Geo$^\textbf{2}$: Geometry-Guided Cross-view Geo-Localization and Image Synthesis
Abstract: Cross-view geo-spatial learning consists of two important tasks: Cross-View Geo-Localization (CVGL) and Cross-View Image Synthesis (CVIS), both of which rely on establishing geometric correspondences between ground and aerial views. Recent Geometric Foundation Models (GFMs) have demonstrated strong capabilities in extracting generalizable 3D geometric features from images, but their potential in cross-view geo-spatial tasks remains underexplored. In this work, we present Geo2, a unified framework that leverages Geometric priors from GFMs (e.g., VGGT) to jointly perform geo-spatial tasks, CVGL and bidirectional CVIS. Despite the 3D reconstruction ability of GFMs, directly applying them to CVGL and CVIS remains challenging due to the large viewpoint gap between ground and aerial imagery. We propose GeoMap, which embeds ground and aerial features into a shared 3D-aware latent space, effectively reducing cross-view discrepancies for localization. This shared latent space naturally bridges cross-view image synthesis in both directions. To exploit this, we propose GeoFlow, a flow-matching model conditioned on geometry-aware latent embeddings. We further introduce a consistency loss to enforce latent alignment between the two synthesis directions, ensuring bidirectional coherence. Extensive experiments on standard benchmarks, including CVUSA, CVACT, and VIGOR, demonstrate that Geo2 achieves state-of-the-art performance in both localization and synthesis, highlighting the effectiveness of 3D geometric priors for cross-view geo-spatial learning.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching computers to understand how a place looks from two very different angles: from the ground (like a street photo) and from the sky (like a satellite image). The authors build one system, called Geo² (Geo-Geo), that does two things:
- It finds where a ground photo is on a map by matching it to the right satellite image (geo-localization).
- It creates one view from the other, like turning a ground photo into a satellite image and also the other way around (image synthesis).
Their big idea is to use 3D shape clues (geometry) to connect these two tasks, because geometry stays the same even when the viewpoint changes a lot.
What questions did the researchers ask?
In simple terms, they asked:
- Can we use powerful 3D “sense” models (called Geometric Foundation Models) to better connect ground and satellite views?
- Can we put both views into the same “shared space” so it’s easier to match locations and to generate one view from the other?
- Is it possible to train the model in one direction (for example, ground to satellite) and still have it work in the opposite direction (satellite to ground) without extra training?
How did they do it?
Think of this in three parts.
Step 1: Learning a shared 3D-aware “language” (GeoMap)
- Problem: Ground photos and satellite images look extremely different (street-level vs bird’s-eye). Regular models struggle to line them up.
- Solution: The authors use a geometry expert model (VGGT) that is good at understanding 3D shapes from images.
- For ground images (often full 360° panoramas), they “cut” the panorama into several normal camera views (like taking multiple photos looking around you), feed those into the geometry model, and collect 3D-aware features.
- For satellite images, they feed them directly into the geometry model to get 3D-aware features.
- They then mix these geometry features with regular “what’s in the picture” features (like buildings, roads, trees) using attention—a way for the model to focus on the most useful parts.
- Finally, both ground and satellite images are mapped into the same compact “shared space” (think of it like a meeting room where both can talk the same 3D-aware language). This makes it easier to:
- Compare a ground image to satellite images (for location matching).
- Re-use those features to guide image generation.
Step 2: Turning one view into the other (GeoFlow)
- Goal: Create a satellite image from a ground photo, and also create a ground image from a satellite photo.
- Approach: They don’t use a standard “paint-by-numbers” generator. Instead, they use a method called flow matching.
- Imagine a slider that morphs one picture’s internal code into another’s. The model learns the “direction of change” (like a wind that pushes the code from ground to satellite).
- Because this “wind” is reversible, if you learn ground→satellite, you can flip the direction and get satellite→ground without training again.
- The shared 3D-aware features from GeoMap act like a GPS, guiding the morphing so it respects the true shapes and layouts (roads, buildings, parks).
Step 3: Training both together
- First, they train the GeoMap part to be great at matching ground and satellite images (the geo-localization task).
- Next, they train GeoFlow (the image generator) using the GeoMap features as guidance.
- Finally, they fine-tune both together, adding a “consistency” push so that ground and satellite features line up even better. This helps both matching and image generation.
What did they find?
In tests on three standard datasets (CVUSA, CVACT, and VIGOR), the system:
- Set or matched state-of-the-art results for finding the correct satellite image for a ground photo, even in hard cases where the test areas are different from the training areas.
- Produced higher-quality generated images for both directions (ground→satellite and satellite→ground) on several metrics:
- FID (how realistic images look) improved noticeably.
- LPIPS (perceptual similarity), PSNR, and SSIM (other quality measures) were competitive or better on many benchmarks.
- Crucially, it could do bidirectional image synthesis after training only in one direction—something many other methods can’t.
Why this is important:
- The shared 3D-aware space made matching more reliable.
- Using geometry as a guide helped the model “understand” structure (like where roads and buildings are) and not just colors or textures.
- The reversible generation saved training time and data.
Why does this matter?
- Better maps and navigation: Matching ground photos to satellite maps can help vehicles, robots, and phones figure out exactly where they are.
- Smarter city and disaster tools: Turning ground views into satellite-like overviews (and back) can help with planning, monitoring, and emergency response.
- AR and virtual tours: Knowing how a place looks from different angles makes it easier to build immersive experiences.
- Efficiency: Training once and getting two directions for free reduces cost and makes the method more practical.
- Bigger picture: It shows that “geometry-savvy” models can connect very different views in a unified way—useful for many other cross-view or 3D-related tasks in the future.
In short, Geo² uses the “shape of the world” as a common thread to link seeing, locating, and imagining places from the ground and from the sky, making both matching and image generation stronger and more flexible.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list identifies concrete gaps, uncertainties, and unexplored aspects in the paper that future research can address:
- Dependency on panoramic ground imagery: The method assumes ground panoramas and relies on an equiangular-to-perspective (E2P) transformation; performance on standard perspective street-view images (single FoV, non-panoramic) remains unknown and untested.
- Sensitivity to E2P parameters: The number of perspective crops V, crop field-of-view, overlap, and sampling strategy are not analyzed; their effect on CVGL/CVIS performance, geometric fidelity, and computational cost needs systematic ablation.
- Computational efficiency and scalability: Multi-view VGGT inference on V crops is potentially expensive; the paper lacks runtime, memory footprint, and throughput measurements, especially for large-scale retrieval (city-level or nationwide datasets).
- Retrieval at scale: The approach uses Euclidean distance in embedding space with batch negatives; there is no evaluation with million-scale candidate sets, approximate nearest neighbor (ANN) indexing, latency, or end-to-end retrieval pipeline considerations.
- Limited geometric evaluation: Image synthesis is evaluated with PSNR/SSIM/LPIPS/FID, which do not capture geometric/layout correctness; missing metrics include BEV topology consistency, road/building layout alignment, structural similarity in map-space, depth/pseudo-geometry accuracy, or camera pose errors.
- Underuse of GFM outputs: VGGT provides depth/point maps/pose, but the pipeline only uses dense features; the benefit of explicitly leveraging predicted poses or depths for cross-view alignment is unexplored.
- Single-GFM reliance and lack of ablations: The model uses VGGT without evaluating alternatives (DUSt3R, MASt3R, AerialMegaDepth variants), without freeze vs. fine-tune comparisons, domain-adapted GFMs, or quantifying how each contributes to CVGL/CVIS.
- Ambiguity in KL consistency loss: KL divergence on embeddings fg and fs is ill-defined unless embeddings are normalized into distributions; the paper does not specify the normalization or theoretical justification, nor provide ablations on the weight α or its actual contribution.
- Joint training efficacy: The claim that CVGL and CVIS mutually reinforce each other lacks quantitative evidence; ablations comparing (i) separate training, (ii) joint training without KL, and (iii) full joint training are missing.
- Flow-matching assumptions: GeoFlow trains on linear displacement interpolation with a constant vector field v = xs − xg; whether this simplistic path captures the non-linear domain translation between ground and satellite views remains untested against alternatives (e.g., non-linear geodesics, learned paths, rectified probability flows).
- ODE solver details and stability: The paper does not describe the ODE integration method, step size, number of steps, numerical stability, or how these choices affect synthesis quality, artifacts, or the success of reversed integration.
- Bidirectional synthesis domain shift: GeoFlow is trained with condition c = fg (G2S) but infers S2G using c = fs; the model has not seen satellite-conditioned inputs during training, which likely contributes to inferior S2G performance; the impact of symmetric conditioning, dual-branch conditioning, or cycle consistency is unexplored.
- S2G quality gap: S2G performance trails G2S; the paper lacks analysis of causes (e.g., ground-view texture complexity, occlusions, lighting) and targeted remedies (e.g., stronger geometry constraints, semantic priors, pose-aware conditioning).
- Handling misalignment and noisy pairing: Real-world ground–satellite pairs often suffer from GPS errors, temporal gaps, and viewpoint offsets; robustness to misregistration, temporal changes (season, construction), weather, and domain shifts (sensor/resolution) is not studied.
- Generalization beyond datasets: Results are limited to CVUSA, CVACT, and VIGOR; performance across diverse geographies (dense megacities, mountainous/desert/coastal regions, high latitudes), sensors (multispectral, SAR), and providers (varying resolutions) is not evaluated.
- Perspective distortions and horizon artifacts: E2P cropping of panoramic ground views can introduce distortions near the horizon and lose vertical context; failure cases and mitigation (e.g., vertical FoV augmentation, 3D rectification) are not analyzed.
- Embedding design ablations: The impact of embedding dimension D, choice of pretrained CNN backbone, tokenization strategy, cross-attention design, and normalization pooling on retrieval and synthesis is not quantified.
- Hard negative mining: While prior CVGL works benefit from hard sample mining, GeoMap trains with InfoNCE but does not investigate curriculum/hard-negative sampling strategies; their effect on R@1, generalization, and robustness is unknown.
- Orientation invariance and rotation sensitivity: The framework avoids polar assumptions, but it does not quantify how embeddings handle rotations (yaw) and camera pose variability in ground/satellite views.
- Uncertainty and calibration: The approach lacks uncertainty estimates for retrieval (e.g., calibrated confidence, top-k probability) and synthesis (e.g., geometric uncertainty), as well as out-of-distribution detection mechanisms.
- From retrieval to coordinates: The method retrieves discrete satellite tiles; regressing continuous geo-coordinates, multi-stage coarse-to-fine localization, or integrating map priors for precise positioning remains open.
- Multi-modal integration: The framework does not explore fusing additional modalities (LiDAR/DEM, vector maps, segmentation, road graphs) to strengthen geometric consistency and synthesis fidelity.
- Failure analysis: Apart from showing VGGT failures when naively applied, the paper does not present a rigorous failure taxonomy for the final system (e.g., scene types, lighting, occlusions) or diagnostic tools to detect and mitigate errors.
- Reproducibility gaps: Critical implementation details are deferred to supplementary (E2P formulas, RAE configuration, solver settings, training schedules, α/τ values, crop counts), hindering reproducibility; compute budgets and hardware requirements are not reported.
- Privacy and fairness: Potential privacy issues (street-level imagery), geographic bias, and fairness across regions/populations are not discussed; ethics and data governance considerations are absent.
- Extension to broader cross-view tasks: Applicability to oblique aerial/drone views, different altitude regimes, or mixed ground-view cameras (dashcam, handheld) is not evaluated; domain adaptation strategies for these settings remain open.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed with today’s imagery, compute, and software stacks, leveraging the paper’s GeoMap (shared geometry-aware latent space), GeoFlow (bidirectional flow matching), and GFM priors (e.g., VGGT) to improve cross-view geo-localization (CVGL) and cross-view image synthesis (CVIS).
Industry
- High-accuracy photo-to-map localization for field operations
- Sectors: utilities, energy, telecom, construction, insurance, logistics
- What it does: Localize ground photos (including panoramas) to the correct satellite tile/coordinates when GPS is unreliable (e.g., dense urban canyons, indoor-to-outdoor transitions).
- Tools/products/workflows: ArcGIS/QGIS plugin or REST API that ingests a ground image, runs E2P → VGGT → GeoMap to retrieve top-K satellite matches with confidence and bounding boxes; dashboard to validate and log results.
- Assumptions/dependencies: Access to recent, licensed satellite basemaps for target geographies; GPU/accelerator for inference; acceptable latency (seconds); adherence to data privacy policies when processing employee/customer photos.
- Map QA and coverage-gap detection via cross-view consistency checks
- Sectors: mapping/GIS, autonomous mapping, map data vendors
- What it does: Generate the opposite view (ground from satellite or satellite from ground) with GeoFlow; flag inconsistencies between real and synthesized counterparts to prioritize map updates (e.g., missing roads, new construction).
- Tools/products/workflows: Batch pipeline that pairs incoming imagery with GeoFlow synthesis and computes LPIPS/SSIM/FID against available counterpart views; rank areas for human QA.
- Assumptions/dependencies: S2G fidelity is lower than G2S; treat synthesized views as cues for triage, not ground truth; versioned imagery to avoid time-of-capture mismatches.
- GPS-denied cross-view localization for mobile robots and drones (prototype-ready)
- Sectors: robotics, warehousing, delivery, infrastructure inspection
- What it does: Use GeoMap embeddings to match onboard camera frames to satellite mosaics for coarse global pose initialization; fuse with visual-inertial odometry/SLAM.
- Tools/products/workflows: ROS node or SDK wrapping GeoMap retrieval; pre-fetch satellite tiles along mission corridor; integrate as fallback when GNSS degrades.
- Assumptions/dependencies: Requires up-to-date satellite imagery and approximate starting region; lighting/weather domain shifts may require fine-tuning; on-device or edge GPU recommended.
- Property, asset, and risk context from single images
- Sectors: insurance, real estate, asset management
- What it does: From a street photo, synthesize aerial context (parcel footprint, nearby water/vegetation); from aerial imagery, synthesize approximate ground perspective to preview street context for listings or claims triage.
- Tools/products/workflows: Web widget/API to auto-attach synthesized counterpart images to records; “confidence + disclaimer” UI for human review.
- Assumptions/dependencies: Synthesis is approximate; use for qualitative context, not for measurements or underwriting decisions without human verification.
- Training data augmentation for aerial/ground ML models
- Sectors: computer vision, remote sensing analytics, AV perception
- What it does: Use GeoFlow to generate missing counterpart views and increase training diversity; use GeoMap’s contrastive retrieval to mine hard positives/negatives.
- Tools/products/workflows: MLOps jobs that generate synthetic pairs, enforce distribution matching with the KL consistency loss, and re-train downstream models (segmentation, change detection).
- Assumptions/dependencies: Maintain provenance labels (real vs synthetic) to avoid bias; periodic human spot checks to prevent drift.
Academia
- Unified baseline for cross-view retrieval and generation
- Sectors: computer vision, remote sensing, robotics
- What it does: A reproducible framework that jointly optimizes CVGL and bidirectional CVIS using GFM priors; strong results on CVUSA, CVACT, VIGOR, including cross-area tests.
- Tools/products/workflows: Open-source code as a teachable baseline; course assignments on flow matching, shared latent spaces, and GFM feature reuse.
- Assumptions/dependencies: Access to VGGT or comparable GFM weights; compute for training/fine-tuning; adherence to dataset licenses.
- Semi-automatic dataset curation and hard-sample mining
- Sectors: data-centric AI
- What it does: Use InfoNCE-trained embeddings to deduplicate, relabel, and mine challenging cross-view pairs; synthesize complements for missing modalities.
- Tools/products/workflows: Data cleaning pipelines that log retrieval scores and synthesis discrepancies to flag anomalies.
- Assumptions/dependencies: Balanced geographic coverage to reduce domain bias; careful thresholding to minimize false relabeling.
Policy and Government
- Rapid crisis mapping and SAR photo localization
- Sectors: emergency management, public safety, humanitarian response
- What it does: Localize crowd-sourced photos without reliable GPS (e.g., disaster zones) to speed up triage and resource allocation; estimate uncertainty envelopes from top-K retrieval dispersion.
- Tools/products/workflows: Intake portal for public photos → GeoMap retrieval with uncertainty → map overlays for incident commanders.
- Assumptions/dependencies: Formal privacy agreements for user-submitted content; clear uncertainty communication; human-in-the-loop verification before action.
- Planning and permitting previews
- Sectors: urban planning, transportation
- What it does: Generate quick-look street perspectives from up-to-date satellite captures in areas lacking street-level coverage to support community meetings and early feasibility checks.
- Tools/products/workflows: Planning portals that embed a “preview ground view” widget powered by GeoFlow.
- Assumptions/dependencies: Present as qualitative visualization; ensure timestamps of satellite sources are clear to avoid misinterpretation.
Daily Life
- “Where am I?” photo-based localization
- Sectors: consumer apps, travel, outdoor recreation
- What it does: Users snap a photo to get an approximate map location when connectivity or GPS is poor.
- Tools/products/workflows: Mobile SDK (iOS/Android) to call a cloud CVGL API; caches tiles for offline retrieval.
- Assumptions/dependencies: Respect user consent and data retention limits; provide uncertainty and avoid precise pin-drop claims.
- Neighborhood context previews
- Sectors: real estate portals, local discovery
- What it does: Generate an aerial snapshot from a ground photo (or vice versa) to understand context (parks, roads) when only one view is available.
- Tools/products/workflows: Web UI toggle “see street/aerial preview” powered by GeoFlow; watermark “AI-synthesized.”
- Assumptions/dependencies: Use as an assistive preview, not as a substitute for official imagery; avoid sensitive content.
Long-Term Applications
These scenarios require further research, scaling, robustness, or policy development before wide deployment, but are enabled by the paper’s core innovations: a shared 3D-aware latent space; bidirectional synthesis from single-direction training; and robust geometric priors from GFMs.
Industry
- GPS-free global navigation using cross-view geometry fused with SLAM/BEV
- Sectors: autonomous vehicles, drones, defense
- What it could do: Real-time localization against global satellite basemaps by continuously aligning onboard camera frames to GeoMap embeddings; fuse with IMU/LiDAR for centimeter-level pose.
- Tools/products/workflows: On-vehicle inference stacks with model distillation for edge; map-tile streaming; continuous calibration.
- Assumptions/dependencies: Significant work on latency, dynamic scenes, illumination/weather invariance, seasonal shifts; safety certification; robust failure modes.
- Geo-consistent digital twins with “fill-in” synthesis
- Sectors: smart cities, construction tech, AEC, utilities
- What it could do: Use GeoFlow to generate missing ground-level views and update twin textures; combine with NeRF/3DGS for consistent 3D reconstruction guided by GeoMap embeddings.
- Tools/products/workflows: Twin-building pipelines that stitch real and synthesized views; confidence-aware rendering.
- Assumptions/dependencies: Higher-fidelity S2G; cross-time alignment; governance to prevent synthesized artifacts being treated as ground truth.
- Automated change detection via latent-space alignment
- Sectors: remote sensing analytics, insurance CAT, ESG monitoring
- What it could do: Compare time-separated embeddings and synthesized counterparts to detect structural changes (new roads/buildings, vegetation loss) at scale.
- Tools/products/workflows: Scheduled jobs that compute Δ-embeddings and alert thresholds; human verification queues.
- Assumptions/dependencies: Temporal metadata consistency; model stability across seasons/sensors; labeled validation programs.
- RF/network planning from synthesized obstructions
- Sectors: telecom
- What it could do: Generate approximate street-level occlusions from aerial data to accelerate RF propagation modeling in areas lacking ground surveys.
- Tools/products/workflows: Planning suites that import synthesized ground masks and obstruction maps as priors.
- Assumptions/dependencies: Needs higher geometric fidelity and calibration with real drive-test data.
Academia
- Cross-view geometric foundation models (Aerial–Ground–LiDAR–SAR)
- Sectors: multimodal 3D vision
- What it could do: Pretrain unified models across sensors and viewpoints, using GeoMap/GeoFlow as a scaffold; improve generalization to unseen geographies.
- Tools/products/workflows: Large-scale pretraining corpora; standardized benchmarks for bidirectional CVIS + CVGL + 3D reconstruction.
- Assumptions/dependencies: Curated multi-sensor datasets with licenses; compute scaling; robust evaluation protocols (uncertainty, fairness across regions).
- Causal and interpretable cross-view reasoning
- Sectors: AI safety and interpretability
- What it could do: Probe the shared latent space to understand which geometric cues drive retrieval and synthesis, improving trust and debuggability.
- Tools/products/workflows: Attribution and counterfactual toolkits for cross-view embeddings and flow fields.
- Assumptions/dependencies: New metrics for “geometric faithfulness” and content provenance.
Policy and Government
- National-scale incident intake with uncertainty-aware localization
- Sectors: emergency management, public health, environmental agencies
- What it could do: Ingest millions of citizen images in crises; provide probabilistic localizations and synthesized cross-views to triage.
- Tools/products/workflows: Federated processing to protect privacy; calibrated uncertainty reports; audit trails.
- Assumptions/dependencies: Policy frameworks for consent, retention, and use; standardized uncertainty communication; red-teaming to prevent misuse.
- Guidelines and audits for generative geo-synthesis
- Sectors: regulators, standards bodies
- What it could do: Establish disclosure, watermarking, and validation standards when synthesized views influence public decisions (planning, permits, investigations).
- Tools/products/workflows: Conformance tests against known datasets; provenance chains for synthesized content.
- Assumptions/dependencies: Multi-stakeholder collaboration (industry, academia, civil society).
Daily Life
- Privacy-preserving personal photo geotagging and trip reconstruction
- Sectors: consumer apps, digital wellbeing
- What it could do: On-device or private-cloud localization of photo libraries using cross-view retrieval to fill missing geotags; build personal maps.
- Tools/products/workflows: Lightweight, distilled models; opt-in processing; per-photo uncertainty.
- Assumptions/dependencies: Efficient mobile inference; strong privacy guarantees; UI to avoid overconfident pins.
- Immersive exploration of places without street coverage
- Sectors: travel, accessibility, education
- What it could do: Generate approximate walk-throughs from satellite imagery to help plan routes, assess terrain, or preview neighborhoods.
- Tools/products/workflows: AR/VR viewers with “AI-generated” overlays and confidence indicators.
- Assumptions/dependencies: Improved S2G realism; clear user education that visuals are approximations.
Notes on cross-cutting assumptions and risks:
- Data availability and licensing: Requires timely, high-resolution satellite/aerial imagery and (for training) paired or partially paired ground views; licensing terms must permit ML use.
- Compute and latency: GeoMap can run in real time with optimization; GeoFlow involves ODE integration and RAE encode/decode—optimize or distill for edge/real-time.
- Domain shift: Snow, foliage changes, construction, and cultural architectural differences affect performance; consider region-specific fine-tuning.
- Fidelity and misuse: Synthesized ground views can be misinterpreted as factual; always watermark, disclose, and include uncertainty; restrict sensitive use cases.
- Security and privacy: Process user imagery with consent; secure storage; comply with regional regulations (e.g., GDPR/CCPA).
Glossary
- AerialMegaDepth: A fine-tuned dataset/model setup that adapts geometric foundation models for aerial–ground imagery to improve cross-view reconstruction. "AerialMegaDepth~\cite{vuong2025aerialmegadepth} further fine-tunes MASt3R and DUSt3R on aerial and ground imagery"
- BEV estimation: Bird’s-Eye View estimation; inferring a top-down representation of a scene to guide cross-view tasks. "BEV estimation has been shown to improve ground-to-satellite synthesis~\cite{Cross-view_meets_diffusion}"
- Bidirectional synthesis: Generating images in both directions between domains (e.g., ground-to-satellite and satellite-to-ground). "not inherently invertible, preventing these methods to generalize on bi-directional synthesis"
- Cross-attention: An attention mechanism where queries attend to keys/values from another feature set to aggregate information. "aggregate information from and via cross-attention."
- Cross-View Geo-Localization (CVGL): Retrieving or estimating location by matching ground-view images to aerial/satellite images. "Cross-View Geo-Localization (CVGL) and Cross-View Image Synthesis (CVIS)"
- Cross-View Image Synthesis (CVIS): Generating an image from one view (ground or satellite) conditioned on the other view. "Cross-View Geo-Localization (CVGL) and Cross-View Image Synthesis (CVIS)"
- DDT heads: Specialized heads for Diffusion Transformers that improve generative modeling within the flow-matching setup. "We employ lightweight DiTs~\cite{DiT} with DDT heads~\cite{wang2025ddt} as the backbone of ."
- Diffusion models: Generative models that synthesize images by iteratively denoising from noise distributions. "These methods are based on GANs or diffusion models with strong assumptions"
- Diffusion Transformer (DiT): A transformer-based architecture used in diffusion or flow-matching generative pipelines. "We employ lightweight DiTs~\cite{DiT} with DDT heads~\cite{wang2025ddt} as the backbone of ."
- Domain translation: Learning a mapping between two data domains (e.g., ground and satellite) without requiring one-to-one invertible assumptions. "We argue that CVIS is better framed as a domain translation problem"
- DUSt3R: A Geometric Foundation Model capable of predicting 3D geometry from images. "Geometric Foundation Models (GFMs) such as DUSt3R~\cite{wang2024dust3r}, MASt3R~\cite{leroy2024grounding}, and VGGT~\cite{wang2025vggt} have demonstrated strong capabilities in 3D understanding and reconstruction."
- E2P (equiangular-to-perspective) transformation: Converting panoramic equiangular images to multiple perspective crops to reduce distortion. "we apply an equiangular-to-perspective (E2P) transformation"
- Flow matching: A training framework that learns a vector field to morph one distribution into another along a continuous path. "we introduce flow matching~\citep{lipman2022flow} to model transformations between aerial and ground domains."
- Fréchet Inception Distance (FID): A distributional metric assessing realism and diversity of generated images compared to real ones. "FID score~\citep{heusel2017gans}"
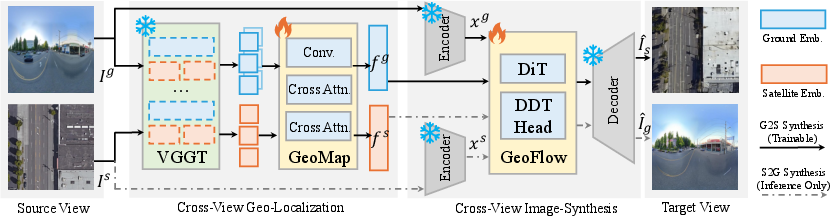
- GeoFlow: The paper’s geometry-conditioned flow-matching model for bidirectional cross-view image synthesis. "We propose GeoFlow, a flow-matching model conditioned on geometry-aware latent embeddings."
- GeoMap: The paper’s dual-branch encoder that embeds ground and satellite images into a shared geometry-aware latent space. "We propose GeoMap, which embeds ground and aerial features into a shared 3D-aware latent space"
- Geometric Foundation Models (GFMs): Large pre-trained models that extract generalizable 3D geometric features from images. "Recent Geometric Foundation Models (GFMs) have demonstrated strong capabilities in extracting generalizable 3D geometric features from images"
- Geometric priors: Prior knowledge about 3D structure used to guide learning and generation. "highlighting the effectiveness of 3D geometric priors for cross-view geo-spatial learning."
- Ground-to-Satellite (G2S): The synthesis or translation direction from ground images to satellite images. "Ground-to-Satellite or G2S"
- Hard sample mining: Training strategy that focuses on difficult negatives/positives to improve discriminative learning. "several works~\citep{zhu2021vigor, deuser2023sample4geo, hardTriplet} also adopt hard sample mining mechanisms"
- Hit rate: A retrieval metric indicating whether the top-1 result covers the query’s location. "For the VIGOR dataset, we also evaluate the hit rate, which measures whether the top-1 retrieved satellite image covers the query ground image location."
- InfoNCE loss: A contrastive objective that maximizes similarity of positive pairs against negatives in a batch. "Optimization is guided by the InfoNCE loss~\cite{oord2018infonce,infonce2} "
- Kullback–Leibler (KL) divergence: A measure of difference between probability distributions, used here to align embeddings. ""
- LPIPS: A perceptual similarity metric that correlates with human judgments of image similarity. "LPIPS~\citep{zhang2018LPIPS}"
- MASt3R: A Geometric Foundation Model for 3D reconstruction and geometry prediction from images. "Geometric Foundation Models (GFMs) such as DUSt3R~\cite{wang2024dust3r}, MASt3R~\cite{leroy2024grounding}, and VGGT~\cite{wang2025vggt}"
- Novel view synthesis: Generating images from unseen viewpoints given one or more observations. "which has wide application in downstream tasks like novel view synthesis~\cite{3dgs, zhang2025eggs}"
- Optimal transport displacement interpolation: An OT-based interpolation path between two distributions used in flow matching. "the optimal transport displacement interpolation~\cite{liu2022flow}"
- Ordinary Differential Equation (ODE): A continuous-time formulation solved via integration of the learned vector field for generation. "Mathematically, the trained defines an ODE function."
- Peak Signal-to-Noise Ratio (PSNR): A distortion-based metric measuring reconstruction fidelity in decibels. "Peak Signal-to-Noise Ratio (PSNR)"
- Polar transformation: A coordinate transform assuming center alignment to reduce cross-view distortion, often used in baselines. "adopting polar transformation, which assumes center-alignment between satellite and ground images."
- RAE: A pretrained regularized autoencoder used to encode images into a latent space for flow-based generation. "we took the pretrained RAE~\cite{RAE} to encode the image into latent space"
- Recall accuracy at Top-K (R@K): Retrieval metric evaluating whether the correct match appears within the top-K results. "we adopt the Recall accuracy at Top-K (R@K)"
- Satellite-to-Ground (S2G): The synthesis or translation direction from satellite images to ground images. "Satellite-to-Ground or S2G"
- Shared geometry-aware latent space: A feature space encoding both views with geometric cues to align and bridge tasks. "a shared geometry-aware latent space"
- Spherical coordinates: A coordinate system for panoramas where angles define positions on a sphere, causing perspective distortion. "panoramas represented in equiangular format and lie in spherical coordinates"
- Structural Similarity Index Measure (SSIM): A perceptual quality metric comparing structural similarity between images. "Structure Similarity Index Measure (SSIM)"
- Triplet loss: A contrastive loss using anchor-positive-negative tuples to enforce embedding separation. "such as triplet loss~\cite{GeoDTR, geodtr+} and InfoNCE loss"
- VGGT: A Geometric Foundation Model used to extract robust dense geometric features from images. "from GFMs (e.g., VGGT) to jointly perform \underline{Geo}-spatial tasks"
- Volume density modeling: Estimating 3D volume densities to guide image synthesis and structure inference. "volume density modeling~\cite{Sat2Density}"
Collections
Sign up for free to add this paper to one or more collections.