- The paper presents a unified framework leveraging explicit 3D geometric perception to integrate coarse satellite retrieval and fine-grained UAV pose estimation.
- It employs a Satellite-wise Attention block and dual geometric-feature verification, achieving an initial R@1 of 58.8% and enhanced meter-level accuracy.
- The approach outperforms traditional two-stage pipelines by maintaining spatial consistency and robustness in GNSS-denied, urban environments.
Unifying UAV Cross-View Geo-Localization via 3D Geometric Perception
Introduction and Motivation
The challenge of UAV cross-view geo-localization arises in GNSS-denied environments, where robust and precise localization based solely on visual data is required. The fundamental difficulty lies in the extreme geometric discrepancy between oblique UAV images and orthogonal satellite maps: the so-called facade-to-roof ambiguity is particularly problematic in urban canyons and dense built areas. Previous work predominantly employed decoupled two-stage pipelines for retrieval and pose estimation, often resulting in error accumulation across stages and limited fine-grained localization capability.
The paper "Unifying UAV Cross-View Geo-Localization via 3D Geometric Perception" (2604.01747) presents a unified framework that leverages explicit 3D geometric modeling—outperforming traditional two-stage approaches by maintaining geometric consistency through all pipeline phases.
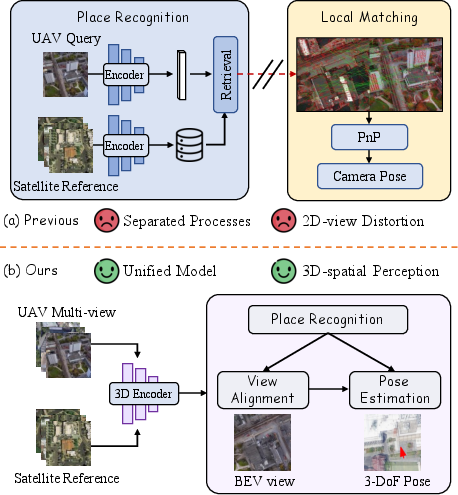
Figure 1: Comparative framework illustration between traditional two-stage (retrieval-estimation) and unified geometric perception pipelines.
Unified Pipeline and Methodological Advances
The core of the method is a geometric-centric pipeline that couples coarse satellite retrieval and fine-grained UAV pose estimation within a single shared 3D scene representation. The pipeline is instantiated via a Visual Geometry Grounded Transformer (VGGT), reconstructing a local 3D point cloud from multi-view oblique UAV images and orthorectifying a satellite-aligned Bird's-Eye View (BEV). The BEV acts as a geometric intermediary for robust cross-view feature correspondence and downstream anchoring in satellite imagery.
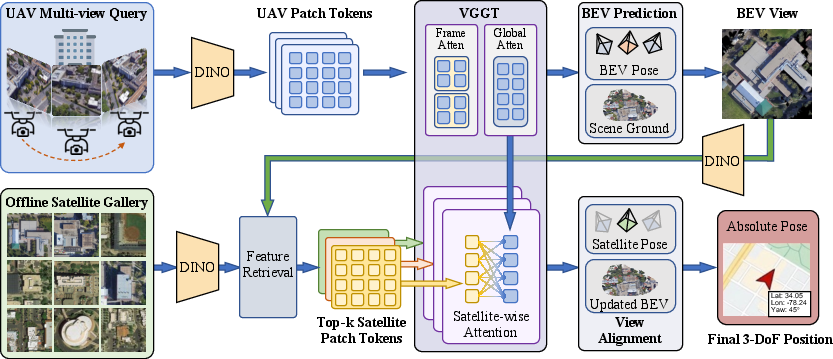
Figure 2: The unified pipeline: multi-view UAV input sequence is transformed, via VGGT, into a 3D scene and satellite-aligned BEV for retrieval and pose regression.
In contrast to implicit 2D-centric models, all retrieval, alignment, and pose regression tasks operate within this unified 3D-aware feature space. The method also dispenses with computationally expensive external SfM initialization, supporting instant dense geometric reasoning.
Satellite-wise Attention Mechanism
To address the inherent ambiguity when registering multiple satellite hypotheses, the paper introduces a Satellite-wise Attention Block. This module prevents cross-hypothesis interference by isolating each satellite candidate in feature space, reducing matching complexity from quadratic to linear and improving geometric consistency.
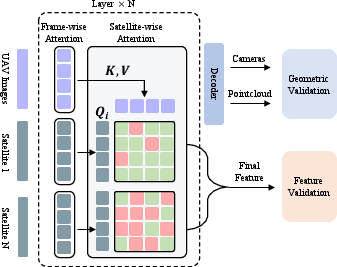
Figure 3: Satellite-wise Attention—each satellite candidate independently attends to the reconstructed UAV scene, removing interference and computational overhead.
Geometric and Feature-Based Verification
The framework employs dual strategies for candidate validation. Geometrically, the system measures the spatial consistency of the top-k satellite candidates by comparing the registration of their location and coverage with respect to the reconstructed 3D scene. In addition, the method computes a high-dimensional similarity matrix between UAV and satellite feature tokens to further discriminate positive matches—demonstrating that feature-level affinity intrinsically aligns with spatial overlap under the shared VGGT representation.
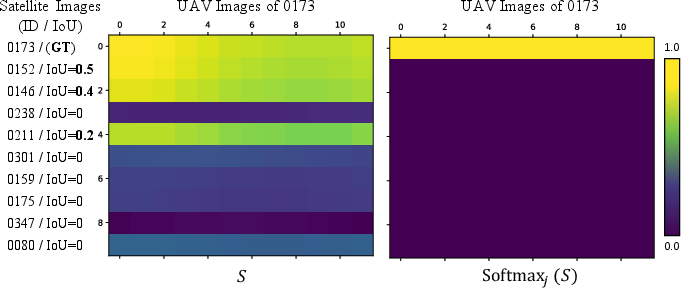
Figure 4: Similarity scores between satellite and UAV image features capture fine geometric and semantic agreement, highlighting discriminative capability for candidate selection.
Dataset Recalibration and Benchmarking
For rigorous evaluation, the paper recalibrates the University-1652 dataset, yielding the "University-Pose" benchmark with precise 3-DoF UAV pose annotations and explicit overlap statistics for satellite tiles. The satellite database is highly overlapping, providing multiple viable candidates per query—a critical property that SOTA methods underexploit.
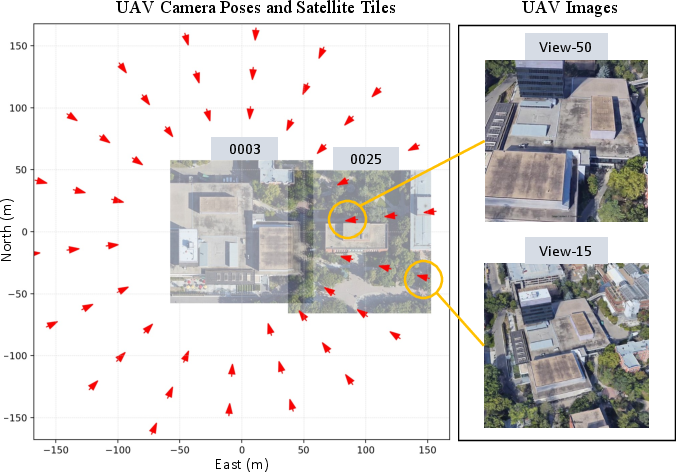
Figure 5: Visualization of geometric relationships between UAV pose, satellite tile grid, and spatial overlap. The dense overlap increases geometric verification robustness.
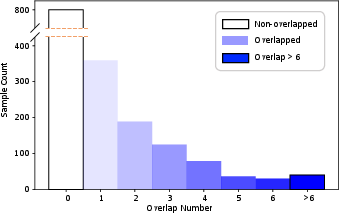
Figure 6: Distribution of satellite tile overlaps, confirming redundancy and opportunity for multi-hypothesis geometric validation.
Experimental Results
The approach is evaluated on both University-1652 and SUES-200 benchmarks. The unified geometry-based framework systematically outperforms previous methods in both retrieval (Recall@K, mAP) and fine localization (meter-level success rates):
- Retrieval (Initial BEV): Achieves 58.8% R@1; performance increases to 79.0% after BEV refinement.
- Fine-grained pose estimation: Delivers strict meter-level accuracy; significantly higher success rates under 50m and 10m error thresholds compared to retrieval-only baselines.
One key finding is that relaxing binary retrieval assumptions to consider overlapping neighbor tiles (i.e., via IoU-based R@K) yields higher recall and provides more robust geometric anchors for downstream pose estimation.

Figure 7: Step-wise BEV refinement visualizations demonstrate spatial alignment improvements through the candidate integration stage.
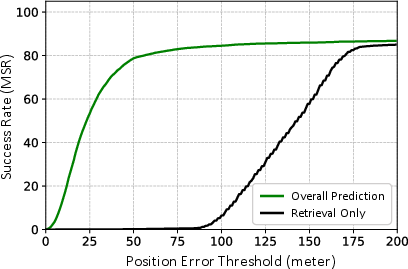
Figure 8: Curves of meter-level position success rates; the unified pipeline maintains strong accuracy at stringent error thresholds, unlike retrieval-only systems.
Ablation and System Analysis
Ablation studies confirm that Satellite-wise Attention and feature-based candidate validation are critical for robust performance. Feature similarity offers more discriminative power over explicit geometric priors for candidate selection, especially in dense, ambiguous search spaces. Increasing the number of UAV input views improves both retrieval and pose estimation up to a practical sequence length.
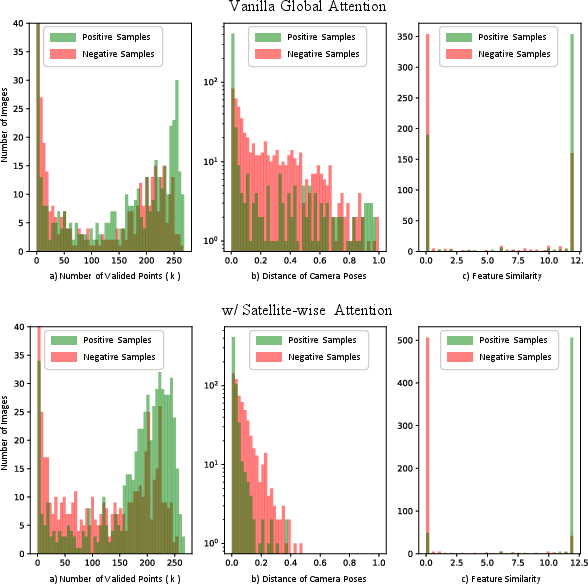
Figure 9: Analysis of satellite image overlap statistics; validating that candidate redundancy is exploited by the method rather than constituting adverse distractors.
Qualitative visualizations showcase accurate top-k retrievals, frequent high ranking of true positives and significant overlaps, and precise long-horizon UAV trajectory localization even in complex built environments.
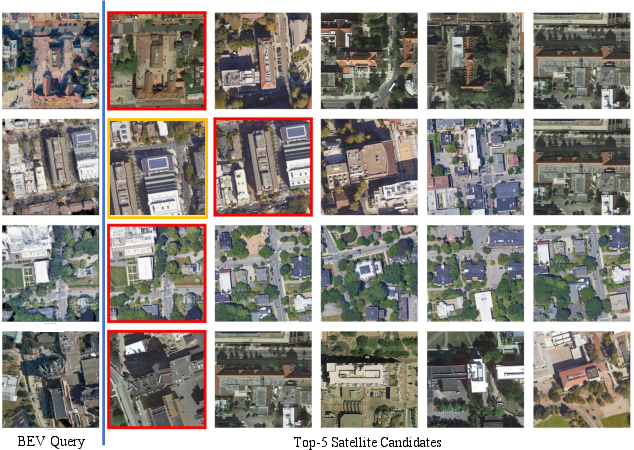
Figure 10: Visualization of cross-view retrieval results—the model consistently retrieves ground truth and high-overlap candidates.
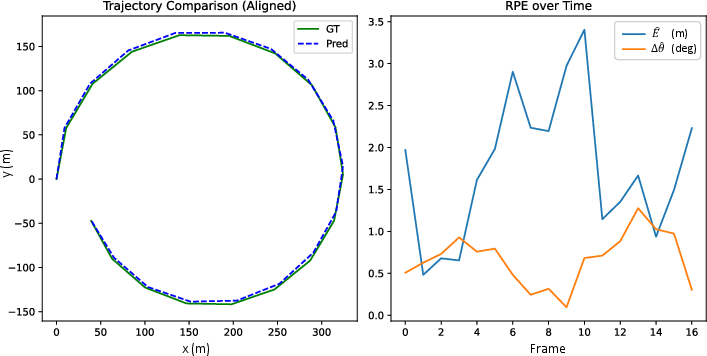
Figure 11: Visualization of predicted UAV trajectory closely following ground truth, underscoring the method's high-fidelity localization capability.
Discussion and Implications
The unified framework marks a methodological advance in coupling geometric consistency across all cross-view localization stages, as opposed to error-prone stage-wise pipelines. The architectural innovations, especially Satellite-wise Attention, are applicable beyond UAV localization to any scenario involving multi-hypothesis geometric registration in dense candidate spaces.
Practical implications include more robust navigation in GNSS-denied or urban environments, improved resilience to viewpoint and occlusion-induced ambiguities, and compatibility with instant or near-real-time onboard processing.
Theoretical implications center on the role of explicit 3D feature spaces in bridging domain gaps in cross-modal perception, encouraging future end-to-end optimization (beyond foundation model pretraining), and motivating implicit alignment pipelines that bypass explicit BEV projection for full-feature correspondence.
Future directions include:
- End-to-end joint optimization with differentiable geometric loss propagation to feature backbones,
- Generalization of the pipeline to single-view (monocular) input via advanced depth priors or generative models,
- Exploration of implicit Neural Feature Field-based token-level cross-modal alignment, dispensing with rasterized BEV intermediaries.
Conclusion
This paper establishes a robust and scalable paradigm for cross-view geo-localization by structurally unifying retrieval, alignment, and pose estimation within a geometry-grounded pipeline (2604.01747). The explicit modeling of shared 3D context, coupled with computationally efficient and interference-aware attention mechanisms, leads to measurable improvements in both retrieval accuracy and strict meter-level localization under challenging conditions. The methodology and empirical insights pave the way for next-generation geometric and feature-centric cross-modal localization systems.