- The paper introduces GS-Light, a training-free pipeline that aligns text-derived lighting priors with multi-view 3D scenes for precise relighting.
- It employs advanced cross-view attention and epipolar constraints to achieve coherent lighting edits across diverse viewpoints.
- Empirical results demonstrate enhanced multi-view consistency (PSNR/SSIM/LPIPS) compared to baseline 2D relighting methods.
Training-Free Multi-View Extension of IC-Light for Textual Position-Aware Scene Relighting
Introduction and Motivation
GS-Light directly addresses the challenge of multi-view coherent, position-aware 3D scene relighting in the context of Gaussian Splatting (3DGS) representations. Existing diffusion-based 2D relighting models such as IC-Light excel at artistic illumination edits but exhibit inherent limitations in multi-view 3D consistency and positional intent preservation when extended to 3D scene representations. GS-Light advances this area by introducing a fully training-free, text-controllable relighting pipeline, explicitly aligning geometric and textual modalities for accurate lighting direction control and enforcing multi-view consistency through architectural modifications.
In contrast to previous 2D-to-3D editing frameworks that either disregard positional cues or struggle to propagate edits consistently across views, GS-Light leverages large vision-LLMs (LVLMs) and geometry estimators to parse prompt-derived lighting priors, fuses view-wise semantic and geometric signals, and applies these as latent initializers in a modified diffusion pipeline that incorporates cross-view attention with epipolar constraints for view-space alignment.
Methodology
Pipeline Overview
The GS-Light workflow begins with rendering images from a pre-trained GS scene at all available viewpoints. The user supplies a relighting instruction encompassing lighting direction, color, intensity, and optionally reference objects. The Position-Align Module (PAM) utilizes an LVLM (Qwen2.5-VL) to robustly parse the prompt for lighting direction and object references, ensuring outputs strictly relevant to relighting.
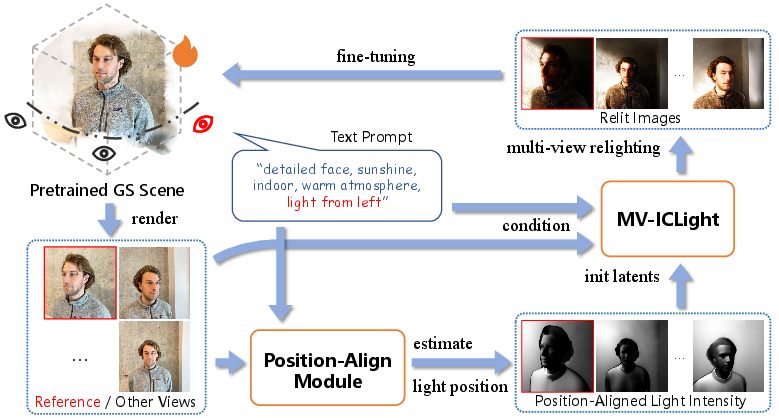
Figure 1: GS-Light's circulation pipeline, detailing text prompt parsing, positional alignment, multi-view latent initialization, diffusion-based relighting, and iterative GS tuning.
Subsequently, per-view geometry (depth via VGGT, normals via StableNormal, semantics via LangSAM masks) is estimated. These priors are fused using a modified Phong illumination model, generating per-pixel intensity maps spatially aligned to the user's intent. These illumination maps are encoded as initialization latents for the diffusion process in MV-ICLight, which employs cross-view attention and advanced epipolar constraints (normalized fundamental matrix for stability) as derived from DGE to ensure feature-level coherence across views. The relit images are used to fine-tune the GS scene’s appearance parameters (color/opacity only), forming a closed-loop iterative finetuning process.
Position-Align Module (PAM)
Standard multimodal models and diffusion editors have limited semantic understanding of position-related prompts (e.g., discerning "light from the left" vs "right") (Figure 2). PAM precisely bridges this gap, parsing directional cues and object semantics from the prompt and rendered views via LVLM and text-guided segmentation (LangSAM). It estimates the initial light source position via semantic mask centroids and view-aligned coordinates, then shifts the inferred source according to the directional prompt. The result is a view-wise, geometry-aware illumination map for latent initialization.
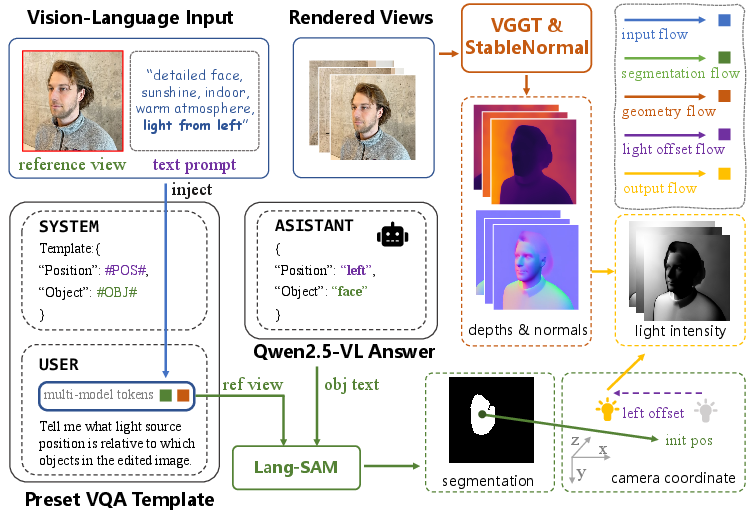
Figure 3: PAM details, showing how Qwen2.5-VL parses lighting direction and object, and how geometry/semantics are combined to generate position-aligned intensity maps.
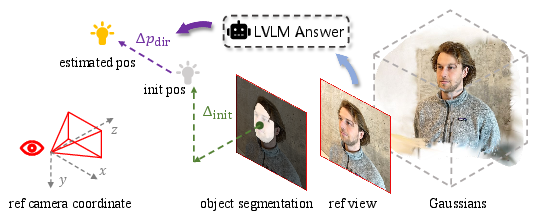
Figure 4: Light source position estimation illustrated for prompt-guided relighting.
MV-ICLight and Multi-View Consistency
To generalize 2D IC-Light to multi-view 3D relighting, MV-ICLight replaces the self-attention mechanism in the diffusion U-Net with cross-view attention, enabling query tokens in one view to attend to keys in all views. The quadratic scaling in memory is mitigated via key frame subsampling and advanced epipolar matching for feature propagation to non-key frames, ensuring computational efficiency and stable multi-view correspondence.
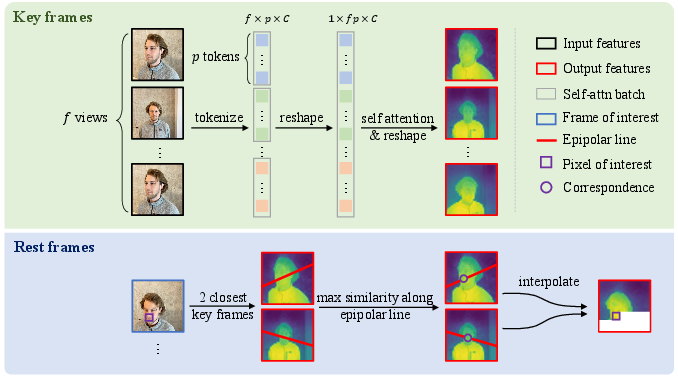
Figure 5: MV-ICLight attention schema: upper shows cross-view attention, lower shows epipolar constraint propagation.
Quantitative ablation confirms that MV-ICLight markedly improves multi-view consistency metrics compared to vanilla IC-Light (PSNR/SSIM/LPIPS), and qualitative results reveal significantly fewer view-dependent artifacts.











































































Figure 6: Multi-view consistency ablation: MV-ICLight results display coherent relit appearances across diverse viewpoints, while standard IC-Light lacks inter-view structure, inducing blurring.
Fine-Tuning and Dataset Update Strategy
Iterative dataset update, inspired by IN2N, ensures convergence of the GS scene to the multi-view consistent relit appearance. The relit images are fed recurrently as supervision in GS fine-tuning, with scene appearance parameters (color, opacity) optimized in a memory-efficient fashion. The process achieves stability within a few minutes per scene per iteration.
Empirical Evaluation
GS-Light is benchmarked on indoor/outdoor scenes across IN2N, MipNerf360, and ScanNet++. Prompts are systematically generated via GPT-5 to cover a range of lighting directions and scenarios. Baselines include RelightVid, Lumen, DGE, EditSplat, IN2N, IGS2GS, and IGS2GS-IC.
































































Figure 7: Qualitative comparison of GS-Light versus prior relighting/video/Gaussian Splatting methods—GS-Light excels in spatial fidelity, aesthetic quality, semantic preservation, and directional lighting control from text.
Objective metrics include CLIP-Text and CLIP-Direction (for prompt-image alignment), VBench video metrics (subject, background consistency, aesthetic, image quality), as well as multi-view consistency (PSNR, SSIM, LPIPS for relit GS renders). Across all datasets and metrics, GS-Light achieves top or competitive performance:
- CLIP-T, CLIP-D, VBench scores consistently highest among all methods.
- GS-Light demonstrates superior subjective ranking by user study (Table: preference).
Ablation Studies
Systematic ablation of PAM, cross-view attention, and IC-Light components reveals their contributions. Removal of PAM or cross-view attention impairs semantic alignment and multi-view coherence; normalization of the fundamental matrix is essential to avoid numerical overflow in epipolar constraint enforcement (Figure 8).

















































































Figure 9: PAM ablation visualization: with PAM, GS-Light precisely controls lighting direction per prompt across all views; without PAM, results lack directional fidelity.
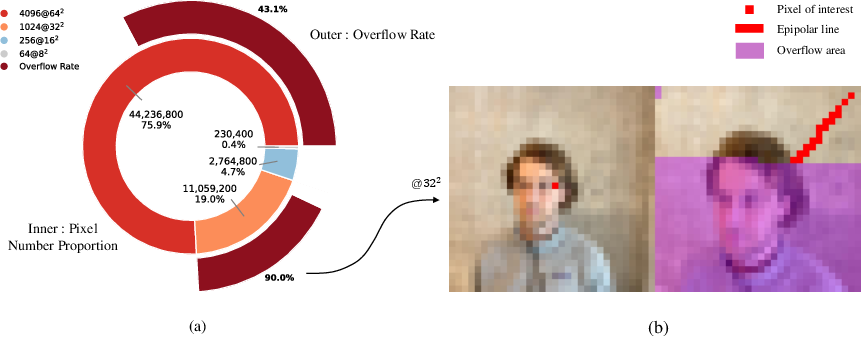
Figure 8: Normalization of fundamental matrix eliminates overflow occurrences during UNet inference, stabilizing epipolar constraints and improving matching.
Limitations and Future Directions
GS-Light inherits several constraints: reliance on off-the-shelf geometry/semantic estimators limits performance in scenes with problematic depth or normals; projection back to the GS model can leave uncovered or poorly textured regions; handling of specular/aniso materials is limited in pure inference pipelines. Integration with differentiable visibility, material priors, and advances in LVLM understanding—particularly for complex and compositional lighting—are potential future enhancements.
Conclusion
GS-Light delivers an efficient, training-free pipeline for multi-view consistent, position-aware 3D scene relighting from textual instructions. The use of prompt-derived priors, position alignment, and multi-view latent initialization enables robust control over lighting semantics, including directionality. The framework establishes new performance paradigms in both objective and subjective evaluations and sets a foundation for further research in accessible, controllable 3D relighting for synthetic and real-world scenes.

