MegaFlow: Zero-Shot Large Displacement Optical Flow
Abstract: Accurate estimation of large displacement optical flow remains a critical challenge. Existing methods typically rely on iterative local search or/and domain-specific fine-tuning, which severely limits their performance in large displacement and zero-shot generalization scenarios. To overcome this, we introduce MegaFlow, a simple yet powerful model for zero-shot large displacement optical flow. Rather than relying on highly complex, task-specific architectural designs, MegaFlow adapts powerful pre-trained vision priors to produce temporally consistent motion fields. In particular, we formulate flow estimation as a global matching problem by leveraging pre-trained global Vision Transformer features, which naturally capture large displacements. This is followed by a few lightweight iterative refinements to further improve the sub-pixel accuracy. Extensive experiments demonstrate that MegaFlow achieves state-of-the-art zero-shot performance across multiple optical flow benchmarks. Moreover, our model also delivers highly competitive zero-shot performance on long-range point tracking benchmarks, demonstrating its robust transferability and suggesting a unified paradigm for generalizable motion estimation. Our project page is at: https://kristen-z.github.io/projects/megaflow.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
MegaFlow: A simple explanation for teens
What is this paper about?
This paper introduces MegaFlow, a computer vision system that can figure out how every pixel in a video moves from one frame to the next. This motion is called “optical flow.” MegaFlow is especially good at handling big movements (like a car zooming past the camera) and works well even on new videos it hasn’t been specially trained on (this is called “zero-shot” generalization).
What questions are the researchers trying to answer?
The paper aims to answer a few key questions in an easy-to-understand way:
- How can we accurately track large, fast movements between video frames without retraining the model for each new type of video?
- Can we reuse powerful “foundation” vision models (trained on lots of images) to help with motion, even though they were trained on static pictures?
- Is there a simple method that first finds matches globally (across the whole image) and then fine-tunes them locally for high precision?
- Can the same model also track any specific point across many frames (point tracking), not just estimate dense motion?
How does MegaFlow work? (Methods in simple terms)
Think of two video frames as two puzzles that are almost the same, but some pieces have moved. MegaFlow tries to find where each “piece” (pixel or small patch) went.
It works in three main stages:
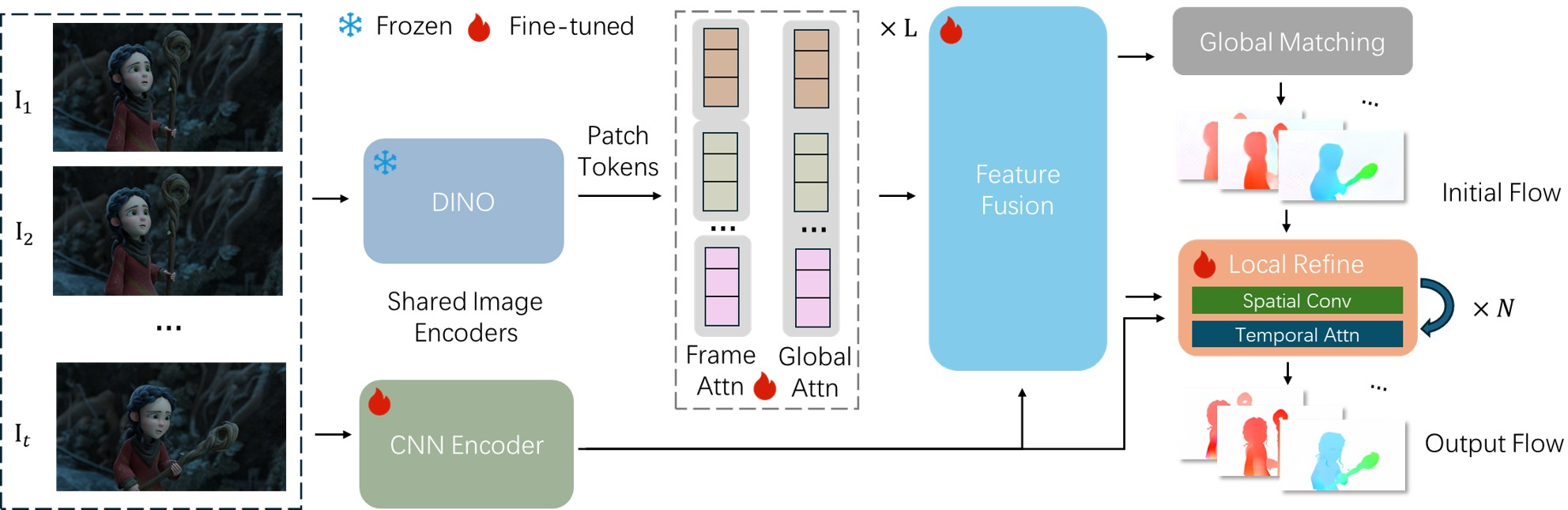
- Getting strong features from each frame
- MegaFlow uses a powerful pre-trained vision Transformer (DINOv2) to understand the big picture of each frame (like understanding objects and their locations).
- It also uses a small CNN to capture fine details (like edges and small textures).
- These two types of features are blended together so the model sees both the overall scene and the tiny details.
- Global matching to handle big motions
- For each patch in frame A, MegaFlow searches the entire frame B to find the best match, not just near the original spot.
- This “search everywhere” step finds a good first guess for where things moved, which is crucial when something jumps far across the screen.
- You can think of it like: “Where did this patch end up in the next frame?” The model computes how similar patches are and picks the most likely destination.
- Local iterative refinement for precision
- After the first guess, MegaFlow zooms in around the predicted spot and refines the motion in small steps.
- It does this several times, using:
- Convolutions (good at local details) and
- Temporal attention (which looks across multiple frames to keep motion consistent over time).
- This polishing step improves “sub-pixel” accuracy (precision smaller than a pixel), making results sharper and more stable.
Bonus: Point tracking without extra parts
- To track specific points (like the tip of a finger) across many frames, the model computes motion from the first frame to each later frame.
- The tracked position is just “starting point + estimated motion.”
- No special tracker is needed—the same flow system does the job.
What did they find, and why does it matter?
The researchers tested MegaFlow on several well-known datasets and found:
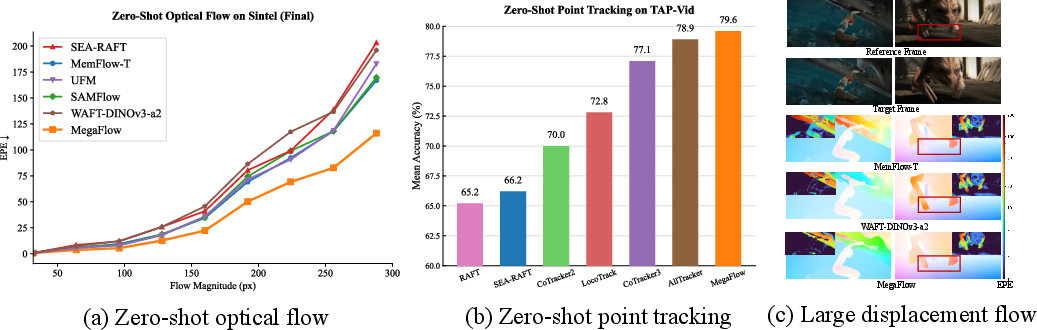
- Zero-shot strength: Without fine-tuning for specific benchmarks, MegaFlow achieved state-of-the-art or highly competitive results on Sintel and KITTI, two popular optical flow tests. It was especially strong on the Sintel “Final” pass, which is tough because of motion blur and haze.
- Large movements: On very big motions (over 40 pixels), MegaFlow’s error was much lower than many other methods. This shows the global matching step really helps.
- Real-world scale: On the high-resolution Spring benchmark, MegaFlow reached state-of-the-art zero-shot performance and produced crisp motion boundaries (like thin branches).
- Point tracking: On TAP-Vid (which measures tracking any point across time), MegaFlow, even as a flow model, beat many specialized trackers in zero-shot. After a small fine-tuning on a tracking dataset (Kubric), it reached state-of-the-art performance.
Why it matters:
- Handling big, fast, and complicated motions is hard but important for real applications like self-driving cars, sports analysis, video editing, AR/VR, and robotics.
- Working “zero-shot” means fewer costly retraining steps and better reliability on new scenes.
- One model that does both optical flow and point tracking simplifies the toolset for video understanding.
What’s the bigger picture? (Implications)
MegaFlow shows a promising direction: reuse strong vision Transformers trained on images, then add a smart two-step strategy—global matching for big jumps and local refinement for precision. This approach:
- Improves accuracy on extreme motions,
- Generalizes to new videos without special tuning,
- Unifies tasks (dense flow and point tracking) in a single framework.
In the future, the authors want to make it faster and more efficient for very long videos and explore training strategies that jointly learn both flow and tracking from the start. Overall, MegaFlow is a step toward a general “motion foundation model” that can handle many kinds of movement in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, written to be concrete and actionable for future work:
- Computational scalability of global all-pairs matching: The initial correlation is computed over all token pairs at ~1/7 resolution, which grows quadratically with image size and pair count. The paper does not quantify memory/compute at higher resolutions (e.g., 1080p, 4K) or longer windows; investigate sparse/ANN-based matching, blockwise attention, or hierarchical/pruned correlation to maintain accuracy while reducing cost.
- Real-time feasibility and deployment: The model has 936M parameters and ~324 ms latency at 540×960 (2 frames, RTX 4090) and grows with frames; assess throughput at 4-frame inference, Full HD, and long sequences, and explore distillation, architectural slimming, quantization, or low-rank adapters to enable real-time or edge deployment.
- Sensitivity to resolution/aspect ratio: Fixed patch tokenization (from the Transformer prior) negatively impacts KITTI; develop resolution-agnostic tokenizers (adaptive patch sizes, learned resizable positional encodings) or multi-scale feature tokenization to mitigate aspect ratio/scale mismatch.
- Small-motion and sub-pixel accuracy: MegaFlow lags SOTA for low-magnitude motions () on Sintel; examine higher-resolution matching, multi-scale refinement, or sub-pixel fitting (e.g., local quadratic fitting on correlation peaks) to reduce small-motion errors without sacrificing large-displacement gains.
- Lack of explicit occlusion/visibility modeling: The method does not predict occlusion masks or point visibility and “tracks through occlusion” via continuous fields; add occlusion heads, forward–backward consistency checks, and confidence estimation to improve flow near motion boundaries and to handle track termination/re-acquisition.
- Ambiguity in global matching due to soft-argmax: The initial flow uses an expectation over the matching distribution, which can average over multi-modal matches; evaluate and compare discrete argmax, Gumbel-Softmax, entropy/temperature control, or mutual nearest-neighbor constraints to avoid “blurry” correspondences.
- Absence of one-to-one or cycle constraints: The global matching does not enforce bijectivity or cycle consistency; integrate mutual consistency (forward–backward) or assignment constraints to reduce mismatches in repetitive/textureless regions.
- Temporal window adaptivity: Longer contexts help on Sintel but degrade performance on KITTI; design mechanisms to adapt window size and aggregation to scene dynamics (e.g., motion statistics, visibility cues), and compare causal streaming vs. non-causal batch processing.
- Persistent memory for long sequences: The tracking extension uses a sliding window (size 8) with trajectory-only carryover; investigate learnable long-term memory (keys/values), cross-window feature persistence, or re-detection modules to mitigate drift over hundreds of frames.
- Visibility-aware tracking: TAP-Vid evaluation benefits from visibility reasoning, but the model lacks explicit visibility/confidence outputs; add visibility estimation and uncertainty-aware scoring for more reliable trajectory evaluation and downstream use.
- Failure analysis on challenging sequences: Sintel Final “Ambush 1” is identified as an outlier but not analyzed; conduct targeted diagnostics (blur, fast occlusions, non-rigid deformations) to identify failure modes and guide architectural or training fixes.
- Domain robustness gaps: Despite strong zero-shot results, robustness to real sensor artifacts (rolling shutter, severe motion blur, ISO noise), adverse weather/night, and strong lighting/exposure changes is not assessed; create or adopt benchmarks and augmentations covering these factors.
- Limited reporting on occluded vs. non-occluded errors: Benchmarks typically break down errors by visibility; report and optimize occluded-region EPE/F1 to better understand occlusion handling deficiencies.
- Lack of geometry-aware constraints: For driving or multi-view scenes, the approach does not exploit epipolar/rigidity priors or camera ego-motion; evaluate hybrid models that regularize flow with geometric constraints or estimate scene flow.
- No uncertainty or confidence calibration: The model outputs deterministic flow without epistemic/aleatoric uncertainty; add predictive uncertainty or confidence maps (e.g., via ensembling, MC dropout, evidential losses) for safer downstream use.
- Training data and pretraining strategy: The method adapts static-scene priors (DINOv2/VGGT) and relies on supervised flow datasets; explore unified video/motion pretraining (masked video modeling, contrastive temporal objectives) and mixed synthetic–real curricula for better motion-aware priors.
- Test-time adaptation: Zero-shot policy is principled, but it remains unknown how much test-time self-supervision (e.g., photometric, cycle consistency) could further boost generalization without domain-specific fine-tuning; systematically evaluate TTA/TTO methods.
- Multi-scale global matching not explored: The paper uses a single global matching scale; investigate hierarchical global matching (coarse-to-fine tokens) to simultaneously handle extreme motions and fine details, and quantify the trade-off with compute.
- Incomplete architectural disclosure for replication: Key hyperparameters (e.g., local correlation radius r, temperature/normalization in softmax, fusion specifics) are deferred to the supplement; provide detailed ablations for r, token stride, patch size, and fusion choices to improve reproducibility.
- Tracking re-identification and out-of-FOV handling: The sliding-window tracker does not explicitly re-detect points that leave/re-enter the field of view; incorporate re-identification mechanisms or global retrieval to extend tracks across long occlusions and exits.
- Evaluation breadth for tracking: Results are shown on TAP-Vid; assess on additional long-form, real-world benchmarks (e.g., HQ long videos with heavy occlusions/articulation) and report failure cases where local appearance changes or re-entry break tracks.
- Trade-offs with frame count: On Spring, 4-frame inference improves EPE but increases 1px outliers relative to 2 frames; analyze this trade-off and design refinement schedules or loss terms to preserve pixel-level sharpness with larger temporal windows.
- Resource accessibility and fairness: Training requires 64 GH200 GPUs over four days; explore compute-efficient training (parameter-efficient fine-tuning, curriculum, smaller backbones) and report performance–compute Pareto curves for broader accessibility.
- Extension to 3D motion: The method targets 2D optical flow; evaluate feasibility of extending to scene flow (3D) with monocular/stereo cues and whether global matching at token level can be augmented with depth priors.
Practical Applications
Immediate Applications
Below are applications that can be deployed now, leveraging MegaFlow’s zero-shot generalization, large-displacement robustness, and unified flow/point-tracking without task-specific fine-tuning.
- VFX and post-production: long-range point tracking for rotoscoping and motion graphics (media/entertainment)
- Tools/products/workflows: Nuke/After Effects plugin that exposes “Track Any Point” over hundreds of frames; batch roto assist; spline/keyframe propagation; plate stabilization for fast pans/zoom.
- Assumptions/dependencies: Runs best on high-memory GPUs (e.g., RTX 4090 or data-center GPUs); near-real-time not required for offline pipelines; use 4-frame windows by default; add automatic fallback to 2 frames on fast forward-motion content.
- Sports broadcast analytics: ball and player tracking in fast-motion footage (media/sports analytics)
- Tools/products/workflows: MegaFlow-based tracking API for analytics suites; automated highlight clipping via trajectory cues; foul/offside assist using stable tracks under large camera motion.
- Assumptions/dependencies: Inference is offline or nearline; high camera shake and occlusions benefit from 4-frame temporal attention; integrate with detection models for identities.
- Drone footage and cinematography: motion-aware stabilization and stitching under rapid parallax (media/robotics)
- Tools/products/workflows: Post-flight stabilization, horizon correction, and mosaic building; fast cut detection via flow discontinuities; improved keyframe selection for 3D reconstruction.
- Assumptions/dependencies: Variable resolution support is needed; for forward-motion scenes (e.g., fast fly-throughs), use T=2 (per paper’s KITTI finding) to avoid occlusion artifacts.
- Construction progress and industrial inspection: long-range correspondence for change tracking (AEC/industrial)
- Tools/products/workflows: Site-progress dashboards measuring motion/shift across weekly videos; conveyor-belt part tracking; weld/corrosion progression tracking in plant videos.
- Assumptions/dependencies: Zero-shot generalization reduces per-site fine-tuning; consistent capture protocols (camera paths, lighting) improve reliability.
- Video restoration and enhancement: motion-compensated deblurring, frame interpolation, and super-resolution (software/media processing)
- Tools/products/workflows: Replace legacy flow in interpolation and sharpening pipelines to better handle fast motion; use global matching for fewer artifacts on s40+ displacements.
- Assumptions/dependencies: Offline batch processing; flow confidence gating advisable; export to standard flow formats to drop-in replace existing pipelines.
- Autonomous driving and ADAS offline analysis: edge-case mining and motion diagnostics (automotive)
- Tools/products/workflows: Offline labeling/QA to find failure modes triggered by large displacements; motion priors for SLAM/SfM replay; trajectory consistency checks for perception stacks.
- Assumptions/dependencies: Not real-time; sensitive to KITTI-style forward motion—prefer 2-frame mode for such sequences; integrate with calibration and ego-motion to reduce boundary artifacts.
- Academic baselines and teaching: a strong zero-shot foundation for motion research and coursework (academia/education)
- Tools/products/workflows: Baseline for multi-frame vs pairwise ablations; labs on global matching vs local refinement; zero-shot benchmarks on Sintel/KITTI/Spring/TAP-Vid without dataset-specific tuning.
- Assumptions/dependencies: Access to a single high-end GPU suffices for demos; public weights and code availability from project page.
- Retail and security analytics: privacy-aware zone flow and queue dynamics (retail/safety)
- Tools/products/workflows: Aggregate flow fields for people/asset movement heatmaps without identity; long-range tracking of anonymous points for queue time estimation.
- Assumptions/dependencies: Operates best offline or nearline; privacy constraints suggest avoiding re-identification—use dense motion only.
- Medical video QA and research: endoscopy/laparoscopy stabilization and tool trajectory analysis (healthcare R&D)
- Tools/products/workflows: Offline research tools for stabilization and motion metrics; instrument tip tracking across occlusions and smoke.
- Assumptions/dependencies: Not for diagnostic/clinical deployment without validation; domain shift can be nontrivial—pilot studies and QA required; data governance (PHI) applies.
- Remote sensing video (aerial/traffic cams): large parallax motion analysis and event localization (geospatial)
- Tools/products/workflows: Motion anomaly alerts (landslides, floods, traffic surges) using dense flow; baseline correspondences for dynamic 3D modeling from video.
- Assumptions/dependencies: Cross-sensor differences (spectral bands, compression) may require pre-processing; run offline on clips; 4-frame window helps with occlusions/blur.
Long-Term Applications
These are feasible with further research, scaling, distillation, or systems integration to address compute, latency, or domain constraints.
- Real-time edge variants for robotics and ADAS (robotics/automotive)
- Tools/products/workflows: “MegaFlow-Lite” via distillation, pruning, and INT8 quantization for 30–60 FPS on embedded GPUs; adaptive T and iteration K; multi-scale tiles.
- Assumptions/dependencies: Model compression research; kernel-level optimizations beyond FlashAttention; thermal/power budget on edge devices.
- On-device AR/VR anchoring and occlusion-robust rendering at 60–120 Hz (AR/VR/mobile)
- Tools/products/workflows: Motion-stable anchors under head snaps; dynamic scene occlusion via accurate flow; predictive reprojection for foveated rendering.
- Assumptions/dependencies: Sub-10 ms latency targets; neural architecture search for mobile NPUs; tight integration with SLAM and IMU.
- Unified motion foundation: jointly learned depth/pose/flow/tracks (software/robotics/3D)
- Tools/products/workflows: A single model producing depth, optical flow, camera egomotion, and long-range tracks; simplifies 3D reconstruction and dynamic scene understanding.
- Assumptions/dependencies: Large-scale joint pretraining beyond current datasets; memory-efficient global matching across tasks.
- Multimodal sensing: fusing event cameras, LiDAR, and thermal for extreme motion/light (robotics/defense)
- Tools/products/workflows: Fusion module to stabilize flow in low light or high-speed scenes; robust odometry and obstacle detection under adverse conditions.
- Assumptions/dependencies: Cross-sensor calibration; training corpora with synchronized modalities; custom attention blocks for asynchronous events.
- Satellite and aerial multi-temporal monitoring under large parallax and seasonal shifts (geospatial/energy/infrastructure)
- Tools/products/workflows: Asset monitoring (wind turbine blades, solar panels), vegetation growth, urban change; risk dashboards for insurers and utilities.
- Assumptions/dependencies: Cross-sensor harmonization; atmospheric effects; scaling global matching to very high resolutions with memory-aware tiling.
- Generative video editing/control: motion-consistent conditioning for diffusion/video LLMs (media/software)
- Tools/products/workflows: Flow-guided inpainting, motion retiming, scene re-animation with fewer artifacts on fast motion; “edit-by-trajectory” UX.
- Assumptions/dependencies: Tight coupling with generation backbones; differentiable flow constraints; user-in-the-loop guardrails for content safety.
- Clinical-grade intraoperative tracking and stabilization (healthcare)
- Tools/products/workflows: Real-time instrument and tissue motion tracking to assist surgeons; tremor compensation; endoscope stabilization.
- Assumptions/dependencies: Regulatory validation; clinically curated datasets; stringent latency and reliability; secure on-prem deployment.
- Content authenticity and safety: motion-consistency signals for deepfake detection (policy/media forensics)
- Tools/products/workflows: Forensic tools that flag implausible motion fields in manipulated videos; long-range trajectory consistency checks.
- Assumptions/dependencies: Robustness to compression and re-encoding; benchmark curation; integration with broader forensic pipelines.
- Consumer video apps: action-camera stabilization and hyperlapse without calibration (consumer software)
- Tools/products/workflows: Mobile/desktop apps offering robust stabilization for fast moves; auto-cut detection using motion saliency; long-shot retargeting.
- Assumptions/dependencies: Strong model distillation; on-device acceleration; variable-aspect-ratio handling (noted KITTI sensitivity).
- Policy and procurement guidance: benchmarking and sustainability standards for vision foundation models (policy/standards)
- Tools/products/workflows: Best-practice docs on zero-shot evaluation, compute reporting (e.g., 64×GH200 training disclosure), and energy footprint; safety guidelines for autonomy use.
- Assumptions/dependencies: Multi-stakeholder coordination; public benchmarks with diverse motion regimes; lifecycle carbon accounting.
Cross-cutting dependencies and assumptions
- Compute and memory: The reference model (∼936M params) is heavyweight; typical latency ~324 ms at 540×960 on an RTX 4090 for 2-frame inference. Real-time uses will require compression, fewer frames (T), fewer refinement steps (K), lower resolution, or specialized hardware.
- Variable frame window: The paper shows T=4 improves complex scenes (Sintel) while T=2 can be better for strong forward ego-motion (KITTI). Production systems should adapt T per scene dynamics.
- Resolution/aspect ratio: Patch tokenization can be sensitive to aspect ratio (KITTI). Use standardized resizing/padding or multi-scale tiling for unusual formats.
- Data governance: For surveillance/medical uses, ensure privacy, consent, and secure processing. Zero-shot transfer reduces the need for domain-specific data but does not eliminate compliance requirements.
- Integration: Best performance often comes from combining MegaFlow with detectors/segmenters (ID assignment), SLAM/IMU (egomotion), or 3D mapping systems.
- Licensing and ecosystem: Dependence on DINOv2/VGGT weights, PyTorch, and FlashAttention-3; ensure license compatibility and kernel availability across platforms.
Glossary
- AdamW: An optimization algorithm that decouples weight decay from gradient-based updates to improve generalization. "optimize with AdamW"
- All-pairs correlation: A similarity computation between every spatial location in one feature map and all locations in another, used to build a global matching cost. "by computing an all-pairs correlation:"
- bfloat16 precision: A 16-bit floating-point format that preserves exponent range for efficient training with lower memory. "leverage bfloat16 precision and gradient checkpointing to improve memory usage and computational efficiency."
- ConvNeXt: A modern convolutional architecture designed to be competitive with Transformers for vision tasks. "a ConvNeXt-based convolutional branch"
- Cost volumes: 4D tensors that encode matching costs over candidate displacements, used to infer correspondences. "pyramid warping and cost volumes to handle large displacements."
- DINOv2: A self-supervised Vision Transformer model providing robust, transferable image features. "we first extract per-frame features using DINOv2"
- DPT-style fusion head: A feature fusion module inspired by Dense Prediction Transformers that aligns and merges multi-scale features. "A DPT-style fusion head then aligns and merges the CNN features with the Transformer feature space"
- Ego-motion: Motion of the camera itself, which can complicate correspondence due to large viewpoint changes. "KITTI features rapid forward ego-motion"
- End-Point Error (EPE): The average Euclidean distance between predicted and ground-truth flow vectors; the standard optical flow accuracy metric. "The primary metric is End-Point Error (EPE), calculated as the average"
- Energy minimization: A classical variational formulation that estimates flow by optimizing an energy objective over pixel correspondences. "Classical methods typically formulate optical flow as an energy minimization problem"
- F1-all: KITTI’s percentage of outlier flow estimates across all pixels. "For KITTI, we additionally report F1-all, indicating the percentage of outliers."
- Fl-all: KITTI’s outlier rate metric reflecting the fraction of pixels with large flow errors. "MegaFlow achieves the best overall Fl-all error of 10.7"
- FlashAttention-3: A fast, memory-efficient attention algorithm for Transformers, accelerating training/inference. "All attention layers are accelerated using FlashAttention-3"
- Frame-wise attention: Self-attention applied within individual frames to model intra-frame dependencies. "whose alternating frame-wise and global-attention Transformer blocks have shown highly effective at modeling cross-view relations."
- Global attention: Self-attention across frames for long-range dependencies and cross-view relations. "Alternating frame and global attention"
- Global matching: Establishing correspondences by comparing features across the entire image pair, not just locally. "we formulate flow estimation as a global matching problem"
- Gradient checkpointing: A memory-saving technique that recomputes intermediate activations during backpropagation. "and gradient checkpointing to improve memory usage and computational efficiency."
- Gradient norm clipping: Stabilization technique that caps the norm of gradients to prevent exploding updates. "We employ gradient norm clipping with a threshold of 1.0"
- Iterative refinement: Repeatedly updating the flow estimate to progressively improve accuracy. "establishes the dominant paradigm of iterative refinement"
- Local correlation volume: A tensor encoding feature similarities over a small neighborhood around a warped location to refine flow. "A local correlation volume is then constructed as:"
- Occlusion artifacts: Errors caused by regions that become invisible between frames, leading to inconsistent correspondences. "Processing isolated pairs leads to temporal inconsistencies and occlusion artifacts"
- Patch tokenization: Converting image patches into tokens for Transformer processing, potentially losing fine spatial detail. "the loss of fine spatial details caused by patch tokenization"
- Patch tokens: Tokenized patch-level embeddings fed into Transformers. "extract dense patch tokens and local structural features."
- Pixel unshuffle: An operation that reduces spatial resolution while increasing channel dimension to compress features. "spatially compressed using pixel unshuffle"
- Point tracking: Estimating the trajectories of specific pixels across frames. "zero-shot point tracking results on TAP-Vid."
- Recurrent module: A network component that updates predictions over iterations or time steps, leveraging temporal context. "a lightweight recurrent module"
- Sliding window: Processing long sequences in overlapping chunks to manage memory and maintain temporal continuity. "we employ an sliding window strategy with a window size of 8."
- Softmax normalization: Converting raw similarity scores into a probability distribution over matches. "we apply a softmax normalization"
- Sub-pixel accuracy: Precision finer than a single pixel, achieved via continuous refinement of correspondences. "for sub-pixel accuracy"
- Temporal attention: Attention over time to aggregate information across frames for consistent motion estimation. "a temporal attention branch correlates features across the sequence."
- Transformer backbone: The core Transformer network used for feature processing and representation learning. "a Transformer backbone composed of L alternating global and frame-wise attention layers"
- VGGT: A large pre-trained vision Transformer backbone emphasizing global geometry and cross-view relations. "following VGGT"
- Vision foundation models: Large pre-trained models with broad transfer capabilities across vision tasks. "highly adaptable to diverse vision foundation models"
- Vision Transformer: A Transformer architecture operating on image patch tokens for visual recognition and correspondence. "pre-trained global Vision Transformer features"
- WAUC: Weighted Area Under the Curve; an evaluation metric aggregating accuracy across thresholds. "weighted area under the curve (WAUC)"
- Zero-shot generalization: Strong performance on unseen datasets without task-specific fine-tuning. "zero-shot generalization scenarios"
Collections
Sign up for free to add this paper to one or more collections.

