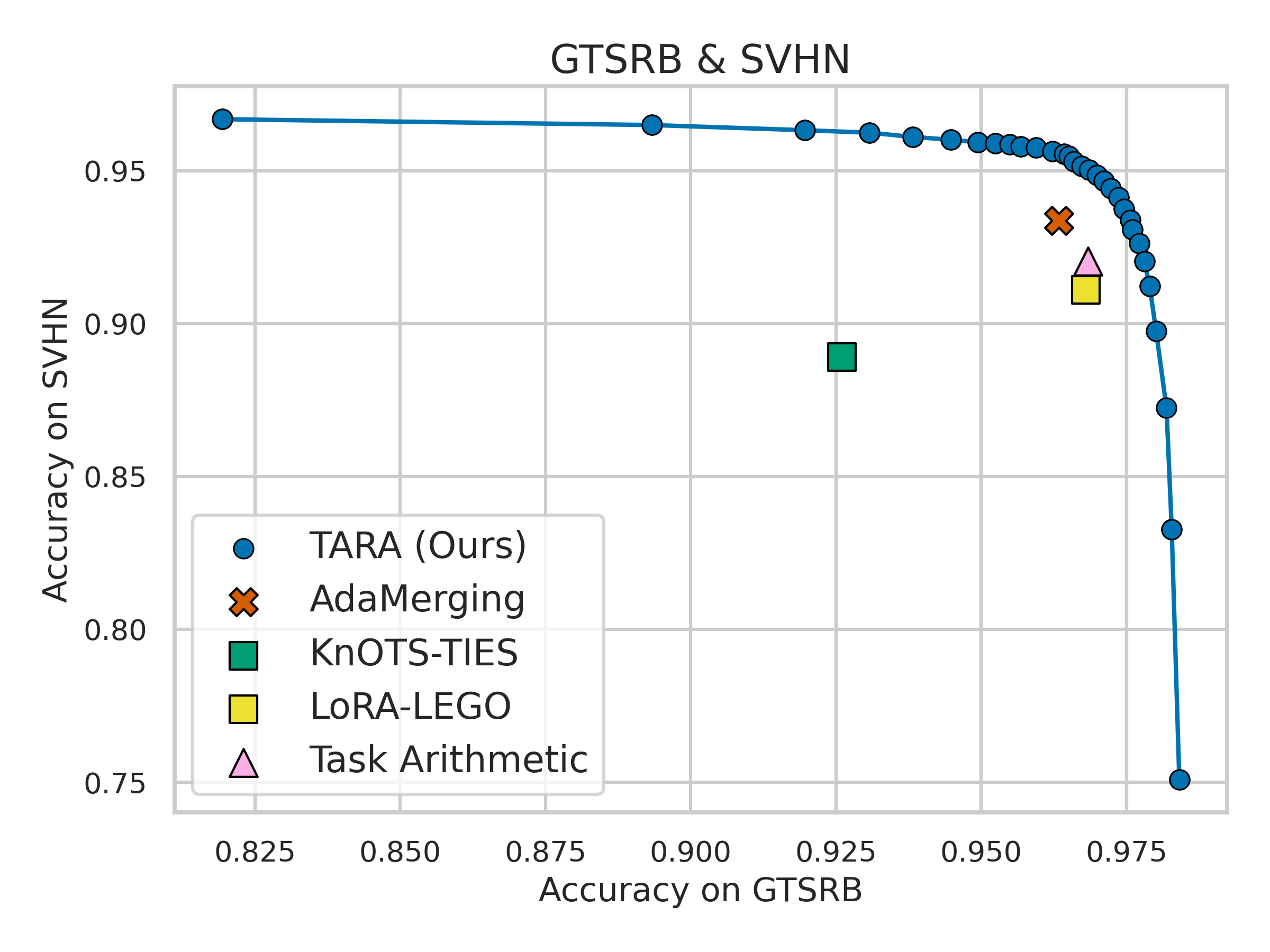
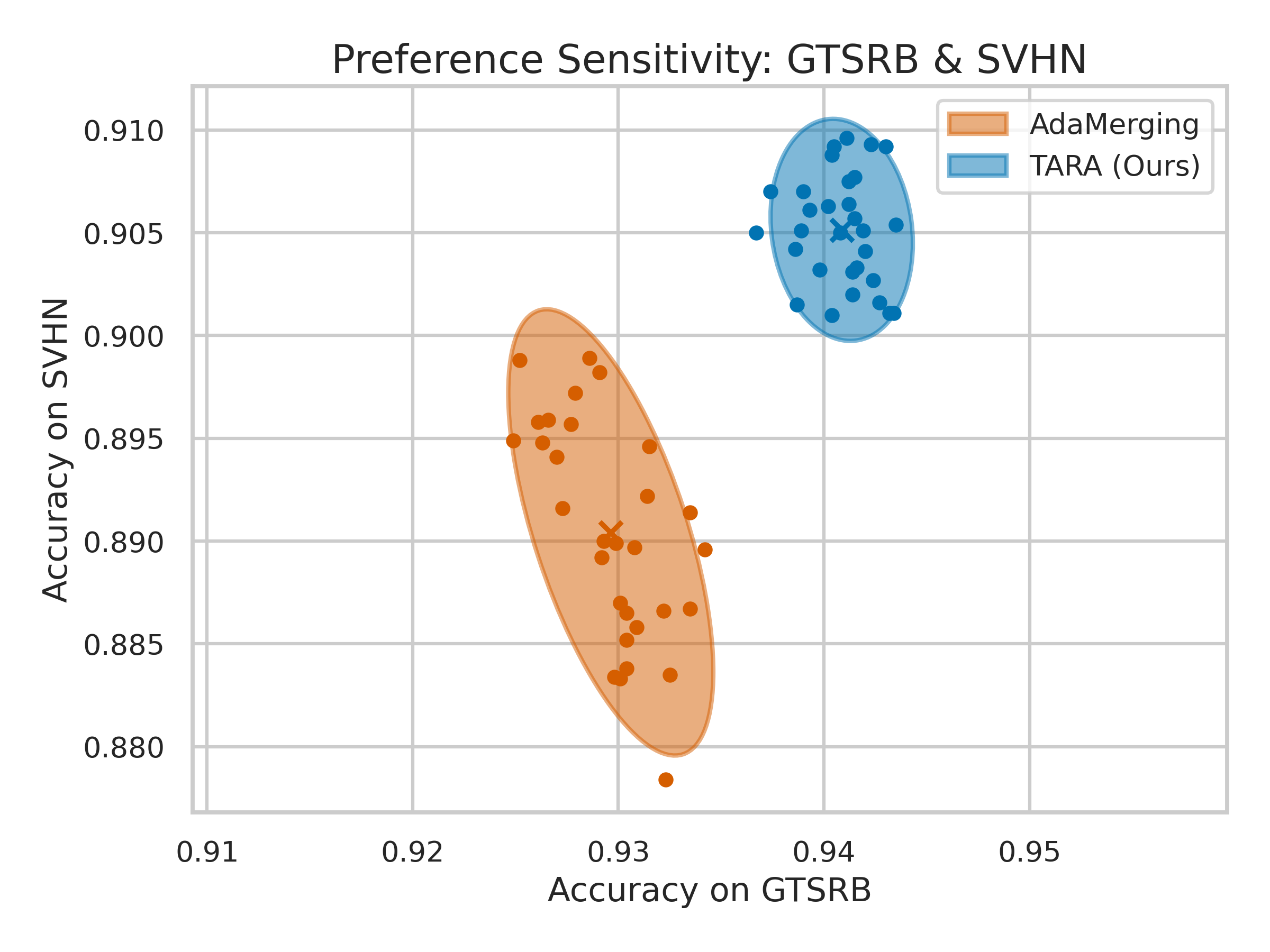
Figure 3: Two-task Pareto fronts and robustness analysis; TARA yields dominant, smooth trade-off curves and tighter performance distributions under preference perturbations.
A sweep of random preference vectors demonstrates that TARA achieves lower empirical covariance and superior stability relative to AdaMerging, attributed to direction-wise reweighting and explicit sensitivity alignment.
Generalization
TARA shows improved generalization to unseen tasks, scoring higher normalized accuracy than all baselines in transfer settings, confirming its robustness to domain shift and effective preservation of task-specific and transferable subspaces.
Computational Efficiency
Despite additional SVD computation in Variant B, the time and memory overhead for TARA at foundation-model scale is minor relative to grid-search-heavy vanilla methods. The practical merge time (≈15–30 minutes for LLaMA-3 or LLaVA) is competitive with state-of-the-art baselines.
Ablations
Both variants of TARA are stable across a wide range of scalarization smoothing hyperparameters (α), and robust to LoRA adapter rank (maintaining accuracy advantage even at reduced ranks). TARA demonstrates comparable or superior accuracy in large-scale settings, including 14 and 20-task merges on both ViT-B/32 and ViT-L/14.
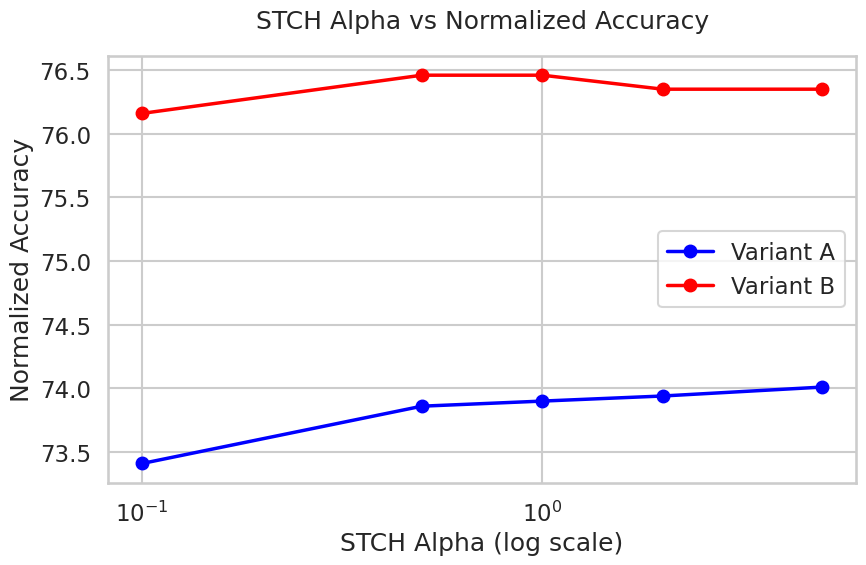
Figure 4: Ablation of scalarization smoothing parameter α; normalized accuracy is stable for both TARA variants over a broad α range.
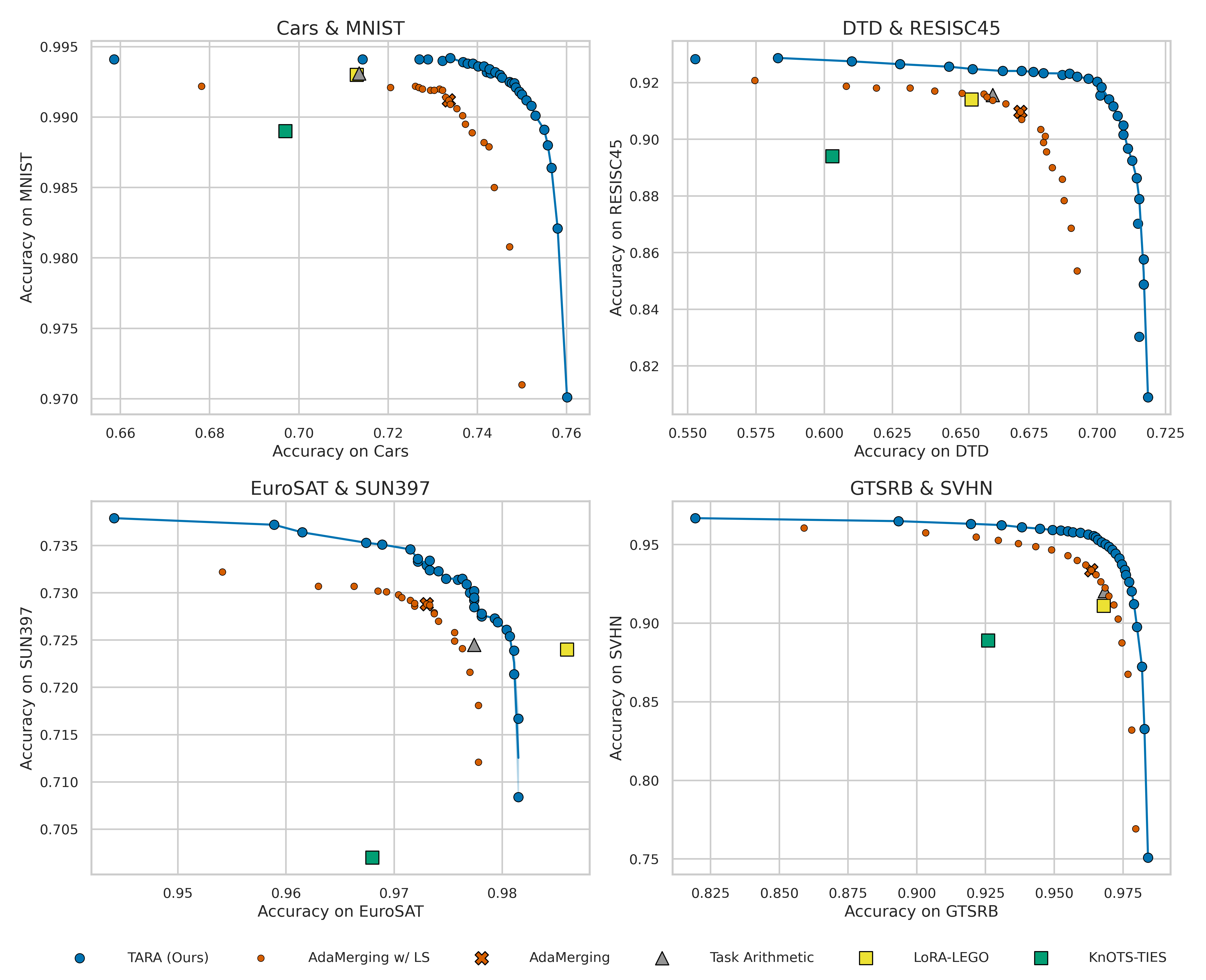
Figure 5: Two-task trade-offs on CLIP ViT-B/32; TARA traces smooth and dominant Pareto fronts across diverse task pairs.
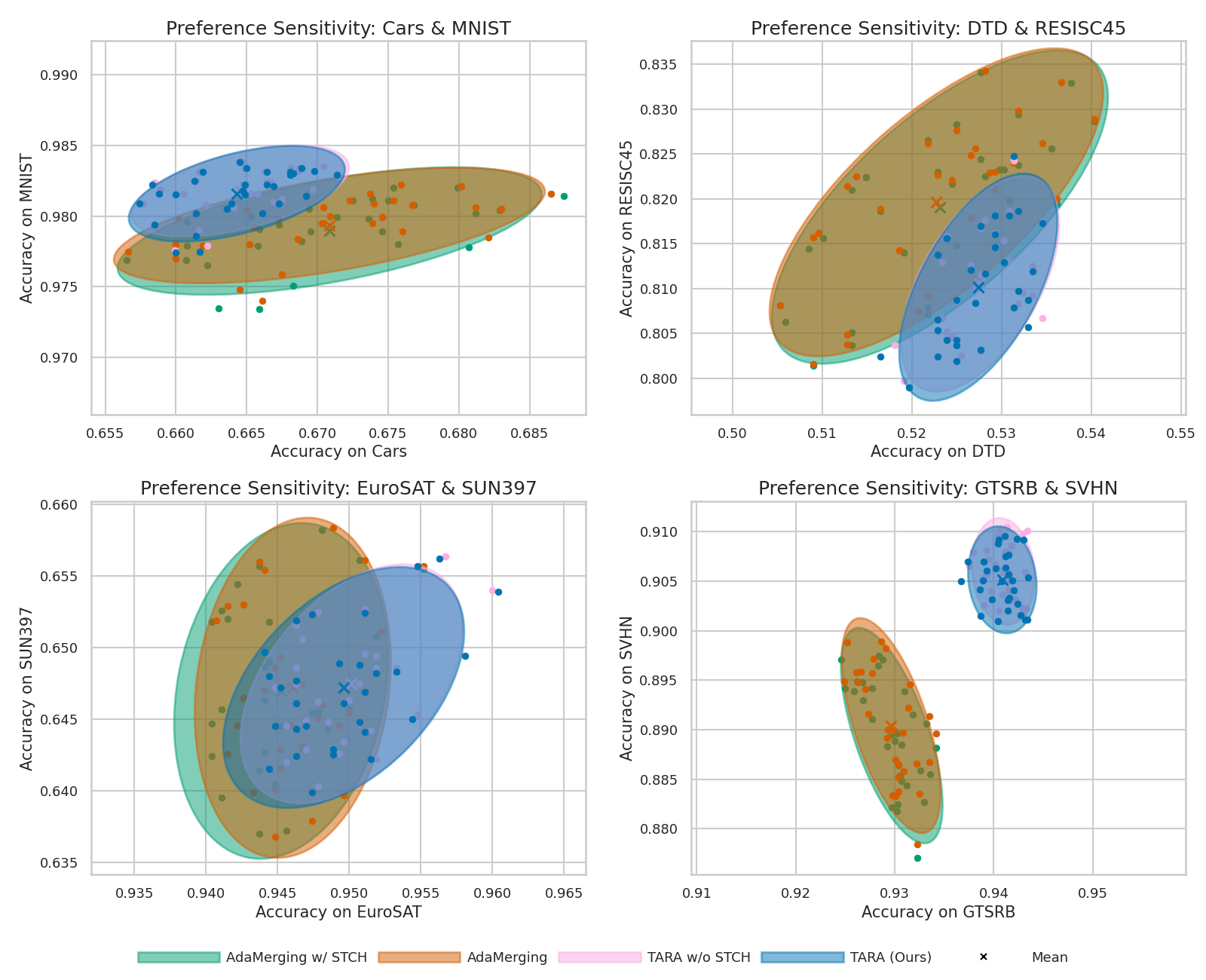
Figure 6: Preference sensitivity under random global preferences; TARA consistently exhibits lower variance and greater robustness.
Theoretical and Practical Implications
TARA addresses structural deficiencies in previous merging schemes, offering a principled methodology to jointly preserve representational diversity and accommodate anisotropic task sensitivities. It establishes that LoRA merging is not merely a linear or pruning operation but requires explicit modeling of directional entanglement and task-driven preference.
From a theoretical perspective, the effective-rank and directional-sensitivity framework lays groundwork for analyzing adapter composition in parameter-efficient fine-tuning, connecting to multi-objective optimization, model editing, and Pareto methods. On the practical side, TARA's robust merging enables scalable construction of general-purpose foundation models from independently fine-tuned modules, lowering the computational barrier for multi-task model building and transfer learning.
Anticipated future directions include:
- Extending TARA to mixture-of-experts architectures with dynamic routing
- Application to continual learning and incremental domain adaptation
- Further theoretical exploration of anisotropy bounds in adapter merging contexts
- Integration with modality-specific merging (e.g., multimodal vision-LLMs)
Conclusion
Preference-Aligned LoRA Merging via TARA demonstrates that robust, general-purpose model merging requires simultaneous preservation of task-relevant subspace coverage and explicit management of directional anisotropy. The method achieves consistent performance gains in per-task, joint, and transfer evaluation, exhibits strong robustness to preference perturbation, and scales efficiently to foundation models in vision and language domains. TARA establishes a new standard for structural and sensitivity-aware LoRA merging, with broad applicability in multi-task and modular AI system design.
(2603.26299)